

Свопинг и пейджинг
Страничное управление (Paging) является средством организации виртуальной памяти с подкачкой страниц по запросу (Demand-Paged Virtual Memory). В отличие от сегментации, которая организует программы и данные в модули различного размера, страничная организация оперирует с памятью, как с набором страниц одинакового размера. В момент обращения страница может присутствовать в физической оперативной памяти, а может быть выгруженной на внешнюю (дисковую) память. При обращении к выгруженной странице памяти процессор вырабатывает исключение #PF — отказ страницы, а программный обработчик исключения (часть ОС) получит необходимую информацию для свопинга — «подкачки» отсутствующей страницы с диска. Страницы не имеют прямой связи с логической структурой данных или программ. В то время как селекторы можно рассматривать как логические имена модулей кодов и данных, страницы представляют части этих модулей. Учитывая обычное свойство локальности (близкого расположения требуемых ячеек памяти) кода и ссылок на данные, в оперативной памяти в каждый момент времени следует хранить только небольшие области сегментов, необходимые активным задачам. Эту возможность (а следовательно, и увеличение допустимого числа одновременно выполняемых задач при ограниченном объеме оперативной памяти) как раз и обеспечивает страничное управление памятью. В первых 32-разрядных процессорах (начиная с i80386) размер страницы составлял 4 Кбайт. Начиная с Pentium, появилась возможность увеличения размера страницы до 4 Мбайт, одновременно с использованием страниц размером 4 Кбайт. В Р6 имеется возможность расширения физического адреса до 36 бит (64 Гбайт), при котором могут использоваться страницы размером 4 Кбайт и 2 Мбайт.
2. Стратегии подкачки страниц
В настоящее время все более относительно дорогим становится относительная стоимость времени, затрачиваемого программистом или вообще пользователем, по сравнению со стоимостью аппаратуры. Поэтому достаточно часто идут на увеличение объема ОП и применяют стратегию упреждающей подкачки, отказываясь от стратегии подкачки по запросу.
3. Стратегии размещения
Их цель состоит в определении того места ОП, в которое следует поместить поступающую страницу или сегмент. В системах со страничной организацией ОП эта проблема тривиальна, так как берется любая свободная страница.
Системы с сегментной организацией ОП требуют более сложных стратегий размещения, так как существует возможность выбора по объему участков свободной памяти и могут быть трудности типа так называемой фрагментации памяти. Суть ее состоит в том, что в ОП накапливается значительное число свободных, небольших по объему, участков, которые невозможно использовать для размещения вновь запрошенных сегментов, так как все эти сегменты больше по своему объему указанных свободных участков памяти. В итоге может оказаться, что существенная часть ОП окажется непригодной для использования без принятия специальных мер со стороны ОС по проведению дефрагментации ОП, однако процедура дефрагментации требует приостановки процесса обслуживания пользователей на некоторое время. Возможно, что именно по этой причине некоторые ОС не используют сегментную организацию памяти.
Большинство имеющихся в литературе данных, как теоретических, так и эмпирических, свидетельствуют о том, что в ЭВМ целесообразно выбирать страницы относительно небольшого размера. Например, в защищенном режиме работы ЭВМ с микропроцессором 80х86 при х > 2 используется размер страницы, равный 4 Кб.
Свопинг и пейджинг процессов
Ограниченный объем RAM в общем случае не позволяет разместить в ней множество образов существующих процессов. Поэтому образы пассивных процессов, для размещения которых нет места в RAM, располагаются в специально отведенной области внешней памяти, называемой областью свопинга. Образы активных процессов располагаются в RAM. Перекачку (свопинг) образов процессов между оперативной и внешней памятью обеспечивает диспетчерский процесс (планировщик свопинга) .swapper (или sched для SUN OS) с идентификатором 0. Он осуществляет загрузку в RAM образов активных процессов и выгрузку в область свопинга образов пассивных процессов.
Свопинг происходит при практической реализации механизмов синхронизации, диспетчеризации и управлении иерархией процессов. Например, когда недостаточно места для размещения в RAM образа порожденного процесса-потомка, образ его предка может быть выгружен (откачен) в область свопинга, чтобы освободить место под образ потомка. В другом случае образ “разбуженного” процесса с высоким приоритетом может быть загружен (подкачен) из области свопинга в RAM для реализации процессорной обработки. В более общем случае образ любого активизированного процесса может быть загружен (подкачен) из области свопинга в RAM при наличии необходимости и свободной памяти, так же как образ любого пассивного процесса может быть выгружен (откачен) из RAM в область свопинга, чтобы освободить ресурсы памяти для более приоритетного процесса.
