

Ведение в социально - экономическую статистику. Учебник. Новосибирск, 2004. 739 с
.pdf4.2. Регрессионный анализ |
143 |
В непрерывном случае эти формулы принимают вид:
∞ |
∞ |
E (x1|x2) = |
x1f (x1|x2) dx1, E (x1) = E (x1|x2) f (x2) dx2. |
−∞ |
−∞ |
(Об условных и маргинальных распределениях см. Приложение A.3.1.)
Условные дисперсии признака рассчитываются следующим образом:
s12 | i2 = |
2 |
xi1 − x¯1 | i2 αi1 | i2 . |
Отклонения фактических значений признака от условных средних
ei1 | i2 = xi1 − x¯1 | i2
обладают, по определению, следующими свойствами:
а) их средние равны нулю:
ei1 | i2 αi1 | i2 = 0,
б) их дисперсии, совпадающие с условными дисперсиями признака, минимальны (суммы их квадратов минимальны среди сумм квадратов отклонений от какихлибо фиксированных значений признака — наличие этого свойства у дисперсий доказывалось в п. 2.4):
2 |
= e2 |
α |
2 |
= |
min (x |
i1 − |
c)2 |
α |
i1 | i2 |
. |
se1 | i2 |
i1 | i2 |
|
i1 | i2 = s1 | i2 |
c |
|
|
|
Общая дисперсия связана с условными дисперсиями более сложно:
s2 |
= xˆ2 |
α |
= |
xˆ2 α |
= |
|
|
|
1 |
|
i1 i1 |
i1 i2 |
i1 i1i2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xi1 − x¯1 | i2 |
+ x¯1 | i2 − x¯1 |
2 |
|
||
= |
i1 |
i2 |
αi1i2 = |
|||||
|
|
|
|
|
|
|
||
|
|
|
|
2 |
|
|
xi1 − x¯1 | i2 x¯1 | i2 − x¯1 αi1i2 + |
|
= |
i1 |
i2 |
xi1 − x¯1 | i2 |
αi1i2 + 2 |
i1 i2 |
|||
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
+ |
x¯1 | i2 − x¯1 αi1i2 = |
|
|
|
|
|
|
|
i1 |
i2 |

144 |
|
|
|
|
|
|
|
Глава 4. Введение в анализ связей |
|
|
|
|
|
|
αi1 |i2 |
|
|
||
|
|
|
|
|
←−−−→ |
|
|
||
|
|
|
|
2 |
|
α |
|
|
|
= i2 |
α i2 |
|
xi1 − x¯1 | i2 |
|
i1i2 |
|
+ |
|
|
|
|
|
|
||||||
i1 |
|
|
α i2 |
|
|||||
|
|
←−−−−−−−−−−−−−−−−−−−→ |
|
|
|||||
|
|
|
s2 |
|
|
|
|
|
|
|
|
|
e1 | i2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
=0 |
|
|
|
|
|
|
|
←−−−−−−−−−−−−−−−−−−→ |
|||
|
+ 2 α i2 x¯1 | i2 − x¯1 |
xi1 − x¯1 | i2 αi1 | i2 + |
|||||||
|
|
|
i2 |
|
|
i1 |
|
|
|
|
|
←−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−→ |
|||||||
|
|
|
|
|
=0 |
|
|
||
|
|
|
|
|
|
|
|
x¯1 | i2 − x¯1 |
2 |
|
|
|
|
|
+ |
|
αi1i2 = se21 + sq21. |
||
|
|
|
|
|
|
i2 |
|
i1 |
|
|
|
|
|
|
|
|
|
|
←−−−−i2 → |
|
|
|
|
|
|
|
|
|
α |
|
|
|
|
|
|
|
|
|
|
Равенство нулю среднего слагаемого в этой сумме означает, что отклонения фактических значений 1-го признака от условных средних не коррелированы (линейно не связаны) с самими условными средними.
В терминах регрессионного анализа
s2q1 — объясненная дисперсия, т.е. та дисперсия 1-го признака, которая объясняется вариацией 2-го признака (в частности, когда признаки независимы и условные распределения 1-го признака одинаковы при всех уровнях 2-го признака, то условные средние не варьируют и объясненная дисперсия равна нулю);
s2e1 — остаточная дисперсия.
