

Выполнение репликации транзакций
Репликация выполняется автоматически, выполним вставку:
use main
go
insert into Студент (N_зач, ФИО, Группа) values (37, 'Волнушкин', '4831')
go
Так как группа 4831 относилась ко второму курсу, запись реплицируется в БД node. Вследствие того, что подписка была создана как немедленно объявляемая, для корректного выполнения репликации из БД node в БД main необходимо задать проверку подлинности SQL Server или Windows для пользователя, редактирующего подписчика (выполняется на подписчике в базе данных подписки):
use node
go
sp_link_publication 'AVB-XEON' , 'main' , 'Гастелло' , 1
go
В БД main таблица Оценка, не заполнялась, выполним вставку:
use node
go
insert into Оценка (N_зач, Код_УП, Оценка, Зачет, Дата)
values (34, 1, 5, 0, '2009/05/01')
go
insert into Оценка (N_зач, Код_УП, Оценка, Зачет, Дата)
values (36, 2, 4, 0, '2009/01/05')
go
После выполнения команд соответствующие строки появляются в БД main. Выполним модификацию:
use node
go
update Студент set ФИО = 'Строчков' where ФИО = 'Сморчков'
go
После выполнения команды изменение отражается в БД main.
Выполнение лабораторной работы
Реализовать в БД репликацию, включающую вертикальную и горизонтальную фрагментацию данных таблиц. Выполнить модификацию данных, иллюстрирующую работу репликации.
Содержание отчета
Содержание отчета:
— скрипты для создания объектов репликации;
— операторы модификации данных для тестирования репликации, наборы данных в таблицах.
Варианты заданий
Варианты заданий приведены в ПРИЛОЖЕНИИ.
Лабораторная работа 12 — Организация хранилищ данных
Хранилища данных
Создание и широкое внедрение корпоративных информационных систем (КИС), происходившее в конце прошлого века, привело к появлению парадоксальной ситуации: информация есть, информации много, но воспользоваться ею для анализа эффективности работы предприятия, решения других экономических и социальных аналитических задач достаточно сложно.
Существовало несколько причин такого положения дел, среди которых отмечались:
(i) несовместимость проектов отдельных подсистем КИС (наследие эпохи «стихийной автоматизации», когда отдельные подсистемы создавались различными разработчиками с применение различных СУБД и систем программирования);
(ii) плохую приспособленность существующих СУБД к выполнению аналитических запросов (выполнение сложного аналитического запроса к строго нормализованной базе данных требует выполнения соединений для большого количества таблиц и, как следствие, приводит к большим затратам времени на обработку запроса).
Ответом на данное положение дел со стороны разработчиков СУБД стала концепция хранилищ данных — DW (Data Warehouse) и появление специального класса серверов для реализации DW. Одним из первых подобных продуктов был Oracle Express Server, являвшийся многомерной СУБД для создания MDB (Multi-Dimensional Database), в котором физически хранение данных организовано в виде гиперкуба, имеющего N измерений (рис. 1).

Рис. 1.
В ячейках гиперкуба хранятся значения показателей, например объемы продаж в натуральном и денежном измерении, полученная прибыль, затраты и пр. для конкретных сочетаний – например, для данного продукта, проданного в определенном регионе за заданный временной промежуток. Измерения позволяют упорядочить данные в соответствии с хронологическими, географическими или другими классификационными признаками.
Альтернативное решение было предложено в Sybase IQ, где данные, рассматриваемые пользователем в виде гиперкуба, находились в реляционной БД, в которой использовались существенно отличающиеся механизмы (по сравнению с реляционными СУБД), такие как вертикальное хранение (сначала данные 1-го столбца таблицы, затем 2-го и т. д.) и Bitmap индексы.
Появление концепции хранилищ данных привело к разделению современных ИС на два основных класса (рис. 2):
(i) системы OLTP (On-Line Transaction Processing), решающие в основном оперативные («учетные») задачи;
(ii) СППР (системы поддержки принятия решений) или DSS (Decision Support System).
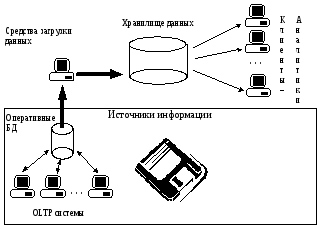
Рис. 2.