Диспетчерский процесс swapper, реализуя механизм свопинга, должен решать две задачи по определению процессов-претендентов для откачки из и подкачки в RAM. Для решения этих задач диспетчерский процесс, не имея фазы “пользователь”, осуществляет бесконечный цикл в фазе “система”. Цикл начинается с просмотра таблицы процессов для поиска процесса-претендента на загрузку или расширение своего образа в RAM. Если претендентов нет, диспетчер переходит в состояние ожидания их появления, используя системную функцию sleep которая назначает ему наивысший приоритет PSWP после пробуждения. диспетчер “пробуждается” системной функцией wakeup при появлении претендента на загрузку в RAM.
Если в RAM недостаточно свободного места для подкачки образа процесса-претендента на загрузку, диспетчер выгружает (откачивает) в область свопинга необходимое число пассивных процессов. Кандидаты на откачку определяются, прежде всего, среди “спящих” процессов с низким приоритетом (ниже PZERO), которые ожидают завершения сравнительно медленных операций ввода-вывода. Если таких процессов несколько, выбирается процесс с максимальным образом в RAM.
Чтобы обеспечить однозначность выбора процесса для загрузки в RAM или для выгрузки в область свопинга при прочих равных условиях, применяется временной критерий оценки. С этой целью в поле p_time структуры struct proc дескриптора любого процесса фиксируется время непрерывного пребывания в RAM или в области свопинга соответственно тому, где находится образ процесса. для свопинга выбирается процесс с максимальным значением в поле p_time. В современных версиях OS UNIX применяется альтернативный свопингу механизм, который использует страничную организацию памяти и называется пейджинг (paging). Пейджинг реализует перемещение активных страниц образов процессов из области свопинга в RAM, называемое подкачкой страниц по требованию, а также обратное перемещение пассивных страниц из RAM в область свопинга, называемое изъятием страниц. Схема реализации пейджинга подобна свопингу, за исключением того, что перемещению между RAM и областью свопинга подвергается не целиком образ процесса, а его отдельные страницы. При этом в RAM должны присутствовать только активные страницы образа процесса, к которым происходит частое обращение. Пассивные страницы, к которым нет обращений, могут быть откачены в область свопинга. Таким образом, при пейджинге загрузка в RAM полного образа процесса не является обязательной. Последнее обстоятельство обуславливает ряд преимуществ пейджинговой схемы по сравнению с традиционным механизмом свопинга, из которых наиболее существенными являются следующие.
· Отсутствие ограничений на размер образа процесса по объему физической памяти. Связано с тем, что в RAM размещаются только активные страницы процесса, а не полные сегменты его образа.
· Ускоренный старт процесса. Становится возможным, поскольку загрузка сравнительно небольшого числа активных страниц может быть реализована быстрее, чем загрузка всех сегментов процесса.
· Экономия оперативной памяти. Поскольку для работы процесса необходима загрузка только активных страниц, память не расходуется на хранение редко используемых кодов и данных.
· Увеличение производительности. Становится ощутимым при параллельном выполнении больших процессов, которые часто обращаются к небольшому подмножеству своих активных страниц.
Недостатком схемы пейджинга являются накладные расходы по обработке так называемых отказов страниц, которые связаны с поиском нужной страницы, если она не загружена в RAM. Кроме того, обработка отказов страниц требует реализации операций ввода-вывода, прерывающих работу процессора для подкачки нужной страницы в RAM из области свопинга. Поэтому частые отказы страниц увеличивают время выполнения процесса. В идеальном случае процесс работает с небольшим числом активных страниц, резидентных в RAM, когда отказы страниц с последующей подкачкой нужных страниц по требованию происходят редко.
