

1. Представьте себе, что у вас есть возможность перейти на другой социологический факультет. Перешли бы вы?
— да, перешел бы
— нет, не перешел бы
— затрудняюсь ответить (з/о)
2. Представьте себе, что вы нигде не учитесь. Пришли бы вы или нет учиться на ваш факультет?
— да, пришел бы
— нет, не пришел бы
— з/о
Проанализируем все возможные сочетания вариантов ответа на эти два вопроса. Таких сочетаний 9, т. е. после сбора информации мы можем столкнуться с девятью ситуациями. Каждая из них требует интерпретации до проведения пилотажа. Как вы знаете, пилотаж — это небольшое по объему пробное исследование для апробации инструментария. На рис. 2.2.1 изображен логический квадрат, в котором каждая возможная ситуация отмечена буквами а, b, с, d, e, f.
|
«Пришел бы...»
|
«Перешел бы...»
| ||
|
Нет
|
З/о
|
Да
| |
|
Да
|
а
|
b
|
f
|
|
З/о
|
b
|
с
|
d
|
|
Нет
|
f
|
d
|
е
|
Рис. 2.2.1 Логический квадрат
Максимальная удовлетворенность будет наблюдаться в ситуации а, минимальная — в ситуации е, средняя — в ситуации с. Вы обратили внимание на то, что некоторые ситуации обозначены одинаковыми буквами. Буквой f обозначены две ситуации, которые практически не могут встретиться в данных, ибо содержат в себе противоречие. Две ситуации, обозначенные b, в определенной мере идентичны. Степень удовлетворенности для этих случаев меньше, чем максимальная, и больше, чем средняя. Например, студент Михаил не хочет никуда переходить, а по поводу поступления на факультет вновь не имеет определенного мнения (з/о), а студент Сергей готов вновь поступить на факультет, но по поводу перехода затрудняется ответить. В определенной мере можно считать, что сила мотивации у них одинакова. При этом она не так сильна, как в ситуации а, но сильнее, чем в ситуации с. И наконец, две одинаковые ситуации, обозначенные буквой d. Им соответствует степень удовлетворенности меньшая, чем средняя, и большая, чем минимальная. Рассуждения аналогичны предыдущим.
Логический квадрат называется логическим в силу того, что исследователь проводит только логические операции, а квадратом — потому что такова его форма существования. На входе мы имеем трехчленную шкалу, а на выходе шкалу порядков с пятью градациями. Можем закодировать или присвоить шкальные значения ситуациям так, чтобы выполнялось условие:
a>b>c>d>e
Например, а=5, b=4, с=3, d=2, e=l.
С помощью логического квадрата мы определяем удовлетворенность учебой только отдельно взятого студента. Для решения поставленной выше задачи, а именно сравнения степени удовлетворенности учебой студентов-социологов различных вузов Москвы, необходимо решить еще одну задачу: измерения искомой удовлетворенности для группы студентов отдельно взятого вуза. Ее можно решить посредством формирования уже групповых индексов. К этой задаче мы вернемся после рассмотрения еще одного логического индекса. Его условно можно обозначить как логический прямоугольник.
Индексы для равнения групп.
Теперь представим себе, отвлекаясь от рассмотренных нами задач, что нам нужен индекс, характеризующий группу респондентов. При этом у нас есть оценки для каждого респондента, полученные по шкале порядков. Логика формирования индекса на основе шкалы порядка одинакова независимо от того, каким способом получена исходная порядковая шкала и сколько на ней градаций (пунктов шкалы). Возьмем, к примеру, случай, когда по каждому респонденту есть оценка «уровня беспокойства» трудоустройством по специальности после окончания вуза, полученная по порядковой шкале с пятью градациями. Выше был приведен этот эмпирический индикатор как вопрос вида «Насколько Вы уверены, что найдете работу по специальности после окончания вуза?». Перед нами стоит задача получения оценки уровня беспокойства/ уверенности в целом по группе респондентов. Для начала несколько упростим ситуацию и представим себе, что исходно имеем дело со шкалой с тремя градациями:
— уверен, что найду
— и да, и нет
— совсем не уверен, что найду
Естественным образом, оценкой «уровня беспокойства» для группы может служить разница между числом «уверенных» и числом «неуверенных» в группе. Но не абсолютная разница, а относительная, т. е. доля этой разницы в общем числе респондентов данной группы. Тогда значение индекса не зависит от объема группы и по нему можно сравнивать «уровни беспокойства» групп разного объема.
