

Березкин Основы теории информации и кодирования 2010
.pdfТаким образом, для стационарных источников все вероятности инвариантны относительно любых сдвигов вдоль последователь-
ности событий 1 2 ... i ... или, говоря другими словами, стати-
стические характеристики процесса появления событий на выходе источника не зависят от выбора начала отсчета времени или наблюдения (рис. 8.5).
Для стационарных источников справедливо равенство
H (A / A ) H (A |
/ A ) для всех i, j . |
|
|
||||
i |
j |
|
|
|
|
|
|
|
|
|
|
i |
|
|
j |
|
|
|
|
|
|
||
|
|
... |
... ... |
|
|||
|
|
|
i |
|
|
j |
|
|
p{ i ak / i 1 |
am ,..., i |
as } |
||||
|
p{ j ak |
/ j 1 am ,..., j as } |
|||||
Рис. 8.5. Иллюстрация свойства стационарности
ТЕОРЕМА 8.2. Для стационарного источника условные энтропии событий H (A 1 / A ) при условии, что заданы все предшест-
вующие события, образуют монотонную невозрастающую последовательность.
ДОКАЗАТЕЛЬСТВО. При рассмотрении свойств энтропии доказано, что
H (Ai / A ) H (Ai / A 1) H (Ai / A 2 ) ... H (Ai / A1) H (Ai ) .
В силу стационарности число i можно заменить на любое целое, лишь бы это целое было больше числа предшествующих событий. Положим в первом члене неравенства i 1, во втором i , в третьем i 1, …, в последнем i 1 и получим
H (A 1 / A ) H (A / A 1) H (A 1 / A 2 ) ... H (A2 / A1) H (A1) ,
что и доказывает справедливость теоремы.
181

ТЕОРЕМА 8.3. Для условных энтропий событий стационарного
источника существует предел lim H (A 1 / A ) H ( A/ A ) , где
H ( A / A ) – некоторое число, характеризующее источник и пред-
ставляющее собой среднее количество информации на событие, достаточно удаленное от момента начала наблюдения.
ДОКАЗАТЕЛЬСТВО. Как всякая энтропия, H (A 1 / A ) удовлетворяет ограничениям 0 H (A 1 / A ) log2 L , т.е. энтропия – неотрицательная величина, ограниченная снизу величиной 0. Последовательность H (A 1 / A ) не возрастает по аргументу и ограничена снизу, откуда сразу же следует существование предела
lim H ( A |
/ A ) H ( A / A ) . Энтропия |
H ( A/ A ) есть пре- |
|
|
1 |
|
|
|
|
|
|
дельная энтропия, необходимая для определения события на выходе стационарного источника.
ТЕОРЕМА 8.4. При любом заданном сколько угодно малом положительном числе 0 последовательность событий, порождаемых дискретным стационарным источником, можно закодировать в последовательность символов, выбираемых из заданного алфавита, таким образом, чтобы среднее по ансамблю число сим-
волов на событие удовлетворяло неравенству n H (A/ A ) . log2 D
ДОКАЗАТЕЛЬСТВО. Разобьем последовательность событий на группы по . Тогда каждая последовательность будет являться
элементом множества A , состоящего из букв, принадлежащих
А (рис. 8.6). Энтропия этого множества в соответствии с известным свойством равна
H ( A ) H ( A1 ) H ( A2 / A1 ) ... H ( A / A 1 ) H ( Aj / A j 1 ) .
