

3.3 Аналоговый синтез формантных частот
В отличие от метода, описанного выше, метод синтеза формантных частот не использует человеческую речь в качестве исходного материала. В этих методах используется известное приближение к человеческой речи с использованием формантных частот (см. выше).
Существует много методов реализации формантного синтеза. Но основные функциональные операции для генерации речи при разных способах формантного синтеза в принципе одинаковы. Все они основываются на детальном знании фонем и фонетическом расчленении речи. По этой причине эта группа методов в литературе получила название «формирование речи по правилам» При синтезе речи по правилам используетсяэлектронная модель голосового тракта человека, то есть синтезатор строится как некоторое приближение к голосовому тракту. При этом настройка синтезатора в этом случае производится отдельно для каждого фонетического элемента алфавита.
Фонетическое описание представляет собой последовательность эле-ментов фонетического алфавита (включая паузы) с указанием длительнос-ти звучания каждого из них. Таким образом, каждому элементу фонетического алфавита ставят в соответствие набор параметров настройки синтезатора. Эти параметры могут быть неизменными в течение всей продолжительности звучания фонемы или аллофона, но могут и изменяться, как, например, для дифтонгов. В последнем случае элементу фонетического алфавита ставится в соответствие последователь-ность нескольких наборов параметров. Наборы параметров настройки синтезатора для каждого элемента фонетического алфавита (ФА) в виде управляющих слов (УС) хранятся в памяти (как правило в ПЗУ). Код элемента ФА используется, таким образом, в качестве адреса и позволяет найти УС или их последовательность. Каждая УС содержит помимо набора параметров настройки синтезатора {pi} параметр длительности звучания фонологического элемента, флаг цепи УС и ряд других флагов.
Для того, чтобы связать фонему с конкретными формантными частотами, которые характерны для некоторых фонем фонетического алфавита английского языка, рассмотрим таблицу 4.1 (усечённую) соответствия некоторых фонем формантным частотам [4]:
Таблица 4.1
-
Фонема
Как в слове
F1 (Гц)
F2 (Гц)
F3 (Гц)
ee
feet
250
2300
3000
i
hid
375
2150
2800
eh
head
550
1950
2600
ae
had
700
1800
2550
ah
tot
775
1100
2500
aw
talk
575
900
2450
u
took
425
1000
2400
oo
tool
275
850
2400
Для каждого звука в таблице даны три основные (старшие) формант-ные частоты, которые наблюдаются в спектрограммах соответствующих фонем, произносимых «средним» мужским голосом. Эти частоты, F1, F2, F3, можно различать визуально на спектрограммах каждой произносимой гласной. Поскольку каждая из этих гласных является «статической», частоты остаются стабильными на протяжении всего времени их произнесения. Теперь, призвав на помощь немного воображения, нетрудно представить электронную схему, состоящую из трёх параллельных полосовых фильтров, частоты которых настроены наF1 F2иF3 и возбуждаются задающим генератором с выходным сигналом, аналогичным импульсу, формируемому в голосовой щели. Как ни проста эта схема, она может служить основой для создания фонемного синтезатора гласных при условии, что формантные частоты регулируются в пределах, указанных в таблице 4.1.
Таким образом, необходимо задавать параметры, регулирующие характеристики полосовых фильтров, амплитуды генератора шума для воспроизведения шумных согласных, фрикативных согласных, амплитуды носовых (нозальных) гласных, и т.п. (см. ниже).
В формантных синтезаторах используется набор от 8 до 15 парамет-. ров. Количество параметров влияет на качество синтезируемой речи, но усложняет структуру синтезатора. Наиболее часто используется набор состоящий из следующих параметров:
F0 – частота сигналов голосовой щели (частота основного тона);
A0 – амплитуда сигналов основного тона;
– 5 F1 - F3 – частота фильтров первой, второй и третьей формант
произносимой фонемы;
FN – частота резонатора носовых гласных;
7. AFR – амплитуда фрикативных согласных;
8. FR – частота резонатора фрикативных согласных;
9. AN – амплитуда носовых гласных;
AГЛ – амплитуда гласных.
Справка (примеры согласных звуков):
Носовые гласные –м,н;
Шумные: взрывные – б, г, д; щелевые –в, з, ж;
Фрикативные: ц, ч;
Глайды : р, л;
Взрывные: п, т, к и т.д.