Для размещения страниц в RAM при подкачке их по требованию используется пул свободных страниц. Определенный уровень наличия свободных страниц поддерживает процедура изъятия страниц, которая откачивает содержимое пассивных страниц в область свопинга и возвращает изъятые страницы в пул свободных страниц. Сохранение содержимого изъятой страницы в области свопинга происходит, если содержание страницы было модифицировано. Процедуры подкачки страниц по требованию и изъятия страниц являются основными в механизме пейджинга. Их реализует следящий процесс pageout (pagedaemon в SUN OS), называемый демоном страниц. Так же как и диспетчерский процесс swapper, управляющий свопингом, демон страниц — это один из начальных процессов OS UNIX. Он имеет идентификатор 2. Демон страниц следит за возрастом страниц и определяет, какие пассивные страницы следует отобрать у процессов, чтобы вернуть их в пул свободных страниц. Он также обеспечивает подкачку страниц по требованию в случае отказов страниц. Демон страниц активизируется, когда начинает ощущаться недостаток свободной памяти или для обработки отказов страниц.
В общем случае демон страниц успешно решает все проблемы по управлению памятью с помощью своих базовых процедур подкачки по требованию и изъятия страниц. Однако могут возникнуть критические ситуации, когда демон страниц не может предоставить необходимое число свободных страниц для удовлетворения запросов процессов к RAM и уровень свободной памяти опустится ниже определенного предела, заданно го системным параметром GPGSLO. В этом случае инициатива передается диспетчерскому процессу, который планирует и реализует свопинг целых процессов. Свопинг подразумевает возвращение в пул свободных страниц всех страниц образа процесса независимо от их возраста. Реализация свопинга продолжается, пока не восстановлен допустимый уровень свободной памяти. После этого инициатива по управлению памятью возвращается демону страниц.
Прерывания.
События — прерывания и исключения
Прерывания (interrupt) и исключения (exception), обобщенно называемые событиями (event), нарушают нормальный ход выполнения программы для обработки внешних событий или сигнализации о возникновении особых условий или ошибок.
Прерывания и исключения
Прерывания и исключения нарушают нормальный ход выполнения программы для обработки внешних сообщений или сообщения о возникновении особых условий или ошибок. Прерывания делятся на:
аппаратные - маскируемые и немаскируемые;
вызываемые электрическими сигналами на входах микропроцессора;
программные выполняемые по команде INT.
Программные прерывания микропроцессором обрабатываются как разновидность исключений. Аппаратные прерывания микропроцессор может воспринимать после выполнения каждой команды. Длинные строковые команды имеют для восприятия прерываний специальные окна. Маскируемые прерывания вызываются переходом в высокий уровень сигнала на входе INTR при установленном флаге IF. В этом случае микропроцессор сохраняет в стеке регистр флагов, сбрасывает флаг IF и вырабатывает два следующих друг за другом цикла подтверждения прерывания, в которых генерируются управляющие сигналы INTA. Высокий уровень INTR должен сохраняться по крайней мере до подтверждения прерывания.
Первый цикл подтверждения холостой по второму импульсу внешний контроллер прерываний передает по шине номер вектора обслуживающего данный тип аппаратного прерывания. Прерывания с полученным номером вектора выполняются микропроцессором так же, как и программным. Обработка текущего прерывания может быть в свою очередь прервана немаскируемым прерыванием, а если обработчик установит флаг IF то и другим маскируемым аппаратным прерываниям.
Немаскируемые прерывания выполняются независимо от состояния флага IF по сигналу NMI. Высокий уровень на этом входе вызовет прерывание с вектором 2 который выполняется так же, как и маскируемые. Его обработка не может прерываться под действием сигнала на входе NMI до выполнения команды IRET.
Исключения делятся на отказы, ловушки и аварийные завершения.
Отказ - это исключение, которое обнаруживается и обслуживается до выполнения инструкции вызывающей ошибку. После обслуживания этого исключения управление возвращается на ту же инструкцию, включая все префиксы, которая вызвала отказ.
Ловушка - это исключение, которое обнаруживается и обслуживается после выполнения инструкции его вызывающей. После обслуживания этого исключения управление возвращается на инструкцию, следующую за вызвавшей ловушку. К классу ловушек относятся и программные прерывания.