j 1
Для множества образованных последовательностей букв можно построить оптимальный код, причем среднее число символов ал-
фавита кодировки на одну последовательность n должно удовлетворять, по ранее доказанной теореме 7.3, соотношению
182

H (A ) |
|
|
H (A ) |
. Делим неравенство на |
|
и получаем |
||||||||||||
|
|
|||||||||||||||||
log2 D |
n log2 |
D 1 |
||||||||||||||||
|
|
|
|
1 |
|
|
|
|
1 |
|
|
|
||||||
новое соотношение |
|
H ( A ) |
|
|
|
|
n |
|
|
H (A ) |
|
1 |
. Далее более |
|||||
|
n |
|||||||||||||||||
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
log2 D |
1 |
|
|
|
|
log2 D |
|
|
|||||
детально рассмотрим величину |
|
H (A ) , |
представив ее в виде |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
суммы |
1 [H (A ) ... H (A / Ai 1 ) H ( A/ A )( i)] . Первые i |
||
|
|
1 |
i |
|
|
|
|
слагаемых суммы отражают переходной процесс условных энтропий событий, а последнее слагаемое – стационарное состояние. После перегруппировки слагаемых можно получить выражение
H (A ) H (A / A ) |
... |
H (A / Ai 1 ) H (A/ A ) |
H (A/ A |
|
) , из |
1 |
i |
|
|||
|
|
|
|
||
|
|
|
|
|
|
которого видно, что с увеличением дробные слагаемые становятся бесконечно малыми величинами. Следовательно,
lim |
1 |
H ( A ) H ( A / A ) . |
Таким образом, |
всегда можно найти |
|||||
|
|
|
|
1 |
|
|
|
|
|
такое целое , что |
|
|
|
H (A/ A ) |
|
||||
|
|
|
|||||||
|
и n log2 D |
. Полученный ре- |
|||||||
|
|||||||||
зультат завершает доказательство теоремы.
a1
A
aL
|
|
|
|
|
|
|
|
|
a1 |
... |
a1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
... |
|
|
|
|
n1 |
||
|
|
|
||||||
|
... |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
... n |
|||
aL |
... |
aL |
|
|
|
|
|
|
|
|
|
|
|
||||
|
... |
|
|
|
|
n |
||
|
|
|
||||||
|
|
|
|
|
|
L |
|
|
Рис. 8.6. Кодирование группы событий длиной
183

Отметим, что эффективность процедур кодирования для случайных источников оценивается по формуле
Эк H ( A / A ) , n log2 D
происхождение которой достаточно очевидно.
8.3. СРЕДНЕЕ ПО АНСАМБЛЮ И СРЕДНЕЕ ПО ПОСЛЕДОВАТЕЛЬНОСТИ
В доказательствах, касающихся стационарных источников, все средние величины, в частности n , H (A ) , вычислялись как сред-
нее по множеству.
На практике обычно интересуются средней длиной последовательности кодовых слов во времени, а не математическим ожиданием длины кодового слова в некоторый момент.
Кроме того, особое значение имеют процессы, в которых усреднение по множеству и усреднение по времени совпадают. Такое совпадение имеет место для эргодических стационарных источников, которые являются подклассом стационарных источников информации.
Для более детального изучения усреднения по множеству и усреднения по последовательности рассмотрим пример марковского источника.
Марковский источник характеризуется состояниями, в которых он может находиться, и правилами, управляющими его переходом из одного состояния в какое-либо другое. Буквы порождаются источником с вероятностями, зависящими только от состояния, в котором находится источник. После порождения буквы новое состояние однозначно определяется старым состоянием и этой буквой.
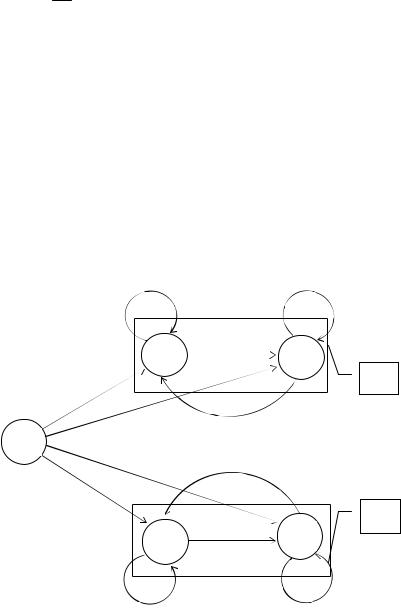
Действие источника удобно иллюстрировать граф-схемами. На рис. 8.7 приведена граф-схема разложимого марковского источни-
ка (режимы E1 и E2 ) [6]. Событие i , порождаемое источником, может быть одной из четырех букв множества A {a1 , a2 , a3 , a4 } . Каждый узел представляет собой состояние
184
S j , j 0,4 , а каждая ветвь указывает изменение состояния, про-
исшедшее в результате порождения буквы ak . Состояние S0 является начальным, имеющим место при порождении первой буквы.
Матрица условных вероятностей полностью описывает источник, а потому и ансамбль сообщений, образованный порожденными им последовательностями букв:
|
|
|
|
|
|
|
a1 |
a2 |
a3 |
a4 |
|
|
|||
|
|
|
|
S0 |
|
0,3 |
0,2 |
0,3 |
|
0,2 |
|
|
|||
|
|
|
|
|
|
|
|||||||||
|
|
|
|
S1 |
|
1/ 2 |
1/ 2 |
0 |
|
0 |
. |
||||
|
p(ak / S j ) |
S2 |
|
3/ 4 1/ 4 |
0 |
|
0 |
||||||||
|
|
|
|
|
|||||||||||
|
|
|
|
S3 |
|
0 |
0 |
2 / 3 |
|
1/ 3 |
|
|
|||
|
|
|
|
S4 |
|
0 |
0 |
1/ 2 |
|
1/ 2 |
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 ;1/ 4 |
|
a1;1/ 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
a2 ;1/ 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S2 |
|
E1 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
/ 4 |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||||
S0
/ 2
E2
|
S3 |
|
|
S4 |
|
|
|
a4 ;1/ 3 |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
a3 ;2 / |
|
|
|
|
4 ;1/ 2 |
|
|
|
|
|
|
Рис. 8.7. Граф-схема марковского источника
185

Как видно из граф-схемы, распределение вероятностей p( i ) для всех натуральных i равно:
p{ i a1} 0,3; |
p{ i a2} 0,2; |
p{ i a3} 0,3; |
p{ i a4} 0,2. |
Условное распределение вероятностей p( i / i 1) можно получить из представленной граф-схемы
|
|
|
|
|
|
a1 |
a 2 |
a3 |
a 4 |
||
|
|
|
|
a1 |
|
1/ 2 |
1/ 2 |
0 |
0 |
|
|
|
|
|
|
|
|
||||||
p( i / i 1) |
|
|
|
a2 |
|
3 / 4 1/ 4 |
0 |
0 |
|
. |
|
|
|
||||||||||
|
|
|
|
a3 |
|
0 |
0 |
2 / 3 |
1/ 3 |
|
|
|
|
|
|
a4 |
|
0 |
0 |
1/ 2 |
1/ 2 |
|
|
Условные распределения вероятностей более высоких порядков задаются соотношением
p( i / i 1, i 2 ,..., i j ) p( i / i 1) , |
j 1. |
Другими словами, условные распределения вероятностей зависят только от непосредственно предшествующего события, если это событие задано.
Источник стационарен, так как все распределения вероятностей не зависят от i . Легко убедиться в справедливости соотношения
p( i 1) p( i / i 1) p( i ) .
i 1 Ai 1
Предположим, что последовательность на выходе источника разбивается на группы событий по два. Возможные комбинации символов на выходе марковского источника и необходимые количественные оценки приведены в табл. 8.1, а распределение вероятностей случайной величины J ( 2 ) на рис. 8.8.
Энтропия ансамбля H ( A2 ) как среднее по множеству имеет вид
H ( A2 ) m[J ( 2 )] 2,88 .
Поскольку вероятность реализации режимов E1 и E2 одинакова, то по истечении некоторого времени источник будет генерировать либо последовательность a1a2 a2 a1... с энтропией ансамбля
186
H (A2 / E1 ) как среднее по временной последовательности
|
|
H ( A2 / E ) m[J ( 2 ) / E ] 2,86 , |
|
|
|
|||||
|
|
1 |
|
1 |
|
|
|
|
|
|
либо последовательность a3a3a4 a4 ... |
с энтропией ансамбля |
|||||||||
H ( A2 / E2 ) как среднее по временной последовательности |
|
|
||||||||
|
H ( A2 / E2 ) m[J ( 2 ) / E2 ] 2,90 . |
|
|
|
||||||
|
|
|
|
|
|
|
|
Таблица 8.1 |
||
|
|
|
Вероятности |
Собственная ин- |
Распределе- |
|||||
Комби- |
Режи- |
|
ние вероят- |
|||||||
|
p( i 1 i ) |
|||||||||
|
формация J ( |
2 |
) |
|||||||
нации |
мы |
|
p( i 1) p( i / i 1 ) |
|
ностей |
|||||
i 1 i |
|
log2 p( i 1 i ) |
P{J ( |
2 |
) J} |
|||||
работы |
|
|
|
|||||||
a1a1 |
|
|
0,15 |
|
|
|
|
|
|
|
a1a2 |
E1 |
|
0,15 |
|
2,70 |
|
|
0,45 |
||
a2 a1 |
|
0,15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
a2 a2 |
|
|
0,05 |
|
4,30 |
|
|
0,05 |
||
a3a3 |
|
|
0,20 |
|
2,30 |
|
|
0,20 |
||
a3a4 |
E2 |
|
0,10 |
|
|
|
|
|
|
|
a4 a3 |
|
0,10 |
|
3,30 |
|
|
0,30 |
|||
|
|
|
|
|
||||||
a4 a4 |
|
|
0,10 |
|
|
|
|
|
|
|
Последние два выражения получены с учетом того, что распределения вероятностей принимают иной вид (табл. 8.2).
|
|
Таблица 8.2 |
|
p{J ( 2 ) J / E } |
J 2,7 |
|
0,9 |
J 4,3 |
|
0,1 |
|
1 |
|
||
|
|
|
|
p{J ( 2 ) J / E } |
J 2,3 |
|
0,4 |
|
|
|
|
2 |
J 3,3 |
|
0,6 |
|
|
||
187

p{J ( 2 ) 2,7} 0,45; |
|
|
|
p{J ( 2 ) J} |
|
|||||
1 |
|
|
|
|
|
|
|
|
|
|
p{J ( 2 ) 4,3} 0,05; |
|
|
|
|
|
|
|
|
|
|
1/2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
p{J ( 2 ) 2,3} 0,20; |
|
|
|
|
|
|
|
|
|
|
p{J ( 2 ) 3,3} 0,30; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
J |
|
|
|
|
|
1 |
2 |
3 |
|
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 8.8. Распределение вероятностей J ( 2 )
В этом случае среднее по ансамблю 2,88 не совпадает со средними по временной последовательности 2,86 или 2,90.
Стационарный источник, обладающий более чем одним режимом работы, называется разложимым или приводимым. Неприводимый стационарный источник всегда эргодический. Можно показать, что любой стационарный источник можно представить как комбинацию эргодических источников.
8.4. КОДИРОВАНИЕ СОБЫТИЙ, ПОРОЖДАЕМЫХ ИСТОЧНИКОМ С ФИКСИРОВАННОЙ СКОРОСТЬЮ
До сих пор рассматривались методы кодирования для источников с управляемой скоростью, т.е. источников, в которых моменты порождения событий могут изменяться кодером (рис. 8.9).
ИИ 
 Кодер
Кодер 
Рис. 8.9. Источник с управляемой скоростью
Очевидно, что для источника с фиксированной скоростью
кодер не может передавать и кодировать слова с той же скоростью, что и источник, так как разные сообщения требуют разного числа символов. Буфер, как следует из теории массового обслуживания,
188