Если обозначим через n+ — число «уверенных», n — число «неуверенных», а через n0 — число «нейтральных», то индекс I будет иметь следующий вид:
![]()
Какой бы индекс социолог ни использовал, он необходимым образом выясняет свойства этого индекса, т. е. выясняет правила его «поведения». Данный индекс обладает следующими свойствами. Он принимает максимальное значение, равное 1, тогда, когда все респонденты в группе уверены, что найдут работу по специальности. Он принимает минимальное значение, равное —1, тогда, когда все респонденты не уверены, что найдут работу по специальности. Индекс равен нулю, если число «уверенных» равно числу «неуверенных». Положительное значение индекса говорит о том, что уверенных больше, чем неуверенных. И соответственно, отрицательное значение появится в ситуации, когда число неуверенных больше, чем уверенных. Понятно, что в группах с одинаковой разницей (отличной от нуля) между числом уверенных и неуверенных (это называется абсолютной разницей в отличие от относительной), значение индекса будет больше в той группе, где меньше нейтральных ответов.
А теперь, опираясь на те же рассуждения, можно предложить аналогичный индекс и для случая пяти градаций. Обозначим через na — число уверенных студентов, nb — число скорее уверенных, чем нет, nc — число нейтральных, пd — число не очень уверенных и ne — число скорее неуверенных. Тогда можно предложить индекс следующего вида:
![]()
Если в предыдущей формуле все коэффициенты при разных n (частотах) были равны единице, то в этой формуле появились коэффициенты разные (1 и 0,5). Это означает, что отдельно взятая градация вносит разный вклад, разную долю в значение индекса. Коэффициент, равный 0,5 перед nb и nd вводится для того, чтобы сделать равноправными «не очень уверенных» и «скорее неуверенных». Это во-первых. Во-вторых, вклад тех, кто «не очень», в два раза меньше, чем вклад тех, кто «очень». И наконец, рассмотрим ситуацию, когда в группе нет респондентов уверенных, нейтральных, не очень уверенных, совсем неуверенных, а все респонденты скорее уверены, чем нет. Тогда значение индекса будет равно 0,5. Аналогичные рассуждения можно продолжить для выяснения всех остальных свойств индекса.
Индекс, который мы рассматриваем, имеет достаточно простую, прозрачную конструкцию. Возникает вопрос, что будет, если число градаций на порядковой шкале увеличить. Самый простой ответ на этот вопрос обусловлен существованием интересного феномена в методической социологии. Назовем его условно для образности и яркости «законом триад». Какое бы исследование ни проводилось, социолог пользуется этим законом. Например, выбирает предприятия, территориальные образования, исходя из простой схемы: большое — среднее — малое. Выбирает для опроса студенческие группы: хорошие — средние — плохие. Анализирует отдельно различные группы по доходу: богатые — средние — бедные. Могут быть триады типа:
— удовлетворенные — и да, и нет — не удовлетворенные
— уверенные — и да, и нет — неуверенные
— вероятные — мало вероятные — невероятные
интересующиеся — и да, и нет — не интересующиеся
Список можно продолжать до бесконечности, но не в этом дело. Для нас с вами важно, что в группе, например, «богатых» можно в свою очередь ввести новую триаду:
— богатые, но не очень — достаточно богатые — очень богатые,
А, например, между группами «удовлетворенных» и тех, кто «и да, и нет», также можно ввести новую триаду. Это очень удобный и простой способ, и для создания порядковых шкал, и для трансформации шкал, т. е. увеличения или уменьшения числа градаций на шкале. Разумеется, речь идет о так называемых сбалансированных шкалах. К ним относятся порядковые шкалы, на которых есть нейтральное положение и число «положительных» позиций равно числу «отрицательных». Сбалансированные шкалы пришли в социологию из психологии, где при измерениях опираются на модель «стимул — реакция». Соответственно, предполагается, что реакция может быть положительной, нейтральной и отрицательной.
Вернемся к задаче формирования индекса для характеристики группы в случае, когда исходные порядковые шкалы имеют большее число градаций, чем пять. В этом случае можно преобразовать исходную шкалу в шкалу с меньшим числом градаций и предложенным способом вычислить групповой индекс. Но следует иметь в виду, что преобразовать необходимо в сбалансированную шкалу. Если же этого нельзя сделать, то возможно проводить сравнения различных групп респондентов на основе других показателей, например на так называемых мерах центральной тенденции. О них будем говорить в соответствующем разделе книги.
Формирование аналитических индексов может быть отнесено и к отдельно взятому респонденту. Совершенно ясно, что с помощью прямо поставленных вопросов или с помощью логических индексов можно измерить очень ограниченное число свойств социальных объектов. Перейдем к рассмотрению еще одного приема измерения, который может быть обозначен как формирование шкалы суммарных оценок.
Впервые такого рода шкалу использовал в 1929—1931 гг. Р. Лайкерт (Ликерт) (R. Licert) для измерения расовых, национальных установок. Обычно социолог, «изобретая» некоторую шкалу суммарных оценок, называет ее шкалой типа шкалы Лайкерта, имея в виду процедуру измерения. Таким образом, шкалой называется и какая-то «линеечка», и алгоритм ее получения, т. е. сама процедура измерения. Процедуру измерения лучше называть шкалированием.
АНАЛИЗ ЛАТЕНТНО-СТРУКТУРНЫЙ - метод вероятностно-статистического моделирования, идея которого основана на предположении, что наблюдаемое поведение (например, ответы индивидов на вопросы теста или анкеты) есть внешнее проявление некоторой скрытой (латентной) характеристики, присущей индивидам. Задача метода заключается в том, чтобы, изучив наблюдаемое поведение индивидов, вывести эту скрытую характеристику и разделить (классифицировать) индивидов по сходству (равенству) ее значений. Метод возник в конце 40-х - начале 50-х гг. Первоначально он разрабатывался в теории тестов как инструмент измерения таких скрытых характеристик индивидов, как способность, интеллект и т.д., а затем в социологии как инструмент классификации. Логические и математические основания метода были изложены в работах американского социолога П. Лазарсфельда. В 50-х - начале 60-х гг. получили дальнейшее развитие математико-статистические основы метода, которые были подытожены в монографии, подготовленной П.Лазарсфельдом и Н.Генри. Однако попытки применить конкретные латентно-структурные модели к реальным данным столкнулись со значительными вычислительными и методическими трудностями. Первоначально оптимистические надежды, связанные с декларированием широких потенциальных возможностей метода, сменились более сдержанным к нему отношением. В середине 70-х и 80-х гг. в связи с бурным развитием быстродействующей вычислительной техники вновь возродился интерес к анализу латентно-структурному. Предложен ряд эффективных алгоритмов, в которых преодолены вычислительные и прикладные трудности. Латентно-структурная техника стала доступной и приемлемой для использования в социологических исследованиях. Анализ латентно-структурный состоит в следующем. Исследователь формирует тест или анкету, состоящую из вопросов, которые, как он полагает, относятся к изучаемой скрытой характеристике. Выделенные вопросы называют явными переменными, а скрытую характеристику - латентной переменной. В теории тестов скрытая характеристика интерпретируется как одномерный латентный континуум (непрерывная латентная переменная). Вопросы предъявляются выборке индивидов. Основная задача метода заключается в том, чтобы на основании полученного распределения ответов на вопросы сделать выводы о позициях индивидов на предполагаемом континууме. Полученные "картины ответов" называют явными данными, а извлеченная и выведенная из них информация о континууме и положении индивидов на нем - латентной, т.е. различаются явные данные, полученные прямым наблюдением, и информация, выведенная из данных при некоторых дополнительных предположениях. Если бы исследователь располагал полной информацией о характере распределений ответов на вопросы, то он мог бы представить эти распределения как математические функции (графики вопросов), ставящие в соответствие с конкретным уровнем континуума определенную вероятность ответа на каждый вопрос. Но так как исследователь не располагает такой информацией, он может лишь предполагать, что выбираемые вопросы отражают некоторые присущие индивидам гипотетические свойства, определяемые латентным континуумом. Данное предположение открывает возможности конструктивной разработки процедуры измерения скрытой характеристики. В связи с тем что исследователь начинает с изучения связи и стремится вывести соответствие между латентной характеристикой и обследуемыми индивидами, необходимо выдвинуть предположение, которое позволяло бы на основании связи вопросов делать вывод о наличии сходства (равенства) между индивидами, т.е. о сходстве (равенстве) значений присущей им латентной характеристики. Основанием такого вывода является предположение, что эта связь должна быть объяснена, исходя из характера отношения между каждым вопросом в отдельности латентным континуумом, т.е. предполагается существование латентного континуума, который объясняет связь между вопросами. Математически точная формулировка того, что латентная переменная объясняет связь между вопросами, сводится к следующему. Если индивиды имеют одинаковое значение латентной переменной, то их ответы на вопросы независимы, т.е. вероятность того, что индивиды будут давать конкретные ответы на вопросы, равна произведению вероятностей ответов на каждый вопрос анкеты в отдельности (см. Теория вероятностей). Таким образом, ответы индивидов на одни вопросы не должны зависеть от ответов на другие при условии, что индивиды имеют одинаковое значение латентной характеристики. Данное предположение независимости является основополагающим в анализе латентно-структурном и получило название аксиомы локальной независимости или принципа условной независимости. Принятие принципа условной независимости имеет важные методические следствия и открывает возможности разработки различных латентно-структурных моделей. Общая модель анализу латентно-структурному дается в следующей формулировке. Пусть вектор (см.) , состоящий из n компонент , обозначает явные или наблюдаемые переменные, а вектор обозначает латентную переменную. В общей статистической модели предполагается, что имеется условная функция распределения . Предполагается далее, что имеет функцию распределения . Тогда безусловная функция распределения х равна: . Если бы функции распределения F и G были известны, то оценки из наблюдаемых могли бы быть получены на основании теоремы Байеса. Однако обычно F и G неизвестны. Но хотя известна или может быть оценена при достаточно большой выборке, тем не менее невозможно единственным образом вывести F и G из Н без некоторых дополнительных предположений относительно этих функций. Основным общим таким предположением и является принцип условной независимости, при котором Т.е. предполагается, что при данных значениях латентной переменной явные переменные , являются независимо распределенными. Помимо математико-статистических достоинств, приводящих к разрешимости моделей анализа латентно-структурного, данное предположение ведет к важным методическим следствиям. Так, подсовокупности индивидов при условии равенства или сходства значений латентной переменной являются однородными. В большинстве ситуаций использования этих моделей исследователь стремится разработать средства измерения, например, анкету или батарею тестов, обеспечивающих такую локальную однородность. В зависимости от предположений о конкретном виде функций F и G получают различные латентно-структурные модели (модель латентно-полиноминальная, латентных дистанций, Раша и др.). Простейшей из них является модель латентных классов, в которой предполагается, что как явные, так и латентные переменные принимают конечный ряд значений. Именно эта модель наиболее широко применяется при решении задачи классификации в социологических исследованиях. П.Лазарсфельд выделяет следующие методологические положения, оказавшие наибольшее влияние на формирование основных идей анализа латентно-структурного. 1. Тезис о предтеоретической стадии развития социальных наук. Его принятие подчеркивало важность систематизации социального знания, осуществляемого с помощью классификационных схем, и выдвигало на первый план разработку проблем классификации, связанных с определением понятий. 2. Идея диспозиции и редукции, используемая для выделения классификационных понятий из всех возможных и более четкого их определения. Диспозиция определяется как свойство исследуемого объекта реагировать определенным образом в определенной ситуации. Диспозиционные термины рассматриваются как теоретические, которые могут легко быть выражены в эмпирических терминах. Классификационные понятия, определяемые диспозиционными терминами, и должны рассматриваться, по мнению Лазарсфельда, в социологических исследованиях Лазарсфельд исследует проблему редукции, выделяет правило взаимозаменяемости соответствующих классификационному понятию индексов, формируемых из наблюдаемых признаков-индикаторов: возможна редукция классификационного понятия к различным индексам. Экспериментальный характер правила позволяет надеяться на разработку со временем (по мере уточнения индексов) более тонких и точных инструментов классификации. В процессе редукции классификационного понятия к эмпирическим индексам выделяются четыре ступени: формирование первоначального образа классификационного понятия; спецификация его размерности; обоснование и выбор наблюдаемых индикаторов как соответствующих классификационному понятию; объединение индикаторов при заданной спецификации в индекс. 3. Утверждение о вероятностном характере отношения между классификационым понятием и индексом. Такая нежесткая связь делает возможным как введение новых индикаторов и эмпирический анализ их соответствия классификационному понятию, так и уточнение классификационного понятия, заданной спецификации его размерности.
