

Перечисляемый тип данных
Перечисляемый тип представляет собой ограниченную упорядоченную последовательность скалярных констант, составляющих данный тип. Значение каждой константы задается ее именем. Имена отдельных констант отделяются друг от друга запятыми, а вся совокупность констант, составляющих данный перечисляемый тип, заключается в круглые скобки.
Программист объединяет в одну группу в соответствии с каким-либо признаком всю совокупность значений, составляющих перечисляемый тип. Например, перечисляемый тип Rainbow (РАДУГА) объединяет скалярные значения RED, ORANGE, YELLOW, GREEN, LIGHT_BLUE, BLUE, VIOLET (КРАСНЫЙ, ОРАНЖЕВЫЙ, ЖЕЛТЫЙ, ЗЕЛЕНЫЙ, ГОЛУБОЙ, СИНИЙ, ФИОЛЕТОВЫЙ). Перечисляемый тип Traffic_Light (СВЕТОФОР) объединяет скалярные значения RED, YELLOW, GREEN (КРАСНЫЙ, ЖЕЛТЫЙ, ЗЕЛЕНЫЙ).
Перечисляемый тип описывается в разделе описания типов, например:
type
Rainbow = (RED, ORANGE, YELLOW,
GREEN, LIGHT_BLUE, BLUE, VIOLET);
Каждое значение является константой своего типа и может принадлежать только одному из перечисляемых типов, заданных в программе. Например, перечисляемый тип Traffic_Light не может быть определен в одной программе с типом Rainbow, так как оба типа содержат одинаковые константы.
Описание переменных, принадлежащих к скалярным типам, которые объявлены в разделе описания типов, производится с помощью имен типов. Например:
type Traffic_Light= (RED, YELLOW, GREEN);
var Section: Traffic_Light;
Это означает, что переменная Section может принимать значения RED, YELLOW или GREEN.
Переменные перечисляемого типа могут быть описаны в разделе описания переменных, например:
var Section: (RED, YELLOW, GREEN);
При этом имена типов отсутствуют, а переменные определяются совокупностью значений, составляющих данный перечисляемый тип.
К переменным перечисляемого типа может быть применим оператор присваивания:
Section:= YELLOW;
Упорядоченная последовательность значений, составляющих перечисляемый тип, автоматически нумеруется, начиная с нуля и далее через единицу. Отсюда следует, что к перечисляемым переменным и константам могут быть применены операции отношения и стандартные функции Pred, Succ, Ord.
ТИП-ДИАПАЗОН.СПОСОБЫ ОПИСАНИЯ.
Тип-диапазон (интервальный тип) есть подмножество своего базового типа, в качестве которого может выступать любой порядковый тип, кроме типа-диапазона.
Тип-диапазон задается границами своих значений внутри базового типа:
<мин.знач.> . . <макс.знач.>
Где: <мин.знач.> - минимальное значение типа-диапазона; <макс.знач.> - максимальное его значение.
Примеры:
type
Workdays = Mon . . Fri;
Index = 0 . . 63;
Letter = 'A' . . 'Z';
Natural = 0 . . MaxInt;
Positive = 1 . . MaxInt;
Тип-диапазон необязательно описывать в разделе type, а можно указывать непосредственно при объявлении переменной. При объявлении типа-диапазона нужно руководствоваться следующими правилами:
два символа . . рассматриваются как один символ, поэтому между ними недопустимы пробелы;
левая граница диапазона не должна превышать его правую границу.
Тип-диапазон наследует все свойства своего базового типа, но с ограничениями, связанными с его меньшей мощностью.
В стандартную библиотеку Паскаля включены две функции, поддерживающие работу с типами-диапазонами:
high(x) – возвращает максимальное значение типа-диапазона, к которому принадлежит переменная x;
low(x) – возвращает минимальное значение типа-диапазона, к которому принадлежит переменная x;
ВЕЩЕСТВЕННЫЕ ТИПЫ ДАННЫХ.АРИФМЕТИЧЕСКИЕ ФУНКЦИИ ЯЗЫКА ПАСКАЛЬ,РЕЗУЛЬТАТ КОТОРЫЙ ВЕЩЕСТВЕННОЕ ЧИСЛО.
