

§ Объекты в JavaScript
Введение
Предшествующая лекция о функциях вводит концепцию функций, учит, как лучше организовать и повторно использовать код, объединяя отдельные действия в логические фрагменты, которые можно вызывать, когда понадобится. Теперь, когда вы освоились с этими существенными компонентами программирования JavaScript, я бы хотел расширить их применение, вводя понятие объектов. Объекты позволяют собрать вместе имеющие отношение друг к другу наборы функциональности, определенные как функции, и объединить их в логически связанный пакет, который можно использовать (передавать и ссылаться на него) как единую сущность. Эта возможность с практической точки зрения имеет очень важное влияние на код, который можно написать, даже если это и звучит в данный момент несколько абстрактно.
Можно было этого не заметить, но неявно вы уже сталкивались с объектами в этой серии статей. Здесь я представлю более явное описание того, как объекты работают в JavaScript, и объясню, как можно увеличить выразительность и повторное использование кода с их помощью.
Лекция имеет следующую структуру:
Зачем нужны объекты?
Знакомая территория
Создание объектов
Ссылка на себя
Объекты как ассоциативные массивы
Объектный литерал
Заключение - еще много надо изучить
Дополнительное чтение
Контрольные вопросы
Примечание: Существует пример, доступный для скачивания и выполнения, который содержит код вычисления площади треугольника, как с объектами, так и без них. Этот код создается ниже в ходе изложения лекции. Выполните пример с объектами треугольниками (http://dev.opera.com/articles/view/objects-in-javascript/triangle_area.html).
Зачем нужны объекты?
Единственной наиболее важной причиной внимания к объектам является возможность с их помощью улучшить представление в коде реализуемых данных и процессов. В качестве тривиального примера рассмотрим, как можно было бы написать код, который выполняет некоторую работу с треугольником.
Вы знаете, что треугольник имеет три стороны, поэтому для работы с определенным треугольником, очевидно, необходимо создать три переменные:
// Это треугольник.
var sideA = 3;
var sideB = 4;
var sideC = 5;
И вот мы получили треугольник! Но не совсем треугольник, не так ли? На самом деле мы просто создали три переменные, которые необходимо отслеживать по отдельности, и комментарий, чтобы напомнить себе, что имеется в виду. Это просто не так уж ясно и не так уж удобно использовать, как могло бы быть. Но неважно, давайте продолжим и рассмотрим, как можно выполнить какие-нибудь вычисления с таким "треугольником". Чтобы найти его площадь, необходимо написать функцию следующего вида:
function getArea( a, b, c ) {
// Возвращает площадь треугольника, используя формулу Герона
var semiperimeter = (a + b + c) / 2;
var calculation = semiperimeter * (semiperimeter - a) * (semiperimeter - b) * (semiperimeter - c);
return Math.sqrt( calculation );
}
alert( getArea( sideA, sideB, sideC ) );
Легко видеть, что нам нужно передать в функцию всю информацию о треугольнике, чтобы она выполнила какие-то вычисления. Действия, связанные с треугольником, совершенно не связаны с данными треугольника, даже хотя они на самом деле не имеют особого смысла в отдельности.
Более того, я использовал подходящее общее имя для функции и каждой из переменных: getArea, sideA, и т.д. Что произойдет, если на следующей неделе обнаружится, что требуется расширить программу, чтобы включить прямоугольник? Я бы хотел использовать переменные sideA и sideB для сторон прямоугольника, но эти имена переменных уже заняты. Я мог бы использовать side1 и side2, но я готов поспорить, что вы можете увидеть, почему это рецепт для создания путаницы и бедствия. Вероятно, я бы закончил выбирая rectangleSideA и rectangleSideB, и, чтобы оставаться последовательным, я бы также должен был вернуться назад и изменить весь уже написанный код для треугольников, чтобы использовать triangleSideA и т.д., что создает некоторые возможности для ошибок. То же самое происходит с именем функции. Я бы хотел использовать getArea для обеих фигур, так как это концептуально одни и те же вычисления, но я не могу. Должен быть лучший способ для представления моих данных!
Точно также как имеет смысл создать функцию с хорошо определенным именем, которая связывает вместе последовательность команд в одно действие, имеет смысл создать здесь объект, который соединяет вместе все "вещи" в одну сущность. Вместо ограничения исходно-поддерживаемыми простыми типами данных JavaScript (строками, числами, логическими значениями, и т.д.), объекты позволяют создавать и использовать свои собственные объединения любого числа переменных любого типа. Эта не связанная формой гибкость позволяет создавать структуры, которые отображаются в некоторой степени непосредственно в "вещи", которые вас интересуют при создании программы, и использовать их непосредственно в коде, почти также как используются простые типы данных. Здесь я собираюсь создать объекты треугольника и прямоугольника, каждый из которых содержит все необходимые данные для разумной работы с фигурами, а также все действия, которые желательно с ними выполнять. Помня об этой цели, рассмотрим немного синтаксиса.