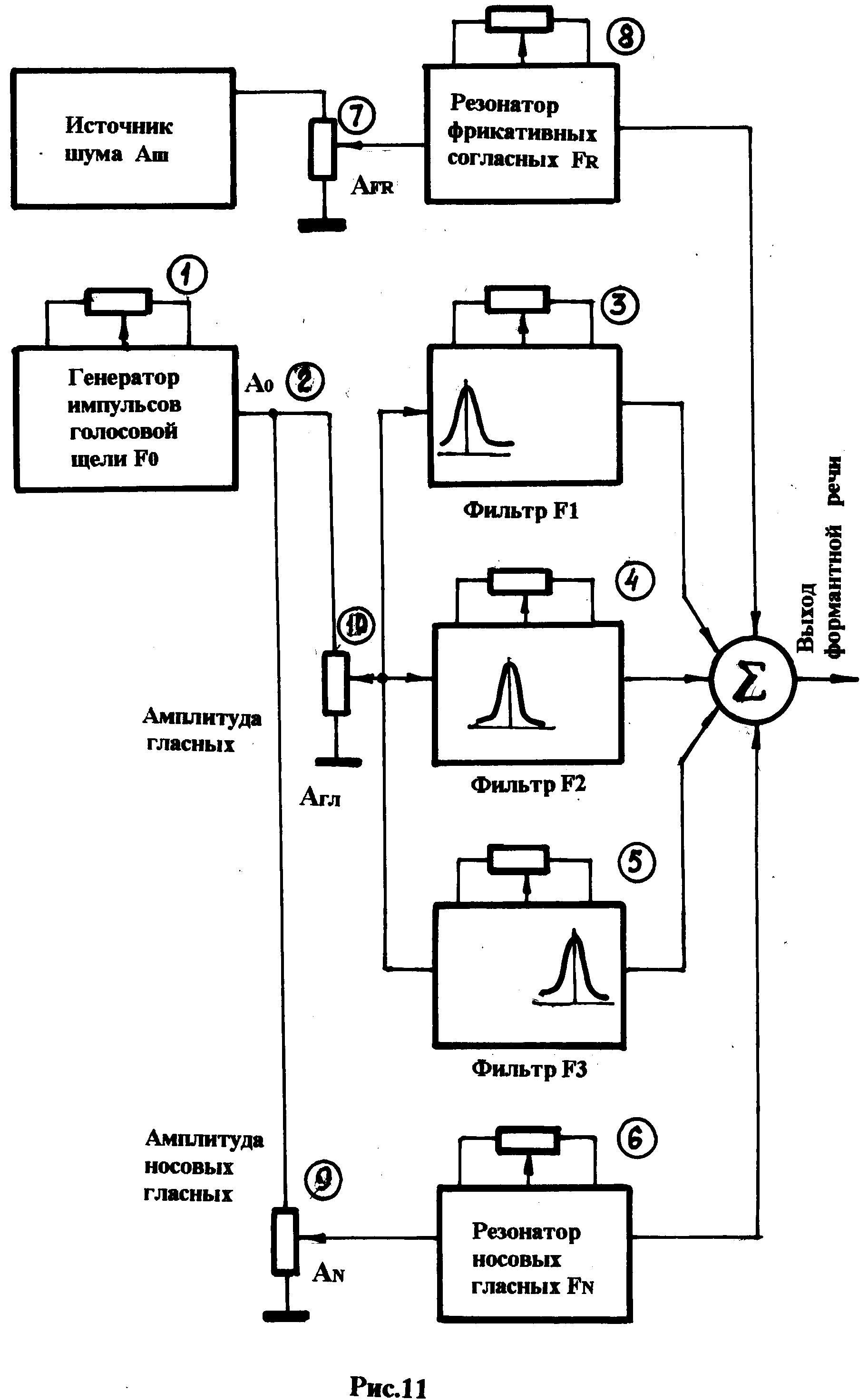
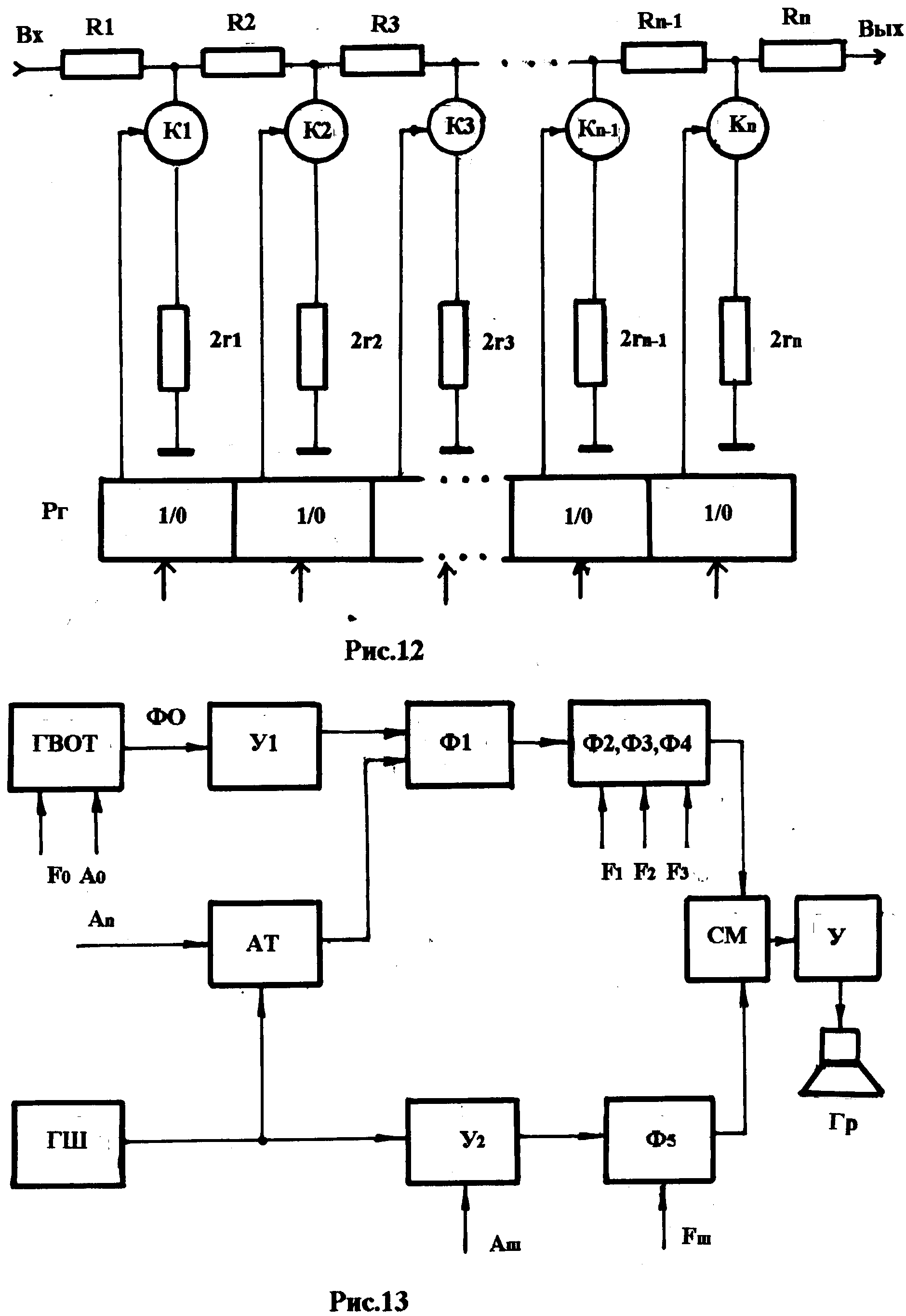
Один из вариантов (практически полный) модели синтезатора приведён на рис.11.На рисунке с помощью потенциометров, подключён-ным к отдельным блокам модели, задаются параметры, управляющие синтезом речи. В указанной схеме используются 9 таких параметров (см. схему). Такую модель несложно реализовать, но практически она будет неработоспособна, так как задание параметров с помощью потенциомет-ров приводит к чрезвычайно большому (даже громадному) времени синтеза, что лишает эту модель права на реализацию. Выходом из сложившейся ситуации является включение в модель вместо потенцио-метров резистивных матриц, управляемых с помощью цифрового кода, которые имеют приемлемое время установки параметра. Структура одной из таких резистивных матриц приведена на рис.12. Матрица содержит резисторыRi, которые подключаются (отключаются) с помощью быстродействующих ключевых схем (ключей)Ki. В свою очередь состояние ключа (открыт-закрыт) определяется наличием двоичной единицы или нуля в разряде регистра управленияRу. Таким образом, двоичный код, задаваемый с регистра (параметр), быстро преобразуется в величину проводимости матрицы от точки «ВХОД» до точки «ВЫХОД» схемы матрицы, а всё остальное не вызывает затруднений, так как быстрое переключение параллельного выходного
порта управляющего компьютера к регистрам управления резистивной матрицей реализуется с приемлемой скоростью.
