

IIS_zachet
.pdfобщее правило комбинирования, по которому вычисляется коэффициент определенности посылки,
заключается в том, что коэффициент определенности дизъюнкции равен коэффициенту ее сильнейшей части, то есть ct(e1 или e2)= max(ct (e1), ct(e2)).
В случае, когда используются два правила для поддержки, например:
ЕСЛИ (е1) ТО (с ) ct(заключения)=0.9
ЕСЛИ (e2) ТО (с ) ct(заключения)=0.8
Был предложен следующий механизм :
ctotal= коэффициент определенности из правила 1 + коэффициент определенности из правила 2
– (коэффициент определенности из правила 1) *(коэффициент определенности из правила 2)
При вычислении итоговых коэффициентов необ ходимо учитывать знаки. В EM YCIN был предложен следующий механизм.
1.если оба коэффициента определенности по ложительны : ctotal= ct1 + ct 2 – ct1*ct2;
2.если оба коэффициента определенности о трицательны : ctotal= ct1 + ct 2 + ct1*ct2;
3.когда отрицателен один коэффициент: ctotal= (ct 1 + ct2)/ (1 – min(abs(ct1),abs(ct2));
4.когда одна определенность равна +1, а другая –1: ctotal= 0.
Помимо использования коэффициентов уверенности, в литературе опи саны и иные подхо ды, альтернативные вероятностному. В частности, много внимания уделяется нечеткой логике (fu zzy logic) и теории функций доверия
(belieffunctions), что положило начало одной из ветвей ис кусственного интеллекта — мягкие вычисления (soft computing).
Применение биполярных коэффициентов определенности может привести к нереальным результатам, если правила сформулированы неточно, поэтому ввели еще о дно ограничение на правила — обратимость.
Все правила попадают в о дну из дву х очень важных ка тегорий. Правила первой категории — обратимые.
Одной из характеристик такого правила является его применимость к любому вероятностному значению, которое может быть связано с посылкой. Правила второй ка тегории считаются необратимыми. Эти правила «работают» только при положительных значениях посылках. Если же ее значение отри цательно, правило при менять нельзя.
Рассмотрим правила:
1.Если э то последняя модель компьютера, то в нем есть встроенный модем.
2.Если э то последняя модель компьютера, то в нем есть дисковод.
Первое правило сохраняет свое значение, когда и посылка , и заключение отрицательны. « Если
это непоследняя модель компьютера, то в нем нет встроенного модема». Значит э то правило обратимо.
Второе же правило теряет смысл при отрицании посылки и заключения. « Если это не последняя модель компьютера, то в нем нет дисковода». Второе правило необратимо.
При создании правил необ ходимо всегда пр оверять их на обратимость и соответствующим образом помечать. Например
ЕСЛИ (е1) ТО (с 1) ct(заключения)=0.9 (nrev)
ЕСЛИ (e2) ТО (с 2) ct(заключения)=0.8 (rev)

17. Проблемы неопределенности в экспертных системах. Байесовское оценивание. Теорема Байеса как основа управления неопределенностью.
Неопределенность знаний в экспертных системах
При решении проблем част о приходит ься вст речат ься с множест вом источников неопределенности используемой информации, но в большинст ве случаев их можно разделит ь на две кат его рии: недост аточно полное знание предметной област и и недост аточная информация о
конкретной ситуации.
Теория предмет ной област и (т.е. наши знания об этой области) может быт ь неясной или неполной: в ней могут использоват ься недо ст аточно четко сформулированные концепции или недост аточно изученные явления. Например, в диагност ике психических заболеваний сущест вует несколько от личающихся т еорий о происхождении и симпт омат ике шизофрении.
Неопределенност ь знаний приводит к т ому, что правила влияния даже в прост ых случаях не всегда дают корректные результ ат ы. Располагая неполным знанием, мы не можем уверенно предсказат ь, какой эффект даст то или иное дейст вие. Например, т ерапия, использующая н овые препарат ы, довольно част о дает совершенно неожиданные результ ат ы. И, наконец, даже когда мы располагаем дост аточно полной т еорией предмет ной област и, эксперт может посчит ат ь, что эффективнее использоват ь не точные, а эвристические методы. Так , мет одика устранения неисправности в электронном блоке пут ем замены подозрит ельных узлов оказывает ся значит ельно более эффект ивной, чем скрупулезный анализ цепей в поиске дет али, вышедшей из ст роя.
