

Лекция 13
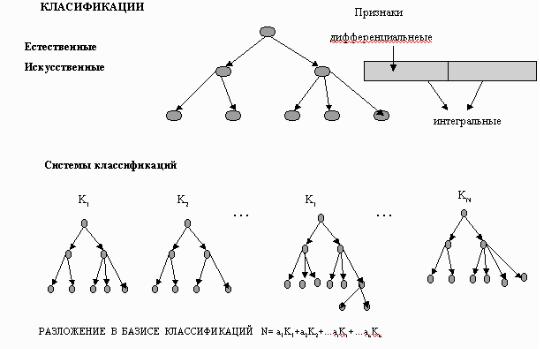
Классификации. Классификации считаются научным результатом. Классификации могут быть естественные и искусственные. Естественная классификация – это классификация навязанная самой природой. Естественная классификация приносит больше пользы. Классификация помогает структурировать то, с чем вы столкнулись в своей задаче. Классификация говорит вот смотри, у меня есть такие узлы, такие признаки – есть они у тебя или нет. А искусственная классификация – это мы так решили сделать, причем очень много абстрактных конструкций, абстрактных теорий. Если вы знаете законы классифицирования, значит вы можете применить их к тому, что вас интересует. Искусственная – придуманная и очень важный вопрос, что за этим стоит. Если вы ее придумали для того, что вы до этого придумали и она вам помогает, то это хорошая классификация.
Если брать все признаки, какого-то объекта, то только часть из них нужна чтобы по дереву ходить. Чтобы по дереву ходить надо знать, чем один набор признаков отличается от другого набора признаков. Набор признаков большой, потому мы выбираем дифференциальные признаки, помогающие ходить по классификации. Это похоже на выбор первичных ключей в базах данных. Мы делаем выделение дифференциальных признаков в самой массе признаков для практической пользы. Вы будете разбирать те, которые понятные, ясные, с которыми легче разобраться. Сложный признак сложнее будет распознавать.
Лучше всего подходить к любой вещи, которую необходимо структурировать в своей задаче с позиции разложения в базисе классификаций. На слайде приведено n – классификаций, как n – ортогональных функций, а в принципе у каждого узла свой набор признаков. Получается: набор признаков к классификации К1, набор признаков к классификации К2, т.е. раскладываем по базису
классификаций. Для целей информационного поиска такие разложения стали делать где-то 30-е годы.
Есть так называемые фасетные классификации. Фасеты – это наборы признаков из разных классификаций.
На одну и ту же вещь надо посмотреть с разных точек зрения, а за каждой точкой зрения стоит своя классификация.
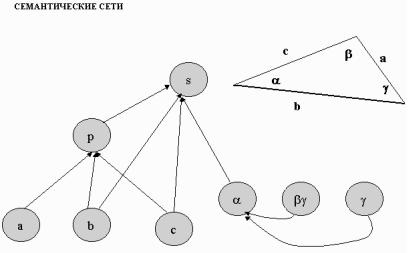
Где-то около 70 прошлого века стали строить семантические сети. Семантические сети состоят из узлов, за которыми стоят какие-то понятия или вещи, и дуг которые соединяют эти узлы. Первая семантическая сеть была построена в 1968 и начался вал семантические сетей. Основанием для того, чтобы строить такие сети, служил наш мозг и нейронные сети. Вот в нейронных сетях сгустки, как будто в них что-то храниться, а между ними дуги – это нейронные связки между областями в мозговых структурах.
Сеть состоит из узлов, за узлами стоят некоторые сущности, чаще всего существующие, представленные в форме понятий о них, для того чтобы можно было экземпляры подставлять под каждый узел. Если у вас какой-то узел треугольник, а треугольников очень много, т.е. в этом плане понятие треугольник, а за ним мало что стоит.
(на слайде) Здесь приведен пример, как раз для треугольника. Фрагмент сети похожий на то, с точки зрения использования, как обычно происходят процессы в нейронных сетях. Выделены стороны, углы, причем, если у нас есть базовых два угла – третий я могу вычислить. Будем считать, что у нас базовых 5 понятий: два угла и 3 стороны. Через 3 стороны я могу вычислить периметр или полупериметр. А через периметр я могу вычислить площадь треугольника. Это вот одна версия связок. Дуги сходятся в одну точку – это как сенаптический вход в нейронных сетях. Причем если два, то вход не возбуждается, а если три то вход возбуждается. Если я на вход дам А, В, С, то могу вычислить S.
Я всегда утверждал, что школьные задачи, это вовсе не задачи, там путь от данных до ответа короткий и очевидный. Бери данные, подставляй, вычисляй, потом снова подставляй и вычисляй. А вот разные олимпиадные задачи – там голову сломаешь путь искать.

