

15. Метод наименьших квадратов.
Метод наименьших квадратов — один из методов регрессионного анализа для оценки неизвестных величин по результатам измерений, содержащих случайные ошибки.
Метод наименьших квадратов применяется также для приближённого представления заданной функции другими (более простыми) функциями и часто оказывается полезным при обработке наблюдений.
Когда искомая величина может быть измерена непосредственно, как, например, длина отрезка или угол, то, для увеличения точности, измерение производится много раз, и за окончательный результат берут арифметическое среднее из всех отдельных измерений. Это правило арифметической середины основывается на соображениях теории вероятностей; легко показать, что сумма квадратов уклонений отдельных измерений от арифметической середины будет меньше, чем сумма квадратов уклонений отдельных измерений от какой бы то ни было другой величины. Само правило арифметической середины представляет, следовательно, простейший случай метода наименьших квадратов.
Примеры

Пример кривой, проведённой через точки, имеющие нормально распределённое отклонение от истинного значения. Пусть надо решить систему уравнений
|
|
(1) |

число которых более
числа неизвестных x,
y,
![]()
Чтобы решить их по способу наименьших квадратов, составляют новую систему уравнений, число которых равно числу неизвестных и которые затем решаются по обыкновенным правилам алгебры. Эти новые, или так называемые нормальные уравнения составляются по следующему правилу: умножают сперва все данные уравнения на коэффициенты у первой неизвестной x и, сложив почленно, получают первое нормальное уравнение, умножают все данные уравнения на коэффициенты у второй неизвестной y и, сложив почленно, получают второе нормальное уравнение и т. д. Если обозначить для краткости:
|
|
|

то нормальные уравнения представятся в следующем простом виде:
|
|
(2) |

Легко заметить, что коэффициенты нормальных уравнений весьма легко составляются из коэффициентов данных, и притом коэффициент у первой неизвестной во втором уравнении равен коэффициенту у второй неизвестной в первом, коэффициент у первой неизвестной в третьем уравнении равен коэффициенту у третьей неизвестной в первом и т. д
Регрессионный анализ. Теоретическое корреляционное отношение и линейный коэффициент корреляции.
Определение регрессии. Регрессия — функция, позволяющая по средней величине одного признака определить среднюю величину другого признака, корреляционно связанного с первым.
С этой целью применяется коэффициент регрессии и целый ряд других параметров. Например, можно рассчитать число простудных заболеваний в среднем при определенных значениях среднемесячной температуры воздуха в осенне-зимний период.
Определение коэффициента регрессии. Коэффициент регрессии — абсолютная величина, на которую в среднем изменяется величина одного признака при изменении другого связанного с ним признака на установленную единицу измерения.
Формула коэффициента регрессии. Rу/х = rху x (σу / σx) где Rу/х — коэффициент регрессии; rху — коэффициент корреляции между признаками х и у; (σу и σx) — среднеквадратические отклонения признаков x и у.
В нашем примере [rху = - 0,96 коэффициент корреляции между изменениями среднемесячной температуры в осенне-зимний период (х) и средним числом инфекционно-простудных заболеваний (у)]; σх = 4,6 (среднеквадратическое отклонение температуры воздуха в осенне-зимний период; σу = 8,65 (среднеквадратическое отклонение числа инфекционно-простудных заболеваний). Таким образом, Rу/х — коэффициент регрессии. Rу/х = -0,96 х (4,6 / 8,65) = 1,8, т.е. при снижении среднемесячной температуры воздуха (x) на 1 градус среднее число инфекционно-простудных заболеваний (у) в осенне-зимний период будет изменяться на 1,8 случаев.
Уравнение регрессии. у = Му + Ry/x (х - Мx) где у — средняя величина признака, которую следует определять при изменении средней величины другого признака (х); х — известная средняя величина другого признака; Ry/x — коэффициент регрессии; Мх, Му — известные средние величины признаков x и у.
Например, среднее число инфекционно-простудных заболеваний (у) можно определить без специальных измерений при любом среднем значении среднемесячной температуры воздуха (х). Так, если х = - 9°, Rу/х = 1,8 заболеваний, Мх = -7°, Му = 20 заболеваний, то у = 20 + 1,8 х (9-7) = 20 + 3,6 = 23,6 заболеваний. Данное уравнение применяется в случае прямолинейной связи между двумя признаками (х и у).
Назначение уравнения регрессии. Уравнение регрессии используется для построения линии регрессии. Последняя позволяет без специальных измерений определить любую среднюю величину (у) одного признака, если меняется величина (х) другого признака. По этим данным строится график — линия регрессии, по которой можно определить среднее число простудных заболеваний при любом значении среднемесячной температуры в пределах между расчетными значениями числа простудных заболеваний.
Сигма регрессии (формула).
![]()
где σRу/х — сигма (среднеквадратическое отклонение) регрессии; σу— среднеквадратическое отклонение признака у; rху — коэффициент корреляции между признаками х и у.
Так, если σу - среднеквадратическое отклонение числа простудных заболеваний = 8,65; rху — коэффициент корреляции между числом простудных заболеваний (у) и среднемесячной температурой воздуха в осенне-зимний период (х) равен — 0,96, то

