

4.6. Восстановление функций степени достоверности.
Вновь обратимся к форме оптимального решающего правила и представим совместную плотность распределения p(k,x) в виде p(k,x)=f(x)p(k|x). Заметим, что в таком выражении, которое является более традиционным в распознавании образов, оптимальное решающее правило непосредственно опирается на апостериорные вероятности появления классов или, другими совами, степени достоверности p(k|x), k=1,,m. Такие функции, как правило, значительно проще плотностей распределения классов f(x|k), так как функции степени достоверности отражают только взаимное различие плотностей распределения классов в основном лишь в небольших областях их перекрытия в признаковом пространстве. Взаимное различие плотностей распределения классов важно лишь в областях, где, по крайней мере, плотности двух классов l и к lk, отличны от нуля. В остальной же, большей части пространства, согласно гипотезе компактности, значения степени достоверности классов близки к 0 или 1. Очевидно, что в противном случае распознавание с приемлемо величиной риска ошибки просто невозможно. Поэтому обучение распознаванию строится как процесс непосредственного восстановления функций p(k|x) ,k=1,,m без восстановления плотностей f(x|k).
Пусть p(c|x) – некоторое параметрическое семейство действительны функций в пространстве признаков xRn, удовлетворяющих условию 0p(c|x)1 для всех cRp. Рассмотрим случайную величину
 .
.
Если в данном параметрическом семействе p(c|x) существуют такие параметры ck, к=1,,m, при которых апостериорные вероятности классов определяются через их значения p(ck|)=p[g(}=k|x()=] для всех Rn, то в каждой точке признакового пространства условное математическое ожидание случайной величины zk() совпадает с математическим ожиданием p(ck|):
![]() для
всех Rn.
для
всех Rn.
Поэтому найдём коэффициенты ск, к=1,,m из условий:
![]() ,
,
что означает
![]() .
.
Если семейство функций p(c|x) регулярно, то получим критерий обучения
![]() .
.
Пусть (xi,gi), i=1,,N – обучающая последовательность, на которой случайная переменная zk() принимает значения
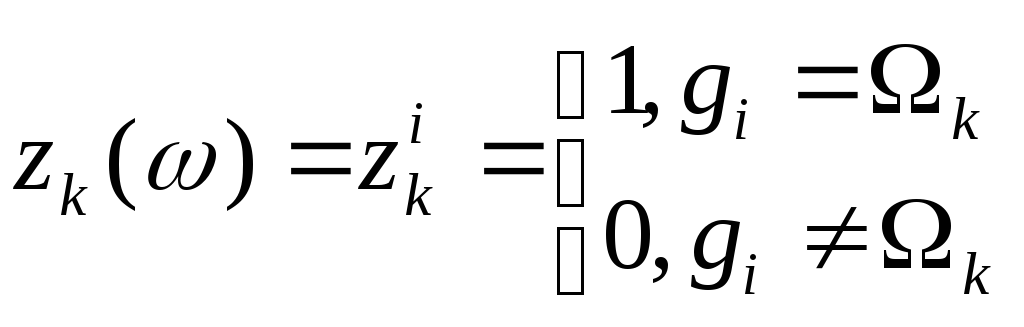 .
.
Заменим операцию математического ожидания усреднением по выборке и получим
![]() .
.
Отсюда получим итерационный градиентный алгоритм оценивания параметров
![]() ,
s=1,,,
,
s=1,,,
где ks – коэффициент основного шага в направлении антиградиента.
В случае бесконечной обучающей выборки (xi,gi), i=1,,, предъявляемой последовательно, рекуррентный алгоритм обучения строится как алгоритм стохастической аппроксимации Роббинса-Монро для решения уравнения регрессии
![]() .
.
Рассмотрим систему некоторых функций yi(x), i=1,,p, образующих пространство Rp, которое является спрямляющим для параметрического семейства p(c|x), таким, что
 .
.
Тогда градиент gradcp(c|x) определяется выражением
 .
.
4.7. МИНИМИЗАЦИЯ СРЕДНЕГО РИСКА.
Методы оценивания плотностей распределения и функций степени достоверности восстанавливают полностью или частично вероятностные характеристики исходных данных. Лишь потом эти характеристики используются для формирования решающего правила. С другой стороны, можно строить алгоритмы обучения для непосредственного выбора решающего правила g(x), минимизирующего средний риск ошибки распознавания R[g()], не восстанавливая вероятностные характеристики исходных данных.