Аварийное завершение - это исключение, которое не позволяет точно установить инструкцию его вызывающую. Оно используется для сообщения о серьезной ошибки такой как аппаратная ошибка или повреждение системных таблиц. Набор и обработка исключений реального и защищенного режимов различны. Под исключения зарезервированы векторы 0?31 в таблице прерываний. Однако в РС часть из них перекрывается системами прерываний BIOS и DOS. Процедура, обслуживающая прерывания и исключения определяется по таблице с помощью номера 8 битного указателя прерывания. Указатель для программных прерываний задается командой. Для маскируемых вводится от внешнего контроллера во втором цикле INTA. Немаскируемый имеет фиксированный вектор, а исключения генерируют и передают вектор внутри микропроцессора. Каждому номеру от 0 до 255 соответствует элемент в таблице дескрипторов прерываний, в реальном режиме таблица прерываний содержит двойные слова -дальние адреса обслуживающих процедур. И после сброса располагаются, начиная с нулевых адресов командой LIDT можно изменять ее положение в пределах первого Мбайта. А размер ее может быть уменьшен до 007F. При попытке обслуживания прерывания с номером, выходящим за заданные параметры таблицы, генерируется исключение типа 8. В защищенном режиме IDT содержит 8 байтные дескрипторы прерываний, может иметь размер от 32 до 256 дескрипторов и располагается в любом месте физической памяти. Анализ условия обслуживания прерываний и исключений выполняется в следующем порядке (по убыванию приоритета):
проверка на исключение (ловушка) отладки (типа 1) по выполненной инструкции (пошаговый режим через флаг TF или точка останова по данным через регистр отладки);
проверка на исключение (отказ) отладки (типа 1) по следующей инструкции (точа останова по инструкции через регистр отладки);
немаскируемые прерывания;
маскируемые прерывания;
проверка на исключения (отказ) сегментации (типа 11 или 13) при выборе следующей инструкции;
проверка на исключение (отказ) страницы (типа 14) при выборке следующей инструкции;
проверка на отказ (декодирование) следующей инструкции (типа 6 или 13);
для операции WAIT проверка TS и MP (исключение 7, если они в единице);
для операции ESCAPE (к математическому сопроцессору) проверка EM и TS (исключение 7, если они в единице);
для операции WAIT или ESCAPE проверка на исключение 16 от сопроцессора;
проверка на отказ сегментации (исключения 11, 12, 13) и страницы (исключения 14) для операндов используемых в инструкции.
Двойной отказ - это исключение 8 возникает, когда при обработке исключения связанного с сегментацией (типа 10?13) микропроцессор обнаруживает исключения отличные от отказа страницы (типа 14). Также двойной отказ возникает, если при отработке исключения отказа страницы (типа 14) обнаруживается исключения другого типа, в этом случае тоже выполняется исключение 8. Если во время обслуживания исключения отказа страницы произойдет еще один отказ страницы, то происходит отключение микропроцессора. Во время отключения никакие новые инструкции не выполняются. Из этого состояния микропроцессор можно вывести только аппаратным сигналом NMI, оставляя его в защищенном режиме или сигналом RESET переводящим процессор в реальный режим. При отработке исключений в защищенном режиме микропроцессор сохраняет в стеке слово, когда ошибки, если оно отлично от нуля то оно содержит селектор дескриптора, с которым связана ошибка.
Для обработки аппаратных прерываний в многопроцессорных системах традиционные аппаратные средства становятся непригрдными, поскольку прежняя схема подачи запроса INTR и передачи вектора в цикле INTA# явно ориентирована на единственность процессора. Для решения этой задачи в процессоры, начиная со второго поколения Pentium, введен усовершенствованный программируемый контроллер прерываний (Advanced Programmable Interruption Controller, APIC). Этот контроллер имеет внешние сигналы локальных прерываний LINT[1:0] и интерфейсную шину, по трем проводам которой (PICD[1:0] и PICCLK) процессоры связываются с контроллером API С системной платы. Для локальных запросов прерываний процессоры имеют линии UNTO, LINT1. Локальные прерывания обслуживаются только тем процессором, на выводы которого поступают сигналы их запросов. Общие (разделяемые) прерывания (в том числе и SMI) приходят к процессорам в виде сообщений по интерфейсу APIC. При этом контроллеры предварительно программируются — тем самым определяются функции каждого из процессоров в случае возникновения того или иного аппаратного прерывания. Контроллеры APIC каждого из процессоров и контроллер системной платы, связанные интерфейсом APIC, выполняют маршрутизацию прерываний (interrupt routing), причем как статическую, так и динамическую. Внешне программный интерфейс обработки прерываний остается совместимым с управлением контроллером 8259А, что обеспечивает прозрачность присутствия APIC для прикладного программного обеспечения. Режим обработки прерываний посредством APIC разрешается сигналом APICEN по аппаратному сбросу, впоследствии он может быть запрещен программно.