Выходные напряжения резонаторов фрикативных согласных, н носовых гласных, а также трёх фильтров подаются смеситель (Σ), на выходе которого образуется формантная речь. Все 9 регулируемых элементов модели, определяющих величину параметров, составляют так называемыеуправляющие слова, которые хранятся в памяти компьютера и последовательно подаются в синтезатор. Перенастройка управления синтезатора происходит с частотой 100 Гц. Учитывая, что каждое управляющее слово состоит из 8-битового байта, синтезатором можно управлять при параллельной передаче управляющих слов со скоростью 900 байт/c. Но это ещё не скорость выдачи фонем на выход синтезатора, а всего лишь скорость передачи данных в самом синтезаторе, необходимая для текущих регулировок фильтров, высоты голосового тона и амплитуд при воспроизведении каждой отдельной фонемы. Данная информация хранится, как правило, в специальной управляющей таблице в памяти компьютера отдельно для каждой фонемы и её вариаций – аллофонов. Она вызывается в виде последовательности, которая определяется входной последовательностью фонем в речевом выходе управляющей программы. Например, по каждой фонеме, которая вводится в компьютер, компьютерное управление синтезатором может потребовать до 30 полных перенастроек системы фильтров. Это означает следующее: чтобы компьютер выдавал схеме управления формантного синтезатора по 900 байт в секунду, в программу опроса справочной таблицы, которая управляет синтезатором, требуется вводить всего по 30 байт в секунду.Это соответствует тому, что выдача данных конечному пользователю произво-дится со скоростью около 240 бит в секунду.
В то время как указанные выше скорости перенастройки фильтров могут меняться от системы к системе, зависимость между числом воспроизводимых фонем и размерами управляющей таблицы остаётся практически неизменной. Естественно, чем больше число обращений к справочной таблице по каждой фонеме, тем большей плавностью будет от-личаться синтетическая речь и тем ближе будет она по звучанию к естественной артикуляции. Однако не следует надеяться , что речь по-добной системы когда-нибудь будет звучать так, что её не отличишь от живой человеческой речи.
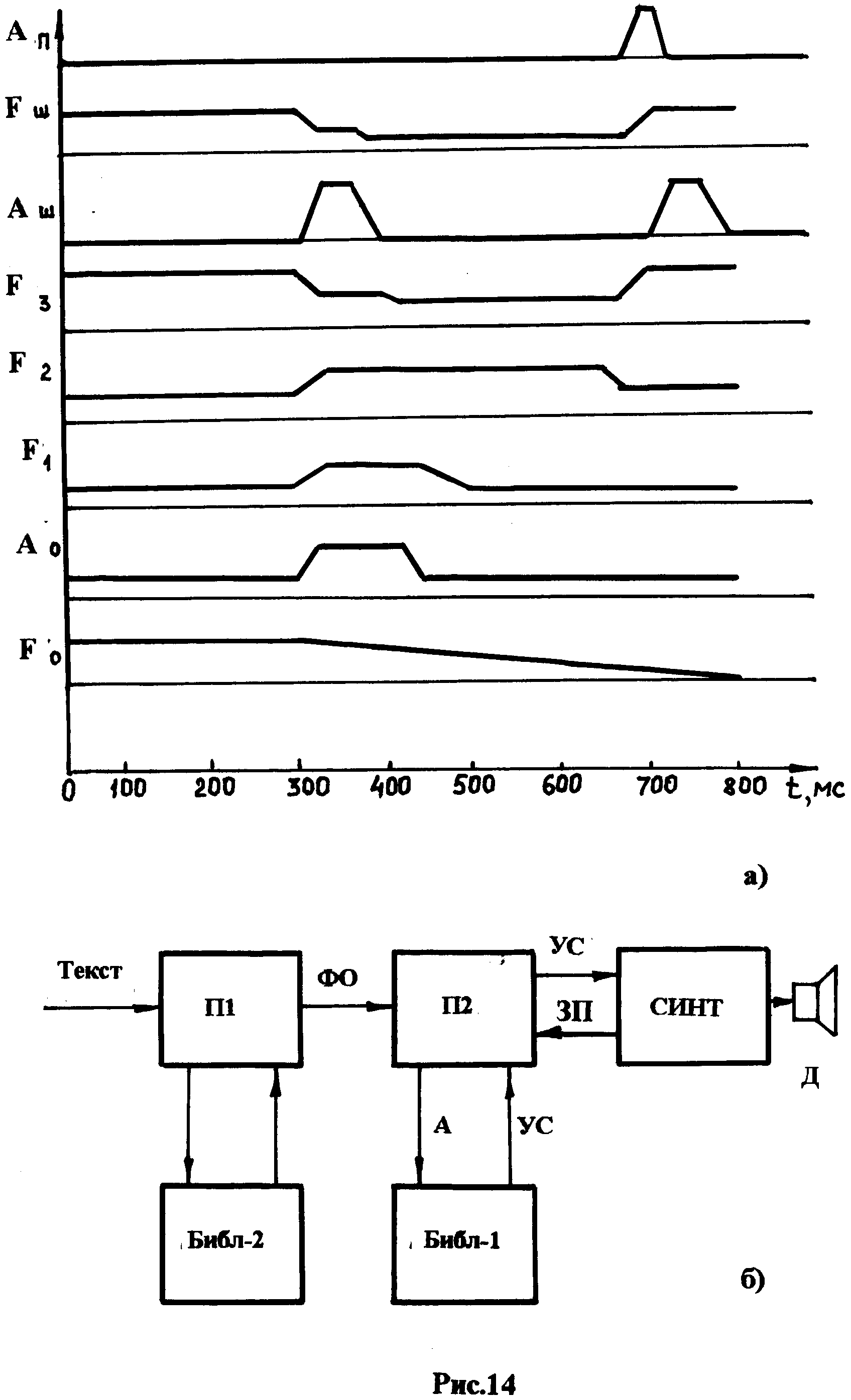
На рис.13 приведена структурная схема синтезатора формантного типа, реализованного на практике одной из западных фирм [5]. В данной структуре используются всего 8 параметров настройки: частота и амплитуда основного тона (F0, A0), три формантные частоты (F1, F2, F3), амплитуда и частота сигнала шума, задающие свистящие и шипящие звуки (Аш, Fш), а также параметр «придыхания».. Приведённая структура синтезатора соответствует модели, рассмотренной выше.
На структуре синтезатора, состоящего из двух трактов, использова- ны следующие обозначения блоков устройства.
Первый тракт:
ГВОТ – управляемый генератор (F0, A0) высоты основного тона;
У1 – усилитель;
Ф1, Ф2, Ф3,Ф4 – фильтры (сглаживающий – Ф1 и фильтры формантных частот – Ф2,Ф3 Ф4)
Эти компоненты структуры участвуют в формировании гласных звуков. Формирование большинства согласных звуков производится с помощью тех же фильтров при подаче на них сигналов с управляемого аттенюатора (делителя напряжения)(AT) и сигнала шума с генератора шума (ГШ).
Второй тракт:
ГШ– генератор шума;
У2 – управляемый усилитель (ГШ);
Ф5 – управляемый фильтр (ГШ);
СМ – смеситель сигналов первого и второго трактов.
Сигналы от этих трактов подаются на смеситель (СМ) далее на уси-литель, к выходу которого подключён громкоговоритель (Гр). Эта схема довольно точно воспроизводит голосовой тракт человека
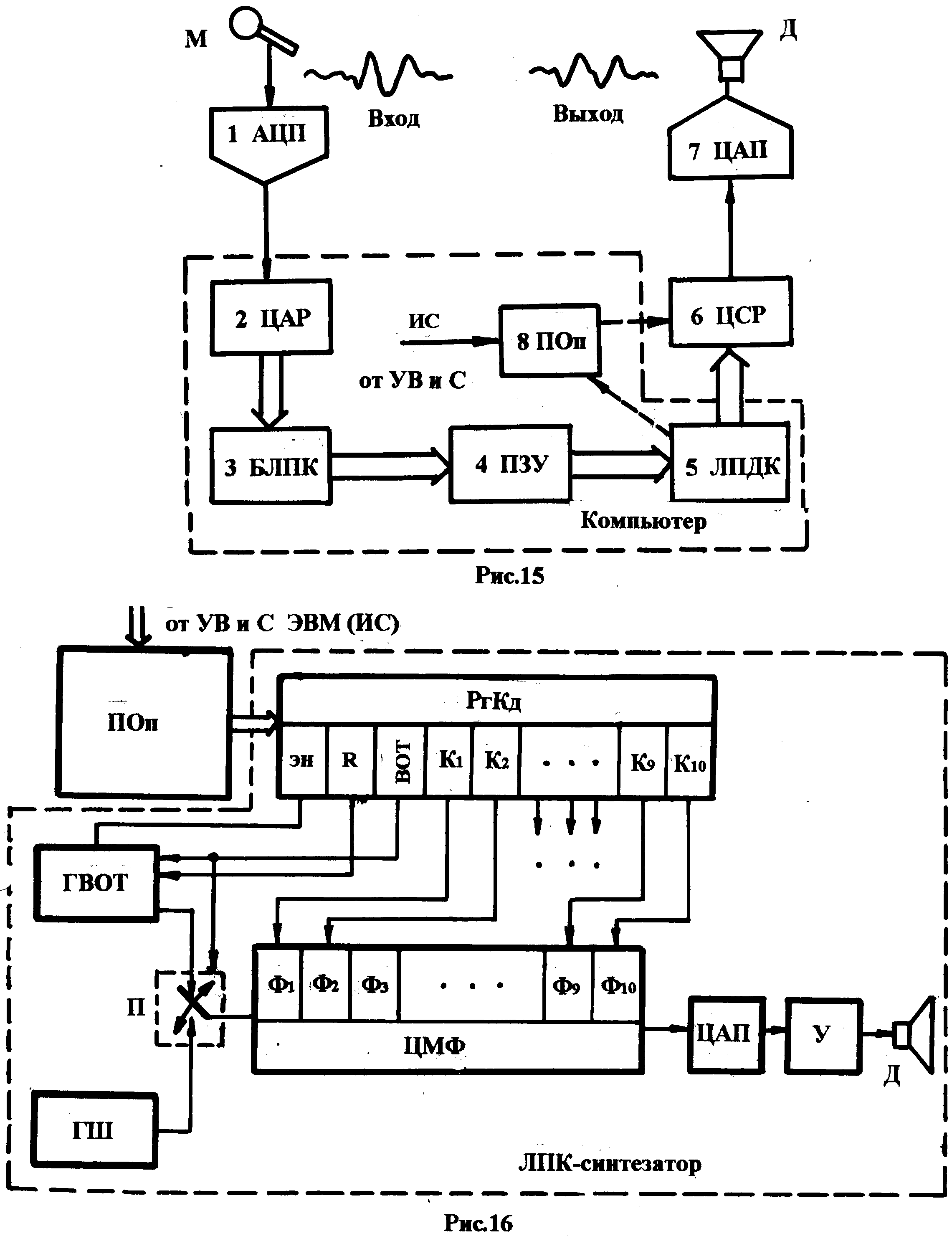
На рис.14,а приведён пример изменения параметров в процессе синтеза речевого сигнала «SIKS», соответствующего произношению английского слова «SIX».
Конструирование речевого сообщения (РС) при формантном синтезе и (вообще по правилам) включает в себя два этапа:
Этап 1. Символьное представление«орфографического текста»,принятого в ЭВМ, преобразуется вфонетическое описание.
Этап 2. Преобразование последовательности элементов фонетичес- кого алфавита в последовательность управляющих слов (УС) для непосредственного управления синтезатором.
Эти преобразования иллюстрируются схемой, приведённой на рис.14,б.
На рисунке использованы следующие обозначения:
П1– программа преобразования орфографического текста в фонети-ческое описание (ФО);
П2 – программа формирования последовательности управляющих слов (УС);
СИНТ – синтезатор;
Библ-1 – библиотека правил формирования фонетических описаний (ФО);
Библ-2 – библиотека управляющих слов (УС);
ФО – фонетические описания;
УС – управляющие слова;
ЗП – запросы от синтезатора
Гр – громкоговоритель;
А – адреса.
Структура, приведённая на рис.14,б работает следующим образом:
1.Последовательность слов и словосочетаний (ТЕКСТ) в виде символьного представления передаётся в программу П1. Эта программа реализуется средствами ЦП или специализированными средствами цифровой обработки, встроенными в систему вывода речи.
Основой для преобразования текста в фонетическое описание (ФО) служит набор правил, хранимых в Библиотеке 1 (Библ-1). Эти правила определяются фонетическими особенностями языка; они сложны и неоднозначны, содержат большое количество исключений. Поэтому ино-
гда первый этап конструирования речи выполняется не в процессе создания системы речевого сообщения, а в процессе создания оператором системы речевого вывода.
3. Пользуясь библиотекой правил (Библ-1) или словарём, программа П1 передаёт фонетическое описание (ФО) программе П2 – программе формирования последовательности УС (управляющих слов).
4.Программа П2 чаще всего реализуется МП-средствами системы речевого вывода. Программа П2 последовательно получает коды элемен-тов ФО, по ним формирует адрес (А), находит УС в библиотеке фонетических описаний элементов (Библ-2), соответствующие каждому элементу и направляет их в синтезатор (СИНТ).
5. Каждое следующее УС передаётся в синтезатор по его запросу (ЗП) по окончании интервала звучания, определяемого параметром длительности звучания в предыдущем УС.
6.Новое УС выбирается по адресу следующего фонетического элемента, если воспроизведение предыдущего завершено, или по следующему по порядку адресу, если в предыдущем УС установлен соответствующий флаг (Фл) цепи УС, то есть если воспроизведение фоне-тического элемента завершено (повтор).
Примечание:В состав управляющего слова (УС) кроме упомянутых выше параметров вводятся также параметры, задающие длительность звучания фонемы и ряд так называемых «флажков», выполняющих служебные функции при работе программ П1 и П2.
Речь сформированная таким образом, отличается сравнительно невысоким качеством, но вполне различима; такая речь звучит неестест-венно, так как в ней отсутствуют присущие человеческой речи ритм, интонация, изменение громкости и т.п.-
Существенным достоинством таких систем является достаточно большой словарь (до 300 слов) и полное время звучания до 200 секунд (почти 3,5 минуты).