Знакомая территория
Если взглянуть на последний пример с функциями из предыдущей лекции, можно увидеть фрагменты кода следующего вида:
var obj = document.getElementById( elementID );
и
obj.style.background = 'rgb('+red+','+green+','+blue')';
Вы удивлены! Мы использовали объекты, даже не зная об этом! Давайте рассмотрим подробнее два эти фрагмента, чтобы начать изучение синтаксиса объектов JavaScript.
Код var obj = document.getElementById( elementID ) должен выглядеть в некоторой степени знакомым. Вы знаете, что скобки в конце команды означают, что выполняется некоторая функция, и можно видеть, что результат вызова функции сохраняется в переменной с именем obj. Единственным новым элементом здесь является точка в середине. Оказывается, что эта запись с точкой используется в JavaScript для предоставления доступа к данным внутри объекта. Точка (.) является просто оператором, который помещается между его операндами, также как + и -.
В соответствии с соглашением хранящиеся в объекте переменные, обращение к которым происходит с помощью оператора точки, обычно называют свойствами. Свойства, которые будут функциями, называются методами. Нет никакого различия для значения этих слов, методы являются просто функциями, а свойства - переменными.
Оператор точки ожидает объект слева от себя, и имя свойства справа, применяя это к фрагменту кода, можно сказать, что происходит обращение к методу getElementById встроенного объекта document (о котором вы прочтете значительно больше в следующей лекции, посвященной обходу DOM).
Следующий фрагмент кода немного интереснее: он содержит две точки. Одним из действительно привлекательных моментов поддержки объектов в JavaScript является понятие сцепления точек, чтобы погрузиться внутрь комплексных структур. Короче говоря, можно соединять объекты цепочкой таким же образом, как можно выполнить var x = 2 + 3 + 4 + 5 и ожидать в результате 14; ссылки на объекты просто разрешают себя слева направо (точным научным языком это означает, что оператор точки в JavaScript является "лево- ассоциативным инфиксным оператором"). В данном случае вычисляется obj.style, разрешаясь в объект, после чего происходит обращение к его свойству background. При желании можно сделать это в коде явно, добавляя скобки: (obj.style).background.
Создание объектов
Чтобы создать собственный объект треугольника, мы создадим его явно, используя следующий синтаксис:
var triangle = new Object();
triangle является теперь пустой основой, ожидающей создания некоторой конструкции с тремя сторонами. Можно сделать это, добавляя в объект свойства с помощью оператора точки:
triangle.sideA = 3;
triangle.sideB = 4;
triangle.sideC = 5;
На самом деле ничего специального для добавления новых свойств в объект делать не требуется. Когда JavaScript вычисляет оператор точки, он на самом деле действует достаточно снисходительно. Если вы попытаетесь задать свойство, которое не существует, JavaScript создаст это свойство. Если вы попытаетесь прочитать свойство, которого там нет, JavaScript вернет "undefined" ("не определено"). Это удобно, но может скрывать при неосторожном обращении ошибки, поэтому следите за опечатками!
Добавление методов работает аналогично - вот пример:
triangle.getArea = function ( a, b, c ) {
// Возвращает область треугольника, используя формулу Герона
var semiperimeter = (a + b + c) / 2;
var calculation = semiperimeter * (semiperimeter - a) *
(semiperimeter - b) * (semiperimeter - c);
return Math.sqrt( calculation );
}; // Обратите внимание на точку с запятой в этом месте; она
// обязательна.
Если вы полагаете, что это очень похоже на определение функции, то вы не ошиблись: я просто удалил полностью имя функции. JavaScript имеет концепцию анонимной функции, которая не имеет своего собственного имени, но хранится вместо этого в переменной, также как и любое другое значение. В данном коде создается анонимная функция, которая хранится в свойстве getArea объекта triangle. Объект затем всегда имеет функцию при себе, также как и любое другое свойство.
Ссылка на себя
Одной из целей создания объекта triangle было создание связи между данными треугольника и действиями, которые можно выполнить с данными. Однако пока это еще не реализовано. Вы сразу заметите, что метод triangle.getArea по прежнему требует, чтобы ему передавались данные о длине сторон, когда он выполняется, что приводит к коду следующего вида:
triangle.getArea(triangle.sideA, triangle.sideB, triangle.sideC);
Я думаю, что это лучше, чем код, который был в начале лекции, так как он ясно выражает отношения между данными и действием. Это отношение, однако, означает, что мы не должны сообщать методу, с какими значениями работать. Он должен сам собирать данные об объекте, в котором находится, и использовать эти данные, не требуя ввода вручную.
Секрет находится в ключевом слове this, которое можно использовать внутри определения метода, чтобы ссылаться на другие свойства и методы этого же объекта. Переписывая метод getArea соответствующим образом, мы получаем следующий код:
triangle.getArea = function () {
// Возвращает площадь треугольника, используя формулу Герона
var semiperimeter = (this.sideA + this.sideB + this.sideC) / 2;
var calculation = semiperimeter * (semiperimeter - this.sideA) * (semiperimeter - this.sideB) *
(semiperimeter - this.sideC);
return Math.sqrt( calculation );
}; // Обратите внимание здесь на точку с запятой, она обязательна.
Как можно видеть, это работает в некоторой степени как зеркало. Когда выполняется метод getArea, он посмотрит на свое отражение, чтобы считать свои свойства sideA, sideB, и sideC. Он может использовать это в вычислениях, вместо использования внешнего ввода.
Примечание: Это немного сверхупрощенное изложение. this не всегда ссылается на объект, в котором определен метод, но наоборот может изменяться на основе определенных контекстов. Прошу прощения за некоторую неясность здесь, но это немного за пределами данной лекции. Зная об этом, вы в остальном можете быть уверены, что в использованном здесь контексте this всегда будет указывать на объект triangle.
Объекты как ассоциативные массивы
Оператор точки является не единственным способом доступа к свойствам и методам объекта, они могут быть доступны вполне эффективно с помощью записи с индексом, которая может быть знакома из предыдущего обсуждения массивов. Вкратце, можно представлять себе объект как ассоциативный массив, который отображает строку в значение, таким же образом, как обычный массив отображает число в значение. Используя такую запись, можно переписать triangle другим способом:
var triangle = new Object();
triangle['sideA'] = 3;
triangle['sideB'] = 4;
triangle['sideC'] = 5;
triangle['getArea'] = function ( a, b, c ) {
// возвращает площадь треугольника, используя формулу Герона
var semiperimeter = (a + b + c) / 2;
var calculation = semiperimeter * (semiperimeter - a) * (semiperimeter - b) * (semiperimeter - c);
return Math.sqrt( calculation );
}; // Обратите внимание на точку с запятой, она здесь обязательна
На первый взгляд это может показаться избыточным. Почему не использовать просто запись с точкой? Преимущество этого нового синтаксиса в том, что имя свойства не является жестко закодированным в программе. Можно использовать переменные для определения имен свойств, что означает, что можно создавать по-настоящему гибкие команды, которые делают различные вещи в зависимости от контекста. Например, можно создать функцию, которая сравнивает два объекта, чтобы проверить, не используют ли они общее свойство:
function isPropertyShared( objectA, objectB, propertyName ) {
if (
typeof objectA[ propertyName ] !== undefined
&&
typeof objectB[ propertyName ] !== undefined
) {
alert("Оба объекта имеют свойство с именем " + propertyName + "!");
}
}
Такую функцию было бы просто невозможно написать при базовом способе использования записи с точкой, так как потребуется явно написать имена свойств для проверки в коде программы. Такой синтаксис используется очень часто.
Примечание: Ассоциативный массив называется "hash" в Perl, "hashtable" в C#, "map" в C++, "hashmap" в Java, "dictionary" в Python, и т.д. Это очень мощная и фундаментальная концепция в программировании, и вы вполне можете быть с ней знакомы под другим именем.
Объектный литерал
Давайте внимательнее посмотрим на код, который, кажется, вполне знакомым:
alert("Hello world");
Можно сразу определить alert как функцию, которая вызывается с одним аргументом: строкой "Hello world". Я хотел бы обратить здесь внимание на то, что не требуется писать:
var temporaryString = "Hello world";
alert(temporaryString);
JavaScript просто понимает, что все, содержащееся внутри пары двойных кавычек (" "), должно интерпретироваться как строка, и делает всю необходимую фоновую работу, необходимую для правильной работы такой записи. Создается строка и передается прямо в функцию. Формально "Hello world" ` называется строковым литералом ; вы, чтобы создать строку, просто вводите все, что должно в ней находиться.
JavaScript имеет аналогичный синтаксис для "объектных литералов ", который позволяет создавать свои собственные объекты без каких-либо синтаксических накладных расходов. Давайте перепишем созданный выше объект еще третьим способом, теперь как объектный литерал.
var triangle = {
sideA: 3,
sideB: 4,
sideC: 5,
getArea: function ( a, b, c ) {
// Возвращает площадь треугольника, используя формулу Герона
var semiperimeter = (a + b + c) / 2;
var calculation = semiperimeter * (semiperimeter - a) * (semiperimeter - b) * (semiperimeter - c);
return Math.sqrt( calculation );
}
};
Синтаксис четкий: объектный литерал использует фигурные скобки для обозначения начала и конца объекта, который содержит произвольное количество разделенных запятыми пар "имяСвойства: значениеСвойства". Это делает достаточно простым создание структур для использования в программах без утомительного повторения имени объекта на каждой строке.