……………………………
Механизм прерываний
Процессор Pentium поддерживает векторную схему прерываний, с помощью которой может быть вызвано 256 процедур обработки прерываний (вектор имеет длину в один байт). Соответственно таблица процедур обработки прерываний имеет 256 элементов, которые в реальном режиме работы процессора состоят из дальних адресов (CS:IP) этих процедур, а в защищенном режиме — из дескрипторов. Контроллер прерываний в большинстве аппаратных платформ на основе процессоров Pentium реализует механизм опрашиваемых прерываний, поэтому общий механизм компьютера носит смешанный векторнб-опрашиваемый характер.
Прерывания, которые обрабатывает Pentium, делятся на следующие классы:
аппаратные (внешние) прерывания — источником таких прерываний является сигнал на входе процессора;
исключения — внутренние прерывания процессора;
программные прерывания, происходящие по команде INT.
Аппаратные прерывания бывают маскируемыми и немаскируемыми. Маскируемые прерывания вызываются сигналом INTR на одном из входов микросхемы процессора. При его возникновении процессор завершает выполнение очередной инструкции, сохраняет в стеке значение регистра признаков программы EFLAGS и адреса возврата, а затем считывает с входов шины данных байт вектора прерываний и в соответствии с его значением передает управление одной из 256 процедур обработки прерываний.
Маскируемость прерываний управляется флагом разрешения прерываний IF (Interrupt Flag), находящимся в регистре EFLAGS процессора. При IF=1 маскируемые прерывания разрешены, а при IF=0 — запрещены. Для явного управления флагом IF в процессоре имеются чувствительные к уровню привилегий инструкции разрешения маскируемых прерываний STI (SeT Interrupt flag) и запрета маскируемых прерываний CLI (CLear Interrupt flag). Эти инструкции разрешается выполнять при CPL<IOPL. Кроме того, состояние флага изменяется неявным образом в некоторых ситуациях, например он сбрасывается процессором при распознавании сигнала INTR, чтобы процессор не входил во вложенные циклы процедуры обработки одного и того же прерывания. Процедура обработки прерывания завершается инструкцией IRET, по которой происходит извлечение из стека признаков EFLAGS, адреса возврата, установка флага разрешения прерываний IF и передача управления по адресу возврата. Для маскируемых прерываний в процессоре отведены процедуры обработки прерываний с номерами 32-255. Соответствие между сигналом запроса прерывания на шине ввода-вывода (например, сигналом IRQn на шине PCI) и значением вектора задается внешним по отношению к процессору блоком компьютера — контроллером прерываний. Немаскируемое аппаратное прерывание происходит при появлении сигнала NMI (Non Maskable Interrupt) на входе процессора. Этот сигнал всегда прерывает работу процессора, вне зависимости от значения флага IF. При обработке немаскируемого прерывания вектор не считывается, а управление всегда передается процедуре с номером 2, описываемой третьим элементом таблицы процедур обработки прерываний (нумерация в этой таблице начинается с нуля). Немаскируемые прерывания предназначаются для реакции на «сверхважные» для компьютерной системы события, например сбой по питанию. В ходе процедуры обслуживания немаскируемого прерывания процессор не реагирует на другие запросы немаскируемых и маскируемых прерываний до тех пор, пока не будет выполнена команда IRET. Если при обработке немаскируемого прерывания возникает новый сигнал NMI, то он фиксируется и обрабатывается после завершения обработки текущего прерывания, то есть после выполнения команды IRET.
Исключения (exeprtions) делятся в процессоре Pentium на отказы (faults), ловушки (traps) и аварийные завершения (aborts).
Отказы соответствуют некорректным ситуациям, которые выявляются до выполнения инструкции, например, при обращении по адресу, находящемуся в отсутствующей в оперативной памяти странице (страничный отказ). После обработки исключения-отказа процессор повторяет выполнения команды, которую он не смог выполнить из-за отказа. Ловушки обрабатываются процессором после выполнения инструкции, например при возникновении переполнения. После обработки процессор выполняет инструкцию, следующую за той, которая вызвала исключение. Аварийные завершения соответствуют ситуациям, когда невозможно точно определить команду, вызвавшую прерывание. Чаще всего это происходит во время серьезных отказов, связанных со сбоями в работе аппаратуры компьютера. Для обработки исключений в таблице прерываний отводятся номера 0-31.