Чем выше объясненная дисперсия по сравнению с остаточной, тем вероятнее, что 2-й признак влияет на 1-й. Количественную меру того, насколько объясненная дисперсия должна быть больше остаточной, чтобы это влияние можно было признать существенным (значимым), дает критерий Фишера, или F-критерий. Статистика этого критерия F c рассчитывается следующим образом:
s21k2 (k1 − 1)
F c = q 2 − . se1 (k2 1)
В случае если влияние 2-го признака на 1-й не существенно, эта величина имеет F-распределение (см. Приложение A.3.2). Такое распределение имеет случайная величина, полученная отношением двух случайных величин, имеющих χ2-распределение, деленных на количество своих степеней свободы:
|
|
χ2 |
df2 |
|
Fdf1, df2 |
= |
df1 |
|
. |
χ2 |
df1 |
|||
|
|
df2 |
|
|
Количество степеней свободы в числителе (df1 ) и знаменателе (df2 ) относится к параметрам F -распределения.
4.2. Регрессионный анализ |
145 |
Рассуждая аналогично тому, как это сделано в конце предыдущего пункта, можно установить, что объясненная дисперсия (в числителе F -статистики) имеет k2 −1 степеней свободы, а остаточная дисперсия (в знаменателе) — k2(k1 −1) степеней свободы. Это объясняет указанный способ расчета данной статистики.
Чтобы проверить гипотезу о наличии влияния 2-го признака на 1-й, необходимо сравнить расчетное значение статистики F c с теоретическим — взятым из соответствующей статистической таблицы 95-процентным квантилем (односторонним)
F -распределения с k2 −1 и k2(k1 −1) степенями свободы Fk2−1,k2(k1−1), 0.95 . Если расчетное значение не превышает теоретическое, то нулевая гипотеза не отвер-
гается, и влияние считается не существенным. В противном случае (объясненная дисперсия достаточно велика по сравнению с остаточной) нулевая гипотеза отвергается и данное влияние принимается значимым. Современные статистические пакеты прикладных программ дают уровень значимости расчетной статистики, называемый в данном случае значением вероятности pv:
F c = Fk2−1, k2(k1−1), 1−pv .
Если pv < 0.05, то нулевая гипотеза отвергается с вероятностью ошибки 5%. Линия, соединяющая точки x i2 , x¯1 | i2 в пространстве значений признаков (абсцисса — 2-й признак, ордината — 1-й) называется линией регрессии, она показывает зависимость 1-го признака от 2-го. Условные средние, образующие эту линию, являются расчетными (модельными) или объясненными этой зависимостью значениями 1-го признака. Объясненная дисперсия показывает вариацию значений 1-го признака, которые расположены на этой линии, остаточная дисперсия —
вариацию фактических значений признака вокруг этой линии.
Линию регрессии можно провести непосредственно в таблице сопряженности. Это линия, которая соединяет клетки с максимальными в столбцах плотностями относительных частот. Понятно, что о такой линии имеет смысл говорить, если имеются явные концентрации плотностей относительных частот в отдельных клетках таблицы сопряженности. Критерием наличия таких концентраций как раз и является F -критерий.
В непрерывном случае уравнение
x1 = E (x1|x2)
называют уравнением регрессии x1 по x2, т.е. уравнением статистической зависимости 1-го признака от 2-го (о свойствах условного математического ожидания см. Приложение A.3.1). Это уравнение выражает статистическую зависимость, поскольку показывает наиболее вероятное значение, которое принимает 1-й признак при том или ином уровне 2-го признака. В случае если 2-й признак является единственным существенно влияющим на 1-й признак, т.е. это уравнение выражает

146 |
Глава 4. Введение в анализ связей |
теоретическую, истинную зависимость, эти наиболее вероятные значения называют теоретическими, а отклонения от них фактических значений — случайными ошибками измерения. Для фактических значений x1 это уравнение записывают со стохастическим членом, т.е. со случайной ошибкой, остатками, отклонением фактических значений от теоретических:
x1 = E (x1|x2) + ε1.
Случайные ошибки по построению уравнения регрессии имеют нулевое математическое ожидание и минимальную дисперсию при любом значении x2 , они взаимно независимы со значениями x2 . Эти факты обсуждались выше для эмпирического распределения.
