

МЕТОДИКА УПРАВЛЕНИЯ РИСКАМИ ПРОГРАММНЫХ ПРОЕКТОВ НА ОСНОВЕ САМООРГАНИЗУЮЩИХСЯ КАРТ КОХОНЕНА
Р.Р. Мулюков, студент Оренбургский государственный университет, г. Оренбург
E-mail: rr_mul@rambler.ru
Введение. К настоящему моменту существует немало разнообразных программных проектов, но не все эти проекты достигают своей цели, воплощаясь в конечный продукт, оправдывающий ожидания заказчика. Недостаточно хорошо поставленный план организации разработки ПО может произвести к излишнему труду программистов, лишние растраты там, где, казалось бы, можно обойтись. Необходимо грамотно подходить к управлению проектом разработки ПО, завершение которого принесет необходимую прибыль исполнителю и обеспечение выполнения требуемых задач заказчику.
Современная наука определяет риск, как возможность возникновения потерь, вытекающая из специфики тех или иных видов человеческой деятельности; вероятность принятия неверных, непринятия нужных управленческих решений; вероятность получения незапланированных результатов при осуществлении той или иной деятельности [1].
Управление рисками — это процесс продумывания корректирующих действий прежде, чем возникнет проблема, пока она еще остается всего лишь абстракцией [2].
Существует 4 типичные стратегии реагирования на появление рисков, способных оказать негативное воздействие на достижение цели проекта: уклонение от риска; передача риска; снижение риска; принятие риска [2]. Для каждого риска необходимо выбрать стратегию или комбинацию стратегий, представляющуюся наиболее эффективной.
В качестве источника информации при выявлении рисков могут служить различные доступные контрольные списки рисков проектов разработки ПО, которые следует проанализировать на применимость к данному конкретному проекту. Существуют главные риски, которые затрагивают большинство проектов, и второстепенные, свойственные, как правило, проектам с определенной спецификой задач. Одними из таких главных рисков являются: нереалистичные сроки и бюджет, текучесть кадров, раздувание требований, низкая производительность [2]. Важно учитывать такие риски.
Руководитель, ответственный за успех проекта, неграмотно или вообще не управляющий рисками рискует приобрести множество проблем, вплоть до провала проекта, с вытекающими из этого обстоятельствами. Участие в процессе управления рисками касается и заказчика, так как от него зависит понятная исполнителю цель разработки и условия (задание сроков, выделение средств, коммуникация с исполнителем и т. п.). Это делает задачу управления рисками разработки ПО актуальной.
Один из этапов управления рисками является: их идентификация, подразумевающая выявление рисков, способных повлиять на проект, и определение их характеристик (вероятность наступления, влекущее неблагоприятное событие; степень опасности; причина возникновения) [3]. Следует помнить, что проблемы завершенных и выполняемых проектов - это, как правило, риски в новых проектах.
Актуальность работы. Ошибки планирования при разработке зачастую не позволяют выпускать продукты в срок и укладываться в выделенный бюджет [4]. Это связано как со сложностью задачи планирования, так и с учетом особенностей продукта и команды разработки, финансовых ограничений и т.д. Анализ таких систем управления проектами, как Spider Project, Primavera, MS Project 2007 показал, что большинство из них требует точной оценки времени выполнения отдельных задач, в них нет механизма анализа параметров задач и исполнителей, который бы позволил оценить это время [5]. Важно отметить и тот факт, что разработка программных систем (ПС) связана с большим числом
неопределенностей, коррелированных величин, что приводит к высокой сложности управления проектом. Прогнозирование производственного процесса, времени выполнения задач, принятия своевременных контрмер, изучение динамики выполнения задач и т.д., способствует предсказанию риска успешного завершения программных проектов. Таким образом, разработка автоматизированной системы прогнозирования величины риска является актуальной задачей в области управления программными проектами.
Технология решения задачи прогнозирования величины риска реализации программного проекта. Прогнозирование рисков будет применяться в первую очередь системным аналитиком (архитектором проекта), так как в его полномочия входят такие обязанности, как выбор средств исполнения, совещания с заказчиком, разбиение системы на компоненты, определение протоколов взаимодействия компонентов, определение форматов хранения и передачи данных, рецензирование требований, разработка нефункциональных требований, стратегическое планирование развития системы, написание технического проекта. В зависимости от значения прогноза, этими функциями можно управлять на основе опыта проектной организации, рекомендаций экспертов, принятия решений и проведение совещания заинтересованными сторонами [6].