Программные прерывания в процессоре Pentium происходят при выполнении инструкции INT с однобайтовым аргументом, в котором указывается вектор прерывания. Общая длина инструкции INT — два байта, исключение составляет инструкция INT 3, которая целиком помещается в один байт — это удобно при отладке программ, когда инструкция INT заменяет первый байт любой команды, вызывая переход на процедуру отладки. Программные прерывания подобно ловушкам обрабатываются после выполнения соответствующей инструкции INT, а возврат происходит в следующую инструкцию. Программное прерывание может вызвать любую из 256 процедур обработки прерываний, указанных в таблице прерываний.
При одновременном возникновении запросов прерываний различных типов процессор Pentium разрешает коллизию с помощью приоритетов. Немаскируемые прерывания имеют более высокий приоритет, чем маскируемые. Приоритетность внутри маскируемых прерываний устанавливается не процессором, а контроллером прерываний (процессор не может этого сделать, так как для него все маскируемые запросы представлены одним сигналом INTR). Проверка некорректных ситуаций, порождающих исключения (в том числе и при выполнении одной команды), выполняется в процессоре в соответствии с определенной последовательностью.
Таблица прерываний в реальном режиме состоит из 256 элементов, каждый из которых имеет длину в 4 байта и представляет собой дальний адрес (CS:IP) процедуры обработки прерываний. Таблица прерываний реального режима всегда находится в фиксированном месте физической памяти — с начального адреса 00000 по адрес 003FF.
В защищенном режиме таблица прерываний носит название IDT (Interrupt Descriptor Table) и может располагаться в любом месте физической памяти. Ее начало (32-разрядный физический адрес) и размер (16 бит) можно найти в регистре системных адресов IDTR. Каждый из 256 элементов таблицы прерываний представляет собой 8-байтный дескриптор. В таблице прерываний могут находиться только дескрипторы определенного типа — дескрипторы шлюзов прерываний, шлюзов ловушек и шлюзов задач.
Шлюзы задач уже рассматривались выше, они используются всегда для переключения с задачи на задачу. Шлюзы прерываний и ловушек специально вводятся для вызова процедур обработки прерываний. Если для вызова процедуры обработки прерывания используется шлюз задач, то происходит смена процесса, а по завершении обработки — возврат к прерванному процессу. Обычно обслуживание прерываний со сменой процесса (и запоминанием его контекста) применяется для внешних прерываний, которые не связаны с текущим процессом, например, когда принтер с помощью прерывания требует загрузить в его буфер новую порцию распечатываемых данных приостановленного процесса.
Шлюзы прерываний и ловушек не вызывают смены контекста задачи, следовательно, процедуры обработки прерываний в этом случае вызываются быстрее, чем при использовании шлюза задачи. Формат дескриптора шлюза прерывания и ловушки аналогичен формату дескриптора шлюза вызова, и обработка процессором этих шлюзов во многом аналогична вызову процедуры через шлюз вызова. Отличие состоит в том, что при вызове процедуры через шлюз прерываний сбрасывается флаг IF и тем самым запрещаются вложенные прерывания. При использовании шлюза ловушки сброса флага IF не происходит, но в стек при некоторых видах исключений дополнительно помещается код ошибки, вызвавшей исключение.
Итак, процессор Pentium предоставляет операционной системе широкий диапазон возможностей для организации обработки прерываний различного типа.
…………………………….
Архитектура памяти x86
В x86-архитектуре память разделяется на три типа адресов:
Логический адрес - адрес расположения ячейки памяти, который может быть (а может и нет) связан непосредственно с физическим расположением. Логический адрес обычно используется при запросе информации из контроллера.
Линейный адрес (или линейное адресное пространство ) - это память, адресация которой начинается с 0. Каждый следующий байт адресуется следующим последовательным номером (0, 1, 2, 3 и т.д.) до конца памяти. Так адресуют память большинство CPU не Intel-архитектуры. В Intel®-архитектурах используется сегментированное адресное пространство, в котором память разделяется на сегменты размером 64KB, а сегментный регистр всегда указывает на базовый адрес адресуемого сегмента. 32-битный режим в этой архитектуре рассматривается как линейное адресное пространство, но в нем тоже используются сегменты.
Физический адрес - адрес, представленный битами физической адресной шины. Физический адрес может отличаться от логического; в этом случае модуль управления памятью транслирует логический адрес в физический.
