

Сети (1)
.pdfНазвание протокола DHCP (Dynamic Host Configuration Protocol) дословно расшифровывается как «Протокол динамической конфигурации хоста». Данный протокол работает на прикладном уровне модели OSI и позволяет компьютерам сети получать ряд настроек (в том числе IP адрес) от расположенного в сети DHCP сервера. Как уже становится понятно все устройства в сети, при работе с протоколом DHCP можно разделить на два вида: DHCP сервера и DHCP клиенты. DHCP клиенты пытаются получить настройки, а DHCP сервера выдают их.
Рассмотрим как работает данный протокол, на примере следующей топологии сети.
На примере данной сети мы рассмотри работу протокола DHCP
Пусть у нас имеется некоторая сеть, в которой существует DHCP сервер. Все компьютеры иDHCP сервер связываются друг с другом через коммутатор. К данной сети подключают еще один новый компьютер. Зная что в сети существует DHCP сервер, в его настройках указывают получать IP адрес автоматически. После этого новый компьютер попытается получить IP адрес от DHCP сервера. Для этого он выполняет широковещательный запрос на IP адрес 255.255.255.255, а в качестве своего IP адреса указывает 0.0.0.0 (так как у него еще нет IP адреса). В ходе данного широковещательного запроса рассылается сообщение DHCPDISCOVER, данное сообщение содержит в себе информацию позволяющую отличить его от других типов запросов/сообщений (тоесть указывает на то, что это сообщение предназначено для DHCP сервера, для получения IP адреса), MACадрес устройства сформировавшего запрос, а также предыдущий IP адрес устройства (если он у него был).
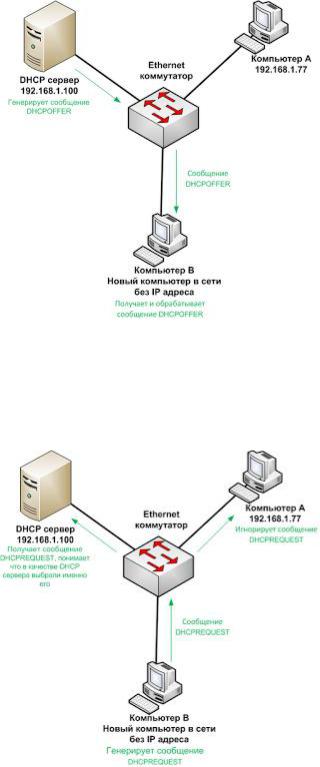
Процесс рассылки сообщения DHCPDISCOVER
Так как сообщение DHCPDISCOVER рассылается широковещательным способом, оно попадает не только на DHCP сервер, но и на другие устройства данного сегмента сети, но так как в сообщение DHCPDISCOVER указывается, что оно предназначено только для DHCPсервера, остальные устройства сети отвергают данное сообщение.
При получении сообщения DHCPDISCOVER DHCP сервером, он анализирует его содержание и в соответствии со своими настройками выбирает подходящую конфигурацию для запросившего компьютера и отправляет ее обратно в сообщении DHCPOFFER. Обычно сообщение DHCPOFFER отсылается только на MAC адрес компьютера, который был указан в сообщении DHCPDISCOVER, но иногда оно может рассылаться и методом широковещательной рассылки.
|
|
DHCP сервер отвечает сообщением DHCPOFFER |
|
В случае если |
в |
сети существует несколько DHCP серверов компьютер может получить |
в ответ на |
сообщение DHCPDISCOVER несколько сообщений DHCPOFFER от разных DHCPсерверов. Из них компьютер выбирает |
|||
одно, обычно полученное первым. И отвечает на него сообщением DHCPREQUEST, которое содержит в себе всю туже |
|||
информацию, что |
и |
сообщение DHCPDISCOVER + IP адрес выбранного DHCP сервера. Сообщение |
DHCPREQUEST |
рассылается широковещательным методом, для того чтобы его могли получить все DHCP сервера сети, если их несколько.
Рассылка сообщения DHCPREQUEST
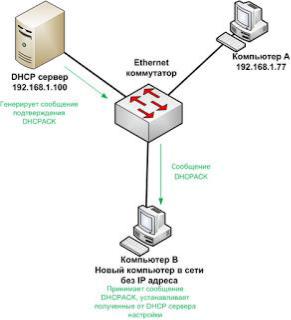
Все устройства сети, не являющиеся DHCP серверами игнорируют сообщениеDHCPREQUEST. DHCP сервера, IP адрес которых не содержится в сообщении DHCPREQUEST понимают, что их не выбрали в качестве DHCP сервера. DHCP сервер IP адрес которого указан в сообщении DHCPREQUEST получает его и понимает, что именного его выбрали в качестве DHCP сервера для нового компьютера, на что он отвечает сообщением DHCPACK, которое как бы подтверждает данный выбор. Сообщение DHCPACK отправляется на MACадрес компьютера указанного в сообщении DHCPREQUEST.
Отсылка подтверждающего сообщения DHCPACK
Компьютер, запрашивающий конфигурацию, получает сообщения DHCPACK. И применяет конфигурацию, которая была получена в сообщении DHCPOFFER. Вот так путем несложного обмена сообщениями функционирует протокол DHCP.
