Специальные виды множеств атд “Дерево двоичного поиска”
Дерево двоичного поиска - структура данных для представления множеств, чьи элементы упорядочены посредством некоторого отношения линейного порядка.
На деревьях двоичного поиска можно реализовать операторы множества
INSERT, DELETE, MEMBER, MIN,
причем время их выполнения в среднем имеет порядок O (log2 n) для множеств, состоящих из n элементов.
Характерным для дерева двоичного поиска является то, что его узлы помечены элементами множеств (узлы дерева содержат элементы множества).
Причем, все элементы, хранящиеся в узлах левого поддерева любого узла х, меньше элемента, содержащегося в узле х, а все элементы, хранящиеся в узлах правого поддерева узла х, больше элемента, содержащегося в узле х.
Примеры двоичного дерева:

Основные операции с двоичными деревьями поиска требуют времени O(h), где h – высота дерева.
Поэтому важно знать какова высота «типичного» дерева.
Для этого необходимо принять какие-то статистические предположения о распределении ключей и последовательности выполняемых операций.
В общем случае ситуация трудна для анализа, поэтому будем рассматривать лишь деревья, полученные добавлением вершин без удалений.
Случайным двоичным деревом поиска из n различных ключей называется дерево, получающееся из пустого дерева добавлением этих ключей в случайном порядке (все n! перестановок считаем равновероятными).
Это не означает, что все двоичные деревья равновероятны, так как разные порядки добавления могут приводить к одному и тому же дереву.
Утверждение: Мат. ожидание высоты случайного дерева из n ключей есть O(log2 n).
Для минимизации среднего пути поиска используются сбалансированные деревья двоичного поиска. АВЛ-дерево – это сбалансированное упорядоченное дерево двоичного поиска, у которого для каждого узла высоты его левого и правого поддеревьев отличаются не более, чем на единицу. Названы так в честь авторов Адельсона-Вельского и Ландиса.
Для АВЛ –дерева применяются специальные методы балансировки поддеревьев при вставке и удалении элементов множества. Для этого узлы АВЛ-дерева содержат дополнительный параметр – признак сбалансированности узла.
Пример АВЛ –дерева:

Представление АВЛ-дерева не отличается от представления двоичного дерева поиска.
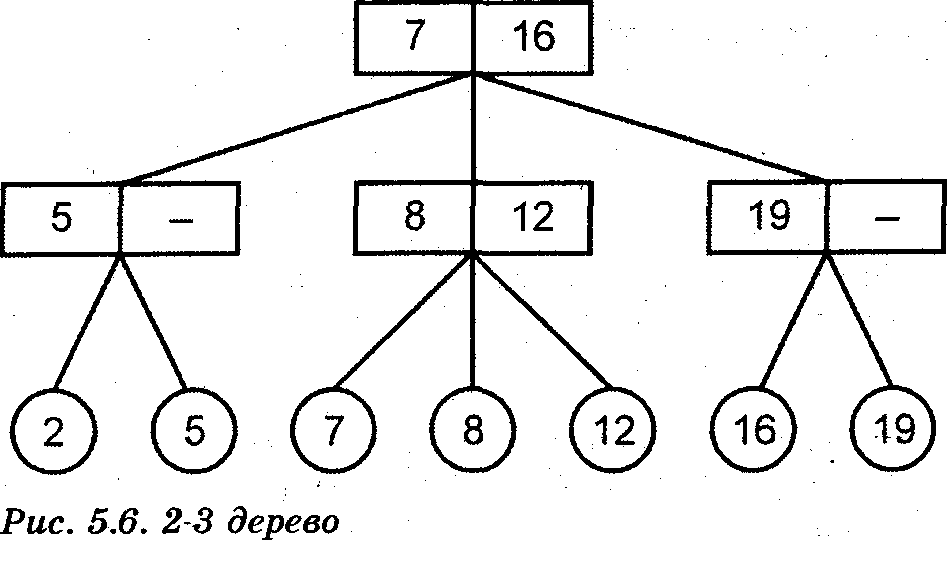
Другой разновидностью сбаланси-рованного дерева поиска является 2-3 дерево, структура которого отличается от структуры дерева двоичного поиска. Для 2-3 дерева характерно, что все узлы имеют 2 или 3 сына, все пути от корня до листа имеют одинаковую длину и все элементы множества содержатся в листьях.
Узлы 2-3 дерева делятся на внутренние и терминальные (листья). Внутренние узлы используются только для маршрутизации поиска в дереве. Каждый внутренний узел содержит ключи наименьших элементов второго и третьего сына (если есть третий сын) и указатели на узлы сыновей.
П редставление
связного дерева двоичного поиска:
редставление
связного дерева двоичного поиска:
Представление сбалансированного связного 2-3 дерева: