Компонентно-ориентированная модель
Программные компоненты, созданные в реализованных программных проектах, хранятся в библиотеке. В новом программном проекте, исходя из требований заказчика, выявляются кандидаты в компоненты. Далее проверяется наличие этих кандидатов в библиотеке. Если они найдены, то компоненты извлекаются из библиотеки и используются повторно. В противном случае создаются новые компоненты, они применяются в проекте и включаются в библиотеку.
Достоинства компонентно-ориентированной модели:
1) уменьшает на 30% время разработки программного продукта;
2) уменьшает стоимость программной разработки до 70%;
3) увеличивает в полтора раза производительность разработки.
2. Стратегии конструирования ПО: ХР-процесс
Процесс ориентирован на достаточно небольшие группы (не больше 10 человек). Применяется, когда требования меняются очень часто.
Четырьмя базовыми действиями в процессе являются:
1. Кодирование
2. Тестирование
3. Выслушивание заказчика
4. Проектирование
Базис XP образует следующие 12 методов:
1. Игра планирования – быстрое определение области действия следующей реализации путем объединения деловых приоритетов и технических оценок
2. Частая смена действий – подразумевает быстрый запуск производства простой системы
3. Метафора – вся разработка осуществляется на основе простой общедоступной истории, как работает вся система. Обеспечивает «видение проекта»
4. Простое проектирование – в процессе применяются самые простые решения, которые необходимы только на данном этапе проектирования
5. Тестирование. Осуществляется непрерывно. Прежде запуска проектируют тесты. Функциональное тестирование (черный ящик)
6. Реорганизация – система постоянно реструктурируется, но ее поведение не изменяется
7. Парное программирование. Является одним из наиболее спорных (увеличение расходов на персонал, но увеличение проектирования).
8. Коллективное владение кодом. Любой разработчик может улучшать любую часть кода в любое время.
9. Непрерывная интеграция. Система интегрируется и строится много раз в день по мере решения каждой задачи.
10. 40-часовая рабочая неделя.
11. Локальный заказчик. В группе постоянно должен находиться представитель заказчика.
12. Стандарты кодирования. При разработке должны обеспечиваться правила, обеспечивающие одинаковое представление кода во всех частях системы.
3. Тяжеловесные и облегченные процессы.
Традиционно для упорядочения и ускорения программных разработок предлагались строго упорядочивающие тяжеловесные (heavyweight) процессы. В этих процессах прогнозируется весь объем предстоящих работ, поэтому они называются прогнозирующими (predictive) процессами. Порядок, который должен выполнять при этом человек-разработчик, чрезвычайно строг — «шаг вправо, шаг влево — виртуальный расстрел!». Иными словами, человеческие слабости в расчет не принимаются, а объем необходимой документации способен отнять покой и сон у «совестливого» разработчика.
В последние годы появилась группа новых, облегченных (lightweight) процессов [29]. Теперь их называют подвижными (agile) процессами [8], [25], [36]. Они привлекательны отсутствием бюрократизма, характерного для тяжеловесных (прогнозирующих) процессов. Новые процессы должны воплотить в жизнь разумный компромисс между слишком строгой дисциплиной и полным ее отсутствием. Иначе говоря, порядка в них достаточно для того, чтобы получить разумную отдачу от разработчиков.
Подвижные процессы требуют меньшего объема документации и ориентированы на человека. В них явно указано на необходимость использования природных качеств человеческой натуры (а не на применение действий, направленных наперекор этим качествам).
Более того, подвижные процессы учитывают особенности современного заказчика, а именно частые изменения его требований к программному продукту. Известно, что для прогнозирующих процессов частые изменения требований подобны смерти. В отличие от них, подвижные процессы адаптируют изменения требований и даже выигрывают от этого. Словом, подвижные процессы имеют адаптивную природу.
Таким образом, в современной инфраструктуре программной инженерии существуют два семейства процессов разработки:
семейство прогнозирующих (тяжеловесных) процессов;
семейство адаптивных (подвижных, облегченных) процессов.
У каждого семейства есть свои достоинства, недостатки и область применения:
адаптивный процесс используют при частых изменениях требований, малочисленной группе высококвалифицированных разработчиков и грамотном заказчике, который согласен участвовать в разработке;
прогнозирующий процесс применяют при фиксированных требованиях и многочисленной группе разработчиков разной квалификации.
4. Модели качества процесса проектирования.
Базовым является модель зрелости процесса конструирования. Базовым понятием модели (СММ) является зрелость компании. Модель фиксирует критерий для оценки зрелости компании и предлагает рецепты для улучшения существующих в ней процессов.
В модели зафиксированы 5 уровней зрелости:
1. начальный уровень – означает, что процесс в компании не формализован, он не может строго планироваться и отслеживаться. Результат работы зависит от личных качеств отдельных сотрудников. Для перехода на 2-й уровень необходимо внедрить формальные процедуры, для выполнения основных элементов процесса конструирования.
2. повторяемый уровень;
3. определённый уровень – требует, чтобы все элементы процесса были определены, стандартизованы и за документированы;
4. управляемый уровень – наступает, когда в компании принимаются количественные показатели качества, как программных продуктов, так и процесса;
5. оптимизирующий уровень – подразумевает, что главной задачей компании становится улучшение существующих процессов и ввод новых технологий.
5. Управление риском.
Формула управления риском RE = P (UO) * L (UO), где
RE – показатель риска;
P – вероятность неудовлетворительного результата;
L – потеря при неудовлетворительном результате;
UO – Unsatisfactory Outcome.
Управление риском включает 6 действий:
1. идентификация риска – выявление элементов риска на проект;
анализ риска – включает в себя оценку вероятности и величины потери по каждому элементу риска.
3. ранжирование риска – упорядочивание элементов риска по степени их влияния;
4. планирование управления риском – подготовка к работе с каждым элементом риска;
5. разрешение риска;
6. наблюдение риска.
Идентификация риска
Выделяют 3 категории источников риска, а именно: проектный риск, технический риск, коммерческий риск.
Источниками проектного риска являются:
1. выбор бюджета, плана, человеческих ресурсов;
2. формирование требований к программному продукту;
3. сложность, размер и структура программного продукта;
4. методика взаимодействия с заказчиком.
К источникам технического риска относят:
1. трудности проектирования, реализации, формирование интерфейса, тестирование и сопровождение;
2. неточность спецификаций;
3. техническая неопределённость или отсталость технического решения.
Источники коммерческого риска:
1. создание продукта, не требующееся на рынке;
2. создание продукта, опережающего требования рынка;
3. потеря финансирования.
Планирование управления риском
Цель планирования – сформировать набор функций управления к каждому элементу риска.
Обычно выбирают 3 эталонных уровня риска:
1. превышение стоимости;
2. срыв планирования;
3. упадок производительности.
Шаги планирования:
исходными данными для планирования является набор четвёрок {Ri, Pi, Li, REi};
определяются эталонные уровни рисков в проекте;
разрабатываются зависимости между каждой четвёркой и каждым эталонным уровнем;
формируется набор эталонных точек, образующих сферу остановок;
для каждого элемента риска разрабатывается план управления. Предложения плана разрабатывается в виде ответов на вопросы: зачем, что, когда, какие, как и сколько.
6. Структурный анализ: основные определения, ПДД
Структурный анализ — один из формализованных методов анализа требований к ПО. Автор этого метода — Том Де Марко (1979). В этом методе программное изделие рассматривается как преобразователь информационного потока данных. Основной элемент структурного анализа — диаграмма потоков данных.
Диаграммы потоков данных – графическое средство для изображения информационного потока и преобразований, которым подвергаются данные при движении от входа к выходу системы.
Основные элементы:

Для полного описания требований к программному изделию должны быть описаны стрелки (потоки данных) и преобразователи (процессы). Для чего используется словарь требований данных и спецификации процессов.
Словарь требований содержит описание потоков данных и хранилищ данных. Большинство словарей содержат следующую информацию:
Имя – основное имя элемента данных, хранилища или внешнего объекта.
Алиас (прозвище) – другие имена того же объекта
Где и как используется объект, т.е. список процессов, который использует данный элемент, с указанием способа использования.
Описание содержания.
Дополнительная информация.
Спецификация процесса – описание преобразователя, она поясняет ввод данных в преобразователь, алгоритм обработки, характеристики производительности преобразователя и формируемые результаты.

В структурный анализ были введены диаграммы управляющих потоков. Они включают в себя:
1. обычные преобразователи;
2. потоки управления и потоки событий.
Вместо управляющих преобразователей используются указатели, ссылки на управляющую спецификацию.
Управляющая спецификация управляет преобразователями в ПДД на основе события, которое проходит в её окно по ссылке.

7. Классические методы проектирования: проектирование для потока данных типа «преобразование»
Исходными данными для метода являются компоненты модели анализа, которые представляются иерархией диаграмм потоков данных. Результат структурного проектирования – иерархическая структура программной системы. Действия структурного проектирования зависят от типа информационного потока в модели анализа. Различают 2 типа информационных потоков: поток преобразований и поток запросов.
Проектирование для потока данных типа «преобразований».
проверка основной системы модели. Модель включает в себя: контекстную диаграмму ПДДО словарь данных и спецификацию процессов. Оценивается их согласованность с их спецификацией.
проверка уточнения диаграмм потоков данных 1 и 2 уровней. Оценивается согласованность диаграмм и достаточность реализации преобразователей.
определение типа основного потока диаграмм потоков данных.
определение границ входящего и выходящего потоков, определение центра преобразований.
определение начальной структуры системы: иерархическая структура формируется нисходящим распространением управления. В такой структуре модули верхнего уровня принимают решение, модули нижнего уровня выполняют работу по вводу, выводу и обработке. Модули среднего уровня реализуются как функции управления, так и функции обработки.
Детализация структуры программируемой системы. Выполняется отображение преобразователей диаграмм потока данных в модули структуры ПС. Отображения выполняются движением по ПДД от границ центра преобразования вдоль входящего и выходящего потоков. Входящий поток проходится от конца к началу, а выходящий от начала к концу.
Для отображения центра преобразований каждый преобразователь отображается в модель, непосредственно подчиненный контроллеру центра. Проходится преобразуемый поток слева направо. Для каждого модуля полученной структуры на базе спецификации процессов модели анализа пишутся сокращенные описания обработки.
7. Уточнение иерархической структуры ПС. Модули разделяются и объединяются для:
- повышения связности и уменьшения сцепления
- упрощения реализации
- упрощения тестирования
- повышения удобства сопровождения
8. Классические методы проектирования: проектирование для потока данных типа «запрос»
1. Проверка основной системы модели. Модель включает в себя: контекстную диаграмму ПДДО словарь данных и спецификацию процессов. Оценивается их согласованность с их спецификацией.
2. проверка уточнения диаграмм потоков запросов 1 и 2 уровней. Оценивается согласованность диаграмм и достаточность реализации преобразователей.
3. определение типа основного потока диаграмм потоков запросов. Основной признак потока запросов явное переключение данных на один из путей действий.
4. определение центра запросов и типа для каждого потока действий. Если конкретный поток действий имеет тип преобразование, то для него указываются границы входящего, преобразуемого и выходящего потоков.
5. Определение начальной структуры ПС. В начальную структуру отображается та часть ПДД, в которой распространяется поток запросов. Начальная структура ПС для потока запросов стандарта и включает входящую ветвь и диспетчерскую ветвь. Структура входящей ветви формируется также, как в предыдущей методике. Диспетчерская ветвь включает диспетчер, находится на вершине ветви и контроллер потоков действий подчинены диспетчеру.
6. Детализация структуры ПС – производится отображение в структуру каждого потока действий.
7. Уточнение иерархической структуры (см. предыдущую методику)
9. Характеристики сложности иерархической структуры ПС.
Иерархическая структура программной системы — основной результат предварительного проектирования. Она определяет состав модулей ПС и управляющие отношения между модулями. В этой структуре модуль более высокого уровня (начальник) управляет модулем нижнего уровня (подчиненным).
Иерархическая структура не отражает процедурные особенности программной системы, то есть последовательность операций, их повторение, ветвления и т. д. Рассмотрим основные характеристики иерархической структуры, представленной на рис. 4.17.
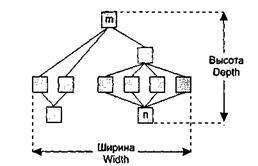
Иерархическая структура программной системы
Первичными характеристиками являются количество вершин (модулей) и количество ребер (связей между модулями). К ним добавляются две глобальные характеристики — высота и ширина:
высота — количество уровней управления;
ширина — максимальное из количеств модулей, размещенных на уровнях управления.
В нашем примере высота = 4, ширина = 6.
Локальными характеристиками модулей структуры являются коэффициент объединения по входу и коэффициент разветвления по выходу.
Коэффициент объединения по входу Fan_in(i) — это количество модулей, которые прямо управляют i-м модулем.