DHCP сервер может быть настроен по разному, и в зависимости от его конфигурации он будет выдавать IP адреса, запрашивающим компьютерам разными способами. Например, можно настроить DHCP сервер так, чтобы он выдавал запросившим компьютерам любые свободные IP адреса из некоторого диапазона, а можно настроить так, чтобы он выдавал определенные IP адреса устройствам с заданными MAC адресами. В общем все зависит от конфигурации.
В роли DHCP сервера может выступать сервер под управлением серверной ОС семействаLinux или Windows, некоторые модели коммутаторов и даже обычные компьютеры с клиентскими операционными системами, в случае если на них установлено специализированное программное обеспечение. Обычно под DHCP сервера не отводят отдельного физического сервера или отдельной виртуальной машины, а устанавливают их на одном из уже существующих не сильно загруженных серверов, выполняющих другую роль.
11) алгоритм ста
Алгоритм связующего дерева (Spanning-Tree Algoritm) (STA)
Алгоритм был разработан для того, чтобы сохранить преимущества петель, устранив их проблемы. Первоначально алгоритм был документирован корпорацией Digital - основным поставщиком Ethernet. Новый алгоритм, разработанный Digital, был впоследствии пересмотрен комитетом IEEE 802 и опубликован в спецификации IEE 802. 1d в качестве алгоритма STA.
STA предусматривает свободное от петель подмножество топологии сети путем размещения таких мостов, которые, если они включены, то образуют петли в резервном (блокирующем) состоянии.
Порты блокирующего моста могут быть активированы в случае отказа основного канала, обеспечивая новый тракт через объединенную сеть.
STA пользуются выводом из теории графов в качестве базиса для построения свободного от петель подмножества топологии сети. Теория графов утверждает следующее:
Для любого подсоединенного графа, состоящего из узлов и ребер, соединяющих пары узлов, существует связующее дерево из ребер, которое поддерживает связность данного графа, но не содержит петель.
Расчет связующего дерева имеет место при подаче питания на мост и во всех случаях обнаружения изменения топологии. Для расчета необходима связь между мостами связующего дерева, которая осуществляется через сообщения конфигурации (иногда называемые протокольными информационными единицами моста - bridge protocol data units, или BPDU).
Сообщения конфигурации содержат информацию, идентифицирующую тот мост, который считается корневым (т.е. идентификатор корневого моста), и расстояние от моста-отправителя до корневого моста (затраты корневого тракта). Сообщения конфигурации также содержат идентификаторы моста и порта моста-отправителя, а также возраст информации, содержащейся в сообщении конфигурации.
Мосты обмениваются сообщениями конфигурации через регулярные интервалы времени (обычно 1-4 сек). Если какой-нибудь мост отказывает (вызывая изменение в топологии), то соседние мосты вскоре обнаруживают отсутствие сообщений конфигурации и инициируют пересчет связующего дерева.
Все решения, связанные с топологией ТВ, принимаются логически. Обмен сообщениями конфигурации производится между соседними мостами. Центральные полномочия или администрация управления сетевой топологией отсутствуют.
12) протокол стп
Назначение протокола STP (Spanning Tree Protocol)
Добрый день дорогие читатели! Сегодня мы с вами поговорим о протоколе, который функционирует на большинстве серьезных коммутаторов, но о важной и неприметной работе которого знают далеко не все, а именно о протоколе STP (Spanning Tree Protocol, Протокол связующего дерева). В данной статье мы поговорим о его назначение, а в следующих статьях мы поговорим о его настройке и принципах его функционирования.
Как всегда, рассматривать работу протокола STP мы будем на конкретном примере, а именно на примере топологии сети представленной на рисунке ниже:

Топология содержащая резервные каналы
И так, пусть у нас есть сеть содержащая резервные пути распространения фреймов (закольцованная сеть), и пусть один из компьютеров сети, например PC0, посылает в данную сеть широковещательный фрейм. Что же произойдет в данном случае? Данный фрейм будет передан на коммутатор Switch0, который в свою очередь передаст полученный фрейм через все свои активные порты, кроме того через который он поступил на коммутатор (а именно через Gig0/1 и Gig0/2). Фрейм поступит на коммутаторы Switch1 иSwitch3, они поступят аналогичным образом и передадут фрейм через порты Fast0/1,Gig0/1 и Fast0/1, Gig0/2. Судьба фреймов поступивших на хосты нас не интересует, а вот о фреймах поступивших на коммутатор Switch2 поговорим далее. На коммутатор Switch2 поступает сразу две копии одного фрейма, одна через интерфейс Gig0/1, другая через интерфейс Gig0/2. Копия поступившая через интерфейс Gig0/1, будет передана через интерфейсы Gig0/2 и Fast0/1. А копия поступившая через интерфейс Gig0/2 будет передана через интерфейсы Gig0/1 и Fast0/1. Судьба фреймов отправленных на хосты нас опять же не интересует. А вот фреймы отправленные далее на коммутаторы, как вы уже наверное понимаете поступают на коммутаторы Switch1 и Switch3, обрабатываются стандартным образом, и как вы уже наверное догадались возвращаются обратно на коммутатор Switch0, но уже не через интерфейс Fast0/1, как это было в начале, а через интерфейсы Gig0/1 и Gig0/2. Как легко догадаться коммутатор Switch0 обработает эту пару фреймов, точно так же как это делал коммутатор Switch2, когда на него поступало две копии фреймов, и фреймы будут отправлены далее по кольцу. Данная циркуляция фреймов по замкнутому контуру будет продолжаться бесконечно до тех пор пока не откажет один из коммутаторов, их портов или каналов между ними (Это происходит из за того, что у фрейма, в отличие от IP пакета, в заголовке отсутствует поле TTL, отвечающее за время его жизни. Если бы у нас циркулировал IP пакет по кольцевому маршруту составленному из маршрутизаторов, то рано или поздно он бы был отброшен, так как его поле TTL исчерпало бы себя).
