

Возможность применения стандартных методик для анализа результатов (методики статистической обработки).
Интерполяция – математическая задача нахождения той функции, которая могла бы заменить объем данных (старых данных на новые).
Экстраполяция – предсказание.
Интерполяция и экстраполяция заложены в математические структуры, аппараты.
Позволяет значительно уменьшить время.
Можно решить вопросы ограничения доступа и защиты информации от несанкционированного доступа.
В настоящее время используются также продукты фирмы «Cognos», распространяемые фирмой «IT».
Основные положения создания ИАС руководителя:
Сбор, согласование и организация хранения данных. Согласование необходимо, так как данные поступают с определенной степенью достоверности и иногда противоречат друг другу.
Выбор способов и методов аналитической обработки накопленных и рационально организованных данных. Рациональная организация необходима из-за того, что не должно быть избытка информации (повторов) и вся эта информация должна быть «разложена по полочкам». Способы аналитической обработки данных определяются постановкой вопроса пользователем.
Выбор методов интеллектуальной обработки данных.
Выбор способов и методов визуализации результатов. Необходима аналитическая (расчет по формулам, определение максимума и минимума продаж) и интеллектуальная (задача прогноза) обработка данных.
Выбор технологий подготовки и разработки прогностических сценариев и методов принятия решения.
Технологии интеллектуального анализа данных (иад, bi – Business Intelligents)
К числу интеллектуальных технологий анализа данных относят такие, которые реализуют:
поиск функциональных и логических закономерностей накопленной информации (интеллектуальная деятельность);
построение моделей и правил с целью объяснения этих закономерностей или найденных аномалий;
прогнозирование развития изучаемых процессов.
Специфика современных требований к переработке данных:
Данные имеют практически неограниченный объем;
Данные являются разнородными (количественными, качественными, текстовыми и т.д.);
Результаты должны быть конкретны и понятны;
Инструменты для обработки «сырых» (непроверенных, непроверифицированных) данных должны быть просты в использовании.
Data Mining – «разведка, добыча данных».
Табл.3. Отличия между технологиями OLAP и Data Mining
OLAP |
Data Mining |
Каковы средние показатели травматизма для курящих и некурящих? |
Встречаются ли точные шаблоны в описании людей, подверженных повышенному травматизму? |
Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? |
Существуют ли стереотипные схемы покупок в случае мошенничества с кредитными карточками? |
Особенности технологии Data Mining
Процесс обнаружения в «сырых» данных:
ранее неизвестных знаний;
нетривиальных выводов;
практически полезных выводов;
доступных для интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Уровни знаний, извлекаемых из данных.
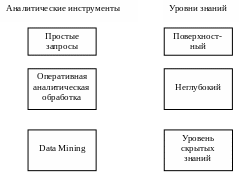
Рис. 34.Схема уровней знаний, извлекаемых из данных
Применение Data Mining.
Data Mining применяются в следующих отраслях:
торговля, в том числе и розничная (анализ покупательской корзины, анализ временных шаблонов, создание прогнозируемых моделей);
банковское дело (выявление мошенников с кредитными карточками, сегментация клиентов (разбиение на группы – каким клиентам какие услуги предлагать), прогнозирование изменения клиентуры);
страхование (аналогично);
в сфере коммуникаций (здесь ставятся следующие задачи: анализ записей по характеристикам вызовов – какой круг клиентов, какими видами услуг пользуется; выявление лояльности клиентов);
в медицине;
в химии;
в промышленности и т.д.
Основные задачи информационно-аналитической деятельности:
Классификация – задача выявления признаков однотипных объектов для того, чтобы отнести новый объект к тому или иному классу.
Кластеризация – развитие идеи классификации на более сложный случай, когда сами классы объектов не предопределены, но стоит задача определить однородные группы данных.
Выявление ассоциаций – установление правил, указывающих на то, что при наступлении одного события с определенной вероятностью наступает другое.
Выявление последовательностей – установление связи между событиями, наступающими не одновременно, а с некоторым временным шагом.
Задача прогнозирования – оценка будущих значений, определяемых показателей на основе их текущих и ретроспективных данных. Это наиболее сложная из перечисленных задач.
Процесс информационной деятельности может быть представлен рядом временных стадий, которые изображены на диаграмме.
Табл.4. Стадии информационной деятельности
Стадии |
|||||
Свободный поиск |
Прогностическое моделирование |
Анализ исключений |
|||
Выявление закономерностей условной логики |
Выявление закономер- ностей ассоциативной логики |
Выявле-ние трендов и колеба-ний |
Предсказа-ние неизвестных значений |
Процесс развития процессов |
Выявление и объяснение отклонений |
Действия |
|||||
Свободный поиск – это процесс исследования накопленных данных на предмет поиска скрытых закономерностей без предварительного выявления гипотез относительно этих закономерностей (если гипотеза скрытая, то поиск свободный).
В процессе свободного поиска используется математический аппарат условной логики, с помощью правил которой могут быть описаны группы примеров в задачах классификации и кластеризации.
На основе использования правил ассоциативной логики можно решать задачи выявления ассоциаций и последовательностей.
Выявление трендов (наличие какой-то устойчивой закономерности в том объеме данных, которые используются) и колебаний является первым этапом программирования.
Вторая стадия информационной деятельности – прогностическое моделирование. Осуществление действий на этой стадии становится возможным после выполнения действий на стадии свободного поиска.
Третья стадия – анализ исключения из правил. Данная стадия занимается тем, чем обусловлено выпадение какого-то параметра от ранее установленной закономерности, выявляются отклонения и даются им объяснения.
Для решения задач информационной деятельности используются БД, накопленные из временных рядов.
Классы информационных технологий и систем Data Mining
Data Mining – мультидисциплинарная область (данные системы решаются с применением нескольких научных дисциплин). Развивается на базе таких наук, как прикладная статистика, теория распознавания образов (авторефераты текстов, распознавание текстов), методов теории искусственного интеллекта, теории БД и других научных дисциплин.
Классификация технологий и систем Data Mining.
Предметно–ориентированные аналитические системы (например, в финансовой области – предсказание курса валют). Часто основой для технологий является статистический аппарат (аппарат прикладной статистики), в наибольшей мере учитывающий специфику рассматриваемой области. Цена таких технологий меньше 1 тысячи $, т.е. они недорогие и их много.
Статистические пакеты. В качестве математического аппарата используются методы математической статистики.
Круг задач, решаемых с помощью статических пакетов: создание корреляционных моделей (корреляция – термин, который обозначает наличие связи между случайными величинами процесса, но связи статистические); факторный анализ (берется параметр, который зависит от каких-то факторов, при этом берется функциональная связь, но сложная, т.к. нет никаких математических зависимостей); регрессионный анализ.
Достоинства данных методов состоит в том, что они основываются на математическом аппарате.
Недостатки: требуется специальная подготовка пользователя; а также математический, принципиальный недостаток пакетов состоит в том, что они дают математически усредненный вывод (например, средняя температура тела по госпиталю).
Существуют такие статистические пакеты, как SAS (SAS Institute), Statistics, SPSS и т.д.
Технологии нейронных сетей.
Принцип работы нейронных сетей заключается в следующем: имитируется работа нейронов в составе иерархической сети. При этом сигналы передаются от нижних слоев к верхним, а сила сигнала зависит от сложности связи.
Недостатки:
необходимо иметь большой объем обучающей выборки;
результаты работы такого пакета трудно объяснить.
К программам, реализующим технологии нейронных сетей относятся: пакет Brain Maker (CSS) Neuro Sheel (Word System Group). Стоимость таких систем очень высока (более 1 тысячи $).
Система рассуждений на основе аналогичных случаев.
Case Based Reasoning (CBR) – системы, основанные на аналогичном случае.
Назначение таких систем: среди БД множества случаев найти тот, который наиболее близок.
Недостатки:
не создается никакой модели (ищем аналогию, но не ищем модель, правило);
все зависит от меры близости, которую можно выбрать и достаточно неправильной.
Для Pattern Recognition Workbench (CMA) необходимо, чтобы был накоплен большой объем данных (для эффективного использования).
Технология деревьев решений (Decision Tree).
Используется в том случае, если применимо правило: If …Then … (на 2 или 3 ветви). Данная технология представляет собой процесс мышления, идущий от корня к ветвям и листьям. Такие переходы понятны, видны графически, т.е. есть модель, по которой пользователь может сделать выводы о результатах; идет логический вывод.
Однако такие модели значительно зависят от того, какие были выбраны условия (можно выбрать неправильное условие).
На использовании технологии деревьев решений работают продукты See5(С 5.0).
Недостаток технологии деревьев решений заключается в том, что трудно найти оптимальное решение, такая система не дает ответа, какое решение следует считать оптимальным, однако иногда можно найти наилучшее решение.
Технологии ограниченного перебора.
Данные технологии разбивают технологию дерева на более сложные. Суть работы таких технологий заключается в следующем: алгоритм вычисляет частоты комбинаций простых логических событий в подгруппах данных, и на основании вычисленных частот делается вывод о полезности той или иной комбинации. Для этого используются методы WizWhy (Wiz Soft). Они определяют логические «if … then …» правила и выдают результат.
Технология ограниченного перебора используется там, где трудно найти функциональную связь. Стоимость таких технологий – около 4000$.
Технология генетических алгоритмов. Данная технология представляет собой попытку найти решение, путем обращения к генетике.
Эволюционное программирование. Является базой для аналогий – программа эволюции;
Другие.
Рис. 35. Задачи и их решения
Информационные технологии, основанные на знаниях
База знаний – это совокупность знаний, относящихся к некоторой предметной области и формально представленных таким образом, что на их основе можно осуществлять рассуждения.
Типы задач, решаемых с помощью баз знаний:
Интерпретация данных – составление смыслового описания по входным данным.
Диагностика – определение неисправностей по признакам или симптомам (наиболее часто используется в медицине и технологических задачах).
Мониторинг – наблюдение за изменяющимся состоянием объекта и сравнение его показателей с ранее установленными или желаемыми.
Проектирование – разработка объекта с заданными свойствами при соблюдении установленных ограничений.
Прогнозирование – определение последствий наблюдаемых ситуаций.
Планирование – определение последовательности действий, приводящих к желаемому состоянию объекта.
Управление – целенаправленное воздействие на объект для достижения желаемого поведения.
Обучение – объяснение или консультация в определенной области знаний.
Для реализации этих технологий разрабатываются информационные системы.
Типы информационных систем, основанных на знаниях:
Интеллектуальные информационно – поисковые системы.
Информационная система является системой, которая дает прямой ответ на поставленный вопрос.
Интеллектуальная информационная система отличается способностью давать адекватные ответы на запросы, не носящие прямого характера (решаются задачи составления авторефератов системой и соотношения (соответствия) с поставленной темой).
Интеллектуальные информационно – поисковые системы используются, когда недостаточно четко сформулирован запрос, однако не возможно найти однозначный ответ.
Экспертные системы.
Экспертные системы – это компьютерные программы, способные делать логические выводы на основании знаний в конкретной предметной области и обеспечивающие решение специфических задач на профессиональном уровне.
Эксперт – человек, который обладает глубокими знаниями в конкретной области.
Экспертные системы – это системы, помогающие экспертам получить квалифицированное заключение.
Всегда при обработке знаний имеются четко и нечетко формализованные задачи.
Интеллектуальные системы необходимы в первую очередь для решения трудно формализуемых задач, т.е. задач, для которых, во-первых, алгоритмическое решение не известно, во-вторых, если алгоритмическое решение существует, то оно не может быть реализовано из-за ограниченных ресурсов компьютера (быстродействие, объем памяти ограничены); когда цели задач не могут быть выражены в терминах точно определенной целевой функции или не существует точной математической модели задачи.
Рассмотрим структуру ЭС.
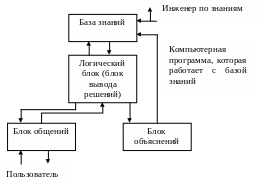
Рис. 36. Общая структура ЭС
Требования к базе знаний.
Знания должны быть специальным образом структурированы (за это отвечает специалист – инженер по знаниям).
Должен существовать решатель–логический блок, в котором вырабатывается экспертное заключение. Он решает все задачи (кроме обучения).
Классификация экспертных систем.
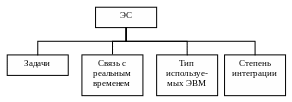
Рис. 37. Классификация ЭС
Классификация по решаемой задаче.
ЭС, обладающие средствами для интеллектуального анализа данных. Для интерпретации данных используются технологии Data Mining.
Диагностические ЭС.
Применяется при диагнозе технической системы, при диагностике в сфере медицины и в сфере финансов, банковского дела.
Причины применения систем заключаются в следующем: задача очень сложная, либо неясная тому, кто принимает решения; при диагнозе технических систем в авиации, космонавтике необходимо применение этих систем.
ЭС мониторинга. Требуют дать объяснение данных в реальном масштабе времени, либо сигнализировать выход параметров за допустимые значения (границы) (в МЧС) (как правило это система распределенная).
ЭС прогнозирования. Системы, которые прогнозируют состояние финансового рынка, курс валют.
ЭС прогнозирования являются первыми моделями аналитического плана, т.е. использующие элемент вероятности.
ЭС для планирования. С помощью таких систем составляется, например, бюджетное планирование, финансирование. Найти ЭС для планирования трудно.
ЭС для управления. Это системы, которые подготавливают варианты возможных решений для управления; системы – подсказчики для руководителей.
По связи с реальным временем.
Статические системы.
К статическим системам относят такие системы, в которых базы данных и данные не меняются с течением времени (по меньшей мере, во время проведения экспертизы). Примером статической системы может служить диагностика технического состояния какого-либо устройства.
Динамические ЭС.
Динамические системы применимы для задачи анализа, когда резко меняется ситуация или база знаний. Для работы такой системы должна существовать обратная связь и быстрые машины.
Квазидинамические ЭС.
К квазидинамическим относятся ЭС, в которых если даже за время осуществления экспертизы параметры меняются, то при повторной экспертизе остаются теми же.
По типам ЭВМ.
ЭС с обычной архитектурой ЭВМ.
ЭС со специальными нейрокомпьютерами – многопроцессорными вычислительными системами.
По степени интеграции с другими программами.
Автономные ЭС. К автономным ЭС относят такие, которые не требуют дополнительных программ для обработки данных.
Гибридные ЭС. К гибридным ЭС относят такие, которые работают с привлечением дополнительных программных средств.
Достоинства ЭС: любому специалисту необходимы системы – подсказчики, которые за малое время могли бы «переваривать» большие объемы данных. Однако существуют определенные сложности в разработке ЭС, т.к. ее надо «научить». Для этого необходимо привлечь эксперта.
Модели представления знаний
К наиболее распространенным моделям представления знаний относятся продукционная, логическая, фреймовая модели и семантические сети.
Продукционные эс
Продукционные ЭС – это ЭС, использующие продукционные модели.
Пример структуры – продукции.
Имя продукции: Интерпретация результатов психологического тестирования
Предусловие: Использовать в первую очередь
Условие: Шкала L<70 баллов
Ядро продукции: Если А, то B: Если (шкала ошибок F - шкала коррекции К)<-11, То вывод сообщения: «Результаты тестирования недостоверны»
Постусловие: Закончить интерпретацию результатов
Интерпретация психологического тестирования.
