

Первичный статистический анализ:
Первичная статистическая обработка нацелена на упорядочивание информации об объекте и предмете изучения. На этой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы. Первично обработанные данные, представленные в удобной форме, дают исследователю в первом приближении понятие о характере всей совокупности данных в целом: об их однородности – неоднородности, компактности – разбросанности, четкости – размытости и т. д. Эта информация хорошо считывается с наглядных форм представления данных и дает сведения об их распределении.
В ходе применения первичных методов статистической обработки получаются показатели, непосредственно связанные с производимыми в исследовании измерениями.
К основным методам первичной статистической обработки относятся: вычисление мер центральной тенденции и мер разброса (изменчивости) данных.
Первичный статистический анализ всей совокупности полученных в исследовании данных дает возможность охарактеризовать ее в предельно сжатом виде и ответить на два главных вопроса: 1) какое значение наиболее характерно для выборки; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных. Для решения первого вопроса вычисляются меры центральной тенденции, для решения второго – меры изменчивости (или разброса). Эти статистические показатели используются в отношении количественных данных, представленных в порядковой, интервальной или пропорциональной шкале.
Бег на 100 метров относится к такой дисциплине легкой атлетики, как бег на короткие дистанции. Но если во время преодоления отрезков в 200 и 400 метров скорость спортсмена постепенно снижается, то во время стометровки поддерживается предельный темп. Именно поэтому результаты бега на сто метров являются показателем, определяющим скоростные качества человека
Прыжок в длину дисциплина относящаяся к горизонтальным прыжкам технических видов легкоатлетической программы. Требует от спортсменов прыгучести, спринтерских качеств а также скоростно-силовых.
Данные тесты определяют скоростно-силовые качества.
Основные статистические характеристики:
Таблица 1.Описательная статистика (первичная обработка данных)
|
Осн. статист. Характерист. |
бег 3000 м. (мин) |
бег 3000 м. (мин) |
бег 1000 м. (мин) |
бег 1000 м. (мин) |
|
2011 г. |
2012 г |
2012 г. 1 замер |
2012 г. 2 замер | |
|
Xср |
14,95 |
13,99 |
3,71 |
3,62 |
|
S2 |
2,30 |
3,21 |
0,39 |
0,32 |
|
S |
1,52 |
1,79 |
0,62 |
0,57 |
|
V |
0,10 |
0,13 |
0,17 |
0,16 |
|
Ур.над. для α=0,05 |
0,71 |
0,84 |
0,29 |
0,26 |
Выводы: Бег 3000 метров 2011год:
Результат 15,0 ± 0,7(мин.) , данные однородные (коэффициент вариации V= 10% < 30%), результаты теста достоверны (коэффициент достоверности Т = 44,10> 2,4), данные подчиняются закону нормального распределения.
Бег 3000 метров 2012года:
Результат 14,0 ± 0,8(мин.) , данные однородные (коэффициент вариации V= 13% < 30%), результаты теста достоверны (коэффициент достоверности Т = 34,91> 2,4), данные не подчиняются закону нормального распределения.
Бег 1000 1 замер 2012года:
Результат 3,7±0,3 (мин.) , данные однородные (коэффициент вариации V= 17% < 30%), результаты теста достоверны (коэффициент достоверности Т = 26,54> 2,4), данные не подчиняются закону нормального распределения.
Бег 1000 2 замер 2012года:
Результат 3,6±0,3 (мин.) , данные однородные (коэффициент вариации V= 16% < 30%), результаты теста достоверны (коэффициент достоверности Т = 28,65> 2,4), данные не подчиняются закону нормального распределения.
Интервальный ряд
Интервальным вариационным рядом называют упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами или относительными частотами попаданий в каждый из них значений величины.
Интегральный ряд используют в качестве последовательности вариантов, записанных в возрастающем порядке и соответствующих им частот.
n – объем выборки
Количество
интервалов нашли по следующей формуле:
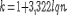 ,
или
,
или
Длину
интервалов нашли по следующей формуле:

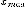 - наибольшее
значение варьирующего признака,
- наибольшее
значение варьирующего признака,
 - наименьшее
значение варьирующего признака.
- наименьшее
значение варьирующего признака.
Наибольшее (xmax = xmin + h ) и наименьшее (xmin = Хi)- h/2) значения признака.
Частота интервалов
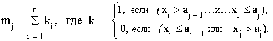
Интервальные частности (pj = mj / n)
Определение средней производится по следующей формуле:
|
|

Рассчитав все данные, строим гистограмму и полигон распределения
Рисунок 1.Частотное распределение графически в виде гистограммы

Рисунок 2. Полигон
Вывод: распределение не нормальное.