Вещественные типы
В Турбо Паскале имеется пять видов вещественных типов, диапазон возможных значений которых зависит от их внутреннего представления. Типы целых, объем занимаемой памяти, количество значащих цифр и диапазон возможных значений приведен в табл. 3. Таблица 3
Тип |
Длина, байт |
К-во зн. цифр |
Диапазон |
REAL |
6 |
11..12 |
|
SINGLE |
4 |
7..8 |
|
DOUBLE |
8 |
15..16 |
|
EXTENDED |
10 |
19..20 |
|
COMP |
8 |
19..20 |
|
Над данными вещественного типа определены следующие операции: - арифметические: +, -, /, * - соотношения: =, <>, <, >, <=, >= Набор встроенных математических функций применимых к данными вещественного типа приведен в табл. 4. Таблица 4
Обращение |
Назначение |
Пример |
sin(x) |
Возвращает синус, угол в радианах |
|
cos(x) |
Возвращает синус, угол в радианах |
|
arctan(x) |
Возвращает арктангенс |
|
abs(x) |
Возвращает абсолютную величину |
|
sqr(x) |
Возвращает квадрат |
|
exp(x) |
Возвращает экспоненту |
|
ln(x) |
Возвращает логарифм натуральный |
|
trunc(x) |
Отбрасывает дробную часть |
trunc(5.6)=5 |
round(x) |
Округляет до ближайшего целого |
round(5.6)=6 |
frac(x) |
Выделяет дробную часть |
frac(10.1)=0.1 |
int(x) |
Выделяет целую часть |
int(10.1)=10.0 |
random |
Датчик случайных чисел (ДСЧ) 0 <n ?1 |
|
random(x) |
Датчик случайных чисел (ДСЧ) 0 <n ? x |
|
randomize |
Инициализация ДСЧ |
|
ТИП ДАННЫХ СТРОКА.ОПИСАНИЕ.ПРОЦЕДУРЫ И ФУНКЦИИ ОБРАБОТКИ СТРОК В ЯЗЫКЕ ПАСКАЛЬ.
Строка (string) - это последовательность литер. Литерные строки уже использовались нами в качестве аргументов операторa write при изучении темы "Ввод-вывод". Теперь познакомимся с ними подробнее.
Тип данных (string) определяет строки с максимальной длиной 255 символов. Переменная этого типа может принимать значения переменной длины.
Например,
MaxLine : string; City : string[30] |
Строковая переменная может иметь атрибут длины, определяющий ее максимальную длину.
Текущая длина строковой переменной может быть определена с помощью встроенной функции Length. Для заданного значения типа string эта функция возвращает целое значение, показывающее количество литер в строке.
Выражения, в которых операндами служат строки, называются строковыми выражениями.
Над строками определены следующие операции:
1. Операция конкатенации (+) применяется для сцепления нескольких строк в одну.
Например, SumStr := 'Турбо '+'Паскаль '+'7.0'
2. Операции отношения (=, <>, >, <, >=, <=) проводят посимвольное сравнение двух строк слева направо до первого несовпадающего символа. Большей считается та строка, в которой первый несовпадающий символ имеет больший номер в стандартной таблице обмена информацией. Результат выполнения операций отношения над строками всегда имеет булевский тип.
Например, выражение 'MS-DOS'<'MS-Dos' имеет значение True
Если строки имеют различную длину, но в их общей части символы совпадают, считается, что более короткая строка меньше, чем более длинная.
Строки считаются равными, если они совпадают по длине и содержат одни и те же символы на соответствующих местах в строке.
Для присваивания строковой переменной результата строкового выражения используется оператор присваивания. Если значение переменной после выполнения оператора присваивания превышает по длине максимально допустимую при описании величину, то все лишние символы справа отбрасываются.
Допускается смешение в одном выражении операндов строкового и символьного типа.
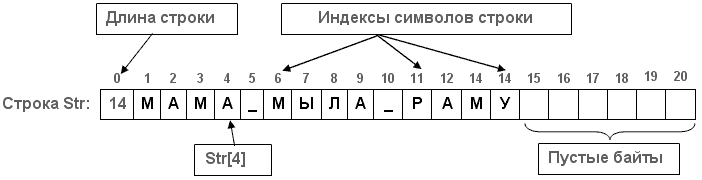
К отдельным символам строки можно обратиться по номеру (индексу) данного символа в строке.
Например, чтобы обратиться к третьему символу строки SumStr надо записать SumStr[3]. Запись SumStr[0] дает значение текущей длины строки.
