

Витрины данных (Data Marts).
Они носят более рекламный, интегрированный характер. Витрины данных – это множество тематических БД, содержащих информацию, относящуюся к отдельным аспектам деятельности организации (т.е. доступ к данным имеет неограниченное или ограниченное по определенным правилам число пользователей).
On-line Transaction Processing (OLTP).
Это системы, ориентированные на операционную транзакционная обработку (оперативная обработка – т.е. транзакция – это простейшая операция (например, нажатие кнопки, вывод, ввод данных)).
On-line Analytical Processing (OLAP).
On-line Analytical Processing (OLAP) – это оперативная аналитическая обработка (т.е. в данном случае обрабатывается не отдельная операция, а производится аналитическая обработка данных с помощью каких-либо правил).
Обработка может быть разной. Это зависит от того, какие данные в системе имеются, и как производится их обработка.
Автоматизированные системы – это системы, обеспечивающие многомерный анализ данных.
Из хранения данных можно выделить следующие разновидности: ROLAP (Relational); OLAP – системы, которые используют реляционные структуры для хранения данных (т.е. в виде плоских таблиц, взаимосвязанных друг с другом); на ее основе возможна аналитическая обработка; HOLAP (Hybrid) – информационные системы, которые используют различные способы хранения данных (таблицы, сетевые модели, либо иерархические модели); MOLAP (Multidimensional) – хранение данных в многомерной структуре.
Многомерное представление данных – это множественная перспектива, состоящая из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Для такого представления данных используются оси. Примерами используемых осей являются: временная, географическая, продуктовая (вдоль них можно накапливать и анализировать данные).
OLAP системы относят к системам обработки данных (СОД).
Существуют также системы поддержки принятия решений (СППР) – т.е. управленческие решения в социально – экономических системах, которые принимает человек (для правильности или быстроты принятия решения).
Такие системы носят название Deciding Support System (системы DSS).
OLAP системы частично или полностью входят в СППР.
Классификация информационных систем по виду режима анализа данных
Информационные системы по виду режима анализа данных делятся на:
статические информационные системы (ИАС).
динамические ИАС.
Статические системы предполагают наличие предопределенного набора сценариев обработки, статичность исходных данных и конечных результатов, т.е. те результаты, которые получены, остаются всегда справедливыми.
Динамические ИАС отрицают статистику (т.е. так как данные устаревают, то время является для динамических ИАС важным параметром).
Недостатком динамических ИАС является то, что заранее трудно предусмотреть сценарий работы.
Динамические ИАС относятся к системам реального времени (СРВ).
Табл.2. Сравнение характеристик статического и динамического анализа данных
Характеристика |
Статический анализ данных |
Динамический анализ данных |
Назначение |
Регламентированная аналитическая обработка |
Многопроходный анализ, моделирование, построение прогнозов |
Типы запросов |
Регламентированные (заранее определены, записаны и заложены в память) |
Непредсказуемые |
Уровень требований |
Средний (основные задаваемые вопросы: сколько?; как?; когда?) |
Высокий (основные задаваемые вопросы: почему?; что будет, если?) |
Время отклика системы на вопрос |
Нет четких требований |
Секунды |
Типичные операции |
Регламентированный отчет, диаграмма |
Интерактивные отчеты, интерактивные диаграммы, динамическое изменение уровней агрегации (объединения) и срезов данных |
Уровень агрегации данных |
Детализированные и агрегированные |
В основном агрегированные |
Возраст данных |
Ретроспективные и текущие |
Ретроспективные, текущие и прогнозируемые |
Типы экранных форм |
Заранее определенные |
Конструируемые пользователем |
Многомерный динамический анализ
Требования к многомерному динамическому анализ.
Основоположником требований к многомерному анализу данных был Е.Кодд. Он сформулировал 12 основных требований к OLAP системе многомерного динамического анализа:
Многомерное представление данных дает возможность разместить информацию по различным направлениям, для различных срезов.
Для этого используются следующие формы представления данных: куб; гиперкуб – когда осей больше, чем три; звезда – когда задается много направлений. При данном представлении можно производить анализ вдоль и поперек осей, вращать срезы или оси и производить другие перемещения.
Прозрачность. Данное требование задается пользователем.