Разрабатываемая ПС будет реализована по следующему сценарию: на текущий этап жизненного цикла программного проекта определяется образующая риск ситуация на основе сложившихся в проекте обстоятельств; риски определяются всеми доступными управляющими сторонами способами, такими, как [7]: анализ документации; методы сбора информации (мозговой штурм, метод Дельфи, проведение опросов, анализ первопричин); анализ контрольных списков; анализ допущений; методы составления диаграмм (причинноследственные диаграммы, блок-схемы процесса, диаграммы влияния); анализ сильных и слабых сторон, возможностей и угроз; экспертная оценка.
Все эти способы решают задачу идентификации рисков. Далее, проводится количественная оценка выявленных рисков соответствующими методами: методы сбора и представления информации (опросы, распределение вероятностей); методы количественного анализа рисков и моделирования (анализ чувствительности, анализ ожидаемого денежного значения, моделирование и имитация); экспертная оценка.
В данной работе применяется иной подход определения величины риска – метод нечеткого логического вывода, использующий лингвистические переменные, в качестве его показателей.
Полученные величины риска и значения их показателей сохраняются в проектной истории. После определения текущей величины, а также, используя уже имеющуюся базу значений рисков по текущему проекту или аналогичным (чья полнота значений удовлетворяет условиям метода прогноза) проводится прогноз следующего значения риска, свойственного сформировавшейся тенденции его поведения. Сформированная диаграмма потоков данных при определении уровня прогноза рисков в нотации Data Flow Diagram (DFD) представлена на рисунке 1.
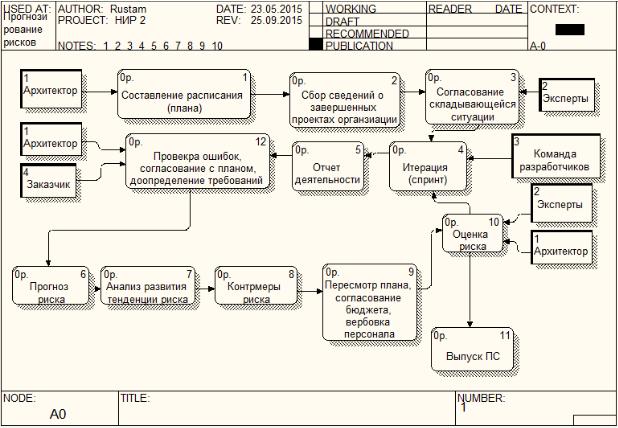
Рисунок 1 – Диаграмма потоков данных DFD
Т.е., чем точнее информацией о формировании значения риска системный аналитик обладает, тем точнее и своевременней может скорректировать средства исполнения, изменить приоритеты требований, иначе спланировать систему, изменить технический проект, обсудить риски с заказчиком. Другими словами – выбрать такое решение, которое обоснует принятие контрмер, передачу риска другим сторонам или решение о бездействии на риск в связи, с, например, нерациональностью расходования на него ресурсов.
Описание задачи. При выполнении работы рассмотрены следующие методы прогнозирования: методы регрессионного и корреляционного анализа; авторегрессионные методы Бокса-Дженкинса (ARIMA); моделирование вероятности Монте-Карло; цепи Маркова; классификационно-регрессионные деревья; нейронные сети [8].
Опишем преимущества и недостатки этих методов и сравним с нейронными сетями, которые были выбраны для решения задачи прогнозирования.
Регрессионные и корреляционные методы, на примере метода наименьших квадратов (МНК). МНК характеризуется независимыми переменными (отсутствует корреляция и автокорреляция), случайные ошибки имеют нулевую среднюю и конечную дисперсию (по нормальному закону), отсутствует мультиколлинеарность, относительная простота реализации на ЭВМ [9]. Недостатками регрессионных и авторегрессионных методов являются: несводимость к линейной зависимости, возникающая на некоторых данных; строгие требования к входным данным (удовлетворение нормальному закону распределения).