Назначение сигмы регрессии. Дает характеристику меры разнообразия результативного признака (у).
Например, характеризует разнообразие числа простудных заболеваний при определенном значении среднемесячной температуры воздуха в осеннне-зимний период. Так, среднее число простудных заболеваний при температуре воздуха х1 = -6° может колебаться в пределах от 15,78 заболеваний до 20,62 заболеваний. При х2 = -9° среднее число простудных заболеваний может колебаться в пределах от 21,18 заболеваний до 26,02 заболеваний и т.д.
Сигма регрессии используется при построении шкалы регрессии, которая отражает отклонение величин результативного признака от среднего его значения, отложенного на линии регрессии.
Данные, необходимые для расчета и графического изображения шкалы регрессии
коэффициент регрессии — Rу/х;
уравнение регрессии — у = Му + Rу/х (х-Мx);
сигма регрессии — σRx/y
Другая важнейшая
задача - измерение тесноты зависимости -
для всех форм связи может быть решена
при помощи вычисления эмпирического
корреляционного
отношения ![]() :
:
![]()
где - ![]() дисперсия
в ряду выравненных значений результативного
показателя
дисперсия
в ряду выравненных значений результативного
показателя![]() ;
;![]() -
дисперсия в ряду фактических значений
у.
-
дисперсия в ряду фактических значений
у.
Для определения степени тесноты парной линейной зависимости служит линейный коэффициент корреляции r, для расчета которого можно использовать, например, две следующие формулы:
![]()