Рассмотрим некоторое заданное параметрическое семейство решающих правил и некоторую фиксированную функцию потерь [g(x),g()]. Тогда средний риск является функцией параметра с: R[g()]=R(c_=M{[g(x,c),g()]}. Тогда требование минимизации среднего риска приводит к условию равенства нулю его градиента.
gradcR(c)=gradcM{[g(x,c),g()]}=0.
Но для функции потерь вида [g(x),g()] перестановка операций дифференцирования и математического ожидания недопустима, так как выражение M{gradc[g(x,c),g()]}0 (тождественно равно нулю) почти для всех с и изменяется скачком в зависимости от параметра с при любом х, так как g(x,c) зависит от с скачкообразно. Из-за этого рекуррентные градиентные процедуры типа стохастической аппроксимации здесь не используются.
Поэтому для построения процедуры обучения используют комбинацию дихотомических решающих правил вида
 ,
,
основанных, как правило, на линейной дискриминантной функции вида d(x,c)=cTx+c0. Тогда параметрическая функция потерь определяется в виде
 .
.
Такая функция штрафует не просто неправильное определение класса объекта, ни и слишком близкое расположение вектора х к разделяющей гиперплоскости в своём классе относительно порога и, тем более, попадание вектора х в область чужого класса. Для такой функции потерь выражение для среднего риска R(с) уже обладает регулярностью, что приводит к невырожденному выражению регрессии
M{gradckl[g(x,c),g()]}=0, k,l=1,,m.
Тогда в случае бесконечной обучающей выборки (xi,gi), i=1,,, предъявляемой последовательно, рекуррентный алгоритм обучения также строится как алгоритм стохастической аппроксимации Роббинса-Монро для решения уравнения регрессии
![]() .
.
4.8. ЛИНЕЙНЫЕ РАЗДЕЛЯЮЩИЕ ФУНКЦИИ.
Как было показано, некоторое решающее правило g(x), независимо от способа его получения, определяет разбиение признакового пространства на области принятия решения 1,,m. Полагая, что решающее правило адекватно структуре обрабатываемых данных, мы считаем, что данные области принятия решений порождают разбиение всего множества исследуемы объектов Х на классы 1,,m. Тем самым мы полагаем, что посредством решающего правила g(x) строится отображение некоторого множества исходных образов, определённых на универсальном множестве , в признаковое пространство, представленное матрицей данных Х.
С другой стороны, решающее правило g(x) порождает совокупность границ, разделяющих области, соответствующие различным классам. Вид границ определяется решающим правилом, где, в частности, линейное решающее правило определяет линейные границы.
Для случая двух классов решающее правило определяет одну границу, такую, что решающее правило принимает совпадающее значение для объектов по одну сторону границы и несовпадающие значения для объектов по обе стороны границы. В таком случае решающее правило удобно определить в виде разделяющей функции вида

В
случае линейной разделяющей функции
получим
![]() .
.
Уравнение вида d(x,c)=0 определяет уравнение разделяющей гиперплоскости в признаковом пространстве. В двухмерном пространстве это просто прямая линия. Обозначив c=(c1,,cn)T, получим уравнение гиперплоскости в виде d(x,c)=cTx+c0=0. Отсюда получим cTx=-c0, где c0 – величина порога. Тогда
 .
.
Возьмём две точки x1 и x2, принадлежащие разделяющей границе классов 1 и 2. Очевидно, что cTx1+c0=cTx2+c0, откуда cT(x1-x2)=0. Следовательно, вектор с ортогонален вектору разности x1-x2. Так как вектор x1-x2 лежит в гиперплоскости, то вектор с определяет нормаль к ней и является её направляющим вектором, а коэффициент с0 называется её смещением от начала координат (вдоль вектора с).
Рассмотрим геометрическое представление уравнения гиперплоскости в двухмерном пространстве (рис.4.2). очевидно, что для x1-x2 выполнены условия cTx1=-c0 и cTx2=-c0. Смещение с0 определяется проекцией некоторого вектора, проведённого из начала координат, с концом, лежащим в гиперплоскости, на её направляющий вектор, например, c0=-||x1||||c||cos. В данном случае c0>0. Тогда проекция некоторого произвольного вектора х на направляющий вектор гиперплоскости есть величина cx=||x||||c||cosx=cTx<0. Так как |cTx|<|c0|, то d(x,c)=cTx+c0=cx+c0>0 есть разность длин проекций или, другими словами, расстояние вектора х до гиперплоскости. Так как в данном случае d(x,c)>0, то нормальный вектор направлен в сторону области 1, а расстояние до гиперплоскости в данной области положительно. В области 2 расстояние до гиперплоскости считается отрицательным.