Модель и методы ARIMA основаны на принципе скользящего среднего, анализирующие временные ряды. ARIMA является расширением модели ARMA для нестационарных временных рядов, которые можно сделать стационарными взятием
разностей некоторого порядка от исходного временного ряда. В ARIMA можно выделить такие особенности, как малая дальность прогнозирования, итеративный подход к определению допустимой модели среди общего класса моделей. Недостатками ARIMA являются: необходимость большого количество исходных данных; отсутствие простого способа корректировки параметров моделей ARIMA; требует больших затрат времени и ресурсов [10].
Моделирование Монте-Карло – общее название группы численных методов, основанных на получении большого числа реализаций стохастического процесса, который формируется таким образом, чтобы его вероятностные характеристики совпадали с аналогичными величинами решаемой задачи. Методы Монте-Карло характеризуются: большим числом опытов, возможностью использования любых распределений, показатели качества исследуемого процесса зависят от большого числа случайных факторов. К недостаткам стоит определить факт о сложности реализации, требующей мощных вычислительных ресурсов [11].
Марковские случайные процессы относятся к частным случаям случайных процессов, которые в свою очередь основаны на понятии случайной функции. Случайной функцией называется функция, значение которой при любом значении аргумента является случайной величиной. Марковские цепи оперируют вероятностными величинами. Особенностями цепей Маркова состоит в том, что при фиксированном настоящем будущее независимо от прошлого. К недостаткам Марковских цепей относят слабую развитость теории сложных цепей, которое представляет объединение предшествующих в одну [12].
Стохастическое градиентное добавление – метод анализа данных, представляющий собой решение задачи регрессии методом простроения комитета (ансамбля) «слабых» предсказывающих деревьев принятия решений. Особенностью метода являются: высокое качество результата, особенно для данных с большим количеством наблюдений и малым количеством переменных; Сравнительно малый размер модели; сравнительно быстрое время построения оптимальной модели. Недостатками являются: относительная слабая устойчивость к ошибочным данным и переобучение; требуется тестовая выборка, либо кросс-валидация; невозможность распараллеливания; сложная интерпретация модели [13].
Карты Кохонена обладают устойчивостью к зашумленным данным, быстрому и неуправляемому обучению, возможностью упрощения многомерных входных данных с помощью визуализации. Недостатком карт является свидетельство об окончательном результате работы нейронной сети, которое зависит от начальных установок сети.
Несмотря на зависимость от начальных установок сети, карты Кохонена относительно не строго требовательны к данным, возможность свести результат моделирования к линейной зависимости, простой способ корректировки параметров, реализация алгоритма относительно большинства рассмотренных методов не сильно предъявляет требования к вычислительным ресурсам.
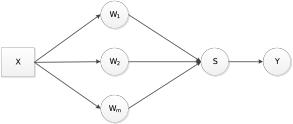
Таким образом, выбор прогнозирования нейросетевым методом оправдан. Описание метода. Модель решения задачи представлена в виде графа, рис.2.
Рисунок 2 – Модель решения задачи прогнозирования

X – вектор входных параметров нейронной сети (показатели риска); W – векторы отображения (разделяющий класс выборки);
S – сумма скалярных произведений скалярного вектора X; Y – выходное значение (величина риска);
m – число скрытых нейронов-отображений w, которые выбирается при построении. Описание алгоритма. Алгоритм обучения сети Кохонена [14].
Подготовительным этапом алгоритма является нормализация входных векторов перед предъявлением их в сеть. Данная операция представлена формулой 1.
x 'i |
|
xi |
|
|
|
|
|
|
|
|
|
n |
|
(1) |
|||
|
|
|
|||
|
|
xi |
2 |
||
|
|
i 1 |
|
|
|
Шаг 1. Инициализация сети. Весовым коэффициентам сети wi,j, i = 1, 2, …, n, j = 1, 2, …, m присваиваются малые случайные значения. Задаются значения α0 – начальный темп обучения и R0 – максимальное расстояние между весовыми векторами (столбцами матрицы W).
Шаг 2. Предъявление сети нового входного сигнала X.
Шаг 3. Вычисление расстояния от входа X до всех нейронов сети (2):
n |
m |
|
d j (xi wiN, j )2 |
(2) |
|
i 1 |
j 1 |
|
Шаг 4. Выбор нейрона k, 1≤k≤m с наименьшим расстоянием dk.
