

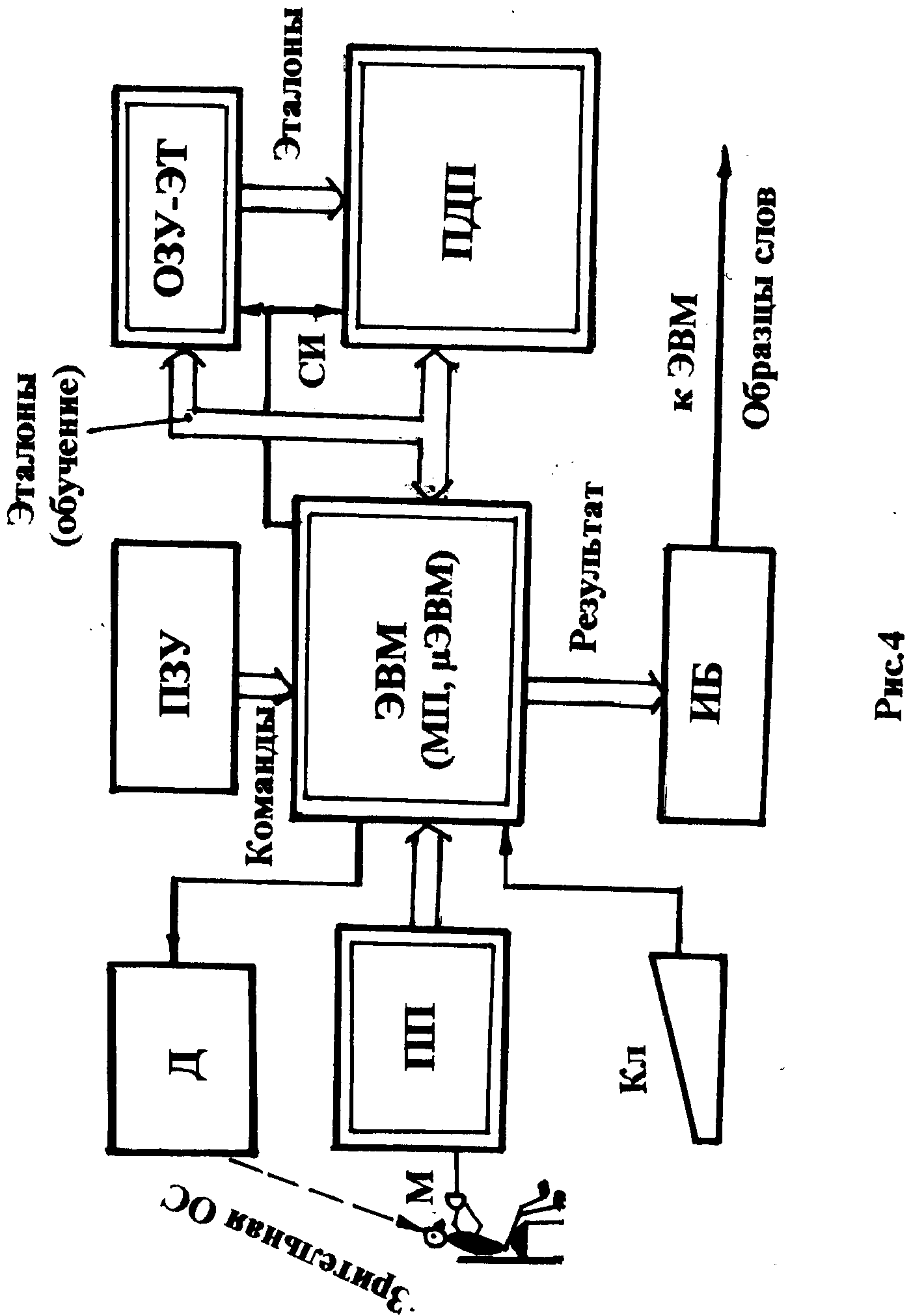
Обобщённая структура устройства распознавания речи
Обобщённая структура устройства распознавания речи (УРВ) приведена на рис.4. В приведённой структуре УРВ используется метод спектрального представления речевого сигнала.
На структурной схеме использованы следующие обозначения:
Д– дисплей (минидисплей) устройство, замыкающее цепь обратной связи, позволяющее информировать диктора о состоянии устройства (режим подсказок диктору);
ПЗУ– постоянное запоминающее устройство, хранящее микропро-граммы управления ЭВМ нижнего уровня (МП, μЭВМ);
ОЗУ-ЭТ– оперативное запоминающее устройство эталонов, храня- щее эталоны;
ПП– предпроцессор, аналого-цифровое вычислительное устройство, осуществляющее спектральный анализ речевого сигнала с последующим преобразованием данных в цифровую форму.