Врассмотренной схеме регрессионного анализа уравнение регрессии можно построить лишь теоретически. На практике получают линию регрессии, по виду которой можно лишь делать предположения о форме и, тем более, о параметрах зависимости.
Вэконометрии обычно используется другая схема регрессионного анализа.
Вэтой схеме используют исходные значения признаков xi1, xi2, i = 1, . . . , N без предварительной группировки и построения таблицы сопряженности, выдвигают гипотезу о форме зависимости f : x1 = f (x2, A), где A — параметры зависимости, и находят эти параметры так, чтобы была минимальной остаточная дисперсия
se21 = |
1 |
(xi1 − f (xi2, A))2 . |
N i |
Такой метод называется методом наименьших квадратов (МНК).
Ковариация и коэффициент корреляции непосредственно по данным выборки
рассчитываются следующим образом: |
|
|
|
|
|
|||||||||
m |
|
= |
1 |
(x |
|
− |
x¯ ) x |
− |
x¯ , r = |
|
mjj |
, j, j = 1, 2. |
||
|
N |
|
|
|
||||||||||
|
jj |
|
|
ij |
j ij |
|
j |
jj |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|||||
mjj mj j
Далее в этом пункте рассматривается случай линейной регрессии, т.е. случай,
когда |
|
x1 = α12x2 + β1 + ε1, |
(4.18) |
где α12, β1, ε1 — истинные значения параметров регрессии и остатков.
Следует иметь в виду, что регрессия линейна, если форма зависимости признаков линейна относительно оцениваемых параметров, а не самих признаков,
4.2. Регрессионный анализ |
147 |
||||
и уравнения |
|
||||
x1 = α12√ |
|
|
+ β1 + ε1, |
|
|
x2 |
|
||||
x1 = α12 |
1 |
+ β1 + ε1, |
|
||
|
|
||||
|
x2 |
|
|||
ln x1 = α12 ln x2 + ln β1 + ln ε1 |
(x1 = x2α12 β1ε1) , |
||||
и т.д. также относятся к линейной регрессии. Во всех этих случаях метод наименьших квадратов применяется одинаковым образом. Поэтому можно считать, что в записи (4.18) x1 и x2 являются результатом какого-либо функционального преобразования исходных значений.
Оценки параметров регрессии и остатков обозначаются соответствующими буквами латинского алфавита, и уравнение регрессии, записанное по наблюдениям i, имеет следующий вид:
xi1 = a12xi2 + b1 + ei1, |
i = 1, . . . , N, |
(4.19) |
а в матричной форме: |
|
|
X1 = X2a12 + 1N b1 + e1, |
(4.20) |
|
где X1, X2 — вектор-столбцы наблюдений |
размерности |
N , соответственно, |
за 1-м и 2-м признаками, e1 — вектор-столбец остатков; 1N — вектор-столбец размерности N , состоящий из единиц.
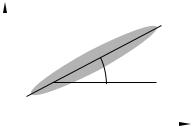
Прежде чем переходить к оценке параметров |
|
|
|
регрессии (применению метода наименьших |
x1 |
|
|
|
|||
квадратов), имеет смысл объяснить проис- |
|
||
|
|
|
|
хождение термина «регрессия». Этот термин |
|
|
|
введен английским статистиком Ф. Гальтоном |
|
|
<45° |
в последней четверти XIX века при изучении |
|
||
|
|
|
|
зависимости роста сыновей от роста отцов. |
|
|
|
Оказалось, что если по оси абсцисс распо- |
|
|
|
ложить рост отцов (x2 ), а по оси ординат — |
|
|
|
|
|
x2 |
|
рост сыновей (x1 ), то точки, соответствую- |
|
|
|
|
|
|
|
щие проведенным наблюдениям (облако то- |
|
|
Рис. 4.1 |
чек наблюдений), расположатся вокруг неко- |
|
|
|
|
|
|
|
торой прямой (рис. 4.1). |
|
|
|
Это означает, что зависимость между ростом сыновей и отцов существует, и эта зависимость близка к линейной. Но угол наклона соответствующей прямой меньше 45◦. Другими словами, имеет место «возврат» — регрессия — роста сыновей к некоторому среднему росту. Для этой зависимости и был предложен термин «регрессия». Со временем он закрепился за любыми зависимостями статистического характера, т.е. такими, которые выполняются «по математическому ожиданию», с погрешностью.
