

1.2 Суперкомп’ютери
Векторні обчислення
Не дивлячись на те, що продуктивність сучасних обчислювальних машин багатократно виросла, існує клас задач, для яких їх можливості залишаються недостатніми. Це задачі зв’язані з моделюванням фізичних процесів в різних середовищах, задачі аеродинаміки, сейсмології, метеорології, ядерної фізики, фізики плазми і т.д.
Характерною особливістю згаданих задач є виконання однакових обчислювальних процедур з великими масивами числових даних, які описують багатомірні фізичні поля в динаміці. Для розв’язання подібних задач розробляється окремий клас обчислювальних систем, що отримав назву суперкомпютерів. Теми повинні володіти можливістю виконувати сотні мільйонів арифметичних операцій в секунду над числами в форматі з плаваючою крапкою. Вартість існуючих систем такого класу досягає 10-15 млн. доларів. На відміну від великих обчислювальних систем (майнфреймів), які проектуються в розрахунку на мультипрограмний режим роботи і інтенсивний обмін інформацією з периферійними пристроями, суперкомп’ютери оптимізовані з врахуванням особливостей числової обробки великих і надвеликих масивів даних.
Із-за великої вартості суперкомп’ютерів і їх спеціализації на виконанні задач певного класу ринок таких систем обмежений. Вони використовуються тільки у великих науково-дослідних центрах, які працюють, в основному, над реалізацією грандіозних наукових проектів. Однією з таких проблем на сьогоднішній день є керований термоядерний синтез. Не дивлячись на великі обчислювальні можливості сучасних суперкомп’ютерів, потреби наукових досліджень весь час зростають.
В рамках цього напряму розвивається клас комп’ютерів, орієнтованих на операції над векторами, - так звані матричні процесори (array processor). Вини використовуються як співпроцесори для ефективної обробки векторних фрагментів програм.
Виконання векторних операцій
В комп’ютері загального призначення обробка векторів або масивів чисел у форматі з плаваючою крапкою організовується у виді циклічної процедури, а при чому в кожному циклі обробляється черговий елемент масиву.
Приклад: Дано два вектори чисел А і В. Необхідно додати їх і помістити результат у вектор С. Для цього потрібно виконати 3 операції додавання:

Як можна прискорити виконання подібних операцій? Необхідно впровадити паралелізм в тій або іншій формі.
Існує кілька підходів впровадження ідей паралельного виконання операцій обробки векторів.
Приклад 1: Перемножити квадратні матриці А×В=С розмірністю (n×n). Кожний елемент матриці обчислюється по формулі:
![]() .
.
Наведемо фрагмент програми на мові Паскаль, яку можна виконати на любому скалярному процесорі загального призначення:
For i:=1 to n do
For j:=1 to n do
Begin
C(i,j) := 0;
For k:=1 to n do
C(i,j) := C(i,j) + A(i,k)*B(k,j);
End;
Один із методів підвищення продуктивності виконання подібних обчислень отримав назву векторної обробки. Цей метод допускає, що в програмі можна оперувати з одномірними векорами даних.
Приклад 2: Наведемо фрагмент програми на мові Паскаль, в якому реалізована нова форма операторів, яка дозволяє специфікувати операції над векторами:
For i:=1 to n do
Begin
C(i,j) := 0;(j = 1,n)
For k:=1 to n do
C(i,j) := C(i,j) + A(i,k)*B(k,j);(j = 1,n)
End;
Запис виду (j = 1,n) означає, що операції над елементами з всіма індексами j в заданому інтервалі будуть виконуватись як єдина процедура. У представленому фрагменті всі елементи i-го рядка обчислюються паралельно. Кожний елемент в рядку представляє собою суму, доданки якої обчислюються послідовно. Але навіть у цьому випадку потрібно тільки N2 операцій вектороного множення у порівнянні з N3 операціями скалярного множення у попередньому варіанті.