Но помимо неточных знаний, неопределенност ь может быт ь внесена и неточными или ненадежными данными о конкрет ной ситуации. Люб ой сенсор имеет ограниченную разрешающую способность и отнюдь не стопроцентную надежност ь. При сост авлении от четов могут быть допущены ошибки или в них могут попасть недостоверные сведения. На практ ике далеко не всегда можно получит ь полные от вет ы на пост авленные вопросы, и хотя можно воспользоват ься различного рода дополнит ельной информацией о пациент е, например с помощью дорогостоящих процедур или хирургическим пут ем, т акие методики используют ся крайне редко из -за высокой стоимости и рискованност и. Помимо всего прочего, существует еще и фактор времени. Не всегда есть возможност ь быстро получит ь необходимые данные, когда сит уация требует принят ия срочного решения. Если работ а ядерного реактора вызывает подозрение, вряд ли кто-нибудь будет ждат ь окончания всего комплекса проверок , прежде чем принимат ь решение о его ост ановке.
Суммируя все сказанное, от метим, чт о эксперт ы пользуются нет очными мет одами по двум главным причинам:
точных методов не сущест вует;
точные методы сущест вуют , но не могут быт ь применены на практ ике из-за отсутст вия необходимого объема данных или невозможности их накопления по соображениям ст оимости, риска или из-за отсутст вия времени на сбор необходимой информации.
Большинство исследоват елей, занимающихся проблемами искусст венного инт еллект а, давно пришли к единому мнению, что неточные методы играют важную роль в разработке экспертных сист ем, но много споров вызывает вопрос, какие именно методы должны использоват ься . До последнего времени многие соглашались с ут верждениями Мак-Карти и Хейеса, что т еория вероят ности не являет ся адекват ным инструментом для решения задач предст авления неопределенност и знаний и данных. Выдвигались следующие аргумент ы в пользу т акого мнения:
т еория вероят ности не дает от вет а на вопрос, как комбинироват ь вероят ности с количест венными данными;
назначение вероят ности определенным событиям требует информации, которой мы просто не располагаем. Другие исследоват ели прибавляли к этим аргумент ам свои:
непонятно, как количест венно оцениват ь т акие част о встречающиеся на практике понят ия, как «в большинст ве случаев», «в редких случаях», или т акие приблизит ельные оценки, как «старый» или «высокий»;
применение т еории вероят ности требует «слишком много чисел», что вынуждает инженеров дават ь т очные оценки т ем парамет рам, кот орые они не могут оценить;
обновление вероят ностных оценок обходит ся очень дорого, поскольку т ребует большого объема вычислений.
Все эти соображения породили новый формальный аппарат для работ ы с неопределенност ями, который получил название нечеткая логика или т еория функций доверия. Этот аппарат широко использует ся при решении задач искусственного инт еллект а, и особенно при построении экспертных сист ем.
Полная вероятность и формула Байеса
Набор событий  , хотя бы одно из которых обязательно (с единичной вероятностью) наступит в результате испытания, называется полным. Это означает, что набор таких событий исчерпывает все возможные варианты исходов . Формально в рамках
, хотя бы одно из которых обязательно (с единичной вероятностью) наступит в результате испытания, называется полным. Это означает, что набор таких событий исчерпывает все возможные варианты исходов . Формально в рамках
аксиоматического подхода это означает, что  . Если эти события несовместны, то в рамках классического определения это означает, что сумма количеств элементарных событий, благоприятствующих тому или иному событию, равно общему количеству равновозможных исходов .
. Если эти события несовместны, то в рамках классического определения это означает, что сумма количеств элементарных событий, благоприятствующих тому или иному событию, равно общему количеству равновозможных исходов .

Пусть имеется полный набор попарно несовместных событий  . Тогда для любого события
. Тогда для любого события  верна следующая формула расчета его вероятности (формула полной вероятности):
верна следующая формула расчета его вероятности (формула полной вероятности):
Тогда вышеописанную формулу Байеса с учетом полной вероятности можно записать в следующем виде:
Теорема Байеса как основа управления неопределенностью
Приведенные выше соотношения предполагают определенную связь между теорией вероятностей и теорией множеств. Если А и В являются непересекающимися множествами, то объединение множеств соо тветствует сумме вероятностей, а пересечение - произведению вероятностей, т. е.
р(А + В) = р(А) + р(В) и р(А * В) = р(А) * р(В).