Ядро продукции описывает преобразования, которые представляют суть продукционного правила.
В продукционной системе база правил и база данных образуют базу знаний. При этом правила представляют собой более долговременную информацию, а данные могут меняться.
Преимущества этой формы представления знаний:
Модульность (совокупность правил представляется посредствам модуля).
Единообразие структуры этих модулей.
Естественность вывода (вывод характерен для человека: если А, то В).
Недостатки:
Недостаточно высокое быстродействие (если есть целая система правил, мы пробегаем по ним и проверяем их все).
Процесс вывода трудно поддается управлению.
Сложно представить родовидовую иерархию понятий.
Фреймовая модель представления знаний
Фреймовая модель возникла в противовес продукционной модели.
Фрейм (Frame – рамка) – единица представления знаний, детали которой могут изменяться в соответствии с текущей ситуацией.
Основными структурными элементами модели являются слот и заполнитель слота.
Структура модели (общий вид:
Имя фрейма: Имя первого слота, значение первого слота
Имя второго слота, значение второго слота
. . . . . . . . . . . . . . . . . . . . . . . . .
Имя k-того слота, значение k-того слота
Пример. Пусть стоит задача составить фрейм, который описывал бы человека.
Описание человека: Дата рождения, . . .
Возраст, . . .
В данном примере значение слота «Дата рождения» является постоянной величиной, а значение слота «Возраст» меняется с течением времени. Иначе говоря, значения слотов могут быть как постоянными, так и вычисляемыми. Таким образом, подобная модель позволяет учитывать и динамические данные. Другими словами, системы фреймов могут быть как статические, так и динамические.
Совокупность фреймов, моделирующая какую-либо предметную область, представляет собой иерархическую структуру, в которую фреймы собираются с помощью родовидовых связей. На верхнем уровне иерархии находится фрейм, содержащий наиболее общую информацию, истинную для всех остальных фреймов.
Фреймы обладают способностью наследовать значения характеристик своих родителей (т.е. фреймов, находящихся на более высоком уровне иерархии).
Пример базы знаний, основанной на фреймах
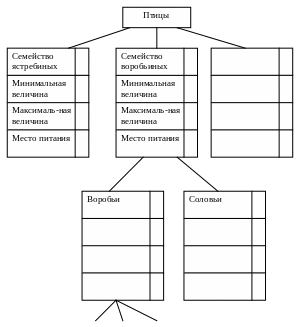
Рис. 38. База знаний о птицах, основанная на фреймах
Для кодирования подобных баз знаний применяют объектно-ориентированные системы программирования.
Преимущество фреймовой модели заключается в том, что значения слотов представляются в такой системе в единственном экземпляре, поскольку включается только в один фрейм. Таким образом, обеспечивается экономное размещение баз знаний в памяти компьютера.
Недостатком фреймовой модели является снижение скорости работы механизма вывода, т.е. системы должны «просканировать» всю структуру на предмет нужной информации.
Логические модели представления знаний
Логическая модель представления знаний создается с использованием свойств логики предикатов. Предикат – это функция, принимающая только два значения: истина и ложь, и предназначенная для выражения свойств объектов или связей между ними;
В логических предикатах применяется термин высказывание. Высказывание – выражение, в котором утверждается или отрицается наличие каких-либо свойств у объекта.
Для именования предметной области используют константы.
Наиболее простым языком логики (в данном случае языком для исчисления высказываний) является язык, в котором отсутствуют переменные, а имеются только константы.
Пример таких высказываний. Пусть имеются две константы – А и B, в качестве связок между константами используются логические функции (и, или, не, или их комбинации).
Например, можно записать:
А – истинно И B – ложно;
А И B – ложно;
А ИЛИ B истинно.
Логика предикатов излагает высказывания в четких математических отношениях и легко программируется, т.е. легко связывается с четкими дискретными методами логики и языками программирования.