ОСНОВАНИЯ ТИПОЛОГИЙ ШКАЛ, ПРЕДЛОЖЕННЫХ КУМБСОМ
Известно довольно много типологий шкал, использующихся в социологии. В разделе 4 будет рассмотрена самая популярная типология, восходящая к Стивенсу. Можно назвать ряд весьма полезных для социолога типологий, которых мы не будем касаться. Это, например, типологии, отраженные в работах [Torgerson, 1957; Косолапов, 1984].
Типологии Кумбса представляются нам наиболее интересными. Кумбс сумел увидеть в способностях респондента оценивать те или иные объекты то, что до него никто не увидел, осуществил глубокий анализ специфики социологических данных. И это нашло отражение в разработке оснований многочисленных предложенных им типологий социологических шкал.
Говорить о полноценной типологии мы не можем, так как коснулись слишком малого количества шкал: если выделяемые на основе предложенных оснований классы рассматривать как некие "полочки", на которые шкалы должны быть "уложены", то на многие из "полочек" нам просто нечего будет положить, поскольку о соответствующих шкалах мы в данной книге даже не упоминаем.
Но рассмотрение оснований типологии представляется имеющим смысл само по себе. В этих основаниях отразилось видение автором специфики социологической информации, и их анализ может многое дать социологу. Внимательно отнесясь к мнению Кумбса, он поймет, во-первых, что наличие соответствующих аспектов в человеческих представлениях имеет смысл учитывать в своей работе, и, во-вторых, что такой учет можно практически осуществить. А это, как мы увидим, может привести социолога к использованию многих нетрадиционных, но весьма полезных подходов к измерению.
Классификация методов шкалирования
Более чем за 50-летнюю историю эмпирических социологических исследований было разработано большое количество шкал, иначе говоря, процедуры количественного представления социальных явлений. В настоящее время социологические шкалы различаются прежде всего по трем моментам: природе шкалируемого социального явления, уровню числового представления, способам получения числового представления.
Первый момент относится к природе явлений. Одно дело, когда изучается социальная установка группы лиц, другое - когда измеряется степень спаянности этой группы. Историческитаксложилось, что социологами наиболее разработаны шкалы измерения социальных установок, а также техника измерения структурных особенностей группы, так называемая социометрия, хотя это разграничение весьма относительно, поскольку социометрия основана на изучении предпочтения, а последнее связано с установкой.
Вместе с тем, изучая группу лиц по социальным установкам, в определенной степени изучают и структуру группы. Однако социологическое исследование не исчерпывается изучением структуры группы. Как измерить микрокультуру группы, уровень социализации индивида, степень влияния друг на друга членов определенной неформальной группы? Можно поставить множество подобных вопросов. Измерить субкультуру группы значительно сложнее, чем установку отдельного индивида, поскольку субкультура - это сложное явление, которое складывается из сочетания отдельных установок. Говоря математическим языком, субкультура - это многомерное явление, тогда как установка - одномерное. Последнее утверждение тоже весьма условно, так как установка - синтез сознательных н бессознательных ориентации и подсознательных влечений; мы полагаем, что этот синтез реализуется на каком-то одномерном непрерывном континууме. Измерить социальную установку индивида - означает определить его положение на этом гипотетическом континууме. Все развитые социологические шкалы установок и предлагают различные методы такого расположения.
Естественно, что при решении проблемы измерения и шкалирования в каждой отрасли социологии имеется своя специфика, что следует относить к содержательной стороне социального явления. Но в то же время природа социального явления обладает формой существования, которая включает три составляющие, а именно: континуум, связь, структуру.
Для измерения структуры группы была разработана социометрическая техника и различные варианты многомерного анализа (факторный анализ, латентно-структурный анализ, причинный анализ, многомерное шкалирование, таксономия). При измерении связи использовалось большое многообразие коэффициентов корреляции.