Без предположения независимости эта связь является неточной и формулы должны содержать дополнительные члены включения и исключения (так например, р(А+В)=р(А)+р(В)-р(АВ). Продолжая теоретико - множественное обозначение, В можно записать как:
Так как э то объединение явно непересекающееся, то:
р(В)= р(В|А) р(А) + р(В|  )р(В).
)р(В).
Возвращаясь к обозначению событий, а не множеств, последнее равенство может быть по дставлено в правило Байеса:
. |
(3.4) |
Это равенство является основой для использования теории вероятности в управлении неопределенностью. Оно обеспечивает путь для получения условной вероятности события В при условии А. Э то соотношение позво ляет Э С управлять неопределенностью и «делать вывод вперед и назад».
18.Теории нейронных вычислений. Задачи, решаемые с помощью нейронных вычислений. Способы реализации. Персептрон.
Нейронные сети – это сети, состоящие из связанных между собой простых элементов формальных нейронов. Большая часть работ по нейроинформатике посвящена переносу различных алгоритмов решения задач на такие сети. В основу концепции по ложена идея о том, что нейроны можно моделировать довольно простыми автоматами, а вся сложность мозга , гиб кость его функционирования и другие важнейшие качества опре деляются связями между нейронами. Каждая связь представляется как совсем простой элемент, служащий для передачи сигнала, или кратко – «Структура связей всѐ, свойства элементов нич то».
Совокупность идей и научно-техническое направление, определяемое описанным представлением о мозге, называется коннекционизмом. С реальным мозгом все э то соотносится примерно так же, как карикатура или шарж со своим прототипом. Важно не буквальное соответствие оригиналу, а проду ктивность технической идеи.
С коннекционизмом тесно связан следующий б лок идей:
однородность системы (э лементы о динаковы и чрезвычайно просты, все определяется структурой связей);
надежные системы из ненадежных элементов и «анало говый ренессанс» использование простых аналоговых элементов;
«голографические» системы при разрушении случайно выбранной части система со храняет свои свойства.
Предполагается, ч то широкие возможности систем связей компенсируют бедность выбора элементов, их ненадежность и возможные разрушения части связей.
Для описания алгоритмов и устройств в нейроинформатике выработана специальная «схемотехника», в которой элементарные устройства (сумматоры, синапсы, нейроны и т.п.) объединяются в сети, предназначенные для решения задач. Для многих начинающих кажется неожиданным, что ни в аппаратной реализации нейронных сетей, ни в профессиональном программном обеспечении эти элементы вовсе не обязательно реализуются как отдельные части или б локи. Используемая в нейроинформатике идеальная схемотехника представляет собой особый язы к описания нейронных сетей и их обучения. При программной и аппаратной реализации выполненные на этом языке описания переводятся на более подхо дящие языки другого уровня.
Самый важный элемент нейросистем адаптивный сумматор, который вычисляет скалярное произведение вектора входного сигнала x на вектор параметровa. Адаптивным он называется из-за наличия вектора настраиваемых параметров a.
Нелинейный преобразователь сигнала по лучает скалярный вхо дной сигна л x и переводит его в заданную нелинейную функцию f(x).
Точка ветвления служит для рассылки о дного сигнала по неско льким адресам. Она получает скалярный вхо дной сигнал x и передает его на все свои выхо ды.
Стандартный формальный нейрон состоит из вхо дного сумматора, нелинейного преобразователя и точки ветвления на выходе .
Линейная связь синапс отдельно от сумматоров не встречается, о днако для неко торых рассуждений бывает удобно выделить э тот э лемент. Он умножает входной сигнал x на «вес синапса» a.
Нейронные сети можно строить как угодно, лишь бы вхо ды получали какие -нибудь сигналы . Обычно используется несколько стандар тных ар хитектур, из которых путем вырезания лишнего или (реже ) добавления строят большинство используемых сетей. Для начала следует определить, как бу дет согласована работа различных нейронов во времени. Как только в системе появляется более о дного элемента, встает вопрос о синхронизации функционирования. Для обычных программных имитаторов нейронных сетей на цифровых Э ВМ этот вопрос не акту ален только из-за свойств основного компьютера, на котором реализуются нейронные сети. Для других способов реализации он весьма важен. Мы же будем рассматривать только те нейронные сети, которые синхронно функционируют в дискретные моменты времени: все нейроны срабатывают «разом».