Следовательно,
знак линейной разделяющей функции
d(x,c)
определяет принадлежность объекта х к
одному из классов 1
или 2,
а значение определяет расстояние до
гиперплоскости при условии, что её
направляющий вектор с имеет единичную
длину. Если ||c||1,
то расстояние от гиперплоскости до
начала координат определяется величиной
![]() ,
а расстояние от некоторого вектора х
до гиперплоскости определяется как
величина
,
а расстояние от некоторого вектора х
до гиперплоскости определяется как
величина
![]() .
.

Рис.4.2. Гиперплоскость и её направляющий вектор.
Для
случая когда число классов m>2
удобно
использовать
![]() различных
решающих функций вида dij(x,c),
где dij(x,c)=-dij(x,c).
Например, для трёх классов нужно построить
три гиперплоскости (рис. 4.3). Как видно,
в данном случае имеется область
неопределённого решения (ОНР), когда
нельзя принять решение о классе объекта.
Для такого объекта классификация не
определена.
различных
решающих функций вида dij(x,c),
где dij(x,c)=-dij(x,c).
Например, для трёх классов нужно построить
три гиперплоскости (рис. 4.3). Как видно,
в данном случае имеется область
неопределённого решения (ОНР), когда
нельзя принять решение о классе объекта.
Для такого объекта классификация не
определена.
Рассмотрим расширенный вектор x=(x1,,xn,1)T и вектор коэффициентов с=(с1,,сn,c0) T. Тогда разделяющая функция имеет вид d(x,c)=cTx, а уравнение разделяющей гиперплоскости в новом, “расширенном” пространстве размерности n+1 имеет вид cTx=0. Согласно рассмотренному выше геометрическому представлению, всякая гиперплоскость cTx=0 имеет нулевое смещение, то есть проходит через начало координат в расширенном пространстве.
В расширенном пространстве удаётся, в частности, избежать появления областей неопределённости решений о классе (рис. 4.3). Например, в данном случае для трёх классов ОНР отсутствует в расширенном пространстве, которое полностью разбито на три области, каждая из которых содержит один класс.


Рис. 4.3.
Область неопределённого решения,
Отсутствие ОНР.
4.9. ОБЛАСТЬ РЕШЕНИЙ ЛИНЕЙНОЙ РАЗДЕЛЯЮЩЕЙ ФУНКЦИИ.
Рассмотрим
снова случай двух классов. Пусть даны
обучающие наблюдения (xi,gi),
i=1,,N,
gi={1,2}.
Мы хотим построить решающее правило
распознавания g(x),
ограничившись параметрическим семейством
решающих правил вида g(x),
ограничившись параметрическим решением
решающих правил вида g(x,c)
на основе построения линейной разделяющей
функции вида d(x,c)=0.
Предположим, что существует такая
разделяющая функция
![]() ,
что вероятность неправильной классификации
хотя бы одного наблюдения из обучающей
выборки с её помощью очень мала. Если
такую разделяющую функцию удаётся
построить, то обучающую совокупность
будем считать линейно разделимой.
Естественно предположить, что в общем
случае существует некоторое множество
гиперплоскостей, разделяющих данную
обучающую последовательность на два
класса. Поэтому в общем случае существует
вполне определённое множество направляющих
векторов таких гиперплоскостей,
образующих область решений в расширенном
пространстве. (Рис. 4.4).
,
что вероятность неправильной классификации
хотя бы одного наблюдения из обучающей
выборки с её помощью очень мала. Если
такую разделяющую функцию удаётся
построить, то обучающую совокупность
будем считать линейно разделимой.
Естественно предположить, что в общем
случае существует некоторое множество
гиперплоскостей, разделяющих данную
обучающую последовательность на два
класса. Поэтому в общем случае существует
вполне определённое множество направляющих
векторов таких гиперплоскостей,
образующих область решений в расширенном
пространстве. (Рис. 4.4).