148 |
|
|
|
|
|
Глава 4. Введение в анализ связей |
Остаточная дисперсия из (4.19) получает следующее выражение: |
||||||
se21 = |
1 |
|
(xi1 − a12xi2 − b1)2, |
|||
|
|
|||||
N |
i |
|||||
|
|
|
|
|
|
|
или в матричной форме: |
|
|
|
|
|
|
|
|
s2 |
= |
1 |
e |
e , |
|
|
|
||||
|
|
e1 |
|
N 1 |
1 |
|
где
e1 = X1 − X2a12 − 1N b1, — остатки регрессии,
штрих — знак транспонирования. Величина e1e1 называется суммой квадратов остатков.
Для минимизации этой дисперсии ее производные по искомым параметрам (сначала по b1 , потом по a12 ) приравниваются к нулю.
∂se21 |
2 |
|
|
|
|
= − |
|
(xi1 − a12xi2 − b1) = 0, |
откуда: |
∂b1 |
N |
|||
|
|
|
ei1 = 0, |
|
|
|
|
b1 = x¯1 − a12x¯2. |
(4.21) |
Это означает, что e¯1 = 0, т.е. сумма остатков равна нулю, а также, что линия регрессии проходит через точку средних.
После подстановки полученной оценки свободного члена форма уравнения регрессии и остаточной дисперсии упрощается:
|
|
|
xˆi1 |
= a12xˆi2 + ei1, i = 1, . . . , N , |
(4.22) |
||||
ˆ |
ˆ |
+ e1, — сокращенная запись уравнения регрессии, |
(4.23) |
||||||
X1 |
= X2a12 |
||||||||
|
|
|
|
1 |
(ˆxi1 − a12xˆi2)2. |
|
|||
|
|
|
|
se21 = |
|
|
(4.24) |
||
|
|
|
|
N |
|||||
Далее: |
|
|
|
|
|
|
|
|
|
|
|
|
∂se21 |
2 |
|
ei1 |
|
||
|
|
|
|
←−−−−−−−−→ |
|
||||
|
|
|
|
= − |
|
|
xˆi2 (ˆxi1 − a12xˆi2) = 0. |
(4.25) |
|
|
|
|
∂a12 |
N |
|||||
Отсюда следует, во-первых, то, что вектора e1 и X2 ортогональны, т.к. ковариация между ними равна нулю ( xˆi2ei1 = 0); во-вторых — выражение для оценки углового коэффициента:
a12 |
= |
m12 |
. |
(4.26) |
|
||||
|
|
m22 |
|
|

4.2. Регрессионный анализ |
|
149 |
Матрица вторых производных остаточной дисперсии в найденной точке равна |
||
1 |
x¯2 |
, |
2 |
|
|
x¯2 |
m220 |
|
где m022 — 2-й начальный (а не центральный, как m22 ) момент для x2 . Тот же результат можно получить, если не переходить к сокращенной записи уравнения регрессии перед дифференцированием остаточной дисперсии по a12 .
Эта матрица положительно определена (ее определитель равен 2m22 , то есть всегда неотрицателен), поэтому найденная точка является действительно точкой минимума остаточной дисперсии.
Таким образом, построен оператор МНК-оценивания (4.21, 4.26) и выявлены свойства МНК-остатков: они ортогональны факторной переменной x2 , стоящей в правой части уравнения регрессии, и их среднее по наблюдениям равно нулю.
«Теоретические» значения моделируемой переменной x1, лежащие на линии оцененной регрессии:
xic1 |
= a12xi2 |
+ b1, |
(4.27) |
xˆic1 = a12xˆi2, |
|
||
где « c » — calculated, часто называют расчетными, или объясненными. Это — математические ожидания моделируемой переменной.
Вторую часть оператора МНК-оценивания (4.26) можно получить, используя другую логику рассуждений, часто применяемую в регрессионном анализе.
Обе части уравнения регрессии, записанного в сокращенной матричной форме (4.23) умножаются слева на транспонированный вектор X2 и делятся на N :
N1 X2X1 = N1 X2X2a12 + N1 X2e1.
Второе слагаемое правой части полученного уравнения отбрасывается, так как в силу отмеченных свойств МНК-остатков оно равно нулю, и получается искомое выражение: m12 = m22a12 .