^ Слоистые сети. Здесь нейроны расположены в несколько слоев. Нейроны первого слоя получают входные сигналы , преобразуют их и через точки ветвления передают нейронам второго слоя. Далее срабатывает второй слой и т.д. до слоя k, который выдает выхо дные сигналы для интерпретатора и пользователя. Если противное не оговорено, то каждый выхо дной сигнал слоя i подается на вхо д всех нейронов слоя i+1. Число нейронов в каждом слое может быть любым и никак заранее не связано с количеством нейронов в других слоях. Стандартный способ подачи вхо дных сигналов: все нейроны первого слоя получают каждый вхо дной сигнал. Особенно широко распространены трехслойные сети, в которых каждый слой имеет свое наименование: первый входной, второй скрытый, тр етий выходной.
^ Полносвязные сети. З десь каждый нейрон передает свой выхо дной сигнал остальным нейронам, включая самого себя. Выходными сигналами сети могут быть все или неко торые выхо дные сигналы нейронов после нескольких тактов функционирования сети. Все вхо дные сигналы подаются всем нейронам.
Элементы слоистых и полносвязных сетей могут выбираться по -разному. Существует, впрочем, стандар тный выбор: нейрон с адаптивным нео днородным линейным сумматором на входе.
Для по лносвязной сети вхо дной сумматор нейрона фактически распадается на два : первый вычисляет линейную функцию от вхо дных сигналов сети, второй линейную функцию от выхо дных сигналов других нейронов, полученных на предыдущем шаге.
Функция активации нейронов (характеристическая функция) это нелинейный преобразователь выхо дного сигнала сумматора. Если функция одна для всех нейронов сети, то сеть называют однородной (гомогенной). Если же характеристическая функция зависит еще от одного или нескольких параметров, значения которых меняются от нейрона к нейрону, то сеть называют нео днородной (гетерогенной).

Составлять сеть из нейронов стандартного вида не обязательно. Слоистая или полносвязная ар хитектуры не налагают существенных ограничений на участвующие в них э лементы. Единственное жесткое требова ние, предъявляемое архитектурой к э лементам сети, э то соответствие размерности вектора вхо дных сигналов элемента (она определяется архитектурой) числу его входов. Если по лносвязная сеть функционирует до получения о твета заданное число тактов k, то ее можно представить как частный случай k-слойной сети, все слои которой одинаковы и каждый из них соответствует такту функционирования полносвязной сети.
Первый бионический бум. Перцептрон
История исследования нейронных сетей испытывала взлеты и падения. Первый всплеск энтузиазма был в 50-60-х годах. Его можно связать с работами Дж. фон Неймана по концептуальному сравнительному анализу работы биологических нейронных сетей и компьютеров [2] и по разработке принципов построения надежных вычислительных систем из ненадежных компонент (фактически формальных нейронов) [3] и с работами Ф.Розенб лата по перцетронам [4]. Работы по перцептронам – наиболее значимое направление исследований первого бионического бума.
Следуя в основном изложению, представленному в книге С.В. Фомина и М.В. Беркенблита "Математические проблемы в биологии" [5]. Перцепторон состоит из элементов 3 -х типов: S-элементов, A-э лементов и R-элемента (Рис.3) . S-э лементы это – слой рецепторов. Эти рецепторы соединены с A -элементами, с помощью тормозных или возбуждающих связей. Каждый рецептор может нахо диться в о дном из дву х состояний – покоя или возбуждения. A- элементы представляют собой сумматоры с порогом (т.е. формальные нейроны). Это означает, что A -элемент возбуждается, если алгебраическая сумма возбуждений, приходящих к нему от рецепторов, превышает определенную величину – его порог. При этом сигнал о т рецептора, прихо дящий по возбуждающей связи, считается положительным, а приходящий по тормозной связи – о трицательным. Сигналы от возбудившихся A -элементов передаются в сумматор R, причем сигнал о т i -го ассоциативного э лемента передается с коэффициентом ki.