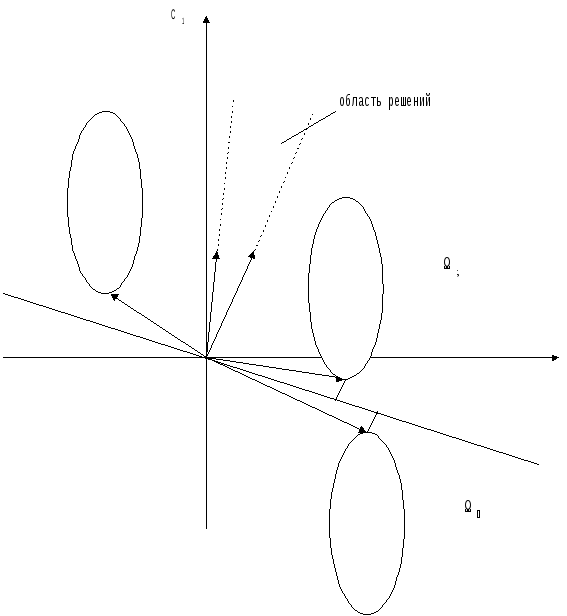
Рис. 4.4. Область решений для двух классов.
Очевидно, что множество направляющих векторов всех гиперплоскостей, разделяющих два класса, образуют конус в расширенном пространстве. Границами конуса являются направляющие векторы таких гиперплоскостей, которые сами проходят через некоторые граничные точки множества 1и2. Для направляющих векторовси области решений все объёкты обучающей совокупности классифицируются правильно, то есть выполнено:
 ,
,
где крайние положения при варьировании направляющего вектора определены моментом, когда в первый раз выполнились условия cTx=0, x1иcTx=0, x2для некоторых граничных точек1 и2.
Часто знак координат объектов из класса 2инвертируют. Тогда все объекты обучающей совокупности12’ классифицируются правильно, еслиcTx>0, x12’, в крайние положения при варьировании направляющего вектора определяются выполнением условияcTx=0для некоторых граничных точек из12’.
Напомним некоторые определения. Пусть в n-мерном пространстве заданы два вектораx1 иx2. Тогда вектор разностиx2-x1направлен из точкиx1 в точкуx2, а векторx=x1+(x2-x1)при 01лежит на отрезке, соединяющем точкиx1 иx2. Векторxназывается выпуклой линейной комбинацией точекx1иx2 и при варьированиипробегает все точки отрезка между точкамиx1 иx2.
Множество точек называется выпуклым, если любые его точки можно соединить отрезком, любая точка которого также принадлежит этому множеству.
Граничной точкой множества называется точка, в - окрестности которой при любомЮ0 содержатся точки, не принадлежащие данному множеству. В противном случае такая точка является внутренней точкой множества. Здесь- окрестностью некоторой точки а называется множество точекx, удовлетворяющих условию||x-a||<.
Множество называется замкнутым, если оно содержит все свои граничные точки.
Выпуклой оболочкой замкнутого выпуклого множества называется множество его граничных точек. Выпуклой оболочкой невыпуклого замкнутого множества называется множество граничных точек минимального выпуклого замкнутого множества, охватывающего данное.
Гиперплоскость называется опорной, если она проходит через некоторую граничную точку выпуклого замкнутого множества или, другими словами, касается его выпуклой оболочки.
Можно доказать, что, если выпуклые оболочки двух множеств не пересекаются и не соприкасаются, то их можно разделить более, чем одной гиперплоскостью, проходящей в расширенном пространстве через начало координат, множество направляющих векторов которых образуют выпуклый конус. Границы выпуклого конуса определяются направляющими векторами опорных гиперплоскостей, проходящих через начало координат.
Тогда в качестве разделяющей можно взять любую из гиперплоскостей, направляющий вектор которой лежит в области решений.
Но, как правило, из всего множества направляющих векторов в области решений стремятся выбрать один или хотя бы некоторое подмножество, являющихся в некотором смысле оптимальными по отношению ко всем векторам области решений.
Представление об оптимальности разделяющей гиперплоскости основано на том, что для разных разделяющих гиперплоскостей с направляющими векторами из области решений существуют в общем случае различные вероятности неправильной классификации. Поэтому оптимальная в некотором смысле гиперплоскость должна, в итоге, обеспечить уменьшение вероятности неправильной классификации.
Предположение о линейной разделимости обучающей совокупности на два класса 1и2при её неизвестных вероятностных характеристиках позволяет сформулировать понятие оптимальности разделяющей гиперплоскости непосредственно терминах гиперплоскостей, косвенно обеспечивая уменьшение вероятности ошибочной классификации.
Рассмотрим исходное (нерасширенное) пространство. Будем считать оптимальной гиперплоскость, которая наиболее удалена от выпуклых оболочек разделяемых множеств. (рис. 4.5).