В примере для модуля n: Fan_in(n)=4.
Коэффициент разветвления по выходу Fan_out(i) — это количество модулей, которыми прямо управляет i-й модуль.
В примере для модуля m: Fan_out(m)=3.
Возникает вопрос: как оценить качество структуры? Из практики проектирования известно, что лучшее решение обеспечивается иерархической структурой в виде дерева.
Степень отличия реальной проектной структуры от дерева характеризуется невязкой структуры. Как определить невязку?
Вспомним, что полный граф (complete graph) с п вершинами имеет количество ребер
ес=n(n-1)/2,
а дерево (tree) с таким же количеством вершин — существенно меньшее количество ребер
et=n-l.
Тогда формулу невязки можно построить, сравнивая количество ребер полного графа, реального графа и дерева.
Для проектной структуры с п вершинами и е ребрами невязка определяется по выражению
![]() .
.
Значение невязки лежит в диапазоне от 0 до 1. Если Nev = 0, то проектная структура является деревом, если Nev = 1, то проектная структура — полный граф.
Ясно, что невязка дает грубую оценку структуры. Для увеличения точности оценки следует применить характеристики связности и сцепления.
Хорошая структура должна иметь низкое сцепление и высокую связность.
Л. Констентайн и Э. Йордан (1979) предложили оценивать структуру с помощью коэффициентов Fan_in(i) и Fan_out(i) модулей [77].
Большое значение Fan_in(i) — свидетельство высокого сцепления, так как является мерой зависимости модуля. Большое значение Fan_out(i) говорит о высокой сложности вызывающего модуля. Причиной является то, что для координации подчиненных модулей требуется сложная логика управления.
Основной недостаток коэффициентов Fan_in(i) и Fan_out(i) состоит в игнорировании веса связи. Здесь рассматриваются только управляющие потоки (вызовы модулей). В то же время информационные потоки, нагружающие ребра структуры, могут существенно изменяться, поэтому нужна мера, которая учитывает не только количество ребер, но и количество информации, проходящей через них.
С. Генри и Д. Кафура (1981) ввели информационные коэффициенты ifan_in(i) и ifan_out(j) [35]. Они учитывают количество элементов и структур данных, из которых i-й модуль берет информацию и которые обновляются j-м модулем соответственно.
Информационные коэффициенты суммируются со структурными коэффициентами sfan_in(i) и sfan_out( j), которые учитывают только вызовы модулей.
В результате формируются полные значения коэффициентов:
Fan_in (i) = sfan_in (i) + ifan_in (i),
Fan_out (j) = sfan_out (j) + ifan_out (j).
На основе полных коэффициентов модулей вычисляется метрика общей сложности структуры:
S
= ![]() length(i)
x (Fan_in(i)
+ Fan_out(i))2,
length(i)
x (Fan_in(i)
+ Fan_out(i))2,
где length(i) — оценка размера i-го модуля (в виде LOC- или FP-оценки).
10. Структурный подход: связность модуля.
Связность модуля (Cohesion) — это мера зависимости его частей [58], [70], [77]. Связность — внутренняя характеристика модуля. Чем выше связность модуля, тем лучше результат проектирования, то есть тем «черней» его ящик (капсула, защитная оболочка модуля), тем меньше «ручек управления» на нем находится и тем проще эти «ручки».
Для измерения связности используют понятие силы связности (СС). Существует 7 типов связности:
1. Связность по совпадению (СС=0). В модуле отсутствуют явно выраженные внутренние связи.
2. Логическая связность (СС=1). Части модуля объединены по принципу функционального подобия. Например, модуль состоит из разных подпрограмм обработки ошибок. При использовании такого модуля клиент выбирает только одну из подпрограмм.
Недостатки:
сложное сопряжение;
большая вероятность внесения ошибок при изменении сопряжения ради одной из функций.
3. Временная связность (СС=3). Части модуля не связаны, но необходимы в один и тот же период работы системы.
Недостаток: сильная взаимная связь с другими модулями, отсюда — сильная чувствительность внесению изменений.
4. Процедурная связность (СС=5). Части модуля связаны порядком выполняемых ими действий, реализующих некоторый сценарий поведения.
5. Коммуникативная связность (СС=7). Части модуля связаны по данным (работают с одной и той же структурой данных).
6. Информационная (последовательная) связность (СС=9). Выходные данные одной части используются как входные данные в другой части модуля.