Пользуясь этой логикой, оператор МНК-оценивания можно получить и в полном формате. Для этого используют запись регрессионного уравнения в форме без свободного члена (со скрытым свободным членом):
X1 = X2a12 + e1, |
(4.28) |
где X2 — матрица [X2, 1N ] размерности N × 2, a˜12 — вектор |
a12 |
b1 . |
150 |
Глава 4. Введение в анализ связей |
Как и прежде, обе части этого уравнения умножаются слева на транспонированную матрицу X2 и делятся на N , второе слагаемое правой части отбрасывается по тем же причинам. Получается выражение для оператора МНК-оценивания:
|
|
|
|
m12 = M22a12, т.е. a12 = M22−1m12, |
(4.29) |
|||
где m12 = |
1 |
X |
X1 |
, M22 = |
1 |
X |
X2 . |
|
|
|
|
||||||
|
N |
2 |
|
|
N |
2 |
|
|
|
|
|
|
|
|
|
||
Это выражение эквивалентно полученному выше. Действительно, учитывая,
что Xj = Xˆj + 1N x¯j , 1N Xˆj = 0, |
j = 1, 2, |
|
|
|
|
|
|||||||
|
m˜ |
12 = |
1 X2X1 |
= |
m12 + x¯1x¯2 |
, |
|
||||||
|
N |
|
|
x¯1 |
|
|
|
||||||
|
|
|
|
|
|
1N X1 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
m0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
22 |
|
|
|
|
|
|
1 X X2 |
X 1N |
|
←−−−−→ |
x¯2 |
|
|||||
˜ |
|
|
|
m22 |
+ x¯ |
2 |
|
||||||
= |
|
|
|
2 |
2 |
|
= |
|
2 |
|
. |
||
M22 |
|
|
|
|
|
|
|
|
|
|
|||
|
N |
|
|
|
|
|
|
|
|||||
|
|
|
|
|
1N X2 |
1N 1N |
|
x¯2 |
|
1 |
|
||
Тогда матричное уравнение (4.29) переписывается следующим образом:
m12 + x¯1x¯2 = m22a12 + x¯22a12 + x¯2b1,
x¯1 = x¯2a12 + b1.
Из 2-го уравнения сразу следует (4.21), а после подстановки b12 в 1-е уравнение оно преобразуется к (4.26). Что и требовалось доказать.
Таким образом, выражение (4.29) представляет собой компактную запись оператора МНК-оценивания.
Из проведенных рассуждений полезно, в частности, запомнить, что уравнение регрессии может быть представлено в трех формах: в исходной — (4.19, 4.20), сокращенной — (4.22, 4.23) и со скрытым свободным членом — (4.28). Третья форма имеет только матричное выражение.
Оцененное уравнение линейной регрессии «наследует» в определенном смысле свойства линии регрессии, введенной в начале этого пункта по данным совместного распределения двух признаков: минимальность остаточной дисперсии, равенство нулю средних остатков и ортогональность остатков к объясняющей переменной — в данном случае к значениям второго признака. (Последнее для регрессии, построенной по данным совместного распределения, звучало как линейная независимость отклонений от условных средних и самих условных средних.) Отличие в том, что теперь линия регрессии является прямой, условными средними являются расчетные значения моделируемой переменной, а условными дисперсиями — остаточная
4.2. Регрессионный анализ |
151 |
дисперсия, которая принимается при таком методе оценивания одинаковой для всех наблюдений.
Теперь рассматривается остаточная дисперсия (4.24) в точке минимума:
2 |
|
1 |
2 |
|
2 2 |
(4.26) |
|
m122 |
|
|
se1 |
= |
|
xˆi1 |
− 2ˆxi1xˆi2a12 |
+ xˆi2a12 |
= |
m11 − |
|
. |
(4.30) |
N |
m22 |
|||||||||
Поскольку остаточная дисперсия неотрицательна,
m11 |
|
m122 |
, т.е. r122 1. |
|
m22 |
||||
|
|
|
Это доказывает ранее сделанное утверждение о том, что коэффициент корреляции по абсолютной величине не превышает единицу.