Для эффективного программирования алгоритмов обработки текстов необходимо хорошо понимать внутреннюю структуру представления строк в памяти. Строки реализованы достаточно просто. Для хранения строковых переменных выделяется количество байтов памяти, на единицу большее максимальной длины строки. Начальный байт этой памяти отводится для хранения текущей длины строки, следующие байты - для символов самой строки. Так как элементы строк стандартно нумеруются целыми числами, начиная с единицы, байт с длиной строки можно считать нулевым ее элементом. Такая структура памяти допускает прямой доступ к ее элементам.
Важно отметить, что имеется возможность динамически управлять текущей длиной строки. Следующая программа показывает автоматическое изменение длины строки после тех или иных операций с нею. Обратите внимание, что общий (определяемый с помощью стандартной функции SizeOf) размер памяти, отведенной для хранения строки все время остается неизменным.
Program StringLength; Var S : string; {макс. длина строки = 255} Begin S:=''; {пустая строка} writeln (S,' ',SizeOf(S),' ',Length(S)); {размер=256, длина=0} S:='Пример длинной строки'; {присваиваем строке некоторое значение} writeln (S,' ',SizeOf(S),' ',Length(S)); {размер=256, длина=21} Delete(S,7,8); {удаляем из строки 8 символов, начиная с 7} writeln (S,' ',SizeOf(S),' ',Length(S)); {размер=256, длина=13} S:=S+' символов'; {добавляем к строке строку} writeln (S,' ',SizeOf(S),' ',Length(S)); {размер=256, длина=22} End. |
Внимание! При решении задач со строковыми переменными Вы можете столкнуться с распространенной трудно обнаруживаемой ошибкой, когда после присваивания некоторым элементам строки символов ни содержимое, ни длина строки не изменяются. Разберемся, с чем это связано.
Очень важно понимать, что при доступе к некоторому элементу строки значение ее текущей длины не проверяется. Это иллюстрирует следующая программа:
Program StringElements; Var S : string; {макс. длина строки = 255} Begin S:='ABCD'; {инициализация строки} writeln (S,' ',Length(S)); {вывод строки и ее длины} S[5] := 'E'; {присваивание элементу строки} writeln (S,' ',Length(S)); {ни сама строка, ни ее длина не изменились} End. |
Присваивание пятому элементу строки некоторого значения не изменяет длину строки, что подтверждает вывод на экран ее содержимого и длины (конечно само присваивание реально произошло, но на значение текущей длины строки в нулевом байте это никакого влияния не оказало). Работа с элементами строки без учета ее текущей длины и является ошибкой программиста. Посмотрите следующую программу:
Program StringElements2; Var Str : string[26]; {длина строки = 26} i : integer; Begin Str:='A'; for i := 1 to 26 do Str[i] := Chr (Ord('A')+i-1); writeln(Str); End. |
Предполагается, что данная программа должна сформировать строку из 26 символов, содержимым которой является последовательность заглавных букв латинского алфавита. Однако вызов процедуры writeln показывает, что содержимым переменной Str будет строка из одного символа 'А'. Природа совершенной ошибки заключается в том, что присваивание значений элементам строки не влияет на текущую длину, которая была установлена равной 1 при первом присваивании. Поэтому правильной будет следующая программа:
Program stringElements3; Var Str : string[26]; {длина строки = 26} i : char; Begin Str:=''; for i := 'A' to 'Z' do Str := Str + i; writeln(Str); End. |
Операция конкатенации, как и все стандартные операции, работающие со строками, в отличие от поэлементного присваивания, изменяет длину строки, что дает корректный результат. Кроме того, вторая программа работает непосредственно с символами букв. Наконец, не следует забывать инициализировать строку перед ее заполнением (первый оператор программы). В противном случае, так как начальная длина строки является неопределенной, можно получить произвольный результат; не стоит рассчитывать на то, что в нулевом байте стоит ноль.
Для обработки строковых данных можно использовать встроенные процедуры и функции:
Delete (Str, Poz, N) - удаление N символов строки Str, начиная с позиции Poz.
Insert (What, Where, Poz) - вставка строки What в строку Where, начиная с позиции Poz.
Copy (Str, Poz, Nstr) - выделяет подстроку длиной Nstr, начиная с позиции Poz, из строки Str.
