

Проекция
Операция проекции — унарный оператор, записываемый как πa1,…,an(R) где a1,…,an — список полей, подлежащих выборке. Результатом такой выборки будет набор последовательностей значений отношения R, в котором будут присутствовать только поля, перечисленные в списке a1,…,an с естественным уничтожением потенциально возникающих кортежей-дубликатов.
Пример
Пусть даны следующие соотношения:
Персоны
|
Имя |
Возраст |
Вес |
|
Harry |
34 |
80 |
|
Sally |
28 |
64 |
|
George |
29 |
70 |
|
Helena |
54 |
54 |
|
Peter |
34 |
80 |
Результат проекции:
πВозраст,Вес(Персоны)
|
Возраст |
Вес |
|
28 |
64 |
|
29 |
70 |
|
54 |
54 |
|
34 |
80 |
Эквивалентный SQL-запрос:
SELECT DISTINCT Возраст, Вес FROM Персоны
Примечательно, что в SQL для полного соответствия операции проекции необходимо указывать ключевое слово DISTINCT, поскольку без него строка с возрастом 34 и весом 80 отобразится дважды, что отличается от результата реляционной операции проекции.
Объединение

Результатом объединения отношений A и B будет отношение с тем же заголовком, что и у совместимых по типу отношений A и B, и телом, состоящим из кортежей, принадлежащих или A, или B, или обоим отношениям.
SQL-запрос:
SELECT Имя, Возраст, Вес FROM Персоны
UNION
SELECT Имя, Возраст, Вес FROM Персонажи
Пересечение
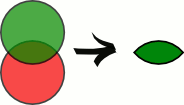
Результатом пересечения отношений A и B будет отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих одновременно обоим отношениям A и B.
SQL-запрос: (Объединение людей из двух разных таблиц)
SELECT Имя, Возраст, Вес FROM Персоны
INTERSECT
SELECT Имя, Возраст, Вес FROM Персонажи
Ключевое слово INTERSECT может отсутствовать в некоторых СУБД, однако оно включено в стандарт.
Разность
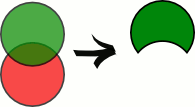
Результатом разности отношений A и B будет отношение с тем же заголовком, что и у совместимых по типу отношений A и B, и телом, состоящим из кортежей, принадлежащих отношению A и не принадлежащих отношению B.
SQL-запрос:
SELECT Имя, Возраст, Вес FROM Персоны
EXCEPT
SELECT Имя, Возраст, Вес FROM Персонажи
Произведение
При выполнении прямого произведения двух отношений производится отношение, кортежи которого являются конкатенацией (сцеплением) кортежей первого и второго операндов.
SQL-запрос:
SELECT * FROM Мультфильмы, Каналы
Деление
Реляционное деление достаточно нетривиально описать, но на примере его смысл нагляден. В целом, из таблицы A берутся значения строк, для которых присутствуют все комбинации значений из таблицы B. Понятно? Ну, примерно об этом я и пытался сказать, смотрим пример:
Соединение
Операция соединения есть результат последовательного применения операций декартового произведения и выборки. Если в отношениях и имеются атрибуты с одинаковыми наименованиями, то перед выполнением соединения такие атрибуты необходимо переименовать.
SQL-запрос:
SELECT * FROM Мультфильмы, Каналы WHERE Название_канала = Код_канала
Языки запросов. Понятие. Классификация.
Язы́к запро́сов — это искусственный язык, на котором делаются запросы к базам данных и другим информационным системам, особенно к информационно-поисковым системам.
Примеры:
SQL — де-факто стандартный язык запросов к реляционным базам данных.
Language Integrated Query — расширение для некоторых языков программирования в .NET Framework, добавляющее к ним SQL-подобный язык запросов.
XQuery — язык запросов, разработанный для обработки данных в формате XML.
XPath — язык запросов к элементам XML-документа.
(Из учебника Диго)
Первоначально под языками запросов понимали языки высокого уровня, ориентированные на конечного пользователя, предназначенные для формирования запросов к БД (в такой трактовке их можно считать одной из разновидностей ЯМД). Однако сейчас ЯЗ понимается шире – многие включают в себя еще и возможности описания данных и корректировки БД. В составе языков описания данных в зависимости от особенностей СУБД поддерживаются все или некоторые из следующих языков: язык описания схем (ЯОС), язык описания подсхем (ЯОПС), язык описания хранимых данных (ЯОХД), языки описания внешних данных (входных, выходных). В некоторых СУБД и сами эти разновидности языков, и создаваемые с их помощью элементы ИС являются самостоятельными компонентами, в других – некоторые из них могут объединены. Языки манипулирования данными разделяются на две большие группы: процедурные и непроцедурные. При пользовании процедурными языками надо указать, какие действия и над какими объектами необходимо выполнить, чтобы получить результат. В непроцедурных языках указывается, что надо получить в ответе, а не как этого достичь. Процедурные языки могут различаться по основным информационным единицам, которыми они манипулируют. Это могут быть языки, ориентированные на позаписную обработку данных, и языки, ориентированные на операции над множеством записей. Так, операции реляционной алгебры оперируют целиком отношением, а не каждой его записью. Примерами непроцедурных языков являются языки, основанные на реляционном исчислении: в частности, табличный язык QBE и язык запросов SQL (основан на реляционном исчислении кортежей).
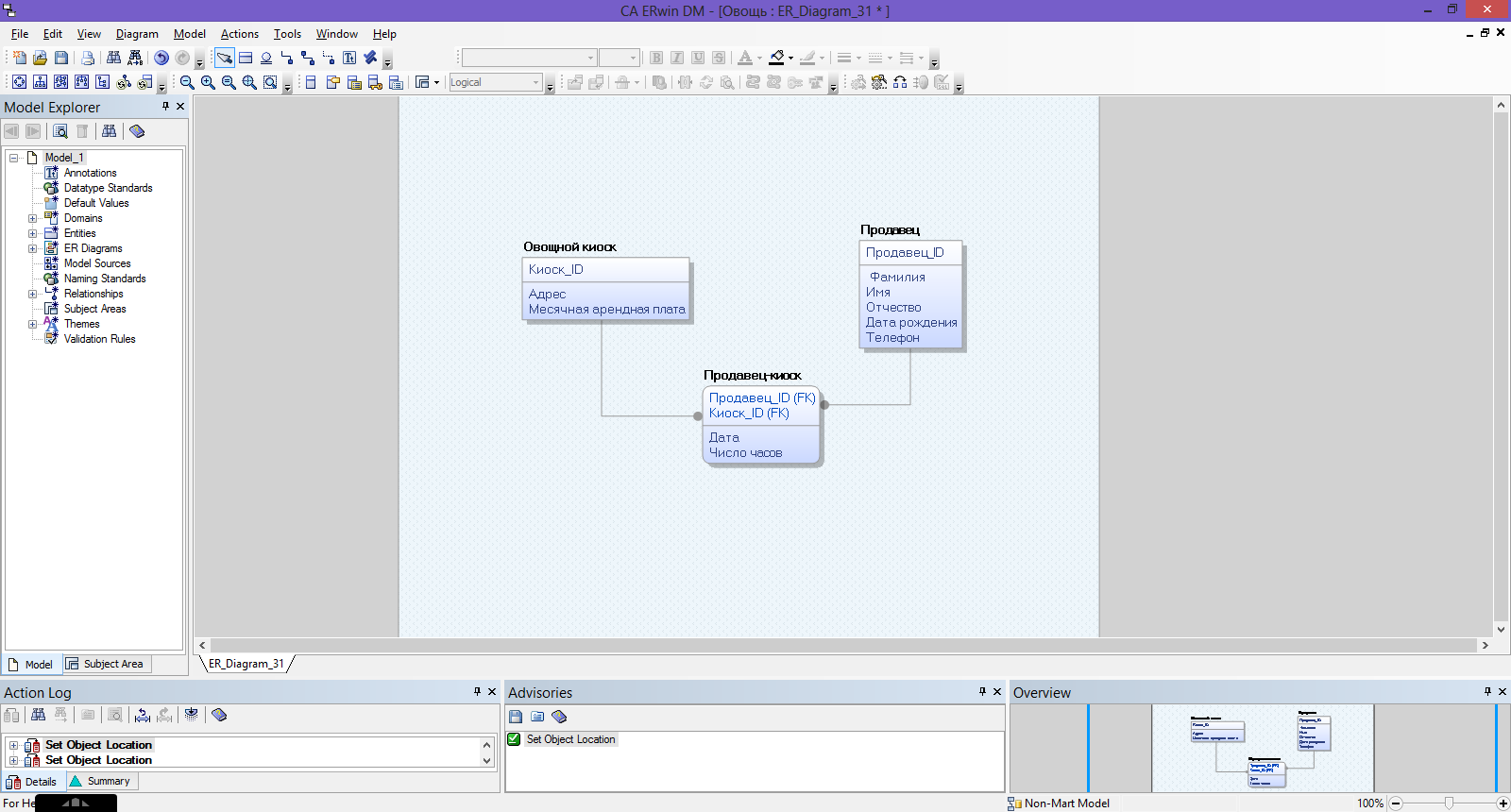
Построить ER-модель для следующей предметной области. Имеется овощной магазин с разветвленной сетью овощных киосков. По каждому киоску известен его адрес и месячная арендная плата. Продавцы жестко не закреплены за киосками. Ведется учет отработанного времени по каждому продавцу (ФИО, дата, киоск, число часов).