Рис. 3. Схема перцептрона. Система связей между рецепторами S и A -элементами, так же как и пороги A-элементов выбираются неко торым случайным, но фиксированным образом, а обучение состоит лишь в изменении коэффициентов ki. Считаем, что мы хо тим научить перцептрон разделять два класса объектов, и по требуем, чтобы при предъявлении объектов первого класса выход перцептрона был по ложителен, а при предъявлении объектов второго класса – отрицательным. Начальные коэффициенты ki полагаем равными нулю. Далее предъявляем обучающую выборку: объекты (например, круги либо квадраты) с указанием класса, к которым они принадлежат. Показываем перцетрону объект первого класса. При этом некоторые A-элементы возбудятся. Коэффициенты ki , соответствующие этим возбужденным элементам, увеличиваем на 1. Затем предъявляем объект второго класса и коэффициенты ki тех A - элементов, которые возбудятся при этом показе, уменьшаем на 1. Этот процесс продолжим для всей обучающей выборки. В результате обучения сформируются значения весов связей ki.
После обучения перцептрон готов работать в режиме распознавания. В э том режиме перцептрону предъявляются "не знакомые" перцептрону объекты, и перцептрон должен установить, к какому классу они принадлежат. Рабо та
перцептрона состоит в следующем: при предъявлении объекта возбудившиеся A |
- элементы передают сигнал R - |
|
элементу, |
равный сумме соответствующих коэффициентов ki. Если э та сумма положительна, то принимается |
|
решение, |
что данный объект принадлежит к первому классу, а если она |
отрицательна – то второму. |

Исследования перцептронов показали, что перцептроны способны обучаться, хотя способности их обучения довол ьно ограничены. Справедлива теорема о сходимости перцептрона, согласно которой независимо от начальных значений коэффициентов и порядка показа образцов при обучении перцептрон за конечное число шагов научится различать два класса объектов, если то лько существуют такие значения. По дчеркнем, что теорема ничего не говорит о том, какие классы могут быть разделены.
Исследования также показали, что слабые стороны перцептрона (в частности большое время обучения) в значительной степени связаны со случайностью связе й между его элементами. Однако эта конструктивная особенность обеспечивает перцептрону и положительное качество – надежность: выхо д из строя заметного числа элементов перцептрона слабо сказывается на качестве его работы (Рис.4).
Первые успехи исследованиям перцептронов других нейросетей вызвал взрыв активности и энтузиазма. М. Минский, Ф.Розенб лат, Б. Уидроу и другие разработали ряд искусственных нейронных сетей. В течение неко торого времени казалось, что ключ к интеллекту найден, и воспроизведение человече ского мозга является лишь вопросом конструирования достаточно большой сети.
Рис.4. Поведение перцептрона при выходе из строя ассоциативных э лементов. По оси ординат – процент правильных ответов, по оси абсцисс – до ля выключенных ассоциативных э лементов.
Но эта иллюзия вскоре рассеялась. Возможности перцептронов оказались довольно о граниченными. Серьезный математический анализ перцептронов был проведен М .Минским и С. Пейпертом [6]. Они, в частности, показали, ч то задачи, ко торые в принципе могут быть решены перцептроном могут потребовать нереально больших времен или нереально большой памяти. Например, для различения некоторых классов объектов коэффициенты части ассоциативных э лементов до лжны быть столь велики, что для хранения их в вычислительной машине п отребовался бы больший объем памяти, чем для того, ч тобы просто запомнить все конкретные объекты этих дву х классов.
Критика перцептронов М. Минским (а он – один из признанных авторитетов в теории искусственного интеллекта), а также сравнительно небольшой прогресс нейрокибернетики 50-60 – х го дов привели к тому, что период энтузиазма сменился периодом спада активности исследований искусственных нейронных сетей. Многие исследователи ушли в те области, ко торые им показались более привлекательными.
Только немногие кибернетики (Т. Ко хонен, С. Гроссберг, Дж.Андерсон, Г.С. Бриндли, Д. Мар, В.Л.Дунин - Барковский, А.А.Фролов и др.) продолжали исследования нейросетей в 70 -х го дах.
19.Нейронная сеть Хопфилда.
