

-
Линейное уравнение регрессии
Формула линейного уравнения регрессии (1)
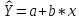 (1)
(1)
Где,
x,y – переменные,
a,b – параметры.
Система нормальных уравнений (2) в общем виде:
 (2)
(2)
Где,
x,y – то же что и в формуле (1),
a,b – то же что и в формуле (1),
n - количество наблюдений в совокупности.
Система нормальных уравнений с вычисленными коэффициентами:

Решение системы:

Построенное линейное уравнение регрессии:


Рис. 1 График линейного уравнения регрессии
-
Показательное уравнение регрессии
Показательное уравнение регрессии имеет следующий вид:
 (3),
(3),
где,
 ,
,
 ,
,
где,
x,y – то же что и в формуле (1),
a,b – то же что и в формуле (1),
n – то же что и в формуле (2).
Найдем b0 и b1:
 ,
,
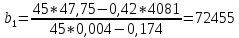 .
.
Полечим показательное уравнение регрессии:

-
Логарифмическое уравнение регрессии
Логарифмическое уравнение регрессии определяется по формуле:
 (6)
(6)
Где,
x,y – то же что и в формуле (1),
b – то же что и в формуле (1),
 ,
,
 (8),
(8),
Где,
x,y – то же что и в формуле (1),
b – то же что и в формуле (1),
n – то же что и в формуле (2).
Найдем b0 и b1:


Получим логарифмическое уравнение регрессии:


Рис. 1 График логарифмического уравнения регрессии
-
Индекс парной корреляции для уравнений регрессии
Индекс парной корреляции исчисляется по следующей формуле:
 (9)
(9)
Где,
y – то же что и в формуле (1),
 – значение
у из исследуемого уравнения,
– значение
у из исследуемого уравнения,
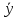 -
среднее значение y.
-
среднее значение y.
Для оценки качества построенной модели регрессии можно использовать индекс детерминации или среднюю ошибку аппроксимации. Чем выше показатель детерминации или чем ниже ошибка аппроксимации, чем лучше модель описывает исходные данные.
Средняя ошибка аппроксимации – среднее относительное отклонение расчетных значений от фактических, рассчитывается по формуле
 (10)
(10)
Где,
n – то же что и в формуле (2),
y – то же что и в фотрмуле (1).
Индекс парной корреляции для линейного уравнения регрессии:
 =
0,92
=
0,92
Средняя ошибка аппроксимации для линейного уравнения регрессии:
 =6%
=6%
Индекс парной корреляции для логарифмического уравнения регрессии:
 =0,95
=0,95
Средняя ошибка аппроксимации для логарифмического уравнения регрессии:
 =6%
=6%
Построенные
уравнения считаются удовлетворительными,
так как
 .
Коэффициент
детерминации достаточно высокий, а это
значит, что модель точно описывает
исходные данные.
.
Коэффициент
детерминации достаточно высокий, а это
значит, что модель точно описывает
исходные данные.
-
Поверка значимости уравнения регрессии и отдельных коэффициентов линейного уравнения
Оценка статистической значимости уравнения регрессии в целом осуществляется с помощью F-критерия Фишера.
Величина Fфакт определяется по формуле:
 (11)
(11)
Где,
 -
индекс детерминации,
-
индекс детерминации,
n – то же что и в формуле (2),
m – число параметров при переменных.
Таким образом, для
-
линейного уравнения регрессии:
Fфакт
=
 =2,26
=2,26
Fкрит =4,08, при α =0,05
Fтабл>Fфакт , гипотеза H0 не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
-
логарифмического уравнения регрессии:
 =3,87
=3,87
Fкрит =4,08, при α =0,05
Fтабл>Fфакт , гипотеза H0 не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов линейной регрессии применяется t-критерий Стьюдента:
Величины tb,факт и ta, факт определяются по формулам:
 (12)
(12)
 (13)
(13)
 (14)
(14)
Где,
a,b – то же что и в формуле (1),
rxy - коэффициент корреляции,
mb, ma, mrxy – стандартные ошибки.
Таким образом, для
-
линейного уравнения регрессии:
 =0,45
=0,45
 =0,66
=0,66
 =0,46
=0,46
-
логарифмического уравнения регрессии:
 =1,93
=1,93
 =3,03
=3,03
 =0,4
=0,4
Стандартные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
 (15)
(15)
 (16)
(16)
 (17)
(17)
Где, y – то же что и в формуле (1),
 – то
же что и в формуле (9),
– то
же что и в формуле (9),
 -
то же что и в формуле (9),
-
то же что и в формуле (9),
rxy - то же что и в формуле (14),
x – то же что и в формуле (1)
Таким образом, для
-
линейного уравнения регрессии:
 =
0,8
=
0,8
 =86,3
=86,3
 =
0,13
=
0,13
-
логарифмического уравнения регрессии:
 =
0,14
=
0,14
 =18,69
=18,69
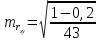 =
0,14
=
0,14
-
Построение интервального прогноза для значения x = xmax по уравнению линейной регрессии
При
построении доверительного интервала
прогноза используется стандартная
ошибка индивидуального значения прогноза
 ,
которая рассчитывается по формуле:
,
которая рассчитывается по формуле:
 (18)
(18)
Где,
 (19),
(19),
Где,
x,y – то же что и в формуле (1),
n – то же что и в формуле (2),
m – то же что и в формуле (15)
Затем
строится доверительный интервал
прогноза, т.е. определяются нижняя
 и верхняя
и верхняя
 границы
интервала прогноза:
границы
интервала прогноза:
 =
= (20)
(20)
 =
= (21),
(21),
Где,
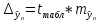 (22),
(22),
Где,
 -
максимально возможное значение критерия
под влиянием случайных факторов при
данной степени свободы k=n-2
и уровне значимости α.
-
максимально возможное значение критерия
под влиянием случайных факторов при
данной степени свободы k=n-2
и уровне значимости α.
 -
стандартная ошибка прогноза
-
стандартная ошибка прогноза
Таким образом, для
-
линейного уравнения регрессии:
 =
35,74
=
35,74

 =
= =57.73
=57.73
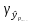 =
= =67,03
=67,03

-
логарифмического уравнения регрессии:
 =7,74
=7,74
 =7,19
=7,19
 =
= =321,2
=321,2
 =
= =323,06
=323,06