Билет №14
Вопросы:
Агрегированные и обобщенные объекты и их отображение в даталогической модели.
Обобщенный объект отражает наличие связи «род – вид» между объектами предметной области. Например, объекты СТУДЕНТ, ШКОЛЬНИК, АСПИРАНТ, УЧАЩИЙСЯ ТЕХНИКУМА образуют обобщенный объект УЧАЩИЙСЯ. Объекты, составляющие обобщенный объект, называются его категориями.
Агрегированные
объекты соответствуют обычно какому-либо
процессу, в который оказываются
«вовлеченными» другие объекты. Например,
агрегированный объект ПОСТАВКА объединяет
в себе объекты ПОСТАВЩИК, ПОТРЕБИТЕЛЬ,
а также саму поставляемую ПРОДУКЦИЮ.
Своеобразным объектом является
ДАТА_ПОСТАВКИ. Агрегированный объект
может, так же как и простой объект, иметь
характеризующие его свойства. В
рассматриваемом примере таким свойством
может быть РАЗМЕР_ПОСТАВКИ. Имя
агрегированного объекта обычно является
отглагольным существительным.
При отображении обобщенных объектов в БД возможны разные варианты: хранить информацию обо всем обобщенном объекте в одном файле/таблице; каждому подклассу объектов низшего уровня выделять отдельные самостоятельные файлы/таблицы. Оба эти варианта могут быть использованы в любой СУБД. В первом случае подчеркивается общность объектов разных подклассов, входящих в обобщенный объект. Во втором, напротив, обобщенный объект как единое целое не отображается в структуре базы данных. Другие способы отображения обобщенных объектов связаны с явным или неявным выделением подклассов в логической структуре БД. Неявное выделение подкласса заключается в том, что в записи отводятся поля для фиксации значений свойств, общих для объектов разных подклассов, и значения признака подкласса, а вместо полей, наличие которых зависит от подкласса, используется одно поле с переменным составом, содержание которого будет зависеть от того, к какому подклассу относится описываемый объект. Реализация принципа явного выделения подклассов в структуре БД существенно зависит от специфики СУБД.
Отображение агрегированных объектов
Каждому агрегированному объекту, имеющему место в предметной области, в реляционной модели будет соответствовать отдельное отношение. Атрибутами этого отношения будут являться идентификаторы всех объектов, «задействованных» в данном агрегированном объекте, а также реквизиты, соответствующие свойствам этого агрегированного объекта. Для отношений, соответствующих агрегированным объектам, ключ будет составной. В большинстве случаев им будет являться конкатенация (соединение) идентификаторов объектов, «участвующих» в этом агрегированном объекте.

Отображение обобщенных объектов
При отображении обобщенных объектов могут быть приняты разные решения. Во-первых, всему обобщенному объекту может быть поставлена в соответствие одна таблица базы данных (рис. 3.8б – вариант 1). В этом случае атрибутами этой таблицы будут идентификаторы обобщенного объекта, все единичные свойства, присущие объектам хотя бы одной категории, включая свойство, по которому производится разбиение на подклассы. Ключом таблицы будет один из идентификаторов этого объекта.
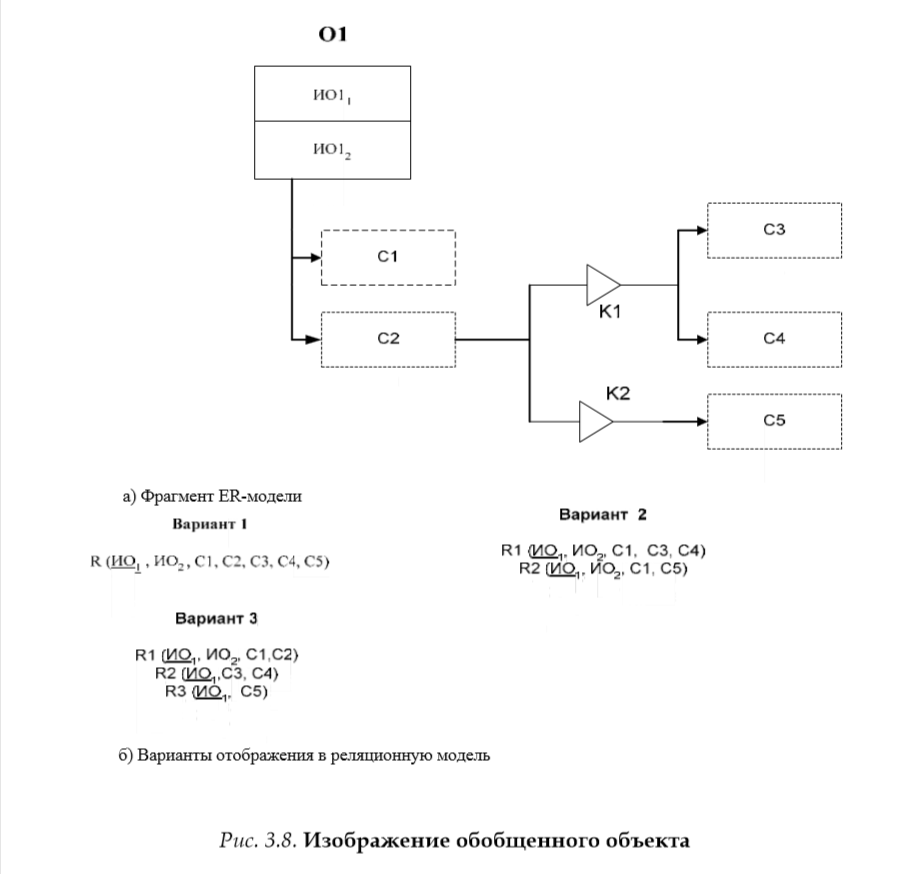
Другим «крайним» вариантом является решение, при котором каждой из категорий объектов нижнего уровня ставится в соответствие отдельное отношение (рис.3.8б – вариант 2). В этом случае каждое отношение будет включать в себя идентификатор объекта (если идентификаторов несколько, то в каждое из отношений будут включены все они; это не приведет к дублированию информации на уровне значений), свойства, присущие родовым объектам, а также свойства, присущие данному подвиду объектов. Свойство, по которому производится разбиение класса на подклассы, в этом случае в качестве поля не включается ни в одно из отношений. Кроме этих двух «крайних» решений возможны и комбинированные варианты. Например, можно выделить общую таблицу для отображения «родовых» свойств объектов (включающую еще и все идентификаторы объекта) и отдельные таблицы для отображения «видовых» свойств (такой алгоритм используется в системе Design/IDEF). Кроме свойств, присущих видовому объекту, в каждом из этих отношений будет повторен ключевой атрибут «основного» отношения (рис. 3.8б – вариант 3). Другим вариантом проектного решения для отображения обобщенного объекта является использование так называемого «кодированного формата файла», при котором, как и варианте 1, используется одна таблица, но для всех «видовых» свойств каждого из подклассов выделяется одно поле, содержимое которого распознается по значению свойства, по которому производится разбиение класса на подклассы.
SQL. Встроенный JOIN
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Входит в раздел FROM операторов SELECT, UPDATE или DELETE.
Операция соединения, как и другие бинарные операции, предназначена для обеспечения выборки данных из двух таблиц и включения этих данных в один результирующий набор. Отличительной особенностью операции соединения является следующее:
в схему таблицы-результата входят столбцы обеих исходных таблиц (таблиц-операндов), то есть схема результата является «сцеплением» схем операндов;
каждая строка таблицы-результата является «сцеплением» строки из одной таблицы-операнда со строкой второй таблицы-операнда.
Определение того, какие именно исходные строки войдут в результат и в каких сочетаниях, зависит от типа операции соединения и от явно заданного условия соединения. Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
При необходимости соединения не двух, а нескольких таблиц, операция соединения применяется несколько раз (последовательно).