Сети Хопфилда
Нейронные сети могут иметь обратные связи (то есть связи от выхо дов некоторых нейронов ко входам других нейронов), а могут не иметь их. Сети Хопфилда – э то нейронные сети с обратными связями, причем выхо д каждо го нейрона связывается со вхо дами всех остальных нейронов. Так как сети собратными связями имеют пу ти, передающие сигналы от выхо дов к входам, то о тклик таких сетей является динамическим, т. е. после приложения нового вхо да вычисляется выход и, передаваясь по сети обратной связи, модифицирует вход. Затем выхо д повторно вычисляется, и процесс повторяется снова и снова. Для устойчивой сети последовательные итерации приводят к все меньшим изменениям выхода, пока в конце концов выхо д не становится постоянным. Для многих сетей процесс никогда не заканчивается, такие сети называют неустойчивыми. Неустойчивые сети обладают интересными свойствами и изучались в качестве примера хао тических систем. Никто не мог предсказать, какие из сетей буду т устойчивыми, а какие буду т находиться в постоянном изменении. Более то го, проблема представлялась сто ль трудной, что многие исследователи были настроены пессимистически относительно возможности ее решения. К счастью, была получена теорема, описавшая подмножество сетей с обратными связями, выходы ко торых в конце концов достигают устойчивого состояния. Э то замечательное достижение открыло дорогу дальнейшим исследованиям, и сегодня многие ученые занимаются исследованием сложного поведения и возможностей этих

систем. Дж. Хопфилд сделал важный вклад как в теорию, так и в применение систем с обратными связями. Поэтому некоторые из конфигураций известны как сети Хопфилда. Остановимся на важном частном случае нейросетевой архитектуры, для которой свойства устойчивости подробно исследованы. На рис. 5. показана с еть с обратными связями, состоящая из дву х слоев. Способ представления несколько о тличается о т использованного в работе Хопфилда и других схо дных, но эквивалентен им с функциональной точки зрения. Ну левой слой не выполняет вычислительной функции, а лишь распределяет выхо ды сети обратно на вхо ды. Каждый нейрон первого слоя вычисляет взвешенную сумму своих вхо дов, давая сигнал NET, ко торый затем с помощью нелинейной
функции F преобразуется в сигнал OUT. Эти операции схо дны с нейронами других сетей.
^ Рис. 5. Сеть Хопфилда.
Состояние сети — э то просто множество текущих значений сигналов OUT о т всех нейронов. В первоначальной сети Хопфилда состояние каждого нейрона менялось в дискретные случайные моменты времени, в последующем - состояния нейронов могли меняться одновременно. Так как выходом бинарного нейрона может быть то лько но ль или единица (промежуточных уровней нет), то текущее состоян ие сети является двоичным числом, каждый бит ко торого является сигналом OUT неко торого нейрона.
Задачи, решаемые данной сетью, как правило, формулируются следующим образом. Известен некоторый набор двоичных сигналов (изображений, оцифровок звука , прочих данных, описывающих некие объекты или характеристики процессов), ко торые считаются образцовыми. Сеть должна уметь из произвольного неидеального сигнала, поданно го на ее вхо д, выделить ("вспомнить" по частичной информации) соответствующий образец (если такой есть) или "дать заключение" о том, что вхо дные данные не соответствуют ни одному из образцов. В общем случае, любой сигнал может быть описан
вектором  , n — число нейронов в сети и размерность вхо дных и выхо дных векторов. Каждый элемент
, n — число нейронов в сети и размерность вхо дных и выхо дных векторов. Каждый элемент  равен либо 1, либо 0. Обозначим вектор, описывающий k-й образец,
равен либо 1, либо 0. Обозначим вектор, описывающий k-й образец,
через  , а его компоненты, соответственно, —
, а его компоненты, соответственно, —  , k = 0…m– 1, m— число образцов. Когда сеть распознaет (или "вспомнит") какой-либо образец на основе предъявленных ей данных, ее выходы будут
, k = 0…m– 1, m— число образцов. Когда сеть распознaет (или "вспомнит") какой-либо образец на основе предъявленных ей данных, ее выходы будут
содержать именно его, то есть Y =  , где Y - вектор выхо дных значений сети:
, где Y - вектор выхо дных значений сети:
 . В противном случае, выхо дной вектор не совпадет ни с одним образцовым.
. В противном случае, выхо дной вектор не совпадет ни с одним образцовым.
Если, например, сигналы представляют собой некие изображения, то, отобразив в графическом виде данные с выхо да сети, можно будет увидеть картинку, по лностью совпадающую с одной из образцовых (в случае успеха ) или же "вольную импровизацию" сети (в случае неудачи).
На стадии инициализации сети весовые коэффициенты синапсов устанавливаются следующим образом:

Здесь i и j — индексы , соответственно, предсинаптическо го и постсинаптического нейронов;  ,
,  — i-й и j-й элементы вектора k -го образца.
— i-й и j-й элементы вектора k -го образца.
Алгоритм функционирования сети следующий (p— номер итерации):
1.
