

Pro Visual C++-CLI And The .NET 2.0 Platform (2006) [eng]-1
.pdf78 |
C H A P T E R 2 ■ C + + / C L I B A S I C S |
Returning Handles
You need to take care when you return a handle from a function.
■Caution Never return a handle to a variable of local scope to a function, because it will not be a valid handle on exiting the function.
Never do this:
ref class |
RefClass {}; |
|
RefClass^ |
ERRORexample() |
|
{ |
|
|
RefClass a; |
|
|
// do |
some stuff; |
|
return %a; |
// This variable will disappear when the function ends, so |
|
|
|
// reference will be invalid |
} |
|
|
Instead, you should return the handle a that was passed to the function or the handle b that was created by the gcnew operator in the function:
ref class RefClass
{
public: int X;
RefClass(int x) : X(x) {}
};
RefClass^ Okexample(RefClass^ a)
{
RefClass^ b = gcnew RefClass(8); // do some stuff;
if (a->X > b->X) return a;
else
return b;
}
void main()
{
RefClass ^r = gcnew RefClass(7); RefClass ^a = Okexample(r);
}
In traditional C++, the variable b in the preceding example would be a classic location for a memory leak, because the developer would have to remember to call the delete statement on the returned value b. This is not the case in C++/CLI, because handles are garbage collected automatically when no longer used; thus delete need not be called.
Returning References
You also need to take care when you return a reference from a function.

C H A P T E R 2 ■ C + + / C L I B A S I C S |
79 |
■Caution Never return a reference to a variable of local scope to a function, because it will not be a valid reference on exiting the function.
Never do this:
ref class RefClass {};
RefClass% ERRORexample()
{
RefClass a;
// do some stuff;
return a; |
// This variable will disappear when the function ends, so |
|
// reference will be invalid |
} |
|
Instead, you should return a reference that was passed to the function, or a pointer or reference to a variable that was created by the gcnew operator within the function:
ref class RefClass
{
public: int X;
RefClass(int x) : X(x) {}
};
RefClass% Okexample(RefClass %a)
{
RefClass^ b = gcnew RefClass(8); // do some stuff;
if (a.X > b->X) return a;
else
return *b;
}
void main()
{
RefClass r(9);
RefClass %a = Okexample(r);
}
Something worth noting in this function is the creation of a reference using the gcnew operator. Again, with traditional C++ you would have to delete the reference. Fortunately, because handles get garbage collected in C++/CLI, there is no need for the delete statement and no memory leak occurs.
Prototypes
You can’t use a function until it has been defined. Okay, there is nothing stopping you from placing function declarations in every *.cpp file where it is used, but then you would have a lot of redundant code.
The correct approach is to create prototypes of your functions and place them within an include (.h) file. (I cover include files in Chapter 4.) This way, the compiler will have the definition
80 |
C H A P T E R 2 ■ C + + / C L I B A S I C S |
it needs, and the function implementation will be in only one place. A prototype is simply a function without its body followed by a semicolon:
int example ( const int %a );
Function Overloading
In the dark ages of C, it was a common practice to have many functions with very similar names doing the same functionality for different data types. For example, you would see functions such as
PrintInt(int x) to print an integer, PrintChar(char c) to print a character, PrintString(char *s) to print an array of characters, and so on. Having many names doing the same thing became quite a pain. Then, along came C++, and now C++/CLI, with an elegant solution to this annoyance: function overloading.
Function overloading is simply C++/CLI’s way of having two or more methods with exactly the same name but with a different number or type of parameter. Usually, the overloaded functions provide the same functionality but use different data types. Sometimes the overloaded functions provide a more customized functionality as a result of having more parameters to more accurately solve the problem. But, in truth, the two overloaded functions could do completely different things. This, however, would probably be an unwise design decision, as most developers would expect similar functionality from functions using the same name.
When a function overloaded call takes place, the version of the method to run is determined at compile time by matching the calling function’s signature with those of the overloaded function. A function signature is simply a combination of the function name, number of parameters, and types of parameters. For function overloading, the return type is not significant when it comes to determining the correct method. In fact, it is not possible to overload functions by changing only the return type. If you do this, the compiler will give a bunch of errors, but only the one indicating that a function is duplicated is relevant.