Concat (Str1, Str2, ..., StrN) - выполняет сцепление строк в том порядке, в каком указаны в списке параметров.
Pos (What, Where) - обнаруживает первое появление подстроки What в строке Where.
UpCase (Ch) - преобразует строчную букву в прописную.
Str (Number, Stroka) - преобразует число в строку.
Val (Stroka, Number, Code) - преобразует строку в число и выдает код правильности преобразования.
ТИП ДАННЫХ МАССИВ.ОПИСАНИЕ.ВВОД И ВЫВОД ЭЛЕМЕНТОВ МАССИВА В ЯЗЫКЕ ПАСКАЛЬ.
Массив – это упорядоченная последовательность величин, обозначаемых одним именем. Упорядоченность заключается в том, что элементы массива располагаются в последовательных ячейках памяти. Существуют одномерные, двумерные и многомерные массивы.
Рассмотрим одномерные массивы.
Для обозначения типа данных массив в Паскале есть служебное слово array.
В начале программы необходимо описать массив, т.е. задать имя массива, количество элементов в массиве и их тип. Например
var A : array[ 1 .. 15 ] of integer
var X, Y: array [1..10] of real
var Q: array [0..9] of real
var A: array ['A'..'Z'] of real
Также можно использовать константу для описания размера массива.
const N=5;
var A : array[ 1 .. N ] of integer
После объявления массива в памяти выделяется место для размещения массива.
При обработке массивов могут встречаться различные задачи, которые можно разделить на группы:
- поиск элементов,
- математическая обработка элементов
- преобразование элементов по какому- то правилу
- преобразование массива
- удаление или вставка элементов массива
и другие задачи
Во всех этих задачах есть обязательно блок ввода элементов массива.
Ввод, вывод и обработка элементов массива производится поэлементно, т.е. используется оператор цикла с параметром.
Можно вводить элементы массива с клавиатуры
for i:=1 to N do
begin
write ('введите a[', i, ']=');
read ( a[i] );
end;
Для заполнения массива может быть использована формула. Например, массив заполняется числами -1, 1, -1, 1 и т.д.
a[1]:=1;
for i:=2 to N do
begin
a[i]:=-1*a[i-1];
write(a[i]);
end;
Для заполнения массива можно использовать генератор случайных чисел. Например , массив заполнится случайными числами в интервале [50,150) в результате выполнения фрагмента
for i:=1 to N do begin
a[i] := random(100) + 50;
write(a[i]);
end;
Блок вывода массива в большинстве случаев присутствует в программе.Так же как и блок ввода он использует цикл.
writeln('Массив A:');
for i:=1 to N do write(a[i]:4);
ТИП ДАННЫХ МАССИВ.ОПИСАНИЕ.СОРТИРОВКА ЭЛЕМЕНТОВ МАССИВА МЕТОДОМ ОБМЕНА.
Сейчас мы поговорим о сортировки массива так называемым методом "пузырька". По другому этот метод называется методом перестановок или методом обмена. Почему метод известен как метод "пузырька", да просто потому, что при его реализации более "легкие" элементы как бы всплывают вверх. Соответственно, более тяжелые "идут ко дну", один человек, обладающий видимо хорошим чувством юмора, заметил, что по всей видимости, пессимисты называют метод пузырька методом "утопленника".
Итак, представим, что у нас есть целочисленный массив из 10 элементов и нам его необходимо отсортировать по возрастанию.
Вот код программы на Паскале:
{ сортировка массива "пузырьком" по возрастанию }
const
n = 10; { количество элементов в массиве }
var
a:array[1..n] of integer;
i,j,buf:integer;
begin
{Заполняем массив случайными целыми числами из диапазона от 0 до 9 и выводим массив на экран}
for i:=1 to n do
begin
a[i]:=random(10);
write(a[i],' ');
end;
for i:=1 to n-1 do
for j:=i+1 to n do {В этой строке начинающие программисты чаcто допускают ошибку}
if a[i]>a[j] then
begin
buf:=a[i];
a[i]:=a[j];
a[j]:=buf;
end;
writeln;
writeln('Массив после сортировки пузырьковым методом: ');
for i:=1 to n do
write(a[i],' ');
end.
|
Пояснения. Как видно из текста программы на Паскале, при сортировке массива методом пузырька, сравниваются два соседних элемента массива. В том случае, если элемент массива с номером iоказывается больше элемента массива с номером i+1, происходит обмен значениями при помощи вспомогательной переменной buf (переменной я дал название со смысловой нагрузкой, от слова "буфер").