Устойчивая производительность. Данное требование отражает проблему, состоящую в том, что существует очень много форматов хранения.
Клиент–серверная архитектура. Необходимо, чтобы большая часть данных хранилась на машине–сервере, а пользователь на PC делал к ней запрос.
Равноправие измерений. Временное измерение требуют все географические происходящие во времени процессы, например, в продуктовом обороте если кому-то понадобится ответ на поставленный вопрос, то он приходит за одно и то же время, а алгоритмы обработки и формы отчетов не должны быть привязаны к одному измерению.
Поддержка многопользовательского режима. Существует необходимость ответа на некоторое количество запросов из разных рабочих мест к одной и той же базе данных.
Виртуальный куб данных
Виртуальный куб данных – это куб, построенный из подмножеств измерений и показателей каких-либо кубов данных.
Виртуальный куб использует рассчитанные агрегаты кубов данных, что ведет к экономии данных.
Пример многомерной (4-х мерной) информационной модели, используемой при анализе промышленного сектора экономики региона.

Рис. 29. Многомерная информационная модель распределения данных
В качестве четвертого измерения можно обозначить перечень отраслей.
Задача поиска состоит в том, чтобы по определенному показателю выйти на какую-то ячейку. Показатели разбиваются (год на кварталы, кварталы на месяца и т.д.).
Пример olap–решений фирмы «Парус»
OLAP-технология – это технология, позволяющая быстро проводить анализ больших объемов данных и наглядно отображать полученные результаты.
OLAP-технологии адресованы в первую очередь аналитикам, менеджерам и руководителям кампаний для анализа сложного процесса на предприятии.
Суть работы с использованием таких технологий заключается в следующем: если пользователь сформировал запрос, то он ставит эту задачу перед программистом, который, исходя из существующих запросов, пишет и отлаживает запрос.
Недостатки традиционной формы запросов:
Большие затраты ресурсов (временных, финансовых и прочих).
Сложность описания с помощью языка SQL (языка для стандартных запросов), т.е. для работы с такой технологией требуется программист высокой квалификации.
Например, необходимо установить какая группа товаров, в каких регионах и по каким потребителям приносит большую прибыль? Для этого составляется виртуальный куб данных с использованием следующих измерений: продукт, география, время (возможно также составление и гиперкуба данных). При этом некоторые оси могут требовать своей детализации.
На пересечении осей находится ячейка с цифрой, называемая мерой.
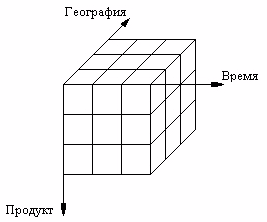
Рис. 30. Многомерный куб данных, показывающий распределение потребления продуктов по территориям в определенный промежуток времени
Возникает необходимость перерасчета, что требует значительных затрат времени. Также могут измениться и требования к запросу и отчету.
Ошибки психологического плана. Они возникают в том случае, когда человек по истечении времени после получения отчета не может анализировать представленные им данные. Чем больше времени определено на ожидание человеком ответа, тем больше требуется понимание. Для избежания таких ситуаций необходимо изменить систему так, чтобы она была более быстродейственной.
Примеры срезов кубов данных.
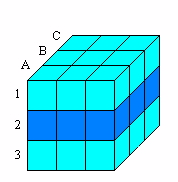
Рис. 31. Горизонтальный срез (по географии и по времени)
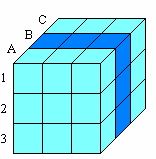
Рис. 32. Вертикальный срез (по времени и продукту)
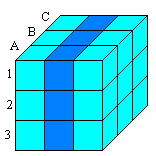
Рис. 33. Вертикальный срез (по продукту и географии)
Делая тот или иной «разрез» куба, мы получаем интересующий нас показатель.
Корпорация «Парус» распространяет продукты фирмы «Oracle».
Основные характеристики продуктов фирмы «Oracle».
Возможности:
Позволяет оперативно анализировать:.
сбыт;
закупки;
логистику;
затраты;
обязательства контрагентов и т.п.
Высокая скорость выполнения отчетов независимо от их сложности и объема БД. Это возможно за счет того, что исходная БД обрабатывается соответствующим образом.