Второе слагаемое (взятое с плюсом) правой части соотношения (4.30) является дисперсией расчетных значений моделируемой переменной (var — обозначение дисперсии):
|
1 |
(xic1 − x¯1c )2 |
e¯=0 |
1 |
(xic1 − x¯1)2 |
(4.27) |
|
|
|
|||
var (x1c ) = |
|
= |
|
|
|
|
= |
|
|
|
||
N |
|
N |
|
|
|
|
||||||
|
|
|
|
1 |
|
2 |
2 |
|
(4.26) |
m122 |
||
|
|
|
= |
|
|
|
(a12xˆi2) = a |
12 |
m22 |
= |
|
. (4.31) |
|
|
|
|
|
|
|
||||||
|
|
|
|
N |
|
|
|
m22 |
||||
|
|
|
|
|
|
|
|
|||||
Эту дисперсию, как и в регрессии, построенной по данным совместного распределения признаков, естественно назвать объясненной и обозначить s2q1 . Тогда из (4.30) следует, что общая дисперсия моделируемого признака, как и прежде, распадается на две части — объясненную и остаточную дисперсии:
s21 = m11 = s2q1 + s2e1.
Доля объясненной дисперсии в общей называется коэффициентом детерминации, который обозначается R2 . Такое обозначение не случайно, поскольку этот коэффициент равен квадрату коэффициента корреляции:
|
|
sq21 |
|
m2 |
|
R2 |
= |
|
= |
12 |
. |
s12 |
|
||||
|
|
|
m11m22 |
||
Коэффициент детерминации является показателем точности аппроксимации фактических значений признаков линией регрессии: чем ближе он к единице, тем точнее аппроксимация. При прочих равных его значение будет расти с уменьшением числа наблюдений. Так, если наблюдений всего два, этот коэффициент всегда будет равен единице, т.к. через две точки можно провести единственную прямую. Поэтому

152 |
Глава 4. Введение в анализ связей |
данный коэффициент выражает скорее «алгебраическое» качество построенного уравнения регрессии.
Показатель статистической значимости оцененного уравнения дает статистика Фишера — как и для регрессии, построенной по данным совместного распределения признаков. В данном случае остаточная дисперсия имеет N − 2 степени свободы, а объясненная — одну степень свободы (доказательство этого факта дается во II части книги):
F c = |
sq21 (N − 2) |
= |
R2 (N − 2) |
. |
|
|
|||
|
se21 |
(1 − R2) |
||
Если переменные не зависят друг от друга, т.е. α12 = 0 (нулевая гипотеза), то эта статистика имеет распределение Фишера с одной степенью свободы в числителе и N −2 степенями свободы в знаменателе. Логика использования этой статистики описана выше. Статистическая значимость (качество) полученного уравнения тем выше, чем ниже значение показателя pv для расчетного значения данной статистики F c.
Оценки параметров α12 , β1 и остатков εi1 можно получить иначе, из регрессии x2 по x1:
xˆi2 = a21xˆi1 + ei2, i = 1, . . . , N .
В соответствии с (4.26) оценка углового коэффициента получается делением ковариации переменных, стоящих в левой и правой частях уравнения, на дисперсию факторной переменной, стоящей в правой части уравнения:
a21 = m21 . m11
1 |
|
1 |
|
|
|
|
|
|
|||
Поскольку xˆi1 = |
|
xˆi2 − |
|
ei2 |
, |
|
|
|
|||
a21 |
a21 |
|
|
||||||||
|
a12 |
(2) = |
1 |
|
= |
m11 |
, |
(4.32) |
|||
|
a21 |
m21 |
|||||||||
|
|
|
|
|
|
|
|
||||
|
b1 (2) = x¯1 − a12 (2) x¯2, |
||||||||||
|
ei1 (2) = a12 (2) ei2, |
|
i = 1, . . . , N. |
||||||||
Это — новые оценки параметров. Легко убедиться в том, что a12 (2) совпадает
с a12 (а вслед за ним b1 (2) совпадает с |
b1 и ei1 (2) — с ei1 ) тогда и только |
тогда, когда коэффициент корреляции r12 |
равен единице, т.е. зависимость имеет |
функциональный характер и все остатки равны нулю.
При оценке параметров α12 , β1 и остатков ei1 регрессия x1 по x2 иногда называется прямой, регрессия x1 по x2 — обратной.