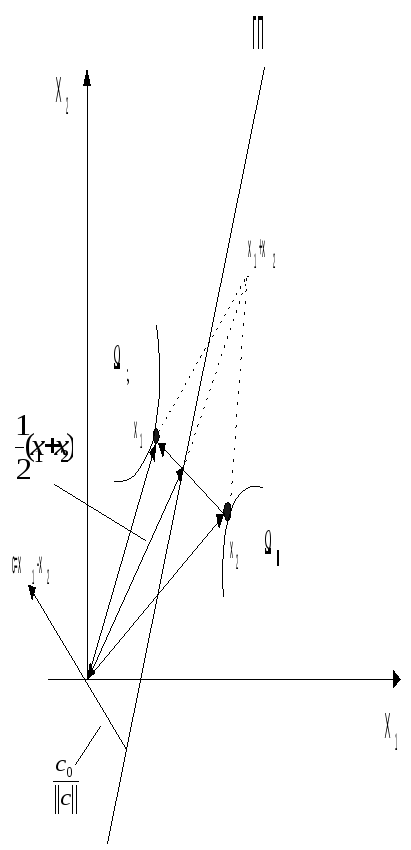
Рис. 4.5. Гиперплоскость, наиболее удалённая от выпуклых оболочек разделяемых множеств.
Пусть
x11иx22– ближайшие точки выпуклых оболочек
разделяемых множеств, где||x1-x2||
- минимальное расстояние среди всех
точек выпуклых оболочек множеств1и2. Тогда
оптимальная гиперплоскость определяется
направляющим векторомc=x1-x2и смещением![]() ,
проходя через середину отрезка,
соединяющегоx11
иx22
перпендикулярно ему.
,
проходя через середину отрезка,
соединяющегоx11
иx22
перпендикулярно ему.
В другом случае (рис. 4.6) в расширенном пространстве оптимальные гиперплоскости не касаются выпуклых оболочек, а их направляющие векторы находятся внутри суженной области решений cTx>b, гдеb-некоторый допуск,x12’или
 .
.

Рис. 4.6. Суженная область принятия решений.
С другой стороны, знание вероятностных характеристик обучающей совокупности позволяет оптимальное решающее правило в виде байесовского классификатора. Задавшись видом параметрического семейства распределений, мы тем самым можем определить параметры оптимальной разделяющей границы. Такую границу, как правило, можно определить как гиперплоскость в соответствующем спрямляющем пространстве.
Пусть, например, задано параметрическое нормальной семейство распределений. Пусть решающее правило

строится на основе разделяющей функции вида
d(x,c)=log p(x|1)+log p(1)-log p(x|2)-log p(2=0, где
p(x|j)=N(j,j), j=1,2.
Тогда получим
D(x,1,1,2,2)=-![]() (x-1)T1-1(x-1)-
(x-1)T1-1(x-1)-![]() log
2-
log
2-![]() log
det1+log
p(1)+
log
det1+log
p(1)+
+![]() (x-2)T2-1(x-2)+
(x-2)T2-1(x-2)+
![]() log2+
log2+![]() log
det2-log
p(2).
log
det2-log
p(2).
Рассмотрим
случай, когда 1=2=2E,
где Е – единичная матрица. Такой случай
возникает, когда признаки Хj,j=1,,nстатистически независимы и имеют
одинаковую дисперсию2.
Напомним, что такому случаю можно прийти,
в частности, перейдя от стандартизованной
матрицы данныхXк
стандартизованной матрицеYпосредством ортогонального преобразованияY=ХАЛ-0,5, где А –
матрица собственных векторов корреляционной
матрицы![]() ,
а Л – диагональная матрица с собственными
числами на главной диагонали. В этом
случае1=2=Eи2=1, а классы1и2являются гиперсферами с центрами в
точках1и2.
Тогдаdet 1=det2=2n,
1-1=2-1=-2E.
,
а Л – диагональная матрица с собственными
числами на главной диагонали. В этом
случае1=2=Eи2=1, а классы1и2являются гиперсферами с центрами в
точках1и2.
Тогдаdet 1=det2=2n,
1-1=2-1=-2E.
После преобразования и сокращения подобных получим разделяющую функцию
![]() .
.
Если
2=1 иp(1)=p(2),
то опустив![]() ,
получим разделяющую функцию
,
получим разделяющую функцию
D(x,1,2)=||x-2||2-||x-1||2.
Решающее правило запишется как
 .
.
Такое байесовское решающее правило часто называется классификатором по минимуму расстояния до эталона класса, где эталонами являются средние по классам 1и2.
С другой стороны
 .
.
Данное
уравнение определяет в исходном
пространстве гиперплоскость с направляющим
вектором -2(1-2)
и смещением
![]() .