Классическим примером измерения континуума является определение социально-экономического статуса как измерение некоторой гипотетической непрерывной величины. Статус складывается из образования и материального дохода. Ясно, что статус больше у того, у кого больше образование и доход. А как быть с теми, у кого образование меньше, а доход больше, или наоборот?
Предположим, что мы оцениваем качество лекции по трем факторам - содержанию (С), интересу (И), технике (Т). Могут быть следующие варианты оценок:
|
Строка |
C |
И |
Т |
Строка |
С |
И |
Т |
|
I |
+ |
+ |
+ |
V |
- |
- |
+ |
|
II |
+ |
+ |
- |
VI |
- |
+ |
- |
|
III |
+ |
- |
+ |
VII |
+ |
- |
- |
|
IV |
- |
+ |
+ |
VIII |
- |
- |
- |
Знаком <плюс> обозначаем присутствие данного фактора в лекции, знаком <минус> - его отсутствие.
Сразу определяются две полярности качества лекции: одна полярность характеризуется всеми тремя положительными значениями факторов, другая - тремя отрицательными значениями этих факторов. Все прочие возможности находятся где-то между этими двумя полярностями. Качество лекции представляет собой как бы некий континуум, обладающий нижней и верхней границей. Эти границы являются граничными, предельными показателями. Эмпирически, операционально они фиксируются в трех одновременно положительных и одновременно отрицательных значениях факторов. Любой другой эмпирический вариант сочетания факторов является показателем промежуточного положения качества соответствующей лекции на этом континууме. При предположении равноправности рассматриваемых факторов естественно полагать, что два положительных ответа являются показателем более высокого качества лекции, чем при одном положительном ответе. В этом случае восемь вариантов ответов конструируют нам четыре показателя качества лекции: строка I - отличное; строки II - IV - хорошее; строки V - VII - удовлетворительное; строка VIII - неудовлетворительное. Но не является ли это слишком большим упрощением? На самом деле, можно ли считать лекцию удовлетворительного качества, если она малосодержательна? Приходится строки IV - V отнести к неудовлетворительному уровню и, следовательно, конструирование меры качества становится иным. Наличие двух полярностей означает существование между ними континуума и дает основание для построения шкалы.
Второй момент в классификации методов шкалирования связан с уровнями (шкалами) числового представления, предложенными Стивенсом. Существуют два фундаментальных аспекта теории измерения - определение информации, содержащейся в наблюдении на фенотипическом уровне, и определение отношения между генотипическим и фенотипическим уровнями. Этиобааспекта обеспечивают базис для осуществления генотипических выводов из наблюдений.
Наблюдаемые данные (ответы на вопросы) - это фенотипический (наблюдаемый, эмпирический) уровень. Внутренний механизм, обусловливающий эти ответы, - генотипический уровень. К генотипическому уровню относятся установки, убеждения, способности и т.п. Проблема двоякая: во-первых, каковы измерительные свойства шкалы; во-вторых, к какому уровню - фенотипическому или генотипическому - относится шкала. Соответственно возникает разделение шкал на две группы - фенотипические и генотипические. Если в психологии, психометрике и психофизике можно выделить пять групп шкал - фенотип-ординальные, фенотип-интервальные, фенотип-пропорциональные, генотип-интервальные, генотип-пропорциональные, то в социологии при такой логике классификации все методы шкалирования образуют только две группы - фенотип-ординальные и генотип-интервальные. Фенотип-ординальные методы дают ординальную шкалу на фенотипическом уровне. Это методы ранжирования, ранговых категорий, шкалограммный анализ Гутмана, техника развертывания Кумбса. Генотип-интервальные методы дают интервальную шкалу измерения на генотипическом уровне. Это метод парных сравнений, основывающийся на законе сравнительного суждения Терстона. Существо метода парных сравнений может быть изложено следующим образом.
Закон сравнительного суждения имеет вид:
S![]() -
S
-
S![]() = x
= x![]()
![]()
где S![]() и
S
и
S![]() - шкальные
значения сравниваемых стимулов,
x
- шкальные
значения сравниваемых стимулов,
x![]() - величина,
соответствующая вероятности того, что
стимул 1 предпочтительнее стимула 2; s1
и s2
- дисперсии
стимулов; r -
корреляции
между стимулами.
- величина,
соответствующая вероятности того, что
стимул 1 предпочтительнее стимула 2; s1
и s2
- дисперсии
стимулов; r -
корреляции
между стимулами.