There is nothing special about coding overloaded functions. For example, here is one function overloaded three times for the supersecret Test function:
int Test () { /* |
do stuff */ } |
|
int |
Test (int x) |
{ /* do stuff */ } |
int |
Test (int x, |
int y, double z) { /* do stuff */ } |
Calling an overloaded function is nothing special either. Simply call the function you want with the correct parameters. For example, here is some code to call the third supersecret Test function:
Test (0, 1, 2.0);
The only thing that C++/CLI programmers need to concern themselves with that traditional C++ programmers do not is that fundamental types and their corresponding runtime value types produce the same signature. Thus, these two functions are the same and will produce an error:
Int32 Test (Int32 x) { /* do stuff */ }
int Test (int x) { /* do stuff */ } // Error Duplicate definition of Test
Passing Arguments to the main() Function
So far in every example in this book, the main() function has had no arguments. If you have worked with C++ before, you know that it is possible to retrieve the parameters passed to a program from the command line via the main() function’s arguments. (If you haven’t, well, now you do.)
C++/CLI has made a rather large change to the main() function, especially if you come from the traditional C++ world or even from the Managed Extensions for C++ world. You now have a choice of main() functions.

C H A P T E R 2 ■ C + + / C L I B A S I C S |
81 |
int main ( int argc, char *argv[] )
The first choice is the standard main() function, which counts all the parameters passed to it, including the program that is being run, and places the count in the first argument, traditionally called argc. Next, it takes all the parameters and places them in an unmanaged pointer to char array, with each parameter being a separate element of the array. Finally, it passes a pointer to this array as the second argument, usually called argv.
■Unsafe Code Passing arguments to this main() function is unsafe code because it uses pointers to pass the values.
Yep, I said pointer. Alarms should have gone off in your head—yes, passing arguments to the main() function using this choice is unsafe code, as passing arguments in this fashion actually compiles to native code and not MSIL code, so the argv argument is not garbage collected. Fortunately, the cleanup of argv is handled automatically (so, you could say that it is sort of garbage collected). Unfortunately, because it is not garbage collected, it adds a major wrinkle when compiling. You can’t use the option /clr:safe. Instead, you can use /clr or /clr:pure.
Listing 2-15 is a little program that reads in all the parameters passed to it and then writes them out.
Listing 2-15. Parsing a Command Line the Traditional Method
using namespace System;
// Passing parameters to main() traditional method int main ( int argc, char *argv[] )
{
Console::WriteLine ( argc.ToString() ); for (int i = 0; i < argc; i++)
{
Console::WriteLine ( gcnew String(argv[i]) );
}
return 0;
}
Figure 2-16 shows the results of this little program when passed the parameter “This is a test this is only a test”.
Figure 2-16. Results of MainArgsTrad.exe
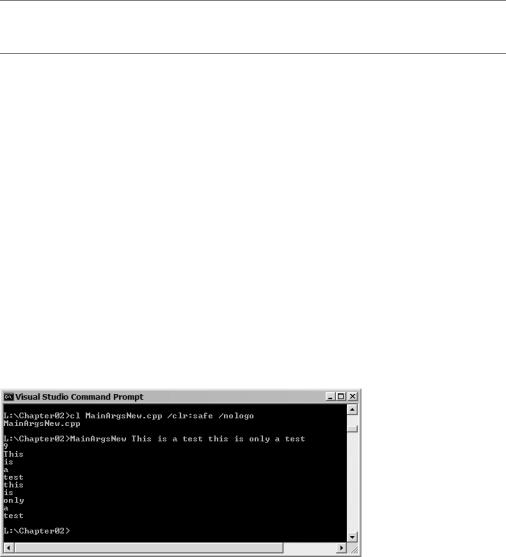
82 |
C H A P T E R 2 ■ C + + / C L I B A S I C S |
int main ( array<System::String ^> ^args )
The second choice more resembles the static main() method of C#. It simply takes all the parameters and places them on a managed array.
One advantage of this type of main() function is that it doesn’t need to have the number of elements being passed, because the managed array provides the number of the argument in a property called Length. By the way, if you process the args array using the for each method, you won’t even need to know how many arguments are being passed.
Another major advantage of this choice of main() function is that it is safe and can be compiled using the /clr:safe option.
■Caution The first element of the args array is not the name program being run as you would expect in the traditional main() function. Instead, it is the first parameter passed to the program.
Listing 2-16 is a little program that reads in all the parameters passed to it and then writes them out.
Listing 2-16. Parsing a Command Line the New Method
using namespace System;
// Passing parameters to main() new method int main(array<System::String ^> ^args)
{
Console::WriteLine (args->Length);
for each (String^ s in args)
{
Console::WriteLine(s);
}
return 0;
}
Figure 2-17 shows the results of this little program when passed the parameter “This is a test this is only a test”. Notice the number of arguments passed is one less than the traditional main() function, as the program name is not passed.
Figure 2-17. Results of MainArgsNew.exe
C H A P T E R 2 ■ C + + / C L I B A S I C S |
83 |
Summary
I covered a lot of ground in this chapter, starting with variables and C++/CLI’s fundamental types. Next, you learned about literals and operators. Then you examined two basic C++/CLI constructs: flow control and looping. You finished by exploring functions.
For the traditional C++ programmer, much of this chapter was not new. The areas that you should pay close attention to are .NET Framework class library fundamental data types, Strings, value types, arrays, all the literals (in particular, string literals), and returning pointers and references from functions.
In the next chapter, you will continue to expand on your knowledge of the basics. This time, you will focus on the object-oriented aspects of C++/CLI.

C H A P T E R 3
■ ■ ■
Object-Oriented C++/CLI
In the previous chapter, I covered in detail the basics of C++/CLI, focusing on programming strictly in a procedural style. This chapter explores the real strength of C++/CLI: as an object-oriented language.
The chapter starts with a review of object-oriented programming (OOP) in general. You will then explore C++/CLI’s OOP capabilities, focusing primarily on ref classes, which are the cornerstones of C++/CLI OOP. You will do this by breaking ref classes down into their parts and examining each part in detail. Finally, you will learn about interfaces.
■Caution Don’t skip this chapter, even if you know C++ very well, because several things are different between traditional C++ and C++/CLI. True, some of the changes may not be significant, but recognizing and understanding these changes now may make your life easier in the future.
OOP is more a way of thinking than a programming technique. For those making the transition from procedural programming, you must understand that OOP will involve a paradigm shift for you. But, once you realize this and make the shift, you will wonder why you programmed any other way.
OOP is just an abstraction taken from everyday life and applied to software development. The world is made up of objects. In front of you is a book. It is an object. You are sitting on a chair or a couch, or you might be lying on a bed—all objects. I could go on, but I’m sure you get the point. Almost every aspect of our lives revolves around interacting with, fixing, and improving objects.
It should be second nature to do the same thing with software development.
Object-Oriented Concepts
All objects support three specific concepts: encapsulation, inheritance, and polymorphism. Think about the objects around you—no, scratch that; think about yourself. You are an object: You are made up of arms, legs, a torso, and a head, but how they work does not matter to you—this is encapsulation. You are a mammal, human, and male or female—this is inheritance. When greeted, you respond with “Good day,” “Bonjour,” “Guten Tag,” or “Buon giorno”—this is polymorphism.
As you shall see shortly, you can apply the object paradigm to software development as well. C++/CLI does it by using software objects called ref classes and ref structs. But before I get into software objects, let’s examine the concepts of an object more generically.
Encapsulation
All objects are made up of a combination of different things or objects. Many of these things are not of any concern to the other objects that interact with them. Going back to you as an example of an
85
86 |
C H A P T E R 3 ■ O B J E C T - O R I E N T E D C + + / C L I |
object, you are made up of things such as blood, muscles, and bone, but most objects that interact with you don’t care about that level of things. Most objects that interact with you only care that you have hands, a mouth, ears, and other features at this level of abstraction.