Помимо констант
в исчислении предикатов используются
и переменные. Такое исчисление предикатов
записывается с помощью кванторов. К
кванторам относятся, например, следующие
![]() и другие.
и другие.
На основе кванторов и констант можно составлять более сложные высказывания.
На языке теории множеств в самом общем случае логическая модель описывается четырьмя основными множествами:
![]() ,
где
,
где
множество
![]() – множество базовых элементов (или
алфавит формальной системы);
– множество базовых элементов (или
алфавит формальной системы);
множество
![]() – множество синтаксических правил, с
помощью которых можно строить корректные
предложения: правила алгебры логики
(понятия логических предикатов множества,
кванторов);
– множество синтаксических правил, с
помощью которых можно строить корректные
предложения: правила алгебры логики
(понятия логических предикатов множества,
кванторов);
множество
![]() – множество аксиом. Аксиома – это
правильное утверждение, заданное
априорно.
– множество аксиом. Аксиома – это
правильное утверждение, заданное
априорно.
множество
![]() –
множество правил продукции, с помощью
которых можно расширять множество
.
–
множество правил продукции, с помощью
которых можно расширять множество
.
Для программирования с помощью логики применяется в большинстве случаев язык программирования ПРОЛОГ.
Преимущества логической модели представления знаний заключается в возможности непосредственно запрограммировать механизм вывода правильных высказываний.
Недостаток заключается в том, что, увлекаясь логическим, можно уйти от истины (с точки человеческого разума нет смысла), т.е. существует реальная возможность увлеченности математической стороной. Еще один недостаток состоит в том, что большинство интеллектуальных задач характеризуется недостаточной полнотой, неточностью и некорректностью. Это важно, например, в медицине и биологических науках, так как они слабо формализованные. Поэтому в данных областях науки чаще используют методы аналогий и ассоциаций.
Модели представления знаний на основе семантических сетей
В моделях представления знаний на основе семантических сетей знания представляются в виде сетевых структур. Элементами, с помощью которых создается сетевая структура, являются вершина сети и дуги. В качестве вершин используются понятия, факты, объекты, события и т.д.; в качестве дуг – отношения, которыми вершины связаны между собой. К наиболее распространенным типам отношений относятся следующие: быть элементом класса; иметь; являться следствием (для причинно-следственных отношений); иметь значение и т.д.
Пример семантической сети из области техники.

Рис. 39. Семантическая сеть
Преимущества модели представления знаний на основе семантических сетей: 1) с помощью этой модели могут быть представлены родовидовые отношения, а, следовательно, возможно и наследование свойств от родителей; 2) простота и наглядность описания предметной области.
Недостатки модели представления знаний на основе семантических сетей: снижение скорости работы механизма вывода, т.е. системы должны «просканировать» всю структуру на предмет нужной информации (т.е. те же недостатки, что и у фреймовых моделей представления знаний), а также понижение быстродействия.
Другие методы представления знаний
В качестве других методов представления знаний можно указать представление знаний по примерам. При использовании такого метода база знаний заполняется следующим образом: инженер по знаниям берет задачу и заполняет матрица из совокупности задач и правильных решений. Можно построить программу с поиском аналогичной задачи (метод на основе примеров). Такой метод применяется, например, в области медицины и в юридической практике.
Достоинством метода представления знаний по примерам является простота данного способа (т.е. для данной задачи находится метод и вносится в память).
К недостатку можно отнести отсутствие интеллектуальной гибкости.
Сетевые технологии Принципы построения глобальной сети Internet
Internet – международная сеть. Сеть Internet объединяет как глобальные, так и локальные сети. Сеть Internet возникла из области военной сферы.
Центральным звеном сети является семейство протоколов межсетевого обмена при построении – протоколы TCP/IP.
TCP (Transmission Control Protocol) – базовый транспортный протокол, предназначенный для передачи сообщений.
IP (Internet Protocol) – базовый сетевой протокол.