Циркуляция фреймов в топологии имеющей резервные каналы
Данное явление бесконечной циркуляции фреймов по замкнутым кольцевым топологиям порождает сразу несколько проблем. Во первых в сети многократно передаются совершенно никому не нужные фреймы, которые занимают полезную пропускную способность сети, причем если коммутаторы и связывающие их каналы функционируют исправно, то эти фреймы никуда не деваются и их количество только растет со временем. Во вторых из за данной циркуляции фреймов, возникают ошибки в построении таблицы коммутации коммутаторов. Как вы наверное помните коммутаторы просматривают заголовки входящих фреймов и анализируют поле содержащее адрес их отправителя. Если MAC адрес, указанный в заголовке, отсутствует в таблице коммутации коммутатора то он добавляется в нее и устанавливается соответствие между портом коммутатора и MACадресом. Если же фрейм с аналогичным MAC адресом приходит с другого порта коммутатора, то запись в таблице коммутатора обновляется и
составляется новое соответствие |
между MAC адресом и портом |
коммутатора. Разберем это на |
примере. Пусть |
хост PC0 имеет MAC адрес MAC0. |
Когда широковещательный |
фрейм от данного хоста |
поступает на |
коммутатор Switch0, то он создает в своей таблице коммутации запись видаMAC0 - Fast0/1. Но как мы уже разбирали ранее коммутатор Switch0 передает поступивший на него широковещательный фрейм в кольцо, и через какое то
время данный фрейм поступит на него обратно, но уже через интерфейс Gig0/1 и Gig0/2. Будем считать что фрейм сначала вернулся через интерфейс Gig0/1. В заголовке фрейма все еще содержится MAC адрес хоста PC0. Коммутатор видит знакомый ему MAC адрес в заголовке, но он так же видит что данный фрейм пришел не из порта Fast0/1, а из порта Gig0/1, поэтому коммутатор обновляет запись в таблице коммутации с MAC0 - Fast0/1 на MAC0 -Gig0/1. Что как вы понимаете является не верным. Если в данный момент на коммутаторSwitch0 поступит фрейм предназначенный для хоста PC0, то он ошибочно будет передан не через интерфейс Fast0/1, а через интерфейс Gig0/1, что как уже можно догадаться приведет к проблемам коммутации.
Для устранения зацикливания фреймов в сетевых топологиях имеющих резервные маршруты был разработан протокол STP(Spanning Tree Protocol, Протокол связующего дерева). Который функционирует довольно просто - он блокирует передачу фреймов на одном из активных интерфейсов входящих в кольцо коммутаторов, тем самым разрывая кольцо и превращая его в древовидную топологию, для которой проблемы связанные с бесконечной циркуляцией фреймов не свойственны.
Если вы соединяли несколько коммутаторов в Packet Tracer и образовывали при этом кольцо, то вы наверное видели что один из портов на одном из коммутаторов так и не окрашивался в зеленый цвет, и так и оставался оранжевым. Поздравляю - вы наблюдали работу протокола STP! А тот порт который остался оранжевым и есть тот отключенный порт.
Стоит отметить что протокол STP блокирует определенный порт коммутатора не на все время существования сети, а только до изменений в ее топологии. Например если в топологии представленной на рисунках данной статьи оборвать канал между коммутаторами Switch0 и Switch3, то произойдет повторная работа протокола STP для вновь образовавшейся топологии и порт Gig0/2 коммутатор Switch1 включится через некоторое время, для восстановления связности сети.
Так же стоит отметить что во время своей работы протокол STP не отключает порт, а именно блокирует его. В этом можно убедиться выполнив на коммутаторе, имеющем заблокированный порт, команду show ip interface brief. В графах Status и Protocol будетUP, что говорит о том, что порт включен и исправно функционирует. А вот если мы выполним команду show spanning-tree interface <название интерфейса> то в графе Stsможно будет увидеть состояние порта в протоколе STP. Если порт не заблокирован состояние будет - FWD, а если заблокирован BLK. Так же для получения аналогичной информации о всех интерфейсах коммутатора можно выполнить команду show spanning-tree active.