Линейный коэффициент корреляции может принимать значения в пределах от -1 до + 1 или по модулю от 0 до 1. Чем ближе он по абсолютной величине к 1, тем теснее связь. Знак указывает направление связи: «+» - прямая зависимость, «-» имеет место при обратной зависимости.
Регрессионный анализ. Ошибки оценок коэффициентов регрессии. Проверка гипотез о значимости коэффициентов регрессии и уравнения регрессии в целом.
Определение регрессии. Регрессия — функция, позволяющая по средней величине одного признака определить среднюю величину другого признака, корреляционно связанного с первым.
С этой целью применяется коэффициент регрессии и целый ряд других параметров. Например, можно рассчитать число простудных заболеваний в среднем при определенных значениях среднемесячной температуры воздуха в осенне-зимний период.
Определение коэффициента регрессии. Коэффициент регрессии — абсолютная величина, на которую в среднем изменяется величина одного признака при изменении другого связанного с ним признака на установленную единицу измерения.
Формула коэффициента регрессии. Rу/х = rху x (σу / σx) где Rу/х — коэффициент регрессии; rху — коэффициент корреляции между признаками х и у; (σу и σx) — среднеквадратические отклонения признаков x и у.
В нашем примере [rху = - 0,96 коэффициент корреляции между изменениями среднемесячной температуры в осенне-зимний период (х) и средним числом инфекционно-простудных заболеваний (у)]; σх = 4,6 (среднеквадратическое отклонение температуры воздуха в осенне-зимний период; σу = 8,65 (среднеквадратическое отклонение числа инфекционно-простудных заболеваний). Таким образом, Rу/х — коэффициент регрессии. Rу/х = -0,96 х (4,6 / 8,65) = 1,8, т.е. при снижении среднемесячной температуры воздуха (x) на 1 градус среднее число инфекционно-простудных заболеваний (у) в осенне-зимний период будет изменяться на 1,8 случаев.
Уравнение регрессии. у = Му + Ry/x (х - Мx) где у — средняя величина признака, которую следует определять при изменении средней величины другого признака (х); х — известная средняя величина другого признака; Ry/x — коэффициент регрессии; Мх, Му — известные средние величины признаков x и у.
Например, среднее число инфекционно-простудных заболеваний (у) можно определить без специальных измерений при любом среднем значении среднемесячной температуры воздуха (х). Так, если х = - 9°, Rу/х = 1,8 заболеваний, Мх = -7°, Му = 20 заболеваний, то у = 20 + 1,8 х (9-7) = 20 + 3,6 = 23,6 заболеваний. Данное уравнение применяется в случае прямолинейной связи между двумя признаками (х и у).
Назначение уравнения регрессии. Уравнение регрессии используется для построения линии регрессии. Последняя позволяет без специальных измерений определить любую среднюю величину (у) одного признака, если меняется величина (х) другого признака. По этим данным строится график — линия регрессии, по которой можно определить среднее число простудных заболеваний при любом значении среднемесячной температуры в пределах между расчетными значениями числа простудных заболеваний.
Сигма регрессии (формула).
![]()
где σRу/х — сигма (среднеквадратическое отклонение) регрессии; σу— среднеквадратическое отклонение признака у; rху — коэффициент корреляции между признаками х и у.
Так, если σу - среднеквадратическое отклонение числа простудных заболеваний = 8,65; rху — коэффициент корреляции между числом простудных заболеваний (у) и среднемесячной температурой воздуха в осенне-зимний период (х) равен — 0,96, то

Назначение сигмы регрессии. Дает характеристику меры разнообразия результативного признака (у).
Например, характеризует разнообразие числа простудных заболеваний при определенном значении среднемесячной температуры воздуха в осеннне-зимний период. Так, среднее число простудных заболеваний при температуре воздуха х1 = -6° может колебаться в пределах от 15,78 заболеваний до 20,62 заболеваний. При х2 = -9° среднее число простудных заболеваний может колебаться в пределах от 21,18 заболеваний до 26,02 заболеваний и т.д.
Сигма регрессии используется при построении шкалы регрессии, которая отражает отклонение величин результативного признака от среднего его значения, отложенного на линии регрессии.
Данные, необходимые для расчета и графического изображения шкалы регрессии
коэффициент регрессии — Rу/х;
уравнение регрессии — у = Му + Rу/х (х-Мx);
сигма регрессии — σRx/y
Стандартная ошибка является оценкой среднего квадратичного отклонения коэффициента регрессии от его истинного значения. Позволяет получить некоторое представление о форме функции плотности вероятности, однако не несёт информации о том, находится ли полученная оценка в середине распределения (т.е. является точной) или в его «хвосте» (т.е. является относительно неточной).