Главной задачей при разработке сети Internet было определение реальной возможности создания сетей, работающих с разными ресурсами, и чтобы была возможна маршрутизация.
Вся глобальная сеть и протоколы базируются на стандарте OSP (Open System Integration) – стандарт взаимодействия открытых систем, т.е. она открыта для дальнейшего развития.
Архитектура протоколов, которые используются в сети Internet.
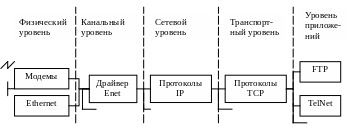
Рис. 40. Архитектура протоколов, используемых в сети Internet
Модем – устройство, которое обеспечивает преобразование аналогового сигнала в цифровой.
Драйвер – программа, непосредственно взаимодействующая с сетевым адаптером.
Карта Ethernet – физическое техническое устройство, с помощью которого компьютер подключается к сети.
При использовании устройств Ethernet и протоколов типа IP каждая ЭВМ имеет минимум один адрес Ethernet и один IP-адрес. IP-адрес предназначается для каждого драйвера сетевого интерфейса. Этот IP-адрес должен быть уникален в рамках всей глобальной сети.
Принципы построения ip-адресов
IP-адрес представляет собой четырехбайтовую последовательность. Принято каждый байт каждой последовательности записывать в виде десятичного числа. Например, IP-адрес Курчатовского института выглядит следующим образом: 144.206.160.32.
IP-адрес состоит из двух частей: адреса сети и адреса хоста.
Хостом называется главная машина, или ЭВМ, которая имеет сетевую карту и свой сетевой интерфейс.
Существует 5 классов IP-адресов, которые отличаются друг от друга количеством битов, отведенных на адрес сети и адрес хоста.
Табл.5. Классы IP-адресов
|
0 7 |
8 15 |
16 23 |
24 31 |
Количество возможных сетей |
Количество возможных узлов |
||||
Класс A |
0 |
Номер сети |
Номер хоста |
126 |
16777214 |
|||||
Класс B |
10 |
Номер сети |
Номер хоста |
16382 |
65534 |
|||||
Класс C |
110 |
Номер сети |
Номер хоста |
209715 |
254 |
|||||
Класс D |
1110 |
Групповой адрес |
– |
228 |
||||||
Класс E |
11110 |
Зарезервировано |
– |
227 |
||||||
Адреса класса A предназначены для использования в больших сетях общего пользования.
Адреса класса B используются в сетях среднего размера (к ним относятся, например, сети больших и сверхбольших компаний).
Адреса класса C предназначены для использования в сетях небольших компаний и фирм (к классу C относятся IP-адреса, начиная с 192).
Адреса класса D используются для обращения к группам или отдельным компьютерам.
Доменная адресация в сети.
Для облегчения взаимодействия в сети стали применять доменную адресацию. Для этого была придумана система для назначения доменных адресов – DNS (Domain Name System).
В начале 80-х годов были определены первые домены верхнего уровня, означающие назначение хоста организации: com – коммерческая организация; edu – гражданское обучение; net – сетевая компания и т.д. Затем появились национальные домены, например, su – СССР,ua – Украина, tw – Тайвань, ru – Россия.
Например, дерево доменной организации DNS может выглядеть следующим образом: kiae.su.
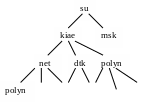
Рис. 41. Пример доменной адресации в сети
Электронная почта в Internet Принцип организации электронной почты в сети Internet
Для того, чтобы работать с электронными сообщениями в сети Internet был разработан специальный протокол прикладного уровня SMTP (Simple Mail Transfer Protocol) – протокол передачи почты. В своей работе он использует транспортный протокол TCP.
Схема взаимодействия по протоколу.
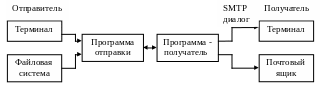
Рис. 42. Схема взаимодействия с использованием протокола SMTP в сети Internet
Также используется протокол UUCP (Unix – Unix – Copy Protocol) – протокол, который хорошо подходит для использования в телефонных линиях связи (в России).