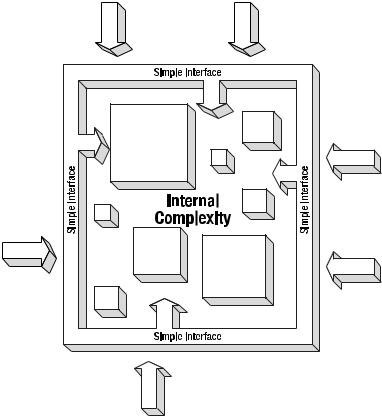
Encapsulation basically means hiding the parts of an object that do things internally from other objects that interact with it. As you saw in the previous example, the internal workings of hands, a mouth, and ears are irrelevant to other objects that interact with you.
Encapsulation is generally used to simplify the model that other objects have to interact with. It allows other objects to only be concerned with using the right interface and passing the correct input to get the required response. For example, a car is a very complex object. But, to me, a car is simple: A steering wheel, an accelerator, and a brake represent the interface; and turning the steering wheel, stepping on the accelerator, and stepping on the brake represent input.
Encapsulation also allows an object to be fixed, updated, or replaced without having to change the other objects interacting with it. When I trade in my Mustang LX for a Mustang GT, I still only have to worry about turning the steering wheel, stepping on the accelerator, and stepping on the brake.
The most important thing about encapsulation is that because portions of the object are protected from external access, it is possible to maintain the internal integrity of the object. This is because it is possible to allow only indirect access, or no access at all, to private features of the object.
Inheritance
Inheritance is hardly a new concept. We all inherit many traits (good and bad) from both of our parents. We also inherit many traits from being a mammal, such as being born, being nursed, having four limbs, and so on. Being human, we inherit the traits of opposable thumbs, upright stature, capacity for language, and so forth. I’m sure you get the idea. Other objects also inherit from other more generic objects.
You can think of inheritance as a tree of objects starting with the most generic traits and expanding to the most specific. Each level of the tree expands on the definition of the previous level, until finally the object is fully defined. Inheritance allows for the reuse of previously defined objects. For example, when you say that a Mustang is a car, you know that it has four wheels and an engine. In this scenario, the base object definition came for free—you didn’t have to define it again.
Notice, though, that a Mustang is always a car, but a car need not be a Mustang. The car could be a Ferrari. The link of inheritance is one way, toward the root.
Polymorphism
The hardest concept to grasp is polymorphism—not that it’s difficult, but it’s just taken so much for granted that it’s almost completely overlooked. Polymorphism is simply the ability for different objects derived from a common base object to respond to the same stimuli in completely different ways.
For example, (well-trained) cats, dogs, and birds are all animals, but when asked to speak, they will all respond differently. (I added “well-trained” because normally a cat will look at you as if you are crazy, a dog will be to busy chasing his tail, and a bird will squawk even if you don’t ask it to do anything.)
You can’t have polymorphism without inheritance, as the stimuli that the object is expected to respond to must be to an interface that all objects have in common. In the preceding example, you are asking an animal to speak. Depending on the type of animal (inheritance), you will get a different response.
A key thing about polymorphism is that you know that you will get a response of a certain type, but the object responding—not the object requesting—determines what the actual response will be.
C H A P T E R 3 ■ O B J E C T - O R I E N T E D C + + / C L I |
87 |
Applying Objects to Software Development
Okay, you know what objects and their concepts are and how to apply them to software development. With procedural programming, there is no concept of an object, just a continual stream of logic and data. Let me back up a bit on that. It could be argued that, even in procedural programming, objects exist, given that variables, literals, and constants could be considered objects (albeit simple ones). In procedural programming, breaking up the logic into smaller, more manageable pieces is done by way of functions. To group common data elements together, the structure or class is used depending on language.
Before you jump on me, I would like to note that there were (obviously) other object-oriented languages before C++, but this book only covers C++/CLI’s history. It wasn’t until C++ that computer data and its associated logic was packaged together into the struct and a new construct known as the class. (If you are a purist, there was “C with Classes” first.) With the combination of data and logic associated with this data into a single construct, object-oriented concepts could be applied to programming.
Here, in a nutshell, is how objected-oriented concepts are applied to C++/CLI development. Classes and structures are programming constructs that implement within the C++ language the three key object-oriented concepts: encapsulation, inheritance, and polymorphism.
Encapsulation, or the hiding of complexity, is accomplished by not allowing access to all data and functionality found in a class. Instead, only a simpler and more restricted interface is provided to access the class.