

5.3.1 Внутренние и внешние ключи
Одно из важнейших понятий, используемых при работе с базами данных, – это первичные ключи, с их помощью идентифицируются значения сущности (записи в таблице). В качестве первичного ключа может использоваться суррогатный или естественный ключ.
Естественный ключ – это атрибут или набор атрибутов, которые однозначно идентифицируют значение сущности (записи таблицы) и имеют некий физический смысл вне БД (номер вагона, номер станции, номер контейнера и т.д.).
Данный метод построения модели БД основан на естественной идентификации сущностей. Уникальность записи может достигаться не только значением уникального кода внешнего объекта, но, например, и датой вставки записи в таблицу (первичный ключ PK – состоит из значения кода объекта и даты вставки записи в БД), см. примеры диаграмм приведенные выше. Конечно естественная идентификация значений сущностей более понятная и предпочтительная, т.к. нет необходимости вводить дополнительные атрибуты не несущие ни какой внешней смысловой нагрузки. Да, и при эксплуатации БД в сложных ситуациях можно восстановить их значения. Но, не всегда возможно выбрать атрибут или короткий набор атрибутов для идентификации значений. В этом случаи без использования внутренних, суррогатных ключей трудно обойтись.
Суррогатный ключ – автоматически сгенерированное значение, никак не связанное с информационным содержанием записи, имеющий некий физический смысл только внутри БД; обычно в роли суррогатного ключа могут использоваться данные типа integer или datestamp.
В данном методе построения модели БД суррогатная идентификация значений сущностей позволяет решить проблему идентификации за счет введения внутреннего ID – сущности и выработки внутреннего суррогатного ключа (PK) для каждого значения в БД. Такой подход предполагает, что для каждой сущности существует набор определенных характеристик, которые в процессе жизни могут меняться или уточняться. Поэтому в БД каждой сущности на предприятии присваивается своя внутренняя идентификация, уникальная на всей протяжении жизни сущности и все характеристики (текущие или измененные) уникально идентифицируются для каждой сущности (создается уникальный внутренний суррогатный ID – сущности). Данный уникальный идентификатор каждого значения в БД является первичным ключом записи (PK) в сущностях (таблицах), содержащих значения характеристик сущностей. На примере рис. 5.3. приведена таблица для выработки и хранения суррогатного ID сущности, на основе которого создаются суррогатные PK ключи значений сущностей (таблиц).
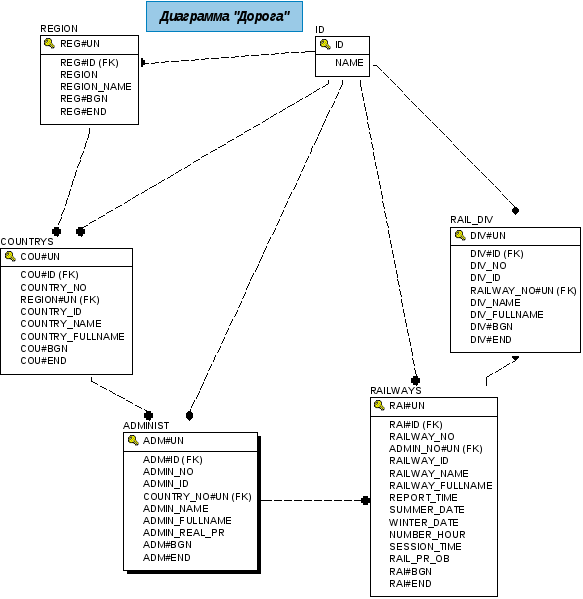
Рис. 5.3. Пример суррогатного ID сущности
5.3.2. Ссылочная целостность
Одной из главных задач при эксплуатации БД, является задача поддержания правил ссылочной целостности, которые были определены при проектировании. Эти правила отражают заданные связи между сущностями и порядок выполнения операций вставка, замена и удаление. Если эти правила не будут соблюдены, то БД быстро деградирует, и не будет отражать те бизнес – правила, которые были заложены при ее проектировании.