ТИП ДАННЫХ ЗАПИСЬ.ОПИСАНИЕ.ОСОБЕННОСТИ ПРИМЕНЕНИЯ.
Как мы уже выяснили, массивы объединяют однородные единицы информации – элементы одного и того же типа. Но многообразие информации нельзя свести только к какому-то одному типу данных. Например, указывая положение точки в пространстве, мы можем воспользоваться одним и тем же типом для указания ее координат, но, описывая человека, мы должны указать его имя, рост, цвет глаз и волос, то есть в одном описании объединим разнородную информацию. Точно так же, описывая автомобиль, мы укажем не только его марку, но и год выпуска, модификацию, да и цвет кузова может нас заинтересовать. Составляя автоматизированный каталог книгохранилища, мы для каждой книги должны указать ее название, имя автора, область знания, количество страниц, год издания, а также, возможно, признак нахождения на руках или в хранилище.
Данные такого рода, описывающие существенные стороны того или иного объекта путем включения в описание нескольких, часто разнотипных, элементов, называют записью (record). В языке Паскаль запись определяется путем указания служебного слова record и перечисления входящих в запись элементов с указанием типов этих элементов.
Запись Паскаля – структурированный комбинированный тип данных, состоящий из фиксированного числа компонент (полей) разного типа.
Например, анкетные данные о студенте вуза могут быть представлены в виде информационной структуры

Такая структура называется двухуровневым деревом. В Паскале эта информация может храниться в одной переменной типа record (запись). Задать тип можно следующим образом:
type < имя _ типа >=record <имя_поля1>: тип; <имя_поля2>: тип; …………………. <имя_поля K >: тип end ;
где record – служебное слово, а <имя_типа> и <имя_поля> - правильные идентификаторы языка Паскаль.
Описание анкеты студента в Паскале будет выглядеть так:
Пример фрагмента программы описания записи Паскаля
Type anketa=record fio: string[45]; pol: char; dat_r: string[8]; adres: string[50]; curs: 1..5; grupp: string[3]; end;
Такая запись Паскаля, так же как и соответствующее ей дерево, называется двухуровневой.
Поля записи Паскаля могут иметь любой тип, в частности сами могут быть записями. Такая возможность используется в том случае, когда требуется представить многоуровневое дерево (более 2 уровней). Например, те же сведения о студентах можно отобразить трехуровневым деревом.

Такая организация данных позволит, например, делать выборки по году рождения или по городу, где живут студенты. В этом случае описание соответствующей записи в Паскале будет выглядеть так:
Пример фрагмента программы описания записи Паскаля
Type anketa1=record fio: string[45]; pol: char; dat_r: record; god: integer; mes: string[10]; den: 1..31; end; adres: record gorod: string[25]; ulica: string [20]; dom, kv: integer; end; curs: 1..5; grupp: string[3]; end;
Поля
После того, как определен тип записи Паскаля, можно определять переменную этого типа. Переменная определяется путем задания ее идентификатора и указания типа.
var student: anketa; student 1: anketa 1;
Теперь нам нужно узнать, как правильно получать доступ к элементам записи Паскаля. Элементы записи называются полями, а обращение к ним производится через использование их имен – идентификаторов полей. Практически, поля записи обрабатываются точно так же, как и любые другие переменные. Но в отличие от обычной переменной имена полей должны предваряться ссылкой на идентификатор записи Паскаля и отделяться от него точкой. Такая запись называется уточняющий идентификатор:
<имя_записи>.<имя_поля>
Например, чтобы обратиться к полю curs переменной student , необходимо указать следующее составное имя:
student.curs :=3;
Для того чтобы обратиться к полю god в записи student 1, необходимо записать уточняющий идентификатор, состоящий из трех имен:
student1.dat_r.god:=1982;
Использование полей записи Паскаля в выражениях и условиях идентично использованию обычных переменных.
Операции над записями Паскаля (это важно!)
Единственная операция, которую можно произвести над однотипными записями Паскаля – это присваивание.
Все другие операции производятся над отдельными полями записи.
Пример решения задачи с использованием записей Паскаля
Рассмотрим для начала простейший пример заполнения записи Паскаля и вывода ее на экран.