Положив2=1
и р(1)=P(2)
и введя
обозначения c=(1-2)
и
c0=
.
Положив2=1
и р(1)=P(2)
и введя
обозначения c=(1-2)
и
c0=![]() (1-2)T(1+2)
получим
уравнение оптимальной гиперплоскости,
наиболее удалённой от гиперсферических
оболочек классов 1
и 2
с радиусами гиперсфер r1=r2<|c0|.
Такая гиперплоскость проходит через
середину отрезка
(1-2)T(1+2)
получим
уравнение оптимальной гиперплоскости,
наиболее удалённой от гиперсферических
оболочек классов 1
и 2
с радиусами гиперсфер r1=r2<|c0|.
Такая гиперплоскость проходит через
середину отрезка
![]() перпендикулярно ему. Приp(1)p(2)
гиперплоскость смещается в соответствующую
сторону на величину log
перпендикулярно ему. Приp(1)p(2)
гиперплоскость смещается в соответствующую
сторону на величину log![]() .
.
Рассмотрим другой простой случай, когда ковариационные матрицы классов совпадают 1=2=, а сами классы являются гиперэллипсоидами с центрами в точках 1 и 2 и полуосями, направленными вдоль собственных векторов ковариационной матрицы . Тогда дискриминантная функция имеет вид
d(x,1,2,)=![]() [(x-2)T-1(x-2)-(x-1)T-1(ч-1)]+log
[(x-2)T-1(x-2)-(x-1)T-1(ч-1)]+log![]() .
.
В случае p(1)=p(2) байесовское решающее правило на основе такой дискриминантной функции называется классификатором по минимуму квадратичного махаланобисова расстояния до каждого из эталонов 1 и 2. Преобразуем выражение и получим
d(x,1,2,)=![]() [xT-1x-2xT-12+2T-12-xT-1x+2xT-11-1T-11]+log
[xT-1x-2xT-12+2T-12-xT-1x+2xT-11-1T-11]+log![]() =
=
=(1-2)T-1x-![]() (1-2)T-1(1+2)+log
(1-2)T-1(1+2)+log![]() =0.
=0.
Это
уравнение гиперплоскости с направляющим
вектором cT=(1-2)T-1
и смещением -![]() (1-2)T-1(1+2)+log
(1-2)T-1(1+2)+log![]() .
Так как направляющий вектор с в общем
случае не совпадает с вектором 1-2,
то разделяющая гиперплоскость в случае
p(1)=p(2)
проходит через середину 1-2
не ортогонально ему. Разделяющая
гиперплоскость пройдёт через середину
1-2
ортогонально ему, если вектор 1-2
лежит в направлении некоторого
собственного вектора матрицы -1,
так как именно в этом случае выполнено
(1-2)T-1=(1-2)T,
где
- является
одним из собственных чисел i,
i=1,,n
(рис. 4.7).
.
Так как направляющий вектор с в общем
случае не совпадает с вектором 1-2,
то разделяющая гиперплоскость в случае
p(1)=p(2)
проходит через середину 1-2
не ортогонально ему. Разделяющая
гиперплоскость пройдёт через середину
1-2
ортогонально ему, если вектор 1-2
лежит в направлении некоторого
собственного вектора матрицы -1,
так как именно в этом случае выполнено
(1-2)T-1=(1-2)T,
где
- является
одним из собственных чисел i,
i=1,,n
(рис. 4.7).

Рис. 4.7. Классификатор по минимуму махаланобисова расстояния.
4.10. АЛГОРИТМЫ ПОСТРОЕНИЯ РАЗДЕЛЯЮЩИХ ГИПЕРПЛОСКОСТЕЙ.
Алгоритмы такого типа возникают в детерминистской постановке задачи обучения распознаванию образов. Напомним, что в такой задаче, например для случая двух классов, предполагается, что плотности распределения вероятностей p(x|1) и p(x|2) сосредоточены целиком в непересекающихся областях пространства признаков 12=. Условием успешного решения задачи обучения служит предположение о существовании в спрямляющем пространстве линейной дискриминантной функцией вида d(x,c)=0. Данная дискриминантная функция существует, если выпуклые оболочки разделяемых областей 1 и 2 не пересекаются. Тогда она выражается как линейная комбинация признаков с коэффициентами, значения которых определены направляющим вектором некоторой гиперплоскости, разделяющей области 1 и 2 в расширенном пространстве. Если выпуклые оболочки областей 1 и 2 соприкасаются, то разделяющая гиперплоскость является единственной. В противном случае множество таких гиперплоскостей. В качестве разделяющей принимается одна из них, либо произвольно, либо удовлетворяющая некоторому условию оптимальности. Следовательно, разделяющая гиперплоскость должна правильно классифицировать объекты x12’ обучающей совокупности, то есть вектор с должен удовлетворять системе линейных неравенств cTx>0, x12’, где 2’ является инверсией 2.