Правила контроля и выполнения этих операций может быть возложена на специально разработанные пользователем программы, но данное решение крайне не надежное и трудоемкое для его реализации. Задача поддержания правил ссылочной целостности обычно реализуется автоматически при генерации схемы БД на основе режимов реализации связей (отношений) с помощью триггеров, обеспечивающих ссылочную целостность. Данные триггера представляют собой программы, выполняемые всякий раз при выполнении операций вставка, замена и удаление. Таким образом, при проектировании автоматически обеспечивается правильная эксплуатация БД.
На рис. 5.4. приведен пример определения правил ссылочной целостности для реализации связи F_COU_AD в среде Erwin.
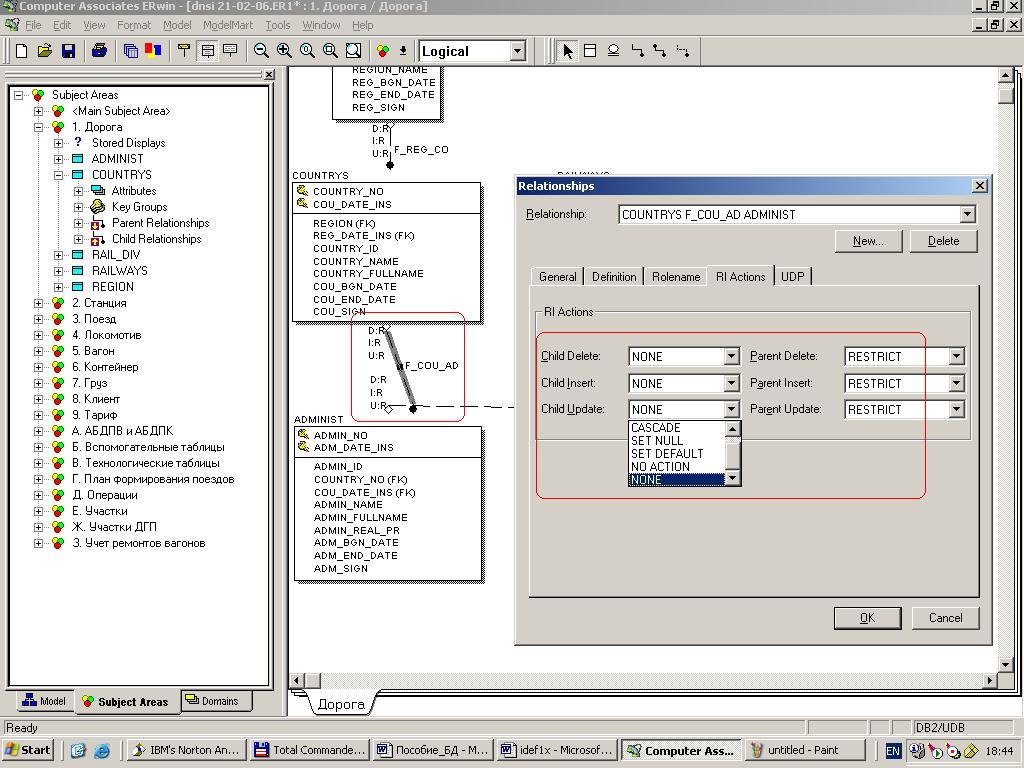
Рис. 5.4. Пример определения правил ссылочной целостности
Cascade – задает каскадное действие (например, удаление родительской записи влечет удаление всех записей у потомков), Restrict – задает ограничение на выполнение действия, (на пример, нельзя удалить родительскую запись, пока есть записи у потомков и наоборот), Set Null – задает действие по установлению FK равным NULL, при удалении родительской записи, Set Default – задает действие по установлению FK равным Default, при удалении родительской записи, None Action – ни каких действий не требуется, если удалены потомки (например, D:R – для родителя, D:S – для потомка или I:R – для потомка, если нет родителя).