Пусть нам необходимо заполнить сведения о студенте (Ф.И.О., дата рождения, адрес, курс и группа), а затем вывести эти сведения на экран.
Пример программы c записью Паскаля
program primer1; type anketa=record fio: string[45]; dat_r: string[8]; adres: string[50]; curs: 1..5; grupp: string[3] end; var student: anketa; begin writeln (‘введите сведения о студенте’); {обратите внимание, ввод каждого поля осуществляется отдельно} writeln (‘введите фамилию, имя и отчество’); readln (student.fio); writeln (‘введите дату рождения’); readln (student.dat_r); writeln (‘введите адрес’); readln(student.adres); writeln (‘введите курс’); readln(student.curs); writeln (‘введите группу’); readln (student.grupp); writeln (‘ввод закончен’); writeln ; {обратите внимание, что вывод записи осуществляется по полям} writeln (‘фамилия студента: ’, student . fio ); writeln(‘ дата рождения : ’, student.dat_r); writeln(‘ адрес : ’, student.adres); writeln(‘ курс : ’, student.curs); writeln(‘ группа : ’, student.grupp); end.
А теперь слегка усложним задачу. Пусть нам необходимо иметь сведения о многих студентах, например, нашего факультета. Следовательно, необходимо организовать массив записей Паскаля. А затем из общего списка вывести фамилии студентов 2-го курса.
Пример программы c записью Паскаля
program primer 2 ; type anketa=record fio: string[45]; dat_r: string[8]; adres: string[50]; curs: 1..5; grupp: string[3] end; var student: array [1..100] of anketa; I: integer; begin {последовательно вводим каждую запись} for I:=1 to 100 do begin writeln (‘введите сведения о’, I , ‘-м студенте’); writeln (‘введите фамилию, имя и отчество’); readln (student[I].fio); writeln (‘введите дату рождения’); readln (student[I].dat_r); writeln (‘введите адрес’); readln(student[I].adres); writeln (‘введите курс’); readln(student[I].curs); writeln (‘введите группу’); readln (student[I].grupp); end; writeln (‘ввод закончен’); writeln ; {просматриваем массив записей и выбираем только студентов 2-го курса } for I:=1 to 100 do if student[I].curs=2 then writeln(‘ фамилия студента : ’, student[I].fio); end.
Оператор присоединения или как избавиться от префикса
Префикс – обязательная предшествующая часть составного идентификатора для имен полей в структуре типа запись Паскаля. Очень часто у программиста возникает желание не указывать префикс в имени полей, например, когда идет постоянное использование одних и тех же записей. В языке Паскаль предусмотрена такая возможность, реализуемая при помощи оператора присоединения, который в общем виде выглядит так:
with <имя_записи> do <действие с полем записи>;
Следует обратить внимание на то, что после служебного слова do может стоять только один оператор, но он может быть составным (любая последовательность операторов, заключенная в операторные скобки begin end ).
Например, фрагмент из предыдущей программы с использованием оператора присоединения будет выглядеть так:
Пример фрагмента программы c записью и префиксом Паскаля
for I:=1 to 100 do with student[I] do begin writeln (‘введите сведения о’, I , ‘-м студенте’); writeln (‘введите фамилию, имя и отчество’); readln (fio); writeln (‘введите дату рождения’); readln (dat_r); writeln (‘введите адрес’); readln(adres); writeln (‘введите курс’); readln(curs); writeln (‘введите группу’); readln (grupp); end;
ТИП ДАННЫХ МНОЖЕСТВО.ОПИСАНИЕ.ОПЕРАЦИИ, ИСПОЛЬЗУЕМЫЕ ДЛЯ РАБОТЫ СО МНОЖЕСТВАМИ В ЯЗЫКЕ ПАСКАЛЬ.
Множественный тип данных Паскаля напоминает перечислимый тип данных. Вместе с тем множественный тип данных – набор элементов не организованных в порядке следования.
В математике множественный тип данных – любая совокупность элементов произвольной природы. Операции, которые производятся над множествами, по существу заключаются во включении и исключении элементов из множества.
Понятие множества в языке программирования значительно уже математического понятия.
В Паскале под множественным типом понимается конечная совокупность элементов, принадлежащих некоторому базовому типу данных.