Однако надо следить за одной вещью: достаточно распространенная ошибка состоит в размещении запятой после последнего элемента в списке свойств объектного литерала (в данном случае после определения getArea ). Размещайте запятую только между свойствами - дополнительная запятая в конце будет вызывать ошибки. Особенно при повторном обращении к коду для добавления или удаления значений, нужно быть очень осторожным, чтобы сохранить запятые на правильных местах.
Заключение - еще много надо изучить
На самом деле мы только прикоснулись к поверхности возможностей и ограничений объектов в JavaScript. После прочтения вы должны без проблем создавать свои собственные объекты, добавляя свойства и методы, и использовать их простым способом, используя ссылки на себя. Там существует намного больше, но все это пока не настолько существенно. Эта лекция должна показать начало пути и дать инструменты, необходимые для понимания кода, с которым придется встретиться, когда вы глубже окунетесь в предмет изучения.
Дополнительное чтение
Object Oriented JavaScript (http://nefariousdesigns.co.uk/archive/2006/05/object-oriented-javascript/): Хорошее введение в более сложные объектно-ориентированные концепции в JavaScript.
Private Members in JavaScript (http://javascript.crockford.com/private.html): Плодотворное обсуждение Дугласом Крокфордом реализации инкапсуляции в JavaScript.
Scope in JavaScript (http://www.digital-web.com/articles/scope_in_javascript/): Более подробное обсуждение особенностей применения ключевого слова this в различных контекстах.
§ DOM (Document Object Model)
Введение
В Web трудно найти пример полезного кода JavaScript, который не взаимодействует некоторым образом с документом HTML. Говоря в общем, коду необходимо прочитать значения со страницы, обработать их некоторым образом, и затем сгенерировать вывод в форме видимых изменений информационного сообщения. В качестве следующего шага по направлению к созданию быстрых интерфейсов для страниц и приложений эта лекция и следующая знакомит с Объектной моделью документа (DOM - Document Object Model), которая предоставляет механизм для проверки и управления создаваемыми слоями семантики и представления.
После прочтения этой лекции вы будете хорошо понимать, что такое DOM, и как ее можно использовать для перемещения по странице HTML, чтобы точно найти место, в котором необходимо получить некоторые данные или сделать изменения. Следующая лекция в этой серии (Создание и изменение HTML) описывает методы, с помощью которых можно манипулировать данными на странице, изменяя значения или создавая полностью новые элементы и атрибуты.
Данная лекция имеет следующую структуру:
Высаживаем семена
Растим деревья
Узлы
С ветки на ветку
Прямой доступ
Заключение
Контрольные вопросы
Высаживаем семена
DOM, как можно понять из названия Объектная модель документа, является моделью документа HTML, которая создается браузером, когда он загружает web-страницу. JavaScript имеет доступ ко всей информации этой модели. Давайте вернемся на несколько шагов назад и рассмотрим, что в действительности моделируется.
Когда создается страница, цель разработчика состоит в добавлении смысла к исходному контенту, отображая его в имеющиеся теги HTML. Единицей контента является параграф, поэтому используется тег p, следующей единицей является ссылка, поэтому используется тег а, и т.д. Также выполняется кодирование отношений между элементами: каждое поле input (ввода) имеет label (метку), и они могут объединяться в fieldset. Более того, можно выйти немного за пределы этого базового набора тегов HTML, добавляя, где необходимо, атрибуты id и class, чтобы насытить страницу дополнительными структурами, которые можно использовать для стилевого оформления или манипуляций. Когда эта базовая структура HTML создана, используется CSS для придания этой чистой семантики стилевого представления. И вот, пожалуйста, создана страница, которая доставляет пользователям настоящее удовольствие.
Но это не все. Создан документ просто сочащийся мета-информацией, которой можно манипулировать с помощью JavaScript. Можно находить определенные элементы или группы элементов и удалять, добавлять, и модифицировать их в соответствии с определенными пользователем переменными, можно находить информацию о представлении (CSS) и изменять стили на лету. Можно проверять информацию, которую пользователь вводит в формы, и делать множество других вещей. Чтобы можно было делать это с помощью JavaScript, требуется доступ к информации, которую DOM предоставляет JavaScript.
Важно также отметить, что хорошо структурированный HTML и CSS формируют основу, из которой вырастает модель страницы для JavaScript. Эта модель для плохо сконструированного документа будет отличаться нежелательным образом от ожидаемой, и будет вести себя по-разному в разных браузерах. Поэтому жизненно необходимо, чтобы коды HTML и CSS были правильно сформированы и соответствовали требованиям (были валидными), что обеспечит получение для JavaScript той модели, которая должна быть.
