

Билет№17
Реляционная база данных — это совокупность взаимосвязанных таблиц, каждая из которых содержит информацию об объектах определенного типа. Строка таблицы содержит данные об одном объекте (например, товаре, клиенте), а столбцы таблицы описывают различные характеристики этих объектов — атрибутов (например, наименование, код товара, сведения о клиенте). Записи, т. е. строки таблицы, имеют одинаковую структуру — они состоят из полей, хранящих атрибуты объекта. Каждое поле, т. е. столбец, описывает только одну характеристику объекта и имеет строго определенный тип данных. Все записи имеют одни и те же поля, только в них отображаются различные информационные свойства объекта.
В реляционной базе данных каждая таблица должна иметь первичный ключ — поле или комбинацию полей, которые единственным образом идентифицируют каждую строку таблицы. Если ключ состоит из нескольких полей, он называется составным. Ключ должен быть уникальным и однозначно определять запись. По значению ключа можно отыскать единственную запись. Ключи служат также для упорядочивания информации в БД.
CREATE TABLE | DBF TableName1 [NAME LongTableName] [FREE]
(FieldName1 FieldType [(nFieldWidth [, nPrecision])]
[NULL | NOT NULL]
[CHECK lExpression1 [ERROR cMessageText1]]
[DEFAULT eExpression1]
[PRIMARY KEY | UNIQUE]
[REFERENCES TableName2 [TAG TagName1]]
[NOCPTRANS]
[, FieldName2 ...]
[, PRIMARY KEY eExpression2 TAG TagName2
|, UNIQUE eExpression3 TAG TagName3]
[, FOREIGN KEY eExpression4 TAG TagName4 [NODUP]
REFERENCES TableName3 [TAG TagName5]]
[, CHECK lExpression2 [ERROR cMessageText2]])
| FROM ARRAY ArrayName
(Рассказать, как создать таблицу)
Совместная обработка таблиц

INNER
JOIN
это синоним для JOIN.
Выбираются только совпадающие данные
из объединяемых таблиц. Чтобы получить
данные, которые не подходят по условию,
необходимо использовать внешнее
объединение - OUTER JOIN. Такое объединение
вернет данные из обеих таблиц совпадающими
по одному из условий.
Существует
два типа внешнего объединения (OUTER JOIN)
- LEFT OUTER JOIN и RIGHT OUTER JOIN. Работают они
одинаково, разница заключается в том
что LEFT - указывает что "внешней"
таблицей будет находящаяся слева (в
нашем примере это таблица users). Ключевое
слово OUTER можно опустить. Запись LEFT JOIN
идентична LEFT OUTER JOIN.
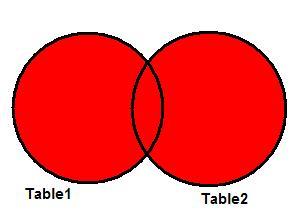
Полностью это соединение называется FULL OUTER JOIN (зарезервированное слово OUTER необязательно). FULL JOIN работает как объединение двух множеств.
Билет 18
Ограничения целостности связи. Возможности реализации в современных СУБД.
Вторым аспектом реляционной модели данных является поддержка целостности.
Целостность данных понимается как правильность данных в любой момент времени при
манипулировании данными. Поддержание целостности базы данных может рассматриваться как защита данных от неверных изменений или разрушений.
В классическом понимании поддержка целостности включает 3 части:
• Структурная целостность
• Языковая целостность
• Ссылочная целостность
Эти 3 вида целостности определяют допустимую форму представления и обработки
информации в реляционных БД.
Для определения некоторых ограничений, связанных с содержанием БД, используется другой вид целостности, а именно:
• Семантическая целостность
Структурная целостность
Структурная целостность подразумевает, что реляционная СУБД может работать только с
реляционными отношениями. А реляционное отношение, в свою очередь, должно удовлетворять ограничениям, накладываемым на него в классической теории реляционных БД (отсутствие одинаковых кортежей и, следовательно, наличие первичного ключа, отсутствие упорядоченности атрибутов и кортежей).
Требование структурной целостности осуществляется с помощью двух ограничений:
• при добавлении кортежей в отношение проверяется уникальность их первичных ключей
• не допускается, чтобы какой-либо атрибут, участвующий в первичном ключе, принимал
неопределенное значение
Здесь возникает необходимость рассмотреть проблему неопределенных значений (Null-значений) [1, 2]. Неопределенное значение интерпретируется в реляционной модели как значение, неизвестное на данный момент времени. При сравнении неопределенных значений не действуют стандартные правила сравнения: одно Null-значение никогда не считается равным другому Null-значению.
Для выявления равенства значения некоторого атрибута неопределенному применяют
стандартные предикаты:
• <Имя атрибута> Is Null
• <Имя атрибута> Is Not Null
Языковая целостность
Языковая целостность состоит в том, что реляционная СУБД должна обеспечивать языки
описания и манипулирования данными не ниже стандарта SQL. Не должны быть доступны иные низкоуровневые средства манипулирования данными, не соответствующие стандарту.
Ссылочная целостность
При установлении связи между отношениями возникает необходимость поддержания
целостности по ссылкам. Отношение со стороны «один» будем называть – основным отношением, а отношение со стороны «многие» – подчиненным.
Требование ссылочной целостности состоит в следующем: для каждого значения внешнего
ключа, появляющегося в подчиненном отношении, в основном отношении должен существовать кортеж с таким же значением первичного ключа.
У первичного и внешнего ключей, образующих связь, должен быть одинаковый тип данных.
То есть значение внешнего ключа должно либо:
• быть равным значению первичного ключа
• быть полностью неопределенным, т.е. каждое значение поля, участвующего во внешнем
ключе должно быть неопределенным. 30
Для каждого внешнего ключа в процессе проектирования необходимо решить три вопроса:
1. Может ли данный внешний ключ принимать неопределенные значения
2. Что произойдет при попытке УДАЛЕНИЯ записи из основного отношения, на которую ссылается
внешний ключ подчиненного отношения?
Например, удалить поставщика, для которого имеется, по крайней мере, одна поставка.
В общем случае существует три ситуации:
• Каскадирование удаления, при котором удаляются все записи из подчиненного отношения, соответствующие удаляемому первичному ключу основного отношения (будет удален поставщик и все его поставки)
• Ограничение удаления, при котором удаляется запись из основного отношения только в том случае, если в подчиненном отношении нет соответствующих значений внешнего ключа, иначе удаление отменяется (удаление поставщика невозможно, пока существует хотя бы одна его поставка)
• Установка неопределенных значений, при которой внешний ключ подчиненного отношения устанавливается в неопределенное значение (Null-значание), а соответствующая запись из
основного отношения удаляется (все значения внешнего ключа в поставках принимают
Null-значение, а поставщик удаляется)
Данное свойство поддерживается не всеми СУБД. Если необходимо применить эту
ситуацию, то в подчиненном отношении сначала нужно удалить все значения внешнего
ключа соответствующие первичному, и только после этого удалять запись из основного
отношения с соответствующим первичным ключом
3. Что произойдет при попытке ОБНОВЛЕНИЯ первичного ключа основного отношения, на
который ссылается некоторый внешний ключ подчиненного отношения? Например, при попытке
обновления кода поставщика, для которого имеется хотя бы одна поставка.
Здесь также возможны три ситуации:
• Каскадирование обновления, при котором при обновлении первичного ключа обновляются
все соответствующие внешние ключи (будет обновлен код поставщика в основном
отношении и все соответствующие ему внешние ключи в поставках)
• Ограничение обновления, при котором обновляется первичный ключ в основном отношении
только в том случае, если в подчиненном отношении нет соответствующих значений
внешнего ключа, иначе обновление отменяется (обновление кода поставщика невозможно,
пока существует хотя бы одна поставка этого поставщика)
• Установка неопределенных значений, при которой внешний ключ подчиненного отношения
устанавливается в неопределенное значение, а соответствующий первичный ключ в
основном отношении обновляется (все значения внешнего ключа в поставках принимают
Null-значение, а код поставщика в основном отношении обновляется)
Семантическая целостность
Данный вид целостности задается разработчиком в процессе проектирования БД посредством задания ограничений для свойств полей. Обычно задаются ограничения свойств:
• уникальность значений полей. Например, в отношении Студент (№ зачетной книжки, ФИО,
Паспорт, Адрес) свойство уникальности значений должно быть установлено для атрибутов:
№ зачетной книжки (т.к. это первичный ключ) и Паспорт (т.к. номера всех паспортов
уникальны)
• обязательность заполнения полей (допустимость или недопустимость Null-значений).
Например, при вводе данных о поставщиках не вся информация может быть доступна
сразу: адрес, телефоны для связи могут быть уточнены позднее. Т.е. для атрибутов Код
города, Адрес, Телефон устанавливается допустимость Null-значений
• значение по умолчанию. Задание значения по умолчанию по умолчания означает, что
каждый раз при вводе новой строки в отношение, при отсутствии данных этому атрибуту
присваивается значение по умолчанию. Например, если большинство поставщиков
находятся во Владивостоке, то для атрибута Код города присваивается значение по
умолчанию соответствующее коду Владивостока
• диапазон значений. Например, оценки выставляются по пяти бальной шкале от 1 до 5,
• принадлежность набору значений. Например, атрибут Результат зачета может принимать
значения только «Зачтено» или «Не зачтено»
Современные СУБД могут служить не только для выбора данных, но и описания ключей, связей. В современных СУБД реализованы механизмы, необходимые для обеспечения целостности данных: установление формата данных в атрибутах, определение характера связей в реляционных отношениях, назначение атрибута первичным и внешним ключом.