CPU использует два модуля для преобразования логического адреса в его физический эквивалент. Первый называется модулем сегментации (segmented unit), а второй - модулем разделения на страницы (paging unit).
Рисунок 1. Два модуля преобразуют адресное пространство

……………………………………………..
Стек — это специальным образом организованный участок памяти, используемый для временного хранения переменных, для передачи параметров вызываемым подпрограммам и для сохранения адреса возврата при вызове процедур и прерываний. Легче всего представить стек в виде стопки листов бумаги (это одно из значений слова «stack» в английском языке) — вы можете класть и забирать листы бумаги только с вершины стопки. Таким образом, если записать в стек числа 1, 2, 3, то при чтении они будут получаться в обратном порядке — 3, 2, 1. Стек располагается в сегменте памяти, описываемом регистром SS, а текущее смещение вершины стека записано в регистре ESP, причем при записи в стек значение этого смещения уменьшается, то есть стек растет вниз от максимально возможного адреса (рис. 4). Такое расположение стека «вверх ногами» может быть необходимо, например в бессегментной модели памяти, когда все сегменты, включая сегмент стека и сегмент кода, занимают одну и ту же область — всю память. Тогда программа исполняется в нижней области памяти, в области малых адресов, и EIP растет, а стек располагается в верхней области памяти, и ESP уменьшается.
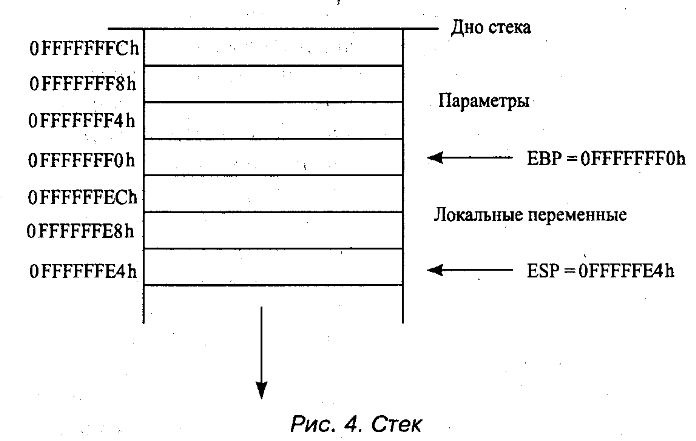
При вызове подпрограммы параметры в большинстве случаев помещают в стек, а в EBP записывают текущее значение ESP. Тогда, если подпрограмма использует стек для хранения локальных переменных, ESP изменится, но EBP можно будет использовать для того, чтобы считывать значения параметров напрямую из стека (их смещения будут записываться как EBP + номер параметра). Более подробно вызовы подпрограмм и все возможные способы передачи параметров рассмотрены в главе 4.3.2.
Стек
Стек представляет собой непрерывную область памяти, адресуемую регистрами ESP (указатель стека) и SS (селектор сегмента стека). Особенность стека заключается в том, что данные в него помещаются и из него извлекаются по принципу «первым вошел — последним вышел». Данные помещаются в стек с помощью инструкции PUSH (заталкивание), а извлекаются по инструкции POP (вытаскивание). Помимо явного доступа к стеку с помощью инструкций PUSH и POP стек автоматически используется процессором при выполнении инструкций вызова, возвратов, входа и выхода из процедур, а также при обработке прерываний.
Стек используют для разных целей:
организации прерываний, вызовов и возвратов;
временного хранения данных, когда под них нет смысла выделять фиксированные места в памяти;
передачи и возвращения параметров при вызовах процедур.
До использования стека он должен быть инициализирован так, чтобы регистры SS: ESP указывали на область реальной оперативной памяти (стек в ПЗУ, естественно, работать не может). Прикладные программы получают, как правило, от операционной системы готовый к употреблению стек. В защищенном режиме сегмент состояния задачи содержит четыре селектора сегментов стека (для раз&ных уровней привилегий), но в каждый момент задействуется, естественно, только один стек. Если для стека определен слишком маленький сегмент, то возможно переполнение стека (stack overflow). Переполнение в ОС защищенного режима вызывает срабатывание защиты, в ОС реального режима приводит к «загадочным» вылетам и зависаниям. Переполнение может происходить при интенсивных прерываниях, когда до завершения обработки одного прерывания возникает и обрабатывается другое, более приоритетное (вложенные прерывания).