3.4 ЛПК- синтезаторы
Линейное предиктивное кодирование (ЛПК-метод) основано на ис-пользовнии математического аппарата – уравнений преобразования закодированной речи в её спектр исходных частот.
Главный принцип, положенный в основу ЛПК-метода сводится к тому, что поступающие выборки речевых сигналов могут рассматриваться как линейные комбинации прошлых выборок речевого сигнала.
Физически это означает, что характер речевого сигнала сравнительно мало изменяется при произнесении какого-либо одного звука, а изменение характера этого сигнала происходит значительно реже (по отношению к частоте квантования – Fкв) при переходе от одного звука к другому. Это отчётливо видно, если речевой сигнал записать на магнитную ленту, а затем рассмотреть осциллограмму.
Существует большое сходство между ЛПК-методом и методом пря-мого кодирования-восстановления речевого сигнала. Сходство заключает-ся в том, что в основе обоих методов используется живая человеческая речь. Но в ЛПК-синтезаторах в память записывается коды слов, а затем на основе этих кодов производится анализ кодированной речи с целью
образовать так называемые кадры ЛПК-данных, которые содержат информацию: о высоте основного тона, о формантных частотах, об амплитуде и интонации речи и т.п. – всего около 12 параметров речи, которые формируются в кадры, управляющие собственно синтезатором.
На рис.15 приведена структура модели системы синтеза речи с использованием ЛПК-метода (модель несколько упрощена) [4]. В модель системы входят:
1. Микрофон (М) для ввода в модель речевых фрагментов и слов с помощью живой человеческой речи;
2. Аналого-цифровой преобразователь;
3. Цифровой анализатор речи (ЦАР);
4. Блок образования линейных предикторных коэффициентов (БЛПК);
5. Постоянное запоминающее устройство (ПЗУ);
6. Блок линейного предиктивного декодирования (ЛПДК);
7. Собственно цифровой синтезатор речи (ЦСР);
8. Память описаний (ПОп);
9. Цифроаналоговый преобразователь (ЦАП);
10. Громкоговоритель (Д).
Следует заметить, что блоки 2 –5 модели реализуются средствами компьютера и являются его программно-аппаратными частями.
Рассмотрим функции отдельных блоков модели и их взаимодейст-вие.
Цифровой анализатор речи – программа, которая анализирует выборки речевых сигналов, поступающих с выхода АЦП, и образует данные оспектральном составе речи, формантных характеристиках речи, данные об амплитуде и интонации речи т.п. – всего 12 парамет-ров.
Блок образования линейных предикторных коэффициентов – программный блок вычисления предикторных коэффициентов, описываю-щих речевой фрагмент (слово, фразу). Это блок предикторного кодирования. Этот блок, по сути дела, является устройством краткосроч-ного прогнозирования, то есть своеобразного «предсказателя» последую-щего речевого сигнала. Выходные данные этого блока управляют параметрами и определяют числовые коэффициенты, которые использу-ются для линейной предиктивной генерации речи.
Постоянное запоминающее устройствохранит данные из блока БЛПК. Эти данные в дальнейшем служат для регенерации речи, формиру-емой системой ЛПК-синтезатора.
После того, как на этапе настройки синтезатора параметры за-писаны в ПЗУ системы, можно приступать к синезу речи. Процесс синтеза (регенерации) речи начинается в блоке ЛПКД.
Блок линейного предиктивного декодирования из данных, записанных в ПЗУ, формируетуправляющие кадры, которые подаются на блокЦСР – цифровой синтезатор речи,который принимает управляющие кадры. Формат управляющего кадра имеет вид:
-
ЭН
R
Вот
К1
К2
К3
К4
К5
К6
К7
К8
К9
К10
4б
1б
5б
5б
5б
4б
4б
4б
4б
4б
3б
3б
3б
Кадр не имеет фиксированной длины, его длина колеблется от 49 бит до 1 бита. Каждая ячейка управляющего кадра (УК) представляет собой код – элемент двоичной информации, который передаётся в синтезатор и управляет синтезом речи.
Ячейки управляющего кадра имеют следующий функциональный смысл:
Ячейка ЭН (энергия) – всегда присутствует в кадре. Её значение – либо 1111, либо 0000. Эта ячейка кадра служит для непрерывного управле-ния амплитудой произносимой речи.
Ячейка R (повторение кадра) – еслиR=1, то повтора кадра нет, в противном случае кадр повторяется (длинный звук).
Ячейка ВОТ (высота основного тона): при ВОТ=0 – глухой звук, при ВОТ=1 – звонкий звук.
К1 – К10– (3-5 бит), управляющие биты, задающие предикторные ко-эффициенты (параметры), вычисленные на этапе цифрового анализа речи (ЦАР) и образования предикторных коэффициентов (БЛПК – ПЗУ – ЛПДК).
Приведём примеры реальных управляющих кадров используемых в синтезаторе фирмы «Тексас инструментс» [4]:
ЭН R ВОТ Коэф-ты. Размер
Кадр для звонкого звука: хххх 0 ххххх К1– К10 – 49 бит
Кадр для глухого звука: хххх 0 00000 К1– К4– 28 бит;
Повторить кадр хххх 1 ххххх 10 бит;
Кадр с нулевой энергией 0000 4 бита;
Кадр с кодом останова 1111 4 бита;
Примечание:Х-безразличное состояние бита.
Система ЛПК-синтеза работает в двух режимах (как и синтезатор, ра-ботающий по методу кодирования-восстановления речи).
РЕЖИМ 1. Режим подготовки системы к генерации речи
В этом режиме при использовании реальной человеческой речи в памяти описаний (ПОп, см рис. 15) необходимо создать массив управляющих кадров для генерации сегмента речи. В этом режиме в системе ЛПК-синтеза работают блоки: АЦП, ЦАР, БЛПК, ПЗУ, ЛПДК, ПОп. Оператор через микрофон передаёт в систему речевые сегменты (фразы, слова), которые оцифровываются и поступают в БЛПК; этот блок образует линейные предикторные коэффициенты, которые записываются в ПЗУ, а затем передаются в блок линейного предиктивного декодирования (ЛПДК). Блок формирует из этих данных управляющие кадры (УК). Управляющим кадрам, соответствующим одному фрагменту речи, присваивается идентификатор сообщения (ИС). Управляющие кадры со своим идентификатором записываются в память описаний. Аналогичные операции совершаются со всеми речевыми фрагментами, которые вводят-ся в синтезатор.
РЕЖИМ 2. Этот режим является основным режимом – режимомсобственно синтеза речи. Он реализуется следующим образом:
Идентификатор (имя) сообщения из ЭВМ верхнего уровня (цент- ральной ЭВМ) передаётся в узел управления выборкой и синхронизации (УВиС). Этот узел осуществляет поиск описания выводимого речевого сообщения в памяти описания (ПОп). Описание речевого сообщения представляет собой последовательность управляющих кадров, поступающих в синтезатор каждые 20 мс, в течение которых предикторные коэффициенты остаются постоянными.
Структурная схема синтезатора описанного типа приведена на рис16. В структуре использованы следующие обозначения:
ГВОТ – генератор высоты основного тона;
ГШ – генератор шума;
РгКд – регистр управляющего кадра (УК);
Эн – ячейка «энергия» регистра кадра (РгКд);
R –ячейка «повторить кадр регистра кадра (РгКд);
ВОТ –ячейка «высота основного тона регистра кадра (РгКд);
К1 – К10 – ячейки управляющих битов регистра кадра (РгКд);
ПОп – память описаний;
УВиС – устройство управление выборкой и синхронизацией
ИС – идентификатор сообщения;
ЦМФ – цифровой многозвенный фильтр;
Ф1 – Ф10 – элементы цифрового многозвенного фильтра;
П – электронный переключатель;
ЦАП – цифро-аналоговый преобразователь;
У – усилитель;
Д – динамик;
Работа синтезатора кратко заключается в следующем.
Будем считать, что синтезатор подготовлен к работе, то есть в режиме 1 в память описаний введена информация в виде речевых сообщений. Из ЭВМ верхнего уровня в устройство УВиС (на рис. 16 не приведено) поступает идентификатор сообщения (ИС). Устройство УВиС осуществляет в памяти описаний (ПОп) поиск начального кадра из числа кадров, которые управляют синтезатором при выводе сообщения, заданного ЭВМ. Управляющие сообщения последовательно записываются в регистр кадров и управляют всеми компонентами синтезатора которые подключены к регистру управляющего кадра. Когда последний управляющий кадр из последовательности кадров реализует свои функции, синтез прекращается.
При формировании речи по образцам (компилятивными методами) количество возможных речевых сообщенийограничено теми сообщениями, описание которых составлены заранее и хранятся непосредственно в памяти описаний или составляются в процессе вывода путём слияния нескольких элементарных сообщений, также хранящихся в памяти.
Составление описаний более сложных сообщений выполняется с использованием программных средств. Например сообщение «Температура воздуха в Москве в ХХ часов была YY градусов» может быть составлено из 5 элементарных сообщений: