

Березкин Основы теории информации и кодирования 2010
.pdfnk p(uk ) p(uk )[ log2 p(uk ) |
1] , |
n H (U ) |
1, что и |
||||||
M |
M |
|
|
|
|
|
|
|
|
|
|
log2 D |
|
|
|
|
|
|
|
k 1 |
k 1 |
|
|
|
|
log2 D |
|
||
завершает доказательство теоремы. |
|
|
|
|
|
|
|||
|
|
|
|
|
D nk 1 |
|
|||
|
|
p(u ) D nk* |
|
|
|
|
|
|
|
|
D nk |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
nk |
nk* |
nk 1 |
|
Рис. 7.4. Графическая интерпретация неравенств D nk |
p(uk ) D nk 1 |
||
7.3. МЕТОД ХАФФМАНА (ОПТИМАЛЬНОЕ КОДИРОВАНИЕ)
Метод кодирования и построения кодового дерева, основанный на равновероятном использовании символов алфавита и использующий статистическую независимость символов, как было показано выше, приводит к коду с минимальной средней длиной слова
H (U ) |
не всегда, а только в случае выполнения равенства |
n log2 D |
p(uk ) D nk .
Существует систематический метод оптимального кодирования, который приводит к оптимальному множеству кодовых слов в том смысле, что никакое множество других кодовых слов не имеет меньшего среднего числа символов на сообщение. Соответствующее кодирование предложено Хаффманом, и получаемый по этому методу код носит название кода Хаффмана. В процедуре Хаффмана все шаги строго регламентированы и никаких неоднозначностей кодирования нет. Произвольное присвоение символов алфавита кодировки различным ветвям дерева не нарушает общую структуру оптимального кода.
171
Процедура оптимального кодирования сообщений заданного множества и произвольного алфавита представлена на рис. 7.5 в виде алгоритма, который не требует дополнительных пояснений.
Рассмотрим пример построения кода Хаффмана для множества сообщений, представленных в табл. 7.3. Будем использовать алфа-
вит кодировки, состоящий из D 2 символов, для которого m0
всегда равно 2. Соответствующая процедура формирования кодовых слов приведена на рис. 7.6. Эффективность кодирования со-
ставила Э |
H (U ) |
|
2,55 |
0,98 . Построенное кодовое дерево |
||||||||
|
|
|
|
|||||||||
к |
|
nlog2 D |
2,60 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|||||
является полным. |
|
|
|
|
Таблица 7.3 |
|||||||
|
|
|
|
|
|
|
|
|||||
|
|
Сообщения |
|
Вероятности |
|
|
|
Код |
|
|||
|
|
|
uk |
|
|
|
p(uk ) |
|
|
Хаффмана |
|
|
|
|
|
u1 |
|
|
|
0,3 |
|
00 |
|
||
|
|
|
u2 |
|
|
|
0,2 |
|
10 |
|
||
|
|
|
u3 |
|
|
|
0,2 |
|
11 |
|
||
|
|
|
u4 |
|
|
|
0,1 |
|
011 |
|
||
|
|
|
u5 |
|
|
|
0,1 |
|
0100 |
|
||
|
|
|
u6 |
|
|
|
0,05 |
|
01010 |
|
||
|
|
|
u7 |
|
|
|
0,05 |
|
01011 |
|
||
|
H (U ) 2,55 |
|
p(uk ) 1 |
|
|
|
2,6 |
|
||||
|
|
|
|
n |
|
|||||||
|
|
|
|
|
|
|
U |
|
|
|
|
|
Рассмотрим другой пример построения кода Хаффмана для множества сообщений, представленных в табл. 7.4. Будем использовать алфавит кодировки, состоящий из трех символов. В этом случае процедура Хаффмана предполагает на первом шаге объеди-
нение m0 2 сообщений с наименьшими вероятностями и D 3 на последующих шагах (рис. 7.7). Эффективность кодирования
составила Э |
|
H (U ) |
|
2,45 |
0,91. Построенное кодовое де- |
|
|
|
|||
к |
nlog2 D |
1,7 1,58 |
|||
|
|||||
рево является неполным.
172
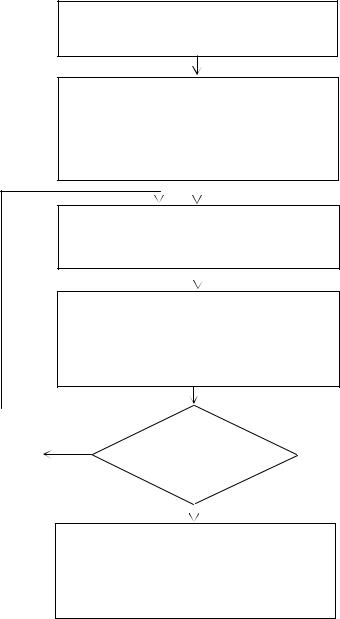
Присвоим i : 0 . M сообщений первоначального
i -го множества располагаем в порядке убывания вероятностей
Находим
условиям:
наименьшее m0 , удовлетворяющее
|
2 m0 |
D ; |
где a – целое положи- |
|
|
|
|
M m0 |
a , |
|
|
|
D 1 |
|
|
|
|
|
|
тельное число. Присвоим j : m0
Группируем вместе j сообщений i -го множест-
ва, имеющих наименьшие вероятности, и вычисляем общую вероятность такой группы – p j
Определяем ( i 1 )-е вспомогательное множество сообщений, рассматривая группу из j сообщений
как отдельное сообщение с вероятностью p j .
Располагаем сообщения ( i 1 )-го вспомогательного множества в порядке убывания вероятностей
Выполним |
|
Вспомогательное |
|
операции |
Нет |
||
присвоения: |
( i 1 )-е множество содержит |
||
|
|||
i : i 1; |
|
единственное сообщение? |
|
j : D |
|
|
|
|
|
Да |
|
|
|
Строим кодовое дерево, в котором первоначальные сообщения являются концевыми узлами. Соответствующие им кодовые слова формируем, приписывая различные символы из заданного алфавита ветвям, исходящим из каждого промежуточного узла дерева
Рис. 7.5. Алгоритм процедуры Хаффмана
173

u1 u2 u3 u4 u5 u6 u7
0,3 |
|
|
|
|
0,3 |
|
|
|
0,3 |
|
|
|
|
0,3 |
|
|
|
|
|
|
0,4 |
|
|
0,6 |
|
0 |
1 |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
1 |
|
|
||||||||||||||||||||
0,2 |
|
|
|
|
|
0,2 |
|
|
|
|
|
|
0,2 |
|
|
|
|
|
0,3 |
|
|
|
|
|
|
0,3 |
|
0,4 |
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
1 |
|
|
|
|
||||||||||||||||||
0,2 |
|
|
|
|
0,2 |
|
|
|
0,2 |
|
|
|
|
0,2 |
|
|
0,3 |
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
0 |
|
|
1 |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
0,1 |
|
|
|
0,1 |
|
|
0,2 |
|
|
0,2 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
0,1 |
|
|
|
0,1 |
|
0 |
0,1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
0,05 |
|
0 |
|
|
|
|
0,1 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
0,05 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Рис. 7.6. Процедура оптимального кодирования для D 2 |
|
|
|
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 7.4 |
|
|
|
|
|
|
|||||||||||
|
Сообщения |
|
|
Вероятности |
|
|
|
|
|
|
Код |
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
uk |
|
|
|
|
|
|
|
|
|
|
|
|
|
p(uk ) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Хаффмана |
|
|
|
|
|
|
|||||||||||||
|
|
|
u1 |
|
|
|
|
|
|
|
|
0,3 |
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
u2 |
|
|
|
|
|
|
|
|
0,2 |
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
u3 |
|
|
|
|
|
|
|
|
0,2 |
|
|
|
|
|
|
|
00 |
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
u4 |
|
|
|
|
|
|
|
|
0,1 |
|
|
|
|
|
|
|
02 |
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
u5 |
|
|
|
|
|
|
|
|
0,1 |
|
|
|
|
|
|
|
010 |
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
u6 |
|
|
|
|
|
|
|
|
0,1 |
|
|
|
|
|
|
|
011 |
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
H (U ) 2,45 |
|
p(uk ) 1 |
|
|
|
|
|
1,7 |
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
n |
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
U |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
u1 |
|
0,3 |
|
|
|
|
|
|
|
|
|
|
0,3 |
|
|
|
|
|
0,5 |
|
|
|
|
|
1 |
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
||||||||||||||
|
u2 |
|
0,2 |
|
|
|
|
|
|
|
|
|
|
0,2 |
|
|
|
|
|
0,3 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|||||||||||||
|
u3 |
|
0,2 |
|
|
|
|
|
|
|
|
|
|
0,2 |
|
|
0 |
|
0,2 |
|
|
2 |
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
u4 |
|
0,1 |
|
|
|
|
|
|
|
|
|
|
0,2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
u5 |
|
0,1 |
|
|
|
|
|
|
|
|
|
0,1 |
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
u6 |
|
0,1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
Рис. 7.7. Процедура оптимального кодирования для D 3
174
ЗАДАЧИ
7.1. Для заданного ансамбля сообщений построить код Шенно- на–Фано (D 2) :
xk |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
p(xk ) |
0,3 |
0,2 |
0,2 |
0,1 |
0,1 |
0,05 |
0,05 |
Оценить эффективность кодирования. Построить кодовые деревья.
7.2. Найти оптимальный троичный код для ансамбля сообщений
xk |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
p(xk ) |
0,3 |
0,25 |
0,13 |
0,12 |
0,11 |
0,09 |
Построить кодовое дерево. Оценить эффективность кодирования.
7.3. Задано множество сообщений
xk |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
x8 |
p(xk ) |
0,4 |
0,17 |
0,11 |
0,09 |
0,08 |
0,06 |
0,05 |
0,04 |
Закодировать сообщения с использованием кодов Хаффмана и Шеннона–Фано (D 3) . Сравнить эффективности кодирования.
175

8. ДИСКРЕТНЫЕ ИСТОЧНИКИ ИНФОРМАЦИИ
Под дискретным источником информации будем понимать источник, который порождает конечное число сообщений. К этому типу источников можно отнести книжный текст, множество телеграфных сообщений и т.п. Соответственно, источники, на выходе которых появляется непрерывно меняющаяся величина, естественно называть непрерывным источником информации.
До сих пор рассматривались сообщения uk U безотноситель-
но к тому, что на выходе источника во времени появляется последовательность сообщений, а энтропия вычислялась как среднее по
ансамблю U {uk }, k 1, M , т.е.
M
H (U ) p(uk ) log2 p(uk ) log2 M .
k1
8.1.ДИСКРЕТНЫЕ ИСТОЧНИКИ, ПОРОЖДАЮЩИЕ СТАТИСТИЧЕСКИ НЕЗАВИСИМЫЕ СООБЩЕНИЯ
Разделим порождаемую источником последовательность сообщений на подпоследовательности равной длины, каждая из которых содержит сообщений (рис. 8.1). Число различных последо-
вательностей из сообщений равно M . Формула автоматически следует из выражения для числа перестановок из M по с уче-
том повторений PM M . Каждая - я последовательность явля-
ется элементом декартового произведения множеств U , причем
U M .
ИИ  ... ... ... ... ...
... ... ... ... ...