Паралельна обробка
Такий підхід допускає, що у нашому розпорядженні є N незалежних процесорів, які працюють паралельно. Для того щоб ефективно їх використати, потрібно якимось чином вказати, які обчислення повинні виконувати ці процесори. Для цього в мові програмування є два типи директив. Директива FORK n вказує, що паралельно виконувані процеси починаються з оператора програми, поміченого міткою n. Кожне виконання директиви FORK породжує новий процес. Дирекива JOIN виконує роль зворотну до FORK. Вираз JOIN N вказує, що N незалежних процесів зливаються в один, який продовжується оператором, який слідує зразу за JOIN. Координація такого зливання процесів покладається на операційну сисиему, і виконання загального процесу не продовжується до тих пір, поки N паралельних незалежних процесів не завершиться.
Приклад 3: Наведемо текст програми паралельної обробки, який по формі мало відрізняється від першого прокладу. Але в даному випадку кожний стовпець С обчислюється окремим процесором і, як наслідок, елементи кожного рядка матриці обчислюються паралельно.
For j:=1 to n do
FORK 100;
J = N;
For i:=1 to n do
Begin
C(i,j) := 0;
For k:=1 to n do
C(i,j) := C(i,j) + A(i,k)*B(k,j);
End;
JOIN N;
Вище описані підходи до логічної організації векторних обчислень. Тепер розглянемо якою має бути структура процесорів, здатних реалізувати ці підходи. Можна виділити три основні категорії:
Процесор з конвеєрними АЛП;
Процесор з паралельними АЛП;
Паралельні процесори.
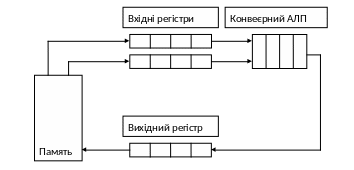
На рис. 1 наведені схеми двох перших варіантів. У наведеній схемі концепція конвеєра поширюється і на організацію АЛП.
Оскільки арифметичні операції з числами з плаваючою крапкою досить складні, то можна розбити кожну операцію на окремі фази і виконувати ці фази паралельно з різними числами (Рис. 2).
Операція додавання розділена на чотири фази:
порівняння порядків – С;
зсув мантиси одного із доданків – S;
додавання мантис – А;
нормалізація суми – N.
а)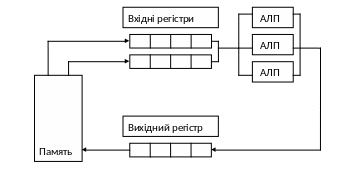
б)
Організація векторних обчислень:
а - конвеєрний АЛП;
б – паралельні АЛП.
Послідовності чисел (векторні доданки) подаються на вхід блоку виконанння першої фази. В дальнійшому, по мірі того як процес обробки просувається, у блоках виконання різних фаз опиняються чотири пари чисел – елементів сумування векторів.
Векторной співпроцесор IBM 3090
Хорошим прикладом використання конвеєрного АЛП для обробки векторів є векторний співпроцесор IBM 3090, розроблений як один з компонентів сімейства IBM S/370. Його векторні функції схожі на ті, що реалізовані в суперкомп’ютері CRAY.
В співпроцесорі широко використовуються векторні регістри. Кожний векторний регістр є набором скалярних регістрів. Для обчисленні векторної суми С = А + В вектори А і В завантажуються в два векторні регістри. Не дочікуючи завершення завантаження, дані з цих регістрів передаються в АЛП, а результат поступає у вихідний регістр. Накладання фаз операцій завантаження і обчислення суттєво прискорює виконання всієї операції.
Структура співпроцесора
Застосування конвеєрного АЛП для виконання операцій з векторами забезпечує підвищення швидкодії в порівнянні з циклічним виконанням скалярних арифметичних операцій, чому сприяють наступні умови:
Фіксована структура векторних даних дозволяє замінити службові операції в тілі циклу більш швидкими внутрішніми операціями в співпроцесорі, які реалізуються апаратно або за допомогою мікропрограм.
Доступ до даних і обчислення можуть виконуватись паралельно.
Використання векторних регістрів для зберігання проміжкових результатів дозволяє уникнути додаткових звернень до пам’яті.