ЭВМ(МП,μЭВМ) – ЭВМ нижнего уровня, управляющая потоками информации в УРВ;
ПДП– процессор динамического программирования, осуществляю-щий вычисление мер сходства между реализациями и эталонами;
Кл– клавиатура;
ИБ– интерфейсный блок (интерфейс), связывающий УРВ с ЭВМ верхнего уровня.
Данная структура функционирует в полном соответствии с моделью устройства речевого ввода, рассмотренного выше.
Определённую специфику в данную структуру вносит предпроцес-сор, который реализует начальную стадию работы устройства как в режиме обучения (создания словаря), так и в режиме распознавания. Структура предпроцессора во многом определяет работу УРВ в целом.
2.3 Структура и функции предпроцессора
Как уже отмечалось выше, предпроцессор, являясь специализирован-ным вычислительным устройством аналого-цифрового типа, выполняет первичную обработку и преобразование речевого сигнала.
В основу алгоритма работы предпроцессора могут быть положены различные методы образования признаковых параметров, характеризующих аналоговый речевой сигнал. В зависимости от выбранного метода изменяется не только структура предпроцессора, но и в той или иной мере и структура всего УРВ. В приведённой на рис.5 структурной схеме предпроцессора используется метод разложения речевого сигнала на его спектральные составляющие с последующим преобразованием составляющих спектра в цифровую форму.
В структуре предпроцессора можно выделить несколько основных блоков (второстепенные блоки опущены, так как они играют вспомогательную роль). На структуре предпроцессора приняты следующие обозначения:
М– микрофон диктора;
У– усилитель, осуществляющий усиление сигнала, поступающего с микрофона и нормирующего амплитуду (размах) речевого сигнала до необходимого уровня, принятого в данном устройстве (ПП);