uk U
Рис. 8.1. Разбиение последовательности независимых сообщений на группы
176

ТЕОРЕМА 8.1. При любом заданном как угодно малом положительном числе 0 можно найти натуральное число и соответ-
ствующее множество кодовых слов мощности M , такое, что среднее число символов алфавита кодировки на сообщение удов-
летворяет неравенству n H (U ) . log2 D
ДОКАЗАТЕЛЬСТВО. Используя символы заданного алфавита кодировки, закодируем последовательности сообщений длиной кодовыми словами с длинами, удовлетворяющими неравен-
ству Крафта (рис. 8.2). Пусть n – среднее число символов на ко-
довое слово, а |
|
|
n |
– среднее число символов на сообщение. |
n |
||||
|
|
|
|
|
Тогда из основной теоремы кодирования следует неравенство для
|
|
: |
H (U ) |
|
|
H (U ) 1. В силу статистической независимо- |
||||||||||||||||||||
|
n |
|
|
|
||||||||||||||||||||||
|
n |
|||||||||||||||||||||||||
|
|
|
log2 D |
|
|
|
log2 D |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
сти |
сообщений, |
|
|
|
порождаемых |
|
|
|
|
источником, |
||||||||||||||||
|
H (U ) H (U U ... U ) H (U ) имеем: |
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
H (U ) |
|
|
|
H (U ) 1; |
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
n |
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
log2 D |
|
|
|
|
|
|
log2 D |
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
H (U ) |
|
|
|
|
|
|
|
|
H (U ) |
1 . |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
n |
|
|
|
||||||||||||||
|
|
|
|
|
|
|
n |
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
log2 D |
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
log2 D |
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u |
u |
... |
|
u |
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
1 |
1 |
|
|
|
|
|
|
1 |
|
|
|
|
n1 |
|
|
||||
|
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
U |
|
|
|
|
... |
|
|
|
|
|
|
|
... |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
||||||||||
|
|
|
|
|
|
|
|
uM |
... |
|
uM |
|
|
|
|
|
||||||||||
|
|
|
|
|
|
uM |
|
|
n |
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
M |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Рис. 8.2. Кодирование последовательностей сообщений длиной
177

Положим |
1 |
|
|
|
H (U ) |
. |
|
, тогда |
n |
||||||
|
log2 D |
||||||
|
|
|
|
|
Основной же вывод состоит в том, что если кодируется последовательность статистически независимых сообщений вместо кодировки отдельных сообщений, то это дает возможность умень-
шить среднюю величину n не более чем на один символ. Докажем соотношение H (U ) H (U ) , использованное вы-
ше, для простого случая U 2 . Пусть p(uk ) pk , k {1,2}. Образуем последовательности из сообщений, общее число которых
составит 2 . Ниже приводятся подробные соответствующие преобразования, не представляющие серьезных трудностей для понимания:
|
|
|
|
|
|
|
|
|
||
H (U ) |
|
|
p k pk log |
p k pk |
|
|
p k pk ( k) log |
p |
||
|
|
|
1 2 |
2 1 2 |
|
|
1 2 |
2 1 |
||
|
k 0 |
k |
|
|
k 0 |
k |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
p k |
pk k log |
|
|
p |
p log |
p |
|
|
p k |
1 pk |
( k) |
|
|
|
|||||||||||||
|
|
|
|
1 |
|
2 |
|
|
2 2 |
1 |
|
2 1 |
|
1 |
|
2 |
|
|
|
|
|
|
|
|
||||||
|
k 0 |
k |
|
|
|
|
k |
|
|
k 1 |
|
|
|
k 0 |
k |
|
|
|
|
k 1 k |
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
!( k) |
|
|
|
||||||||||||||
p log |
p |
|
|
|
p |
|
|
p |
2 |
k p log |
2 |
p |
|
|
|
|
|
p |
|
|
p |
2 |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
2 |
|
2 2 |
|
1 |
|
|
|
|
1 |
|
1 |
k!( k)! |
1 |
|
|
|
|
||||||||||||
|
|
|
|
|
k 0 |
k |
|
|
|
|
|
|
|
|
|
|
k 0 |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
!k |
|
|
|
|
|
|
|
|
|
|
|
1 |
|
1 |
|
|
|
|
|
||||||
p log |
|
p |
|
|
|
|
|
|
p k pk 1 p |
log |
p |
|
|
|
p k 1 pk |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
2 |
|
2 2 |
|
|
|
|
|
|
1 |
2 |
|
|
1 |
|
2 1 |
k |
|
1 |
|
|
2 |
|
||||||||
|
|
|
k 0 k!( k)! |
|
|
|
|
|
|
|
|
k 0 |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
p log |
|
p |
|
|
|
|
|
p k pk 1 |
[( p p ) 1 p log |
p |
|
|
|
|||||||||||||||||
|
2 |
|
2 2 |
|
|
|
|
|
1 |
2 |
|
|
|
1 |
|
2 |
|
1 |
|
|
|
2 1 |
|
|
|
|
||||
|
|
|
|
|
|
|
k 1 |
k |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
( p1 p2 ) 1 p2 log2 p2 ] [ p1 log2 p1 p2 log2 p2 ] H (U ).
8.2.СЛУЧАЙНЫЕ ДИСКРЕТНЫЕ ИСТОЧНИКИ
Пусть 1 2 ... i ... – последовательность статистически зависимых событий на выходе источника. Каждое конкретное событие
i |
может быть одной из L букв a1a2 ...ak ...aL множества |
||
Ai |
{ak }, k |
|
(рис. 8.3). Уменьшение избыточности, обуслов- |
1, L |
|||
178
ленной наличием статистических связей между буквами, может быть достигнуто кодированием не отдельных элементарных букв, а составленных из них групп длиной . Подобный метод уменьшения межбуквенных статистических связей часто называют декор-
реляцией.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 2... i ... |
|
1... n... |
||
ИИ |
|
... ... |
|
|
... ... |
|
|
||||||
|
|
a |
|
|
|
|
|
|
|
|
|
||
|
1 |
|
|
|
Индекс i |
|
|
... |
|
|
|
||
|
|
ak |
|
Ai |
указывает |
|
|
|
|
позицию |
|||
|
... |
|
|
|
буквы |
|
|
|
|
|
|
||
|
|
aL |
|
|
|
|
|
|
|
|
|
|
|
Рис. 8.3. Разбиение последовательности зависимых событий на группы
Прежде чем переходить к кодированию, дадим математическое описание случайных источников. Множество, порождаемых источником последовательностей, описывается совокупностью условных вероятностей:
p( 1) p{ 1 ak } L ;
p( 2 / 1) p{ 2 aj / 1 ak } L2 ;
p( 3 / 1 2 ) p{ 3 ad / 1 ak , 2 aj} L3;
...
p( i / 1 2... i 1) p{ i am / 1 ak , 2 aj ,..., i 1 as} Li .
Совместная вероятность появления на выходе источника пер-
вых событий есть p( 1 2 ... ) p( 1 ) p( 2 / 1 )...p( / 1... 1 ) ,
а совместное распределение ( 1) -го и -го событий равно
p( 1 ) ... p( 1... 2 1 ) .
A1 A 2
179
Описание последовательностей событий через условные вероятности приводит к следующим формулам определения энтропии события на выходе источника:
1 |
H ( A1 ) p( 1 ) log2 |
|
p( 1 ) ; |
|
|||
1 A1 |
|
A |
|
|
|
|
|
|
|
1 |
1 |
|
|
|
|
1 |
2 |
H ( A2 / A1 ) p( 1 2 ) log2 |
p( 2 / 1 ) ; |
||||
1 A1 |
2 A2 |
|
A |
2 |
A |
|
|
|
|
|
1 |
1 |
2 |
|
|
|
|
|
... |
|
|
|
|
1 |
2 |
... i H ( Ai / A1...Ai 1 ) |
|
||||
1 A1 |
2 A2 |
i Ai |
|
|
|
|
|
|
|
... p( 1 2 ... i ) log2 |
p( i / 1 2 ... i 1 ). |
||||
|
|
1 A1 2 A2 i Ai |
|
|
|
||
Обозначим через |
H ( A / A ) |
|
условную энтропию i -го события |
||||
при условии, что |
i |
|
|
|
|
||
предшествующих событий уже произошло |
|||||||
(рис. 8.4): |
|
|
|
|
|
||
H (Ai / A ) ... p( i ... i 1 i ) log2 |
p( i / i ... i 1 ) |
||||
Ai |
Ai 1 |
Ai |
|
|
|
|
H ( Ai / Ai 1...Ai ). |
|
|
||
i |
i 1 |
i 2 ... |
i 1 |
i |
|
|
|
|
... |
|
|
|
1 |
2 |
3 ... |
|
i |
|
|
|
1 |
|
|
Рис. 8.4. Иллюстрация условной энтропии H (Ai / A )
ОПРЕДЕЛЕНИЕ 8.1. Источник информации называют стационарным, если условная вероятность появления события i при
условии задания предшествующих событий не зависит от номера i для всех целых , т.е.
p( i / i 1... i ) p( j / j 1... j ); i, j .
180