Системы OLTP реализуются на основе файл-серверных или клиент-серверных архитектур, имеют нормализованные структуры баз данных, предназначены для автоматизации повседневных задач, решаемых персоналом «нижнего» звена (учет клиентов, договоров, заказов, взаиморасчетов, запасов и пр.).
В отличие от OLTP-систем, системы DSS ориентированы на руководство «верхнего» звена — старших менеджеров, принимающих стратегические решения по проблемам развития корпорации.
Подход, основанный на использовании MDB для построения DSS, получил название OLAP (On-Line Analytical Processing) или MOLAP (Multi-dimensional OLAP), а альтернативный, основанный на реляционных СУБД — ROLAP (relational OLAP).
Ниже в таблице дается краткое сравнение OLTP- и OLAP-технологий.
Таблица 1.
Сравнение OLTP- и OLAP-систем
|
Признак |
OLTP |
OLAP |
|
Типы запросов |
Статистические (подсчет суммарных итогов) |
Аналитические (анализ тенденций, формирование прогнозов) |
|
Типы отчетов |
Стандартные (заранее регламентированные: за день, месяц, квартал, год и пр.) |
Произвольные, динамические (последовательности итеративно уточняемых отчетов) |
|
Уровень агрегации данных |
Детализированные данные |
В основном суммарные |
|
Возраст данных |
Оперативные и выгруженные из БД в архив |
Исторические за большие временные периоды |
|
Частота обновления, объем добавляемых данных |
Высокая, добавление небольшими порциями |
Низкая, загрузка больших информационных массивов, загруженные ранее данные не изменяются |
|
Упорядоченность данных |
Отсутствует |
Данные упорядочены хронологически и по другим измерениям |
|
Структура БД |
Нормализованная, большое количество связанных таблиц |
Ненормализованная, таблица фактов, ссылающаяся на несколько таблиц измерений (ROLAP) |
Системы, основанные на хранилищах данных, в последствии стали рассматривать как предназначенные для сбора, интеграции и аналитической обработки информации, накопленной в различных источниках, таких как: оперативные БД (БД OLTP-систем), «плоские» файлы с наборами данных, данные внешних источников (например, данные доступные в глобальных сетях) и др. Важную роль в таких системах играют метаданные (базы метаданных) — знания о структуре существующих баз данных и информационных источников, типе и формате хранимой информации, связях между информационными объектами, семантике информационных объектов и их атрибутов, ограничениях на значения данных и ссылочной целостности и пр. (рис. 3).
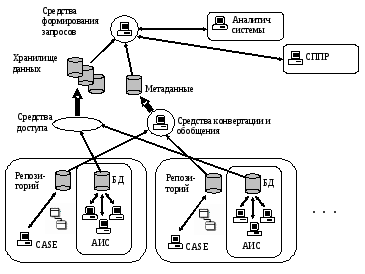 Рис. 3.
Рис. 3.
В настоящее время для организации хранилищ данных реализованы семейства продуктов (IBM Business Intelligence, Oracle Business Intelligence, SAP BusinessObjects и др.), обеспечивающие решение следующих групп задач:
(i) проектирование и реализация хранилища данных;
(ii) работа с метаданными, подготовка и загрузка информации в хранилище — ETL (Extract, Transform, Load);
(iii) собственно выполнение аналитических запросов.
Процесс проектирования и реализации хранилища данных включает несколько этапов:
(i) Анализ типов запросов, составление словаря: формулируются типичные запросы различных категорий пользователей, выявляются состав интересующих показателей, степень детализации информации и пр.
(ii) Анализ информационных источников: собирается информация о структурах имеющихся баз данных, строится/анализируется нормализованная модель данных.
(iii) Выбор измерений: выбираются признаки по которым необходимо строить «срезы» данных для различных категорий пользователей – склады, временные периоды, статьи затрат, виды продукции и пр.
(iv) Построение иерархии измерений: анализируются выбранные измерения, и строится их иерархия (типовыми иерархическими структурами являются: временные – день, неделя, месяц, квартал, год; географические – объект, район, город, регион, страна).
(v) Построение таблиц фактов: определяется состав фактических показателей для различных сочетаний и/или уровней измерений.