В зависимости от того, какие величины даны в правой части, различают пять случаев закона Терстона. Простейший вариант имеет вид:
S![]() -
S
-
S![]() =
x
=
x![]() s
s![]() =
z
=
z![]()
z![]() - это
вероятности, но практически приходится
принимать частоты за вероятности. Чаще
всего производится многократное
сравнение, и за вероятности принимаются
усредненные частоты. По Терстону,
эксперты оценивают каждую пару установок
в отношении предпочтения. В квадратной
таблице ставят процент экспертов,
оценивших данную пару. Если все различия
подчиняются нормальному закону, то эти
проценты рассматривают как площади под
нормальной кривой и в таблицах нормального
распределения находят соответствующие
абсциссы. По каждому столбцу они
складываются, что дает интервальный
балл каждой установке по данной группе
экспертов.
- это
вероятности, но практически приходится
принимать частоты за вероятности. Чаще
всего производится многократное
сравнение, и за вероятности принимаются
усредненные частоты. По Терстону,
эксперты оценивают каждую пару установок
в отношении предпочтения. В квадратной
таблице ставят процент экспертов,
оценивших данную пару. Если все различия
подчиняются нормальному закону, то эти
проценты рассматривают как площади под
нормальной кривой и в таблицах нормального
распределения находят соответствующие
абсциссы. По каждому столбцу они
складываются, что дает интервальный
балл каждой установке по данной группе
экспертов.
Третий момент связан с тем, что шкала получается путем оценки, самооценки, сравнения, экспертного суждения и т.п.
Это последнее направление в классификации методов шкалирования включает две основные проблемы - характер инструментария измерения и процедуру приписывания баллов (мер, индексов). Первая проблема дает следующий перечень альтернатив (далеко не полный): отдельный вопрос, вынужденный выбор, множественный выбор, косвенные меры, физиологические меры и т.п. Вторая проблема может быть разрешена посредством экспертных оценок, суммарных шкал, кумулятивных шкал и т.д.
Проблема измерения, как мы уже отмечали, включает два аспекта - логико-теоретический и эмпирический, операциональный. Логико-теоретический аспект связан с характеристикой числовой системы. Эмпирический аспект означает множество операций над самими объектами, посредством которых можно наблюдать некоторые свойства этих объектов таким образом, чтобы удовлетворить определенным аксиомам числовой системы. Если отвлечься от специальных математических вопросов, то для социологии актуальны два момента современной теории измерения: во-первых, способ выявления выполнимости аксиом порядка в эмпирической системе и, во-вторых, выявление и характеристика промежуточных шкал, например таких, как частично упорядоченная шкала, т.е. выявление математических свойств эмпирических систем, часть членов которых удовлетворяет аксиомам порядка, а часть - аксиомам равенства.
Вопрос о специфике именно социологического измерения имеет давнюю историю, хотя по сегодняшний день он остается открытым. Еще Г. Морфи в середине 30-х годов различал психологическое измерение как получение индивидуального балла в отношении рассматриваемой установки, а социологическое измерение - как измерение установки на основе групповых данных, полученных на основе вопросника.
В процедуре измерения в соответствии с его двумя аспектами выделяются два подхода. Первый связан с характеристикой и особенностями числовых систем, на которых оно реализуется, и определяет типы или уровни измерения (номинальный, порядковый, интервальный, числовой). Второй подход акцентирован на выявлении путей, посредством которых результируется измерение. Этот подход приводит к двум видам измерения - производным и фундаментальным. Квадранты Кумбса - основа для классификации методов измерения, однако полная их систематизация в социологии еще не осуществлена.
Мы можем задать себе вопрос в отношении некоторого человека, с одной стороны, нравится ли он вам или нет, с другой - занимается, например, он спортом или нет. В первом случае эмпирические данные будут отражать отношение этого человека к нашему предпочтению, идеалу. Во втором - данные отражают отношение этого человека к определенному атрибуту (хороший). Известный психолог и социолог Кумбс это различие обозначил как две задачи: А и В. Задача А - это оценка суждения объекта, признака, вопроса, т.е. реализации предпочтения (например, я выбираю таких друзей в силу того, что их взгляды близки моим взглядам, привязанностям, наши мнения совпадают. Задача В - оценка суждения относительно соответствующего атрибута, т.е. выявление содержания (продолжая идею предыдущего примера, можно сказать, что в этом случае выбор таких друзей происходит в силу того, что они принадлежат к одной партии, одному поколению, что они имеют одинаковое семейное и общественное положение, и т.п.). Задача А - это соотношение вопроса и субъекта, задача В - соотношение вопроса анкеты и атрибута, объекта.
Специфика природы данных и эмпирических показателей также связана с относительностью и безотносительностью поведения при ответах на вопрос. При относительном поведении ответ выражает отношение двух или более вопросов, т.е. возможен выбор: в случае задачи А спрашивается, какой из данных пунктов предпочитается, в случае задачи В - какой из данных пунктов обладает большей характеристикой. При безотносительном поведении мы рассматриваем ответ на отдельный вопрос, не связанный со сравнением: в случае задачи А - это пример с арифметическим тестом, в случае задачи В - это шкала оценки (например, требуется оценить по шкале <знает - не знает> знания данного студента).
Эти два подхода - задачи А и В и относительное и безотносительное поведение - в характеристике данных эмпирического социологического исследования наглядно представлены с помощью квадрантов Кумбса:
|
|
Безотносительное поведение |
Относительное поведение |
|
Задача А |
II |
I |
|
Задача В |
III |
IV |
Это можно представить на более формальном языке с помощью трех альтернатив: 1) отношения на паре точек или паре расстояний; 2) элементы пары - из одного множества или из разных множеств; 3) отношения - или отношение - порядка или близости (рис.14).
Четыре класса, образованные перекрестным делением первых двух дихотомий, обозначены квадрантами от I до IV, а дополнительное деление дается отношениями порядка (>) и близости (0), которое делит квадранты на две части - а и b соответственно.
Наблюдаемое поведение в квадранте I - на паре расстояний, где каждое расстояние - между парой точек из различных множеств (обычно это индивиды и стимулы). Контекст реального мира, в котором наиболее часто можно получить этот вид данных, состоит в наблюдении предпочтительного выбора индивида среди множества стимулов. Данные могут рассматриваться как сравнение различий индивид - стимул или как так называемые данные предпочтительного выбора.
Наблюдаемое отношение в квадранте II - на паре точек, которые взяты из различных множеств (обычно это индивиды и стимулы). Такие данные называются данными простого стимула. Важно отметить, что они включают в себя не только данные
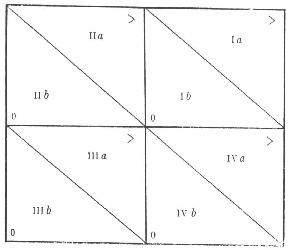
Рис. 14
психологического тестирования, выявления мнения и психофизических порогов, но также рейтинг-шкалы, метод последовательных интервалов и то, что называется данными абсолютного суждения.
Наблюдаемое поведение в квадранте III - на паре точек, которые взяты из одного и того же множества (они суть стимулы). Это данные сравнения стимулов. С таким видом данных мы имеем дело в социометрнческих матрицах.
Наблюдаемое поведение в квадранте IV - на паре расстояний, где каждое расстояние - между парой стимулов. Это данные сравнения, различий стимулов. Ввиду того что это поведение типично при ответе на относительное подобие стимулов, то они еще называются данными подобия. Следовательно, содержание квадрантов можно представить таким образом:
|
Данные простого стимула |
Данные предпочтительного выбора или сравнения различий индивид - стимул |
|
Данные сравнения стимулов |
Данные подобия или сравнения различий стимулов |
Кумбс различает методы сбора и методы анализа данных, хотя некоторые методы, например метод последовательных интервалов Терстона, могут выступать и в качестве первых, и в качестве вторых. Методы сбора классифицируются по указанным квадрантам следующим образом:
I квадрант включает методику развертывания, предложенную Кумбсом;
II - III квадранты - методы тестирования и метод шкалирования по Лайкерту;
IV квадрант - метод последовательных интервалов по Терстону.
Методы анализа можно сгруппировать так:
I квадрант включает шкалограммный анализ Гутмана;
II - III квадранты - латентно-структурный анализ Лазарсфельда;
IV квадрант - метод последовательных интервалов Терстона.