Шаг 5. Настройка весов нейрона k и всех нейронов, находящихся от него на расстоянии, не превосходящем DN (3):
wiN, j 1 wiN, j N h (xi |
wiN, j ) |
(3) |
Где h – функция соседства нейронов (функция Гаусса, 4), R – уровень соседства, w – номер нейрона победителя, i – текущий нейрон (1 ≤ i ≤ m) (4).
|
|
|
2 |
i |
|
2 |
|
|
||
|
|
|
w |
|
||||||
|
(i mod m wmod m) |
|
|
|
|
|
|
|
(4) |
|
|
|
|
|
|||||||
|
|
2 R2 |
|
m |
|
m |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
h e |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Шаг 6: Уменьшение значения αN, RN.
Шаг 7: Шаги 2 – 6 повторяются до тех пор, пока веса не перестанут меняться (или пока суммарное изменение всех весов станет очень мало).
После обучения классификация выполняется посредством подачи на вход сети испытуемого вектора, вычисления расстояния от него до каждого нейрона с последующим выбором нейрона с наименьшим расстоянием как индикатора правильной классификации.
Шаг 8: В данном случае целесообразно заранее не выделять какое-то отображение, а прогнозировать по всем группам координат. Т.о., вычисляют сумму скалярных
произведений S (5) входного вектора X с каждым выходным отображением W . В этом
случае для прогноза используется итоговое значение функционирования сети Y, которое получается подстановкой скаляра S в функцию активации, заданную гиперболическим тангенсом (6). Этот процесс можно также рассматривать как добавление нового скрытого слоя в сеть [15].

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S (W |
j X ) |
(5) |
||||||||
|
|
|
|
j 1 |
|
|
|
|
|
|
|
|
|
|
|
|
Y |
eS e S |
(6) |
||||||
|
|
|
|
eS e S |
||||||||
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
j – номер |
где X |
– исходный вектор; W – отображение исходного вектора X ; |
|||||||||||
отображения вектора X ; – количество отображений вектора X .
Процедура прогнозирования.
Шаг 1: Ключевое отличие данной модели от других исследований в области сетей Кохонена состоит в том, что для определения начальных векторов-отображений использует-
ся ковариационная матрица вектора X .
Для достижения цели фиксации выбросов каждого временного промежутка нужно задать исходный вектор X , рассматривая временной период за N контрольных точек до
дня прогноза. При этом целесообразно использовать метод «скользящего окна», т.е. данный отрезок сдвигать вперёд во времени на каждом шаге прогноза.
Внутри промежутка из N контрольных точек находится точка с максимальным абсолютным ростом уровня риска, а затем формируется начальный вектор X , состоящий из
N/2 последовательных значений до точки максимума. Далее проводится итеративная процедура обучения сети, описанная выше.
Данный этап обучения называется «обучением на максимуме». Затем можно перейти к следующему этапу – «обучению на минимуме». Исходный вектор X в данном случае
формируется из N/2 значений до точки минимума – наименьшего абсолютного роста уровня риска на том же отрезке времени. При этом на втором этапе начальные векторы-отображе- ния не формируются заново, а используются те, которые были получены в процессе «обучения на максимуме» [16], рис.3.
Заключение. ПС предназначается для системного аналитика проекта, который будет применять систему для учета рисков проекта и своевременной реакции реагирования на ожидаемые угрозы. В ходе выполнения работы была определена графовая модель решения задачи, выбран метод прогнозирования рисков посредством обучения нейросети по алгоритму Кохонена. Данный метод обладает преимуществами перед другими методами.
В результате, определен метод решения задачи о прогнозировании рисков в прикладных программных проектах.
