

4.2. Процесс компиляции
В настоящем разделе рассмотрим, каким образом программа, написанная на листке бумаги становится доступной для выполнения машиной. Для того чтобы ввести программу, например, с клавиатуры в оперативную память машины, используется специальная системная программа, которая называется редактор текста (рис. 4.1). Каждой нажатой клавише соответствует определенный код (ASCII), снимаемый с регистра данных клавиатуры. Редактор текста этот код без всякого преобразования заносит в оперативную память в виде файла. В дальнейшем этот файл может быть записан на внешний носитель, например, на диск. Файл программы, занесенный в машину, называется исходным файлом. Файл имеет имя, присвоенное ему пользователем, и расширение. Расширение имени отделяется от имени точкой, состоит из трех букв и обычно связано с типом файла. Расширение используется человеком для характеристики файла и операционной системой для обработки файлов по умолчанию. Последнее предполагает, что система в соответствии с типом файла будет выполнять определенные действия без подробного указания со стороны пользователя.
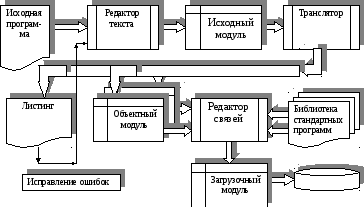
Рис. 4.1
Для дальнейшей подготовки исходного модуля к выполнению на компьютере его необходимо перевести на язык, понятный машине, т.е. в итоге в двоичный код. Программа перевода с одного языка на другой называется транслятор. Транслятор не обязательно переводит что-то в машинный код. Он может, например, перевести с языка Pascal на язык Assembler. Будем считать, что на рис. 4.1 транслятор переводит исходную программу в двоичный код, но он еще не может быть запущен на исполнение! Результат работы транслятора дает два файла:
листинг (расширение *.LST) — подробная распечатка программы с указанием встреченных ошибок, распределением адресов переменных и прочими полезными для опытного программиста сведениями;
объектный модуль (расширение *.OBJ) — программа в двоичном коде со ссылками на библиотеки стандартных программ, необходимых для работы транслируемой прикладной программы.
Если в листинге программы есть серьезные ошибки, то объектный модуль не будет сгенерирован транслятором. Для исправления ошибок необходимо вызвать редактор текста и в нем исправить ошибки прикладной программы. Затем повторить трансляцию.
Если ошибок нет, то с помощью еще одной служебной программы редактора связи можно скомпоновать все необходимые программные модули в один загрузочный. Необходимые модули это объектные модули пользователя. При сложной программе отдельные фрагменты ее можно транслировать отдельно (это служебные программы, например, драйверы — программы, обслуживающие внешние устройства, стандартные математические функции и т.п.).
Загрузочный модуль это программа, почти полностью готовая к исполнению и имеющая, например, расширение *.exe или *.sav в зависимости от системы программирования. Как правило, это программа в машинных кодах, но в относительных адресах, т.е. первая команда имеет нулевой адрес. Привязка с физическим адресам и загрузка программы на исполнение в оперативную память производится обычно специальной программой — загрузчиком.
Рассмотренный процесс перевода программы в загрузочный модуль называется процессом компиляции. Однако существуют и имеют определенные преимущества, впрочем как и недостатки, еще два метода интерпретации и ассемблирования.
Интерпретация — это компиляция и выполнение отдельно каждого оператора исходной программы. Интерпретация требует меньше машинных ресурсов, особенно оперативной памяти, но для выполнения программы требуется значительно больше времени, чем для скомпилированных программ.