7. Функциональная связность (СС=10). Части модуля вместе реализуют одну функцию.
Отметим, что типы связности 1,2,3 — результат неправильного планирования архитектуры, а тип связности 4 — результат небрежного планирования архитектуры приложения.
Общая характеристика типов связности представлена в табл. 4.1.
Характеристика связности модуля
Тип связности |
Сопровождаемость |
Роль модуля |
Функциональная |
|
«Черный ящик» |
Информационная ( последовательная ) |
Лучшая сопровождаемость |
Не совсем «черный ящик» |
Кэммуникативная |
|
«Серый ящик» |
Процедурная |
|
«Белый» или «просвечивающий ящик» |
Временная |
Худшая сопровождаемость |
|
Логическая |
|
«Белый ящик» |
По совпадению |
|
|
11. Структурный подход: сцепление модулей.
Сцепление (Coupling) — мера взаимозависимости модулей поданным [58], [70], [77]. Сцепление — внешняя характеристика модуля, которую желательно уменьшать.
Количественно сцепление измеряется степенью сцепления (СЦ). Выделяют 6 типов сцепления.
1. Сцепление по данным (СЦ=1). Модуль А вызывает модуль В. Все входные и выходные параметры вызываемого модуля — простые элементы данных (рис. 4.13).
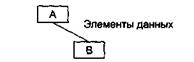
Сцепление поданным
2. Сцепление по образцу (СЦ=3). В качестве параметров используются структуры данных (рис. 4.14).
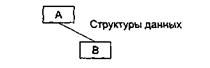
Сцепление по образцу
3. Сцепление по управлению (СЦ=4). Модуль А явно управляет функционированием модуля В (с помощью флагов или переключателей), посылая ему управляющие данные (рис. 4.15).
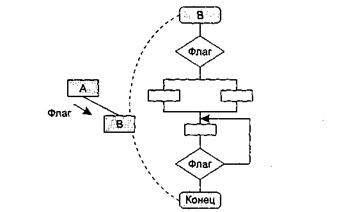
Сцепление по управлению
4. Сцепление по внешним ссылкам (СЦ=5). Модули А и В ссылаются на один и тот же глобальный элемент данных.
5. Сцепление по общей области (СЦ=7). Модули разделяют одну и ту же глобальную структуру данных (рис. 4.16).
6. Сцепление по содержанию (СЦ=9). Один модуль прямо ссылается на содержание другого модуля (не через его точку входа). Например, коды их команд перемежаются друг с другом (рис. 4.16).

Сцепление по общей области и содержанию На рис. видим, что модули В и D сцеплены по содержанию, а модули С, Е и N сцеплены по общей области.
12. Основные понятия и методы структурного тестирования ПО.
Тестирование — процесс выполнения программы с целью обнаружения ошибок. Шаги процесса задаются тестами.
Каждый тест определяет:
свой набор исходных данных и условий для запуска программы;
набор ожидаемых результатов работы программы.
Другое название теста — тестовый вариант. Полную проверку программы гарантирует исчерпывающее тестирование. Оно требует проверить все наборы исходных данных, все варианты их обработки и включает большое количество тестовых вариантов. Увы, но исчерпывающее тестирование во многих случаях остается только мечтой — срабатывают ресурсные ограничения (прежде всего, ограничения по времени).
Хорошим считают тестовый вариант с высокой вероятностью обнаружения еще не раскрытой ошибки. Успешным называют тест, который обнаруживает до сих пор не раскрытую ошибку.
Целью проектирования тестовых вариантов является систематическое обнаружение различных классов ошибок при минимальных затратах времени и стоимости.
Тестирование обеспечивает:
обнаружение ошибок;
демонстрацию соответствия функций программы ее назначению;
демонстрацию реализации требований к характеристикам программы;
отображение надежности как индикатора качества программы.
А чего не может тестирование? Тестирование не может показать отсутствия дефектов (оно может показывать только присутствие дефектов). Важно помнить это (скорее печальное) утверждение при проведении тестирования.
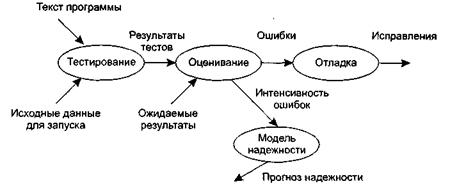
Рассмотрим информационные потоки процесса тестирования. Они показаны на рис. 6.1.