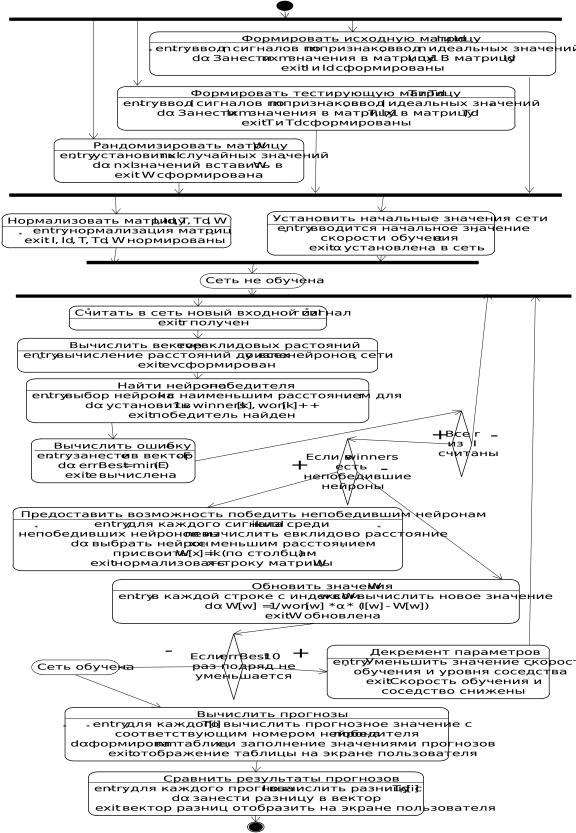
Рисунок 3 – Диаграмма состояний работы нейронной сети Кохонена
Список литературы:

1 Ишакова, Е.Н. Программная система оценки рисков в сфере высшего образования с использованием продукционно – фреймовой модели / Е.Н. Ишакова, Т.М. Зубкова, А.С. Медведев // Вестник ОГУ. - 2014. - №1. - С. 183 - 188.
2 Де Марко Т., Листер Т., Вальсируя с медведями. Управление рисками в проектах по разработке программного обеспечения / Т.Де Марко, Т.Листер – М.: p.m.Office, 2005 – 208 c.
3 Архипенков С., Лекции по управлению программными проектами / С.Архипенков
– М.: 2009 – 127 с 4 Полицин С.А. Система планирования проектов разработки программного
обеспечения / С.А. Полицин // Вестник воронежского государственного университета. Серия: системный анализ и информационные технологии. – 2013, - №1, -с. 136-141
5 Голубева Т.А., Структурно-логическая модель прогнозирования времени выполнения проекта разработки программного обеспечения / Т.А. Голубева // Научные труды винницкого национального технического университета. -2008, -№3, - C.10.
6 Архитектор программного обеспечения // ru.wikipedia.org, URL:https://ru.wikipedia.org/wiki/Архитектор_программного_обеспечения (дата обращения: 01.06.2015).
7 Руководство к своду знаний по управлению проектами (руководство PMBOK). Четвертое издание. - Пенсильвания, PMI, 2008. – 496 с.
8 Классификация методов и моделей прогнозирования // habrahabr.ru, URL: http://habrahabr.ru/post/177633/ (дата обращения: 01.06.2015).
9 Тихонов Э.Е. Прогнозирование в условиях рынка. Учебное пособие. / Э.Е.Тихонов – Невиномысск: Северо-Кавказский государственный технический университет, 2006. – 221 с.
10 ARIMA // ru.wikipedia.org, URL:https://ru.wikipedia.org/wiki/ARIMA (дата обращения: 01.06.2015).
11Метод Монте-Карло // ru.wikipedia.org, URL:https://ru.wikipedia.org/wiki/Метод_Монте-Карло (дата обращения: 01.06.2015).
12Костин В.Н., Статистические методы и модели: Учебное пособие. / В.Н.Костин, Н.А.Тишина – Оренбург: ГОУ ОГУ, 2004. – 138 с.
13Классификация и регрессия с помощью деревьев принятия решений // habrahabr.ru, URL: http://habrahabr.ru/post/116385/ (дата обращения: 01.06.2015).
14Чулюков В.А. Системы искусственного интеллекта. Практический курс. Учебное пособие / В.А.Чулюков, И.Ф.Астахова, А.С.Потапов, И.Л.Каширина, Л.С.Миловская, М.В.Богданова, Ю.В.Просветова – М.: Физматлит, 2008. – 292 с.
15Головачев, С.С. Использование искусственных нейронных сетей для прогнозирования американского фондового рынка в период кризиса / С.С. Головачев // Управление экономическими системами: Электронный научный журнал. – 2012. - № 11 (47).
-Режим доступа: http://www.uecs.ru/uecs-47-472012. (дата обращения: 01.06.2015).
16Е.Н.Ишакова, Нейросетевое прогнозирование образовательных рисков / Е.Н. Ишакова, Т.М.Зубкова // Современные информационные технологии в науке, образовании и практике: материалы XI Всеросийской научно-практической конференции. – 2014. – с. 2628.