БПФ– блок полосовых фильтров «вырезающих» из сравнительного широкополосного речевого сигнала ряд гармонических сигналов с часто-тамиf1, f2, f3, …,fn. В блоке полосовых фильтров количество его элементов выбирается в зависимости от заданного диапазона частот речевого сигнала и составляет для разных вариантов УРВ величинуn=5 – 12-16, а иногда значительно больше. Частотаf1 является (как правило) частотой основного тона речевого сигнала (см. ниже).
На выходах БПФ образуется n напряжений синусоидальной формыUf,i , которые по частоте равномерно распределены в диапазоне f1 – fn. Этот набор «гармоник» представляет собой спектр речевого сигнала, зафиксированного в ряде точек частотного диапазона речевого сигнала. Гармонические колебанияUf,i подаются на соответствующие входы блока детектирования для дальнейшей обработки спектральных составляющих речевого сигнала.
БД– блок детектирования; осуществляет образование и запоминание максимальных амплитуд сигналовUf,i в каждом из частотных каналов или (амплитуд этих сигналов, превышающих заданный уровень).
КОМ– высокочастотный коммутатор, осуществляющий под управ-лением МП подачу компонентовX1,к – Xn,кна АЦП.
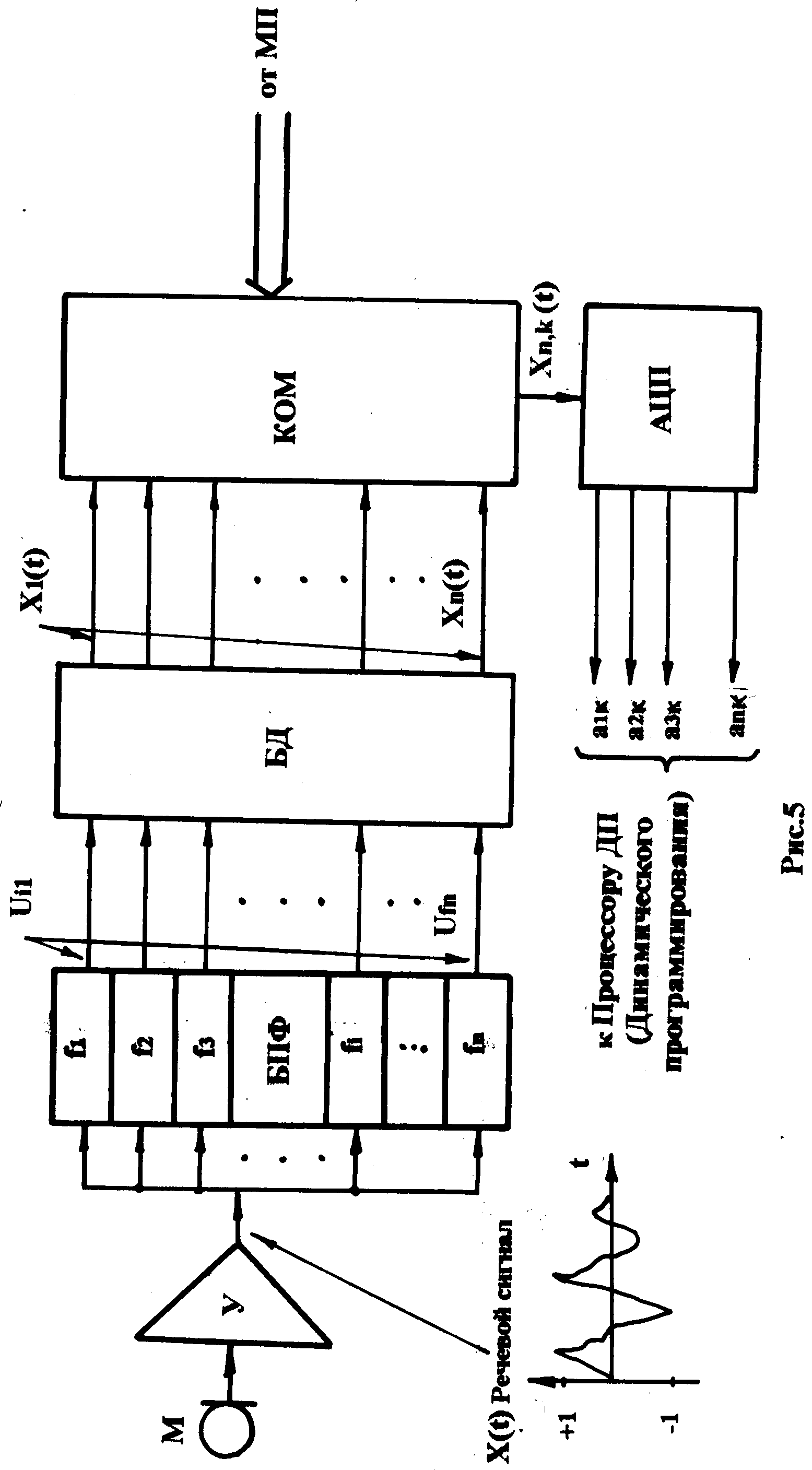
АЦП – аналого-цифровой преобразователь; преобразует двоичный код вк-ом столбце в вектор-столбец – набор цифровых данныха1к – аnк.
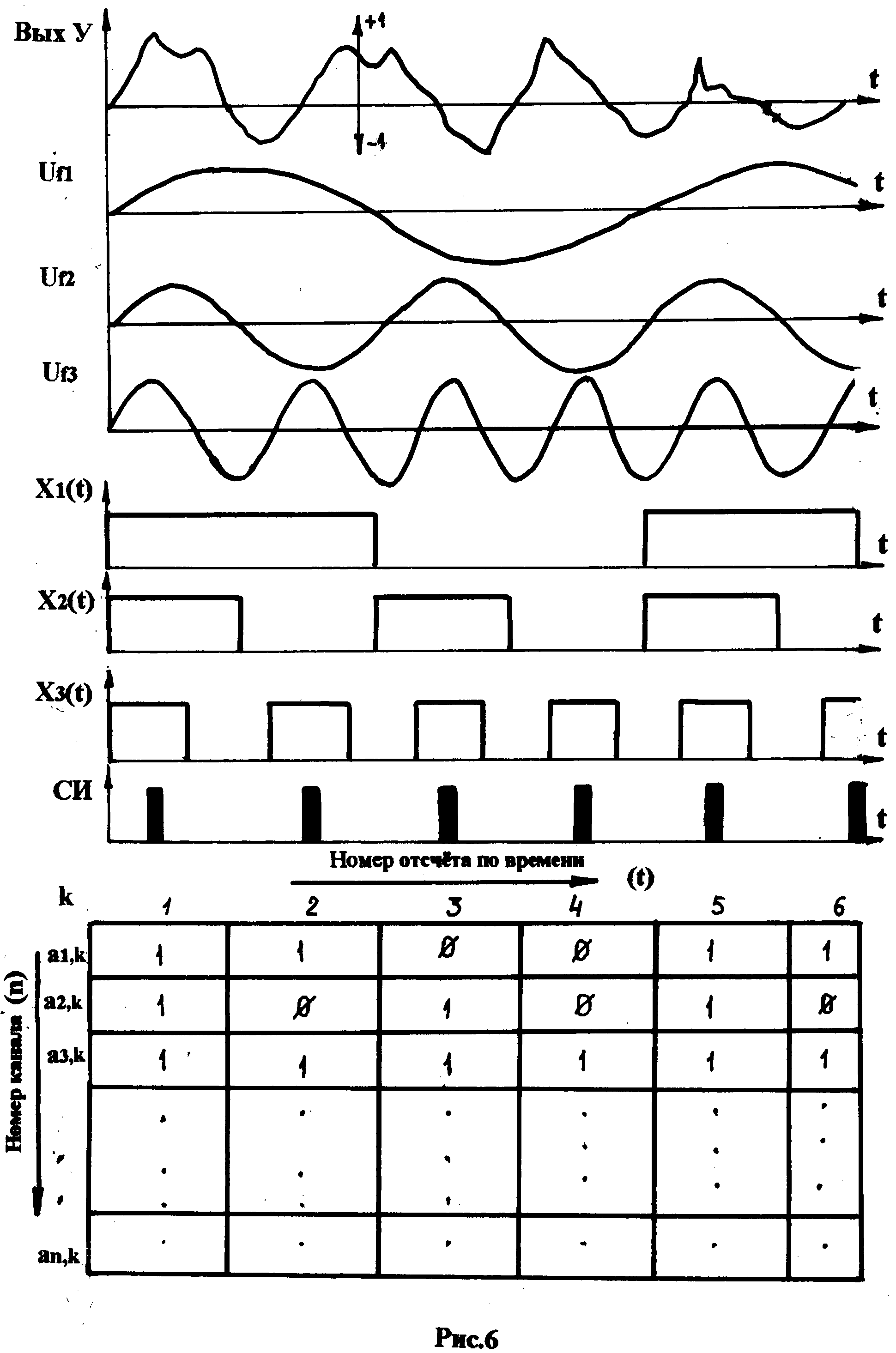
Временная диаграмма, иллюстрирующая работу предпроцессора приведена на рис.6. Временная диаграмма построена в сокращённом виде – всего для 3-х частотных каналов (1-го – 3-го из 16), что не влияет на общность рассмотрения.
С выхода усилителя У(см. рис.5) нормированный по амплитуде речевой сигнал X(t) поступает на блок полосовых фильтров (БПФ), на котором он преобразуется в гармонические составляющиеUf1 – Uf3 (аргументt на временной диаграмме и на рис.5 опущен). Синусоидальные сигналы поступают на блок детектированияБД, который преобразует (де-тектирует) гармонические сигналы, то есть фиксирует максимальную амплитуду сигнала на отрезках времени, на которых гармонический сиг-нал положителен(Ufi >0). На выходах блока детектирования, таким образом, возникают прямоугольные сигналыX1(t) – Xn(t), гдеn – номер частотного канала. Длительность этих сигналов уменьшается в соответствии с возрастанием номера частотного канала.