проверке гипотезы H0 остатистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fфактопределяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:

где n – число единиц совокупности;
m – число параметров при переменных x.
Fтабл – это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости a. Уровень значимости a – вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно a принимается равной 0,05 или 0,01.
Если Fтабл< Fфакт, то H0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если Fтабл> Fфакт, то H0 – гипотеза не отклоняется и признается статистическая незначимость, надежность уравнения регрессии.
2. t-критерий Стьюдента используется для оценки статистической значимости коэффициентов регрессии и коэффициента корреляции.
В качестве основной гипотезы выдвигают гипотезу H0 о незначимом отличии от нуля параметра регрессии или коэффициента корреляции. Альтернативной гипотезой, при этом является гипотеза обратная, т.е. о неравенстве нулю параметра или коэффициента корреляции.
Найденное по данным наблюдений значение t-критерия (его еще называют наблюдаемым или фактическим) сравнивается с табличным (критическим) значением, определяемым по таблицам распределения Стьюдента (которые обычно приводятся в конце учебников и практикумов по статистике или эконометрике).
Табличное значение определяется в зависимости от уровня значимости (a) и числа степеней свободы, которое в случае линейной парной регрессии равно (n-2) , n - число наблюдений.
Если фактическое значение t-критерия больше табличного (по модулю), то считают, что с вероятностью (1-a) параметр регрессии (коэффициент корреляции) значимо отличается от нуля.
Если фактическое значение t-критерия меньше табличного (по модулю), то нет оснований отвергать основную гипотезу, т.е. параметр регрессии (коэффициент корреляции) незначимо отличается от нуля при уровне значимости a.
Фактические значения t-критерия определяются по формулам:
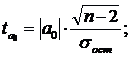

где 
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции используют критерий:

где r - оценка коэффициента корреляции, полученная по наблюдаемым данным. tтабл остается прежним.
3. Адекватность регрессионной модели оценим с помощью средней ошибки аппроксимации – среднее отклонение расчетных значений от фактических:

Допустимый предел
значений ![]() –
не более 8-10%.
–
не более 8-10%.
Линейный коэффициент корреляции и коэффициент Фехнера. Проверка линейного коэффициента корреляции на значимость.
Для определения степени тесноты парной линейной зависимости служит линейный коэффициент корреляции r, для расчета которого можно использовать, например, две следующие формулы:
![]()

Линейный коэффициент корреляции может принимать значения в пределах от -1 до + 1 или по модулю от 0 до 1. Чем ближе он по абсолютной величине к 1, тем теснее связь. Знак указывает направление связи: «+» - прямая зависимость, «-» имеет место при обратной зависимости.
коэффициент Фехнера, характеризующий элементарную степень тесноты связи, который целесообразно использовать для установления факта наличия связи, когда существует небольшой объем исходной информации. Данный коэффициент определяется по формуле
![]()
где na - количество совпадений знаков отклонений индивидуальных величин от их средней арифметической; nb - соответственно количество несовпадений.
Коэффициент Фехнера
может изменяться в пределах
-1,0 ![]() Кф
Кф ![]() +1,0.
+1,0.
проверке гипотезы H0 остатистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fфактопределяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:

где n – число единиц совокупности;
m – число параметров при переменных x.
Fтабл – это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости a. Уровень значимости a – вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно a принимается равной 0,05 или 0,01.
Если Fтабл< Fфакт, то H0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если Fтабл> Fфакт, то H0 – гипотеза не отклоняется и признается статистическая незначимость, надежность уравнения регрессии.
2. t-критерий Стьюдента используется для оценки статистической значимости коэффициентов регрессии и коэффициента корреляции.
В качестве основной гипотезы выдвигают гипотезу H0 о незначимом отличии от нуля параметра регрессии или коэффициента корреляции. Альтернативной гипотезой, при этом является гипотеза обратная, т.е. о неравенстве нулю параметра или коэффициента корреляции.
Найденное по данным наблюдений значение t-критерия (его еще называют наблюдаемым или фактическим) сравнивается с табличным (критическим) значением, определяемым по таблицам распределения Стьюдента (которые обычно приводятся в конце учебников и практикумов по статистике или эконометрике).
Табличное значение определяется в зависимости от уровня значимости (a) и числа степеней свободы, которое в случае линейной парной регрессии равно (n-2) , n - число наблюдений.
Если фактическое значение t-критерия больше табличного (по модулю), то считают, что с вероятностью (1-a) параметр регрессии (коэффициент корреляции) значимо отличается от нуля.
Если фактическое значение t-критерия меньше табличного (по модулю), то нет оснований отвергать основную гипотезу, т.е. параметр регрессии (коэффициент корреляции) незначимо отличается от нуля при уровне значимости a.
Фактические значения t-критерия определяются по формулам:
![]()