На входы сети подается неизвестный сигнал. Фактически его ввод осуществляе тся непосредственной установкой значений аксонов:
поэтому обозначение на схеме сети вхо дных синапсов в явном виде носит чисто условный характер. Ноль в скобке справа от  означает нулевую итерацию в цикле работы сети.
означает нулевую итерацию в цикле работы сети.
2.
Рассчитывается новое состояние нейронов:
и новые значения аксонов
где f — активационная функция в виде скачка.
3.
Проверка, изменились ли выхо дные значения аксонов за последнюю итерацию. Если да — переход к пункту 2, иначе (если выходы стабилизировались) — конец процедуры. При э том выходной вектор представляет собой образец, наилучшим образом сочетающийся с вхо дными данными.
20.Нейронная сеть Хемминга.
Сеть Хемминга – это о дна из наиболее многообещающих распознающих и классифицирующих нейронных сетей. В э той сети черно-белые изображения представляются в виде m-мерных бипо лярных векторов. Свое название она получила от расстояния Хемминга, которое используется в сети в мере сходства R изображений вхо дного и
эталонных, |
хранимых с помощью весов связей сети. Мера схо дства определяется соотношением |
R = m – Rx, |
(1) |
где m – число компонент вхо дного и эталонных векторов; Rx - расстояние Хемминга между векторами.
Определение 1. Расстоянием Хемминга между двумя двоичными векторами называется число компонент, в которых векторы различны.
В силу определения расстояния Хемминга мера сходства изображений(1) может быть задана и как число a компонент двоичных векторов, в которых они совпадают: R = a.
Запишем для биполярных векторов  и
и  их скалярное произведение через число совпадающих и отличающихся компонент:
их скалярное произведение через число совпадающих и отличающихся компонент:

(2)
где а – число одинаковых компонент векторов; d – число различных компонент векторов S и Z.
Поскольку т – размерность векторов, то m = a + d,следовательно, скалярное произведение (2) можно записать в виде
SZ = 2a – m.
Отсюда несложно по лучить:
(3)
Правую часть выражения (3) можно рассматривать как вхо дной сигнал нейрона, имеющего m синапсов с
весовыми коэффициентами  и смещением
и смещением  . Синапсы нейрона
. Синапсы нейрона
воспринимают m компонент входного вектора S = (s1, … , sm).Такая интерпретация правой части выражения (3) приводит к ар хитектуре нейронной по дсети, изображенной в нижней части рис. 1. Одни авторы сеть, изображенную на рис 1, называют сетью Хемминга, другие сетью Хемминга называют только ее нижнюю часть,
считая, ч то приведенная сеть состоит из дву х по дсетей –Хемминга и Maxnet.Мы будем придерживаться первой точки зрения.

Сеть Хемминга имеет m входных нейронов S1, …, Sm?, воспринимающих биполярные компоненты  вхо дных изображений
вхо дных изображений  Выхо дные сигналы S -элементов определяются соотношением
Выхо дные сигналы S -элементов определяются соотношением
(4)
т. е . выходной сигнал S-э лемента повторяет его вхо дной сигнал:
Каждый нейрон S j (j = |
) связан со вхо дом каждо го элемента Zk (k = |
). Веса э тих |
|
связей w 1k, …, wmk содержат информацию о k -м эталонном изображении |
|
: |
|
|
|
. |
(5) |
Функции активации Z-элементов описывается соотношением |
|
|
|
(6)
где Uвх. – вхо дной сигнал нейрона; k 1, Un |
– константы. |
При предъявлении входного изображения |
каждый Z-ней-рон рассчитывает свой вхо дной |
сигнал в соответствии с выражением вида (3):
(7)
и с помощью функций активации, определяет выхо дной сигнал  . Выхо дные
. Выхо дные
сигналы  Z-элементов являются вхо дными сигналами a1, …, anвер хней подсети, ко торой является сеть Maxnet. Функции активации нейронов Ap (p =
Z-элементов являются вхо дными сигналами a1, …, anвер хней подсети, ко торой является сеть Maxnet. Функции активации нейронов Ap (p =  ) и веса их связей задаются соотношениями
) и веса их связей задаются соотношениями
где 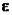 – константа , удовлетворяющая неравенствам 0 <
– константа , удовлетворяющая неравенствам 0 < 

 .
. Сеть функционирует циклически, динамика нейронов описывается итера -ционным выражением
Сеть функционирует циклически, динамика нейронов описывается итера -ционным выражением