Параллельно с образованием указанных выше сигналов произво-дится формирование двоичной матрицы (см.рис.6), которая представляет собой «цифровой портрет» речевого сигнала, состоящий из двоичных единиц и нулей. Каждый элемент матрицы образуется в момент появления синхроимпульса (СИ),который фиксирует номер отсчёта по времени.
Элемент матрицы принимает значение «1», если сигнал Xi (t) имеет высокий уровень и равен «0 в противном случае. Так в первом столбце матрицы зафиксированы три двоичных единицы (отсчёт № 1, код 111…), а во втором столбце две единицы и нуль (отсчёт №2, код 101…)
Сформированный на очередном отсчёте столбец матрицы (а1, а2, а3,…,аn) записывается вОЗУ-ЭТ(см. рис.4). В результате обработки речевого фрагмента в ОЗУ эталонов формируется матрица эталонов.
В режиме распознавания формирование матрицы речевого сигнала (матрицы реализации) осуществляется аналогично. Матрица реализации сразу же передаётся в блок сравнения с матрицами эталонов (блок 4, см. рис.3), после чего реализуется алгоритм сравнения матрицы реализации с матрицами эталонов.
На рис.7 приведена матрица признаков распознаваемого слова. Стро-ки матрицы (16 строк) соответствуют номеру частотного канала, а столбцы – номеру отсчёта по времени. В режиме распознавания, выполняется последовательное сравнение всех эталонов словаря с набором аналогичных признаков, полученных при произнесении слова (команды) в микрофон УРВ. По результатам анализа полученных мер сходства (или несходства) со всеми эталонами. По результатам анализа полученных мер сходства микропроцессор принимает решение и передаёт его на дисплей (Д) и в интерфейсный блок.