SQL. Упорядочение данных. Операция объединения.
УПОРЯДОЧЕНИЕ ВЫВОДА ПОЛЕЙ
Таблицы - это неупорядоченные наборы данных, и данные которые выходят из них, не обязательно появляются в какой-то определенной последовательности. SQL использует команду ORDER BY чтобы позволять вам упорядочивать ваш вывод. Эта команда упорядочивает вывод запроса согласно значениям в том или ином количестве выбранных столбцов. Многочисленные столбцы упорядочиваются один внутри другого, также как с GROUP BY, и вы можете определять возрастание (ASC) или убывание (DESC ) для каждого столбца. По умолчанию установлено - возрастание. Давайте рассмотрим нашу таблицу порядка, приводимую в порядок с помощью номера заказчика
(обратите внимание на значения в cnum столбце):
SELECT *
FROM Orders
ORDER BY cnum DESC;
Мы можем также упорядочивать таблицу с помощью другого столбца, например, с помощью \ amt, внутри упорядочения cnum.
SELECT *
FROM Orders
ORDER BY cnum DESC, amt DESC;
ORDER BY может кроме того, использоваться с GROUP BY для упорядочения групп. Если это так, то ORDER BY всегда приходит последним. Вот - пример из последней главы с добавлением предложения ORDER BY. Перед группированием вывода, порядок групп был произвольным; и мы, теперь, заставим группы размещаться в последовательности:
SELECT snum, odate, MAX (amt)
FROM Orders
GROUP BY snum, odate
GROUP BY snum;
Так как мы не указывали на возрастание или убывание порядка, возрастание используется по умолчанию.
УПОРЯДОЧЕНИЕ ВЫВОДА ПО НОМЕРУ СТОЛБЦА
Вместо имен столбца, вы можете использовать их порядковые номера для указания поля используемого в упорядочении вывода. Эти номера могут ссылаться не на порядок столбцов в таблице, а на их порядок в выводе. Другими словами, поле упомянутое в предложении SELECT первым, для ORDER BY - это поле 1, независимо от того каким по порядку оно стоит в таблице. Например, вы можете использовать следующую команду чтобы увидеть определенные пол таблицы Продавцов, упорядоченными в порядке убывани к наименьшему значению комиссионных ( вывод показывается Рисунке 7.7 ):
SELECT sname, comm
FROM Salespeople
GROUP BY 2 DESC;
SELECT snum, COUNT ( DISTINCT onum )
FROM Orders
GROUP BY snum
ORDER BY 2 DESC;
В этом случае, вы должны использовать номер столбца, так как столбец вывода не имеет имени; и вы не должны использовать саму агрегатную функцию. Строго говор по правилам ANSI SQL, следующее не будет работать, хотя некоторые системы и пренебрегают этим требованием:
SELECT snum, COUNT ( DISTINCT onum )
FROM Orders
GROUP BY snum
GROUP BY COUNTОМ ( DISTINCT onum ) DESC;
Это будет отклонено большинством систем!
УПОРЯДОЧЕНИЕ С ПОМОЩЬЮ ОПЕРАТОРА NULL
Если имеются пустые значения (NULL) в поле которое вы используете для упорядочивания вашего вывода, они могут или следовать или предшествовать каждому другому значению в поле. Это - возможность которую ANSI оставил для индивидуальных программ. Данная программа использует ту или иную форму.
Для объединения запросов используется служебное слово UNION:
<запрос 1>
UNION [ALL]
<запрос 2>
Оператор UNION объединяет выходные строки каждого из запросов в один результирующий набор. Если определен параметр ALL, то сохраняются все дубликаты выходных строк, в противном случае в результирующем наборе остаются только уникальные строки. Заметим, что можно связывать вместе любое число запросов. Кроме того, с помощью скобок можно менять порядок объединения.
При этом должны выполняться следующие условия:
Количество выходных столбцов каждого из запросов должно быть одинаковым.
Выходные столбцы каждого из запросов должны быть сравнимыми между собой (в порядке их следования) по типам данных.
В результирующем наборе используются имена столбцов, заданные в первом запросе.
Предложение ORDER BY применяется к результату соединения, поэтому оно может быть указано только в конце составного запроса.