Столкнулись с такой проблемой: если надо построить сеть для такойто предметной области, она становиться очень громоздкой. Если вы выбрали конкретную предметную область, где число понятий не очень большое, вот в программирование универсальном, там понятий – 250 – 300. А вот возьмем теорию автоматического управления, там терминов около 500. Т.е. столкнулись с проблемой комбинаторного взрыва при использовании семантических сетей. Большое всегда надо резать на части. А раз надо разрезать на части, значит надо делать обобщения. Любое понятие – это деревья. Наверху более общее, внизу менее общее. С позиции общности самый лучший прием резать на части. Разрезать на части надо по типовым ситуациям, по типовым фрагментам и блокам. Теория фрейма: разрезать на части эффективным образом, разрезать на части с помощью типовых рамок.
Здесь приведен фрейм для вопросов связанных с движением. Типовая рамка, это когда вы можете что-то оценивать по любым законам, для движения, например, по законам Ньютона. Что, кто, как, когда, где, откуда, куда и т.д. За фреймом всегда стоит группа вопросов. И на эти вопросы надо ответить. Кто – это класс, что – это класс, а вот экземпляр подставляется туда во фрейм. Фреймовые представления привели к специфическим структурам данных, в них как в классах приходится подставлять значения в экземпляры, если формируются экземпляры. И активность переходит от одного фрейма к другому, так и решаются задачи. Фрейм не решают задач, они данные представляют в удобной форме для решения задач, причем данные они представляют семантические, так как это принято в человеческой деятельности. Типовые фреймы приходиться использовать совместно и активизировать совместно. Фрейм всегда будут в структуризации, потому что это тип структур данных. Основные приложения искусственного интеллекта используют фреймы, наверное это и подтолкнуло основных разработчиков языков программирования и трансляторов вести этот тип данных – фрейм. Все языки для представления знаний, это где-то до 80 года, потом появились структуры данных с операциями, а от туда были перенесены в универсальные языки

программирования и появилось объектно-ориентированное программирование. ООП меньше 20 лет.
Продукционные системы. Там в основе работы лежит представления опыты в виде реакций каких-то условной деятельности. Т.е. если такая ситуация, то такая реакция. Смысл термина продукция простой, (на слайде). Специалист решает задачи, относящиеся к окружающему миру и окружающий мир ему их подбрасывает. Поэтому мы не имеем права игнорировать реальность в экспертных системах. Любой программист должен особое внимание уделять реальности, иначе он будет не программистом, а абстракционистом, и тоже бесполезным. Раньше было много предметов относящихся или связанных с физикой природной, с физикой компьютера. Там все рассматривалось на уровне моделирования, а именно на уровне моделирования реальности. Т.е. окружающий мир для которого вы решаете задачи, надо чувствовать и понимать, иначе вы будете даже плохим помощником.
Окружающий мир, рассуждающая система, база знаний – три системы специально выделены в отдельные блоки. Для того, что бы потом типы продукции выделить. Ядро, если А, то В. Если А – какое-то состояние, какое-то условие в окружающим мире, то В – следствие для рассуждений.
АW→Br – эта продукция влияет на способ рассуждения. И если у вас проявляется новая ситуация, она может изменить ход ваших рассуждений. Т.е. вы рассуждали, например, дедуктивно, а что-то произошло, и приходиться индуктивно рассуждать или детективно.
Есть тип продукции, который связывает то, что в окружающем мире с его представлением. На уровне слайдов у вас все есть, я повторять не буду. Если вы решаете задачу методом экспертизы или вы создаете экспертную систему, то в БЗ будут части, области, она будет разрезана, в зависимости от типов продукции там будут различные блоки. И разные блоки будут разные функции в процессе решения. Вот тут «ход рассуждения», «управление событиями» - очень важна роль рассуждений во всех этих процессах. Рассуждать надо всем людям и надо уметь

рассуждать (предположим, пусть, если – то). Рассуждения должны быть толковые и к месту.
Мы рассмотрели некоторые формы представления знаний. Этот слайд о тех приемах, способах, которые принято использовать, если в хотите знания от куда-то извлечь и вложить или в себя, или в ЭС. Первая ветка по извлечению знаний: коммутативная – значит придется с кем-то разговаривать (с высококвалифицированный специалистами, с самим собой – со своей роль, или вступать в диалог со своим опытом). В коммуникативных процессах две ветки: активная и пассивная. В пассивной ветке вы можете просо за кем-то наблюдать, но таким образом, что бы не мешать его процессам. На уровне активных: мозговой штурм, круглый стол, ролевые игры. У каждой из этих игр свои правила и методики. Еще одна ветка – текстологические. Это значит, знания извлекают из литературы, «написанной умными людьми». Есть хорошие и плохие версии программ извлечения знаний из книг, но они есть и ими пользуются.