Общий подход, используемый для нахождения решения такой системы линейных неравенств состоит в подборе некоторого критерия J(c), который минимизируется при условии, что вектор с является вектором решения. Тогда алгоритм строится как градиентная процедура поиска минимума критерия J(c).
Как известно, применение градиентных процедур сопряжено с целым рядом проблем. Содержательно, эти проблемы определяются сложностью формы поверхности, вид которой определён видом экстремизируемого функционала J(c): проблема начального решения, проблемы вычисления градиента, проблема выбора величины шага, проблема локальности решения, скорости сходимости и прочее.
Но в данном случае большинство данных проблем можно легко решить, так как мы можем сами определить вид функционала J(c), сделав его, естественно, как можно более простым. Наиболее естественно определить функционал J(c)как число неверно классифицированных объектов x12’. Очевидно, что данная функция критерия имеет единственный минимум, но вычисление её градиента вызовет трудности, так как она является кусочно-постоянной. Поэтому более удобной является другая простая функция, так называемая функция перцептрона, имеющая вид
![]() ,
012’,
где 0
– множество неверно классифицированных
объектов обучающей совокупности.
,
012’,
где 0
– множество неверно классифицированных
объектов обучающей совокупности.
Очевидно, что Jp(c)0 и достигает глобального минимума Jp(c)=0 когда множество неверно классифицированных объектов пусто. В этом случае вектор с принадлежит области решений линейной разделяющей функции d(x,c)=0. Геометрически функция Jp(c) пропорциональна сумме расстояний от неверно классифицированных объектов до разделяющей гипеплоскости. На рис. 4.8 показан её вид в двухмерном случае. Для расширенных векторов функция градиента имеет вид
![]() ,
где
,
где
![]() ,i=1,,n,
,i=1,,n,
![]() .
.
Пусть мы находимся на шаге sкорректировки вектора cs. Получим его новое значение
![]() ,
,
где s – длинна очередного шага. Следовательно, мы получили выражение для целого класса рекуррентных градиентных процедур минимизации функции перцептрона.

Рис. 4.8. Функции перцептрона.
Пусть снова (xj,gj), j=1,, - бесконечная обучающая последовательность. Тогда обобщенная итерационная процедура минимизации функции критерия для случая двух классов запишется как
cj+1=cj-jjjgradcd(xjmcj), где
![]() ,
,
 ,
,
где j – некоторая числовая последовательность, определяющая длину шага; коэффициент j определяет, что изменение вектора с происходит лишь на тех шагах j, на которых очередной элемент (xj,gj) обучающей последовательности неверно классифицируется функцией d(xj,cj), то есть jd(xj,cj)0;, коэффициент j выполняет инверсию координат вектора xj, если xj2, то есть оxj2’. Шаг длинны о делается в направлении наибольшего возрастания функции оd(xобсо)0.
Последовательность
j
можно определить по-разному, например,
j=1
даёт правило постоянного приращения.
Впервые оно было предложено Ф.Розенблаттом
для перцептронной модели мозга как
реализация принципа обучения с поощрением.
В более общем случае j0,
например, j= ,
образуя убывающую последовательность
j,
где
,
образуя убывающую последовательность
j,
где
![]() ,
,![]() .
Можно доказать, что число шаговj=1
корректировки вектора с конечно. Для
j=1
этот факт известен как теорема о
сходимости перцептрона.
.
Можно доказать, что число шаговj=1
корректировки вектора с конечно. Для
j=1
этот факт известен как теорема о
сходимости перцептрона.
Следовательно, дискриминантная функция d(x,c)=0 будет найдена с вероятностью 1 после конечного числа предъявлений объектов для распознавания. Алгоритмы такого вида называются конечно - сходящимися. Тем не менее, оценить, какая длина обучающей выборки является достаточной, в общем случае невозможно в принципе. Можно лишь оценить вероятность того, что дискриминантная функция уже обладает нужными свойствами на очередном шаге.
