

Индексированные файлы
Еще одним распространенным способом организации файла записей является поддержание файла в отсортированном (по значениям ключей) порядке. В этом случае файл можно было бы просматривать как обычный словарь или телефонный справочник, когда мы просматриваем лишь заглавные слова или фамилии на каждой странице. Чтобы облегчить процедуру поиска, можно создать второй файл, называемый разреженным индексом, который состоит из пар (x ,b), где x – значение ключа, а b – физический адрес блока, в котором значение ключа первой записи равняется x. Этот разреженный индекс отсортирован по значениям ключей.
Линейный поиск годится лишь для небольших индексных файлов. Более эффективным методом является двоичный поиск. Допустим, что индексный файл хранится в блоках b1,b2,…,b(n/2)-1.Если x>=y , но x меньше, чем ключ блока b(n/2)-1, используется линейный поиск, чтобы проверить, совпадает ли x с первым компонентом индексной пары в блоке b(n/2). В противном случае повторяется поиск в блоках b(n/2)+1, b(n/2)+2,…, b(n). При использовании двоичного поиска нужно проверить лишь [Log2(n+1)] блоков индексного файла.
B-деревья
B-дерево – это особый вид сбалансированного m-арного дерева , который позволяет нам выполнять операции поиска, вставки и удаления записей из внешнего файла с гарантированной производительностью для самой неблагоприятной ситуации. Оно представляет собой обобщений 2-3 дерева. С формальной точки зрения B-дерево порядка m представляет собой m-арное дерево поиска, характеризующееся следующими свойствами.
-
Корень либо является листом, либо имеет по крайней мере двух сыновей.
-
Каждый узел, за исключением корня и листьев, имеет от [m/2] до m сыновей.
-
Все пути от корня до любого листа имеют одинаковую длину.
Обратитие внимание: каждое 2-3 дерево является B-деревом порядка 3, т.е.3-арным. На рис показано B-дерево порядка 5 , здесь предполагается, что в блоке листа умещается не более трех записей.
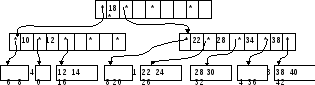
B-дерево можно рассматривать как иерархический индекс, каждый узел в котором занимает блок во внешней памяти. Корень B-дерева является индексом первого уровня. Каждый нелистовой узел на B-дереве имеет форму(p0,k1,p1,k2,…,kn,pn), где p(i) является указателем i-того сына,0 i n, а k1 ключ,1 i n. Ключи в узле упорядочены, поэтому k1<k2<…<kn. Все ключи в поддереве, на которое указывает p0, меньше, чем k1. В случае 1 i < n все ключи в поддереве, на которое указывает p1, имеют значения, не меньшие, чем k(i), и меньшие, чем k(i+1). Все ключи в поддереве, на которое указывает p(n), имеют значения, не меньшие, чем k(n).
Существуют несколько способов организации листьев. В данном случае мы предполагаем, что записи основного файла хранятся только в листьях. Предполагается также, что каждый лист занимает один блок.
Содержание
Алгоритмы. Основные определения 3
1. От задачи к программе 3
Типы данных, структуры данных 7
и абстрактные типы данных 7
Время выполнения программ 13
Глава I. Линейные абстрактные типы данных 31
АТД «Список» 31
АТД «Стек» 46
АТД «Очередь» 48
2. АТД «Дек» 53
НЕЛИНЕЙНЫЕ абстрактные типы данных 54
Деревья 54
Коды Хаффмана 69
Специальные виды множеств 73
Графы 83
Задача нахождения кратчайшего пути 91
Остовные деревья минимальной стоимости 94
3. Обход графов 98