Растим деревья
После создания и оформления документа следующий шаг состоит в передаче его браузеру для вывода пользователям. Здесь начинает играть свою роль DOM. Считывая написанный документ, браузер динамически генерирует DOM, который можно использовать в программах. В частности DOM представляет страницу HTML как дерево, почти таким же образом, как можно представить себе генеалогическое семейное дерево пользователя. Каждый элемент на странице представлен в DOM как узел, с ветвями, соединенными с элементами, которые он непосредственно содержит (его потомки), и с элементом, в котором он непосредственно содержится (его предок). Давайте рассмотрим простой документ HTML, чтобы яснее представить себе эти отношения:
<html>
<head>
<title>This is a Document!</title>
</head>
<body>
<h1>This is a header!</h1>
<p id="excitingText">
This is a paragraph! <em>Excitement</em>!
</p>
<p>
This is also a paragraph, but it's not nearly as exciting as the last one.
</p>
</body>
</html>
Как можно видеть, весь документ содержится в элементе html. Этот элемент непосредственно содержит два других: head и body. Они показаны в нашей модели как его потомки, и каждый из них указывает на html, как на предка. И так далее, вниз по иерархии документа, где каждый элемент указывает на своих непосредственных потомков, и на своего непосредственного предшественника предка.
title является потомком head.
body имеет три потомка - два элемента p и элемент h1.
Элемент p с id="excitingText" имеет своего собственного потомка - элемент em.
Текстовое содержимое элементов (например, "This is a Document!") также представлено в DOM как текстовые узлы. Они не имеют собственных потомков, но указывают содержащие их элементы как предков.
Поэтому получаемая иерархия DOM для показанного выше документа HTML визуально представляется следующим образом:
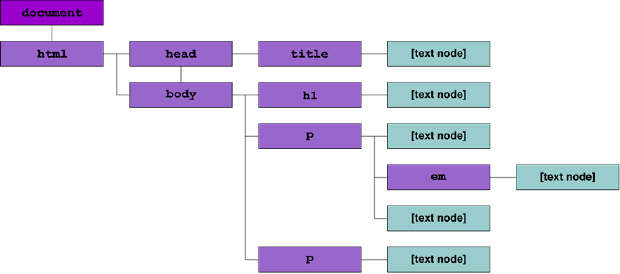
увеличить изображение Рис. 8.1. Документ HTML, представленный визуально как дерево DOM.
Это прямолинейное отображение из документа HTML в древовидную структуру, которая сжато представляет прямые отношения между элементами на странице, делая иерархию понятной. Однако можно заметить, что здесь добавлен узел, помеченный document, выше узла html.Это корень документа, который действует как наиболее видимая зацепка для JavaScript в документе.
Узлы
Прежде чем мы начнем рассматривать дерево и перемещаться с ветки на ветку, давайте рассмотрим подробнее, что именно мы будем с ним делать.
Каждый узел дерева DOM является объектом, представляющим один элемент на странице. Узлы знают об отношениях с другими узлами в своей непосредственной близости, и содержат достаточно много информации о себе. Поэтому можно легко получить всю необходимую информацию из узла, чтобы получить доступ к его предку или к потомкам.
Как и можно было ожидать, учитывая объектную природу JavaScript, искомая информация в данном случае находится в свойствах узла. В частности в свойствах parentNode и childNodes. Так как каждый элемент на странице имеет максимум одного предка, то свойство parentNode является простым: оно просто предоставляет доступ к предку узла. Однако узлы могут иметь любое число потомков, поэтому свойство childNodes является в действительности массивом. Каждый элемент массива указывает на одного потомка, в том же порядке, в котором они появляются в документе. Элемент body документа нашего примера будет, поэтому, иметь массив childNodes, содержащий элементы h1, первый p, затем второй p, в данном порядке.
Эти, конечно, не единственные интересные свойства узла. Но это хорошее начало. Какой же код необходимо использовать, чтобы, прежде всего, получить доступ к одному из этих узлов? Где следует начать исследование дерева?
С ветки на ветку
Лучшим местом для старта является корень документа, доступный через объект document. Так как document находится точно в корне, он не имеет свойства parentNode, но имеет единственного потомка: узел элемента html, который доступен через массив childNodes:
var theHtmlNode = document.childNodes[0];
Эта строка кода создает новую переменную с именем theHtmlNode, и присваивает ей значение первого потомка объекта document (вспомните, что массивы JavaScript начинают нумерацию с 0, а не с 1). Можно убедиться, что мы получили доступ к узлу html, проверяя свойство nodeName переменной theHtmlNode, которое предоставляет жизненно важную информацию о точном виде узла, с которым мы имеем дело:
alert( "theHtmlNode is a " + theHtmlNode.nodeName + " node!" );
Этот код выводит окно сообщения, которое содержит "theHtmlNode is a HTML node!" ("theHtmlNode является узлом HTML!"). Отлично! Свойство nodeName предоставляет доступ к типу узла. Для узлов элементов, это свойство содержит имя тега в верхнем регистре: в данном случае это "HTML"; для ссылки это будет "A", для параграфа "P", и т.д. Свойство nodeName текстового узла будет "#text", а nodeName объекта document будет "#document".
Мы знаем также, что theHtmlNode должен содержать ссылку на своего предка. Можно убедиться, что это работает ожидаемым образом, с помощью следующего теста:
if ( theHtmlNode.parentNode == document ) {
alert( "Hooray! The HTML node's parent is the document object!" );
}
Это работает, как мы и ожидали. Используя эту информацию, давайте напишем некоторый код для получения ссылки на первый параграф тела примера документа. Это будет второй потомок элемента body, который является вторым потомком элемента html, который является первым потомком объекта document. Вот так!
var theHtmlNode = document.childNodes[0];
var theBodyNode = theHtmlNode.childNodes[1];
var theParagraphNode = theBodyNode.childNodes[1];
alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );
Отлично. Мы получили то, что хотели. Но в действительности это достаточно многословно, и существует значительно лучший способ для записи этого кода. В лекции об объектах мы узнали, что ссылки на объекты можно соединять цепочкой, то же самое можно сделать здесь, пропуская промежуточные переменные и записывая следующий код:
var theParagraphNode = document.childNodes[0].childNodes[1].childNodes[1];
alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );
Этот код значительно короче.
Первый потомок узла всегда будет node.childNodes[0], а последний потомок узла всегда будет node.childNodes[node.childNodes.length - 1]. Эти элементы используются достаточно часто, но записывать их снова и снова достаточно громоздко. В связи c этим в DOM имеются для них явные сокращенные записи: .firstChild и .lastChild, соответственно. Так как узел html является первым потомком объекта document, а узел body является последним потомком узла html, можно переписать код еще более коротко следующим образом:
var theParagraphNode = document.firstChild.lastChild.childNodes[1];
alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );
Эти методы перемещения между узлами на близком расстоянии будут полезны, и позволяют оказаться в любом месте документа, но они несколько громоздки. Даже в этом крошечном примере документа можно видеть, насколько трудоемко может быть перемещение из корневого узла в глубину разметки. Должен быть лучший способ для таких задач!
Прямой доступ
В действительности очень сложно определить явные пути доступа для каждого требуемого элемента на странице. Более того, это становится совершенно невозможно, если страница, с которой вы работаете, является в какой-то степени динамически сгенерированной (например, с помощью серверных языков, таких как PHP или ASP.NET), так как невозможно гарантировать, что, например, параграф, который вы ищете, всегда является вторым потомком узла body. Поэтому для доступа к определенному элементу требуется лучший способ, не требующий явного знания его окружения.
Вернемся назад к документу HTML в примере выше. Можно видеть, что у рассмотренного только что параграфа имеется атрибут id. Этот id является уникальным, и идентифицирует определенное место в документе, что позволяет избавиться от явного пути доступа, используя метод getElementById объекта document. Этот метод делает именно то, что вы от него ожидаете, возвращает либо null, если JavaScript получает id, который не существует на странице, или узел запрашиваемого элемента, если он существует. Чтобы проверить это, давайте сравним результаты нового метода со старым:
var theParagraphNode = document.getElementById('excitingText');
if ( document.firstChild.lastChild.childNodes[3] == theParagraphNode ) {
alert( "theParagraphNode is exactly what we expect!" );
}
Этот код выводит подтверждающее сообщение, говорящее, что два метода выдают идентичные результаты для примера документа. getElementById является наиболее эффективным способом получения доступа к определенному фрагменту страницы: если вы знаете, что требуется выполнить некоторую обработку где-то на странице (особенно, если вы не можете гарантировать место), добавление атрибута id в соответствующем месте сбережет ваше время.
В равной степени полезным является метод DOM getElementsByTagName,который возвращает совокупность всех элементов на странице определенного типа. Можно, например, заставить JavaScript показать все элементы p на странице. Следующий пример выдает нам все параграфы на странице:
var allParagraphs = document.getElementsByTagName('p');
Обработка полученной совокупности, хранящейся в allParagraphs, лучше делать с помощью цикла for: можно работать с совокупностью почти также как с массивом:
for (var i=0; i < allParagraphs.length; i++ ) {
// выполните здесь обработку, используя
// "allParagraphs[i]" для ссылки на
// текущий элемент совокупности
alert( "This is paragraph " + i + "!" );
}
Для более сложных документов, получение всех элементов данного типа, может по-прежнему быть чрезмерным. Вместо работы с множеством элементов div на большой странице, скорее всего в действительности необходимо обработка div из определенного раздела. В этом случае можно объединить эти два метода, чтобы профильтровать результаты: выбрать элемент с помощью его id, и опросить его обо всех элементах, заданного типа, которые он содержит. В качестве примера можно было бы выбрать все элементы em параграфа с id="excitingText", выполняя следующее
document.getElementById('excitingText').getElementsByTagName('em')
Заключение
DOM является основой почти всего, что делает для нас JavaScript в web. Это интерфейс, который позволяет взаимодействовать с контентом страницы, и важно понимать, как можно использовать эту модель.