![]() где
где
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции используют критерий:
![]()
где r - оценка коэффициента корреляции, полученная по наблюдаемым данным. tтабл остается прежним.
3. Адекватность регрессионной модели оценим с помощью средней ошибки аппроксимации – среднее отклонение расчетных значений от фактических:

Допустимый предел
значений ![]() –
не более 8-10%.
–
не более 8-10%.
Коэффициенты корреляции рангов.
В статистической практике могут встречаться такие случаи, когда качества факторных и результативных признаков не могут быть выражены численно. Поэтому для измерения тесноты зависимости необходимо использовать другие показатели. Для этих целей используются так называемые непараметрические методы.
Наибольшее распространение имеют ранговые коэффициенты корреляции, в основу которых положен принцип нумерации значений статистического ряда. При использовании коэффициентов корреляции рангов коррелируются не сами значения показателей х и у, а только номера их мест, которые они занимают в каждом ряду значений. В этом случае номер каждой отдельной единицы будет ее рангом.
Коэффициенты корреляции, основанные на использовании ранжированного метода, были предложены . Спирмэном и М. Кендэлом.
Коэффициент корреляции рангов Спирмэна (р) основан на рассмотрении разности рангов значений результативного и факторного признаков и может быть рассчитан по формуле

где d = Nx - Ny , т.е. разность рангов каждой пары значений х и у; n - число наблюдений.
Ранговый коэффициент
корреляции Кендэла (![]() )
можно определить по формуле
)
можно определить по формуле

где S = P + Q.
К непараметрическим методам исследования можно отнести коэффициент ассоциации Кас и коэффициент контингенции Ккон , которые используются, если, например, необходимо исследовать тесноту зависимости между качественными признаками, каждый из которых представлен в виде альтернативных признаков.
Для определения этих коэффициентов создается расчетная таблица (таблица «четырех полей»), где статистическое сказуемое схематически представлено в следующем виде:
|
Признаки |
А (да) |
А (нет) |
Итого |
|
В (да) |
a |
b |
a + b |
|
В (нет) |
с |
d |
c + d |
|
Итого |
a + c |
b + d |
n |
Здесь а, b, c, d -
частоты взаимного сочетания (комбинации)
двух альтернативных признаков
![]() ;
n - общая сумма частот.
;
n - общая сумма частот.
Коэффициент ассоциации можно расcчитать по формуле
![]()
Коэффициент контингенции рассчитывается по формуле

Нужно иметь в виду, что для одних и тех же данных коэффициент контингенции (изменяется от -1 до +1) всегда меньше коэффициента ассоциации.
Показатели тесноты связи между двумя качественными признаками. Проверка гипотезы о существенности связи.
Коэффициент ассоциации Кас и коэффициент контингенции Ккон , которые используются, если, например, необходимо исследовать тесноту зависимости между качественными признаками, каждый из которых представлен в виде альтернативных признаков. Для определения этих коэффициентов создается расчетная таблица (таблица «четырех полей»), где статистическое сказуемое схематически представлено в следующем виде:
|
Признаки |
А (да) |
А (нет) |
Итого |
|
В (да) |
a |
b |
a + b |
|
В (нет) |
с |
d |
c + d |
|
Итого |
a + c |
b + d |
n |
Здесь а, b, c, d -
частоты взаимного сочетания (комбинации)
двух альтернативных признаков ![]() ;
n - общая сумма частот.
;
n - общая сумма частот.
Коэффициент
ассоциации можно расcчитать по формуле![]()
Коэффициент
контингенции рассчитывается по формуле