

Генерация тестовых данных
Для тестирования выполнения запросов и оценки эффективности выбранных индексов необходимо, что бы в таблицах БД было количество записей, сопоставимое с тем, которое будет достигнуто (возможно, в течение нескольких лет) в ходе реальной эксплуатации системы. Один из способов решения этой задачи — использование генератора тестовых данных.
Существует достаточно много продуктов, осуществляющих генерацию данных для тестирования запросов к БД в ходе ее разработки, здесь можно упомянуть CASE-системы (например, SAP Sybase PowerDesigner), отдельные продукты (например, EMS Data Generator for SQL Server), а так же продукты, входящие в средства разработки (например, в Microsoft Vusual Studio).
Для генерации тестовых данных в SAP Sybase PowerDesigner необходимо:
(i) Создать источник данных ODBC (см. методические указания к лабораторной работе №3).
(ii) Выполнить реинжиниринг в SAP Sybase PowerDesigner: File\Reverse Engineer\Data Base…, после чего задать имя модели, выбрать СУБД, нажать Ok, выбрать созданный источник данных ODBC (в поле Using Data Source), установить соединение (Connect), нажать OK, выбрать таблицы и еще раз нажать OK..
(iii) Собственно сгенерировать тестовые данные: Database\Generate Test Data\Number of Rows, задать необходимое количество записей для каждой таблицы и нажать OK (рис. 1).
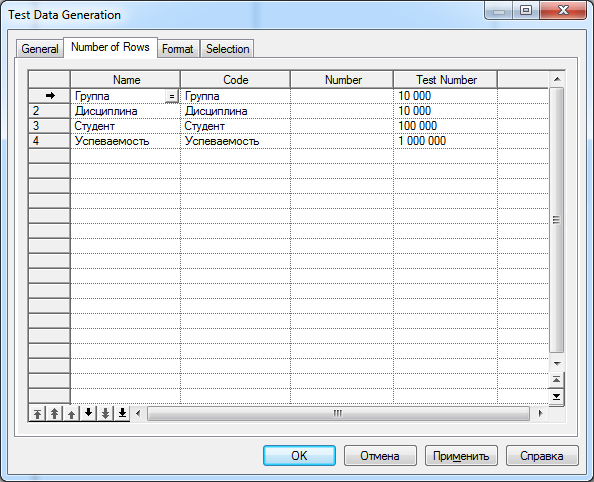
Рисунок 1.
Для тестирования запросов можно создать отдельную БД, один из способов сделать это — получить скрипт для создания БД, выполнив команды Задачи\Сформировать сценарии… из контекстного узла соответствующей БД в дереве объектов Management Studio, после чего ответить на вопросы мастера, получить скрипт и выполнить скрипт в новой БД.
При вставке тестовых данных следует учитывать, что добавление данных, содержащих значения полей identity возможно, если это предварительно разрешено директивой set identity_insert <имя таблицы> { on | off }.1
Для выполнения скриптов большого размера (миллионы insert into) можно воспользоваться утилитой командной строки sqlcmd, утилита имеет достаточно много параметров, если соединение с SQL-сервером установлено из Management Studio, достаточно указать имя БД и путь к файлу:
sqlcmd -d"Университет1" -i"d:\mydb\mssql2008\testdataУниверситет1.sql"
Анализ использования индексов
Решение об использовании индексов принимает оптимизатор запросов СУБД, проанализировать используется ли индекс и каким образом происходит его сканирование можно из планов выполнения запросов. Один из способов просмотра планов выполнения запросов — использование директивы:
set showplan_text { on | off }
go
или более подробно с помощью директивы:
set showplan_all { on | off }
go
В MS SQL директивы отображения планов отключают выполнение запросов, для выполнения запросов необходимо установить значения параметров в off.
Для графического отображения плана выполнения запроса используются команды меню Management Studio Запрос\Показать предполагаемый план выполнения и Запрос\Включить действительный план выполнения. В планах выполнения запросов отображается довольно много пиктограмм (http://msdn.microsoft.com/ru-ru/library/ms175913(SQL.105).aspx) и видов сообщений (http://msdn.microsoft.com/ru-ru/library/ms191158(SQL.105).aspx), об использовании индексов говорят сообщения{ clustered | nonclustered } index { seek | scan }, seek соответствует префиксному сканированию, а scan — сплошному.
Повлиять на решения, принимаемые планировщиком запросов относительно порядка соединения таблиц, использования индексов, алгоритмов выполнения соединений и др. можно с помощью подсказок — hints (http://msdn.microsoft.com/ru-ru/library/ms173815%28v=sql.105%29.aspx) (http://msdn.microsoft.com/ru-ru/library/ms173815%28v=sql.105%29.aspx).