Эта лекция рассказала об основных инструментах такой работы. Вы можете теперь легко перемещаться по DOM, используя document, чтобы получить доступ к корню DOM, и childNodes и parentNode для перехода к ближайшим непосредственным связанным узлам. Вы можете пропускать промежуточные узлы и исключать жесткое кодирование длинных и громоздких путей доступа с помощью getElementById и getElementsByTagName для создания своих собственных сокращений. Но возможность побродить по своему дереву является только началом.
Следующий логический шаг состоит в том, чтобы начать делать всякие интересные вещи с полученными результатами. Вам необходимо получить данные, чтобы привести в действие свои сценарии, и манипулировать данными на странице для создания привлекательного взаимодействия с пользователями. Мы исследуем эти вопросы в следующей лекции, показывающей, как использовать методы, которые предоставляет DOM для взаимодействия с узлами и их атрибутами, и для включения этого взаимодействия в будущие сценарии и интерфейсы.
§ HTML и JavaScript
Введение
В этой лекции рассматриваются основы использования JavaScript для управления контентом страницы, включая отображение и скрытие частей страницы, добавление нового кода HTML и его удаление. В конце вы поймете, что наиболее фундаментальной вещью, для чего используется JavaScript, является изменение контента страницы, и вы узнаете, как лучше всего это делать.
Лекция имеет следующее содержание:
Скрытие и отображение
Пример скрытия и отображения
Регулярные выражения
Соединение работающего кода со страницей
Создание HTML
Скрытие и отображение
Легче всего начать с управления кодом HTML, который уже имеется, скрывая или отображая элементы, которые находятся на странице. Для этого можно использовать JavaScript, который позволяет изменять стили элементов. Стили CSS уже являются мощным средством описания внешнего вида элемента, и одной из составляющих того, как выглядит элемент, является вопрос, отображается ли элемент вообще. Свойство CSS display является ключом для отображения и скрытия элемента: если задать его как display:none;, элемент будет скрыт. Представьте параграф следующего вида:
<p id="mypara" style="display: none">I am a paragraph</p>
Этот параграф будет невидим на странице. JavaScript позволяет динамически добавлять стиль display: none для элемента и удалять его.
JavaScript предоставляет возможность получить ссылку на элемент HTML. Например, var el = document.getElementById("nav"); выдает ссылку на элемент с id="nav". Когда ссылка на элемент получена, можно с помощью атрибута style изменить примененный к нему код CSS. Например, параграф "mypara" выше в настоящий момент скрыт (в нем задано display: none). Чтобы показать его, задайте атрибут стиля display как block:
var el = document.getElementById('mypara');
el.style.display = 'block';
И вот, параграф появился. Задание CSS на элементе через атрибут style делает то же самое, что задание его в атрибуте style в самом HTML, поэтому код выше, задающий el.style.display = 'block', добивается того же эффекта, что и размещение style="display: block" прямо в коде HTML. За исключением того, что он является динамическим. Скрытие любого элемента также просто:
var el = document.getElementById('mypara');
el.style.display = 'none';
Пример скрытия и отображения
С теорией все хорошо, но здесь может быть полезен более практический пример. Представьте множество вкладок, где щелчок на самой вкладке показывает ее и скрывает все остальные.
Вот пример множества вкладок:
<ol class="tablinks">
<li><a href="#tab1">Tab 1</a></li>
<li><a href="#tab2">Tab 2</a></li>
<li><a href="#tab3">Tab 3</a></li>
</ol>
<div class="tab" id="tab1">This is tab 1</div>
<div class="tab" id="tab2">This is tab 2</div>
<div class="tab" id="tab3">This is tab 3</div>
В разделе head файла примера (см. действующий пример tabs.html по адресу http://dev.opera.com/articles/view/creating-and-modifying-html/tabs.html), вы найдете следующий код CSS и JavaScript (который будет обычно помещаться во внешние файлы и импортироваться в HTML, но здесь все содержится в одном файле, чтобы упростить просмотр). Часть кода выглядит устрашающе; не беспокойтесь, мы рассмотрим это.
<style type="text/css">
ol.tablinks {
margin: 0; padding: 0;
}
ol.tablinks li {
float: left;
border: 2px solid red;
border-width: 2px 2px 0 2px;
background: #eee;
list-style: none;
padding: 5px;
margin: 0;
}
ol.tablinks li a {
text-decoration: none;
color: black;
}
div.tab {
clear: left;
border: 2px solid red;
border-width: 1px 2px 2px 2px;
}
</style>
<script type="text/javascript">
var tabify = {
hasClass: function(el,c) {
return el.className.match(new RegExp('(\\s|^)'+c+'(\\s|$)'));
},
addClass: function(el,c) {
if (!tabify.hasClass(el,c)) el.className += " " + c;
},
removeClass: function(el,c) {
if (tabify.hasClass(el,c)) {
el.className=el.className.replace(new RegExp('(\\s|^)'+c+'(\\s|$)'),' ');
}
},
hideAllTabs: function(ol) {
var links = ol.getElementsByTagName("a");
for (var i=0; i<links.length; i++) {
tabify.setTabFromLink(links[i], "none");
}
},
setTabFromLink: function(link, style) {
var dest = link.href.match(/#(.*)$/)[1];
document.getElementById(dest).style.display = style;
if (style == "none") {
tabify.removeClass(link, "active");
} else {
tabify.addClass(link, "active");
}
},
addEvent: function(obj, type, fn) {
if ( obj.attachEvent ) {
obj['e'+type+fn] = fn;
obj[type+fn] = function(){obj['e'+type+fn]( window.event );};
obj.attachEvent('on'+type, obj[type+fn] );
} else {
obj.addEventListener( type, fn, false );
}
},
init: function() {
var ols = document.getElementsByTagName("ol");
for (var i=0; i<ols.length; i++) {
var ol = ols[i];
if (!/(^|\s)tablinks(\s|$)/.test(ol.className)) { continue; }
tabify.addEvent(ol, "click", function(e) {
var target = window.event ? window.event.srcElement : e.target;
if (target.nodeName.toLowerCase() === "a") {
tabify.hideAllTabs(e.target.parentNode.parentNode);
tabify.setTabFromLink(e.target, "block");
if (e) e.preventDefault();
if (window.event) window.event.returnValue = false;
return false;
}
}, true);
tabify.hideAllTabs(ol);
tabify.setTabFromLink(ol.getElementsByTagName("a")[0], "block");
}
}
};
tabify.addEvent(window, "load", tabify.init);
</script>
Листинг . (html, txt)
Каждая вкладка является ссылкой. Каждая ссылка содержит обработчик событий onclick. Этот обработчик событий делает две вещи: он скрывает все div (используя подход display: none, показанный выше), а затем показывает div, соответствующий этой вкладке, задавая style этого div как display: block.
Можно видеть, что код HTML задан таким образом, чтобы все работало даже в отсутствие сценария, хотя щелчок на ссылке не показывает и не скрывает вкладку, ссылки переходят на соответствующую вкладку, поэтому страница по-прежнему действует корректно, и имеет семантический смысл даже в браузерах без JavaScript. Это важно: такая техника часто называется "постепенным улучшением" (или несколько лет назад называлась "постепенное снижение эффективности", но больше так не говорят). Это важно не только для людей, которые используют современный браузер, но с отключенным JavaScript, но и для множества других типов пользователей. Вспомогательные технологии, такие как считыватели экрана для слепых пользователей, существенно полагаются на то, что структура HTML будет семантической и содержательной, и их поддержка для усовершенствований JavaScript не такая хорошая, как для зрячих пользователей. Мобильные браузеры также обладают не очень большой поддержкой сценариев. Процессоры поиска считывают HTML, но не сценарий - можно сказать, что Google является самым ненасытным слепым пользователем браузера. Вот в чем состоит значение термина "последовательное улучшение": начните со страницы, которая имеет смысл, и отобразите ее содержимое в самой простой рабочей среде, такой как web-браузер с поддержкой только текста, а затем постепенно добавляйте к ней дополнительные функции, так чтобы на каждом шаге этого пути сайт оставался по-прежнему пригодным к употреблению и функциональным.
Весь код JavaScript в основном присутствует в двух частях: часть, которая фактически делает работу, и часть, которая соединяет ее с HTML. Код, который фактически делает работу в этом примере, достаточно тривиален:
отображение вкладки, соответствующей определенной ссылке, с помощью двух строчек кода JavaScript:
var dest = link.href.match(/#(.*)$/)[1];
document.getElementById(dest).style.display = "block";
Ссылки, если вы помните, выглядят следующим образом <a href="#tab1">Tab 1</a>, и поэтому первая строка использует регулярное выражение (см. Примечание ниже) для извлечения той части ссылки, которая появится после символа #; в данном примере это будет строка tab1. Эта часть ссылки будет такой же как ID соответствующего div (потому что, как упоминалось, страница создается таким образом, чтобы иметь семантический смысл, поэтому "вкладка" ссылается на свой div). Затем мы извлекаем ссылку на этот div с помощью document.getElementById, и задаем style.display как block, как было показано ранее.