«Stop - Go» – почтовое сообщение, передаваемое по цепочке сервера от одной машины к другой, пока не достигнет получателя. При этом время доставки увеличивается. Принцип работы электронной почты с использованием протокола «Stop - Go» ближе подходит к режиму Off-Line.
SMTP – работа производится в режиме On-Line –режиме реального времени, т.е. протокол ищет непосредственно адрес получателя.
Система почтовых адресов
Система почтовых адресов базируется на доменном адресе машины, подключенной к сети. Почтовый адрес состоит из двух частей: идентификатора, стоящего перед @, и доменного адреса машины. Например, ИДП@SAM или paul@polyn.net.kiae.su.
Также используется и другой почтовый протокол – POP3.
POP3 (Post Office Protocol, версия 3) – протокол обмена почтовой информацией, служащий для разбора почты из почтовых ящиков пользователя на рабочие места.
Если пользователи отправляют почту по сети при помощи протокола SMTP, то они получают почту из почтовых ящиков на почтовом сервере в свои локальные файлы по протоколу POP3.
Схема работы с почтовым сервером.
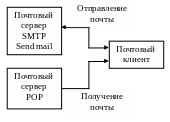
Рис. 43. Схема работы с почтовым сервером на основе протоколов SMTP и POP3
Доступ к информационным ресурсам Internet (краткая характеристика)
Ресурсами сети называется совокупность информационных технологий и баз данных, которые становятся доступными с помощью этих технологий.
Наиболее часто используемые информационные ресурсы приведены в таблице 6.
Табл.6. Системы сети Internet
Название |
Описание |
E – mail |
Система электронной почты. |
Usenet |
Система телеконференций, с помощью которой организуется международное общение по интересующим пользователя темам. |
FTP (File Transfer Protocol) |
Система файловых архивов. Начала создавалось на первых этапах создания Internet. В данной системе есть источники БД и баз знаний. Однако для получения файлов с помощью данной системы необходимы свои программы. |
WWW |
Распределенная гипертекстовая информационная система, использующая гипертекст и гипермедиатекст. Гипертекст – это особый способ представления информации. |
Who Is |
Справочная система, справочная служба для получения коротких справок. |
Gopher |
БД |
Основные компоненты технологии www (World Wide Web)
Web-сервер использует гипертекстовую технологию (до этого гипертекст не находил широкого применения).
Гипертекст – это легкая в использовании, однако чрезвычайно мощная система связанных слов и фраз, позволяющая осуществлять навигацию между страницами, и которая может носить нелинейный характер. Данное понятие было дополнено и преобразовано в гипермедиа.
Гипермедиа – это среда, основана на внутренних взаимосвязях, развивающая концепцию гипертекста за счет включения в нее графики, видео и звука.
Основные компоненты технологии WWW:
Язык гипертекстовой разметки документов HTML (Hyper Text Mark Language).
Текст необходимо разметить, указать формат шрифта ссылок, нанести разметки медийных компонентов.
W eb-документы представляют собой файлы, записанные в коде ASCII (американский стандарт кодирования и передачи информации). Данный код позволяет просто кодировать текстовые документы и все знаки, сопутствующие тексту. Большинство текстовых редакторов работают с этой кодировкой. При этом размерность файла коротка, что позволяет экономить на объеме документов.
В качестве базы для разработки этого языка был выбран язык SGML (Standard Generalized Markup Language), затем модифицированный в язык HTML первоначально в версию 1.0, а потом в версию 4.0. В настоящее время очень много документов используют также язык XML – расширенный язык разметки данных.
Возможности языка HTML.
Данный язык:
дает возможность осуществлять разметку, позволяет представлять новости, почту;
позволяет использовать меню с опциями;
представляет результаты запросов к БД;
структурированные документы со встроенной графикой.