На практике длина обучающей совокупности конечна (xj,gj), j=1,,N. Поэтому дискриминантная функция строится путём многократного циклического предъявления объектов обучающей последовательности. Если дискриминантная функция d(x,c)=0 строится за конечное число шагов, то параметр с перестанет изменяться после конечного числа циклов обучения. Следует отметить, что обратное утверждение, вообще говоря, не верно. А именно, циклически сходящийся алгоритм обучения не обязательно окажется конечно - сходящимся, так как существует конечная вероятность того, что обучающая выборка конечного размера не является в достаточной степени представительной выборкой из генеральной совокупности.
4.11. АЛГОРИТМ ПОСТРОЕНИЯ ОПТИМАЛЬНОЙ РАЗДЕЛЯЮЩЕЙ ГИПЕРПЛОСКОСТИ.
Следует отметить, что требование линейной разделимости классов в детерминистской задаче распознавания является весьма жёстким априорным предположением о структуре данных. Легко предположить, что на практике это требование часто окажется невыполненным. Теорема о сходимости утверждает лишь то, что число корректировок решающего правила конечно в случае линейной разделимости данных и не определяет поведения конечно – сходящегося алгоритма в противном случае. На практике это означает, что без привлечения дополнительной информации, характеризующей поведение алгоритма, ничего нельзя сказать о том, зациклился алгоритм или длина обучающей выборки всё ещё недостаточно для его остановки.
Существуют различные способы эвристического усложнения общей градиентной процедуры построения разделяющей гиперплоскости, позволяющие предотвратить зацикливание. При остановке по признаку зацикливания либо отказываются от построения разделяющей гиперплоскости, либо определяют решение, оптимальное в некотором смысле по числу неверно классифицированных отчетов. В последнем случае естественно использовать детерминистские аналоги критериев оптимальности в вероятностной задаче обучения.
Рассмотрим итерационный алгоритм Б. Н. Козинца минимизации перцептронной функции критерия для случя двух классов, который находит оптимальную разделяющую гиперплоскость с направляющим вектором с и смещением с0, либо устанавливает, что выпуклые оболочки разделяемых множеств пересекаются. Здесь, как было определено ранее, оптимальной называется гиперплоскость, наиболее удалённая от выпуклых оболочек разделяемых множеств.
Работу данного алгоритма удобно рассмотреть в исходном пространстве размерности n. Для различия множеств 1и 2сформируем дискриминантный функционал вида
 ,
с=(с1,,сn)T,
x=(x1,,xn)T.
,
с=(с1,,сn)T,
x=(x1,,xn)T.
Данный
алгоритм за конечное число шагов находят
точки x+1
и x–2
выпуклых оболочек такие, что проекции
отрезка между ближайшими точками
выпуклsх
оболочек на вектор x+-x–
меньше его длинны ||x+-x–||
не более,
чем на вершину ||x+-x–||,
где 0<<1
– достаточно малая наперёд заданная
величина. В качестве разделяющей
принимается гиперплоскость cTx+c0=0
с направляющим
вектором c=x+-x–
и смещением
с0=![]() (x+-x–)T(x+-x–),
проходящая ортогонально через середину
вектора x+-x–.
Если ||x+-x–||<,
где 0<<1
– достаточно малая наперйд заданная
величина, то считается, что разделяющая
гиперплоскость не существует.
(x+-x–)T(x+-x–),
проходящая ортогонально через середину
вектора x+-x–.
Если ||x+-x–||<,
где 0<<1
– достаточно малая наперйд заданная
величина, то считается, что разделяющая
гиперплоскость не существует.
Отметим
важное свойство данного алгоритма. А
именно, между гиперплоскостями,
проходящими ортогонально через точки
вектора x+-x–,
лежащие на расстоянии
![]() от его концов, гарантированно не
содержится ни одной точки из множества
1
и 2.
Такие гиперплоскости отличаются от
оптимальной только своими смещениями
от его концов, гарантированно не
содержится ни одной точки из множества
1
и 2.
Такие гиперплоскости отличаются от
оптимальной только своими смещениями
![]() к
множеству 1
и
к
множеству 1
и
![]() к
множеству
2
(рис. 4.9).
к
множеству
2
(рис. 4.9).

Рис. 4.9. Оптимальная разделяющая гиперплоскость.
Алгоритм работает следующим образом. Циклически поочерёдно просматриваются объекты из 12, например в порядке следования в обучающей последовательности (xk,gk), k=1,,N. Если очередной объект xk1, то точка xk– остаётся без изменений xk–=xk-1–. Новая точка xk– определяется как точка вектора xk-xk-1+, ближайшая к точке xk–:
![]() ,
,
 ,
,
где
 ;
;
 .
.
Обозначим ck-1=xk-1+-xk-1– и получим
 и
и
 .
.