Сравнение эталонов и вычисление мер сходства сопряжены с трудностями. Например, возникает задача их нормализации по длительности, так как при речевом вводе одного и того же сообщения могут быть значительные отличия формы и величины исходного сигнала с микрофона из-за нелинейного изменения темпа речи или силы голоса.
Амплитудные изменения учитываются при обработке речевого сигнала в предпроцессоре (ПП). Изменения в темпе произнесения учитываются более сложным путём [3], например, нормализацией сигнала по времени, разбиением его на определённое число интервалов, что не всегда даёт удовлетворительный результат, или использованием алгоритмовдинамического программирования (ДП), обеспечива-ющих наилучшее возможное выравнивание между неизвестным высказыванием и эталоном.
Для реализации прцедуры ДП составляется матрица близостиили различия двух образов: реализации (распознаваемого слова) и очередного эталона, с которым производится сравнение. Для выполнения процедуры ДП первый столбец матрицы признаков слова сравнивается со всеми столбцами признаков эталона. Оцениваются меры близости этих отдельных отсчётов – частичные меры.Они заносятся в первую строку формируемой таким образом матрицы близости образцов.
Для определения частичной мерой близости можно воспользоваться, например, простейшим правилом: при полном совпадениикодов в каждом из разрядов столбцов результат равен сумме разрядов столбцов (16 в нашем случае, см. рис.7), при совпадении в половине разрядов – 8 и так далее. В случае определения меры отличия (несходства) – картина обратная – результат равен нулю при полном совпадении кодов и нарастает в зависимости от степени отличия.
Затем берутся остальные столбцы матрицы признаков слова и каждый из них последовательно сравнивается со столбцом матрицы признаков эталона. В ходе такой процедуры последовательно заполняется вторая и остальные строки матрицы близости (или различия) образов.
Рассмотрим матрицу различия для слова «ПУСК» (см. рис 8). Приве дённые на рисунках случаи соответствуют двум вариантам произнесения слова. При полном совпадении слова и его эталона значения с минимальным различием частичной меры располагаются строго по диагонали (см. рис. 8,а).При временных искажениях в произнесении слова может быть вариант, представленный нп рис.8,б. Чтобы определить меру различия двух образов, необходимо просуммировать частичные меры различия по любому пути, соответствующему возможным деформациям оси времени. При этом оптимальная деформация даёт минимальную меру различия образов.
Для нахождения оптимального пути используют аппарат ДП. Один из возможных вариантов процедуры ДП выглядит так:
M(i-1, j) + m(i, j);
М (i, j) = min{ M(i-1, j-1) +2m(i, j); (*)
M(i, j-1) +m(i, j),
где; i-координата по оси ординат – номер отсчёта признаков распоз- наваемого слова;j-координата по оси абсцисс – номер отсчётов признаков эталона;M-полная мера различия в точках матрицы;m-частичная мера различия.

На основе выражения (*) строится матрица оптимального пути и подсчитывается мера M(I,J) в его конце.
Как видно из изложенного выше процесс распознавания, состоящий из вычисления мер сходства (различия) реализации и эталона очень трудоёмкий процесс. Поэтому для реализации алгоритмов ДП используется специализированный процессор, так как решение этой задачи программными средствами приводит к большим затратам времени.
Учитывая относительно большой словарь УРВ, а также тот факт, что каждое слово произносится некоторое время (разное для разных слов), ДП-процессор, кроме того, должен нормировать время произнесения и слова и в приемлемое время дать ответ о сходстве (несходстве) произнесённого слова и эталона. Поэтому ДП-процессор реализуется аппаратно. Дадим ориентировочные временные оценки и требования к объёму памяти. Исходными данными являются:
Средняя длина произносимого слова ∆t=0,6 сек;
Периодичность опроса
(fси не ниже частоты основного тона)τ = 15 мс;
Разрядность матрицы эталона по строкам n = 16.
Эталон описывается областью памяти:
Vэт = (∆t·n)/τопр= (0,6·16)/0,015 = 640 бит = 80 байт.
Если словарь составляет m=200 слов, то объём памяти словаря составляет:
Vсл = Vэ·m = 640·200 ≈ 15,6 Кбайт.
Если время ответа (распознавания) составляет tотв = 0,8 с (УРВ «ИКАР»), то время на вычисление меры сходства (матрицы меры) составляет:
t выч = t отв/m = 0,8/200 ≈ 4 мс
За это время необходимо вычислить матрицу сходства по алгоритму рассмотренному выше.