В качестве базовых типов могут использоваться:
перечислимые типы;
символьный;
байтовый;
диапазонные на основе вышеперечисленных.
Такие ограничения связаны с формой представления множественного типа данных в Паскале и могут быть сведены к тому, чтобы функция ord() для используемого базового типа лежала в пределах от 0 до 255.
После того, как базовый тип задан, совокупность значений соответствующего множественного типа данных определяется автоматически. В нее входят все возможные множества, являющиеся произвольными комбинациями значений базового типа. Все эти множества являются отдельными значениями определенного множественного типа данных.
Описание множественного типа данных Паскаля
Type <имя_типа>= set of <базовый_тип>
Пример множественного типа данных Паскаля
Type symbol= set of char; {описан множественный тип symol из букв} Var letter, digits, sign: symbol; {описаны три переменные множественного типа}
Для того чтобы придать переменной множественного типа значение, используют конструктор множества – перечисление элементов множества через запятую в квадратных скобках. Например,
sign:= [‘+’, ‘-‘];
Конструктор множества может содержать диапазон значений базового типа. Тогда во множества включаются все элементы диапазона. Например,
digits:= [‘0’ .. ‘9’]; letter:= [‘a’ .. ‘z’];
Обе формы конструирования множеств могут сочетаться. Например,
letter:= [‘a’ .. ‘z’, ‘A’ .. ‘Z’];
Конструктор вида [] обозначает пустые множества.
В программе можно использовать множественны тип как константы, в этом случае их определяют следующим способом:
Const YesOrNo= [‘Y’, ‘y’, ‘N’, ‘n’];
Можно множественный тип определить как типизированную константу:
Const digits: set of char= [‘0’ .. ‘9’];
При описании множественного тип как констант допускается использование знака “+” (слияние множеств). Например,
Const Yes= [‘Y’, ‘y’]; No= [‘N’, ‘n’]; YesOrNo= Yes+ No;
Операции над множественными типами Паскаля
С множественными типами Паскаля можно выполнять действия объединения, исключения и пересечения.
Объединение множественных типов содержит элементы, которые принадлежат хотя бы одному множеству, при этом каждый элемент входит в объединение только один раз. Операция объединения множеств обозначается знаком ‘+’.
Пример множественных типов Паскаля
Type symbol= set of char; Var small, capital, latin: symbol; ……………… small:= [‘a’ .. ‘z’]; capital:= [‘A’ .. ‘Z’]; latin:= small + capital; {образованы множества латинских букв путем объединения множеств small и capital}
Возможно объединять множественные типы и отдельные элементы. Например,
small:= [‘c’ .. ‘z’]; small:= small + [‘a’] +[‘b’];
Исключение определяется как разность множественных типов, в котором из уменьшаемого исключаются элементы, входящие в вычитаемое. Если в вычитаемом есть элементы, отсутствующие в уменьшаемом, то они никак не влияют на результат. Операция исключения обозначается знаком ‘-‘.
Пример исключения множественных типов Паскаля
letter:= [‘a’ .. ‘z’]; {множества букв латинского алфавита} glasn:= [‘a’, ‘e’, ‘o’, ‘u’, ‘i’, ‘y’]; {множества гласных букв} soglasn:= letter-glasn; {образовано множества согласных букв путем исключения из множества всех букв множества гласных букв}
Пресечение множественных типов– множества, содержащие элементы, одновременно входящие в оба множества. Операция пересечения множеств обозначается знаком ‘*’.
Пример пересечения множественных типов
Type chisla= set of byte; Var z,x,y: chisla; ……….. x:= [0..150]; y:= [100..255]; z:= x*y {получено множества чисел из диапазона 100..150 в результате пересечения двух множеств}
Операции отношения множественных типов Паскаля
Наряду с рассмотренными выше операциями, над значениями множественного типа определены и некоторые операции отношения. Операндами операций над множественными значениями в общем случае являются множественные выражения. Среди операций отношения над значениями множественного типа особое место занимает специальная операция проверки вхождения элемента во множества, обозначаемая служебным словом in. В отличие от остальных операций отношения, в которых значения обоих операндов относятся к одному и тому же множественному типу значений, в операции in первый операнд должен принадлежать базовому типу, а второй – множественному типу значений, построенному на основе этого базового типа. Результатом операции отношения, как обычно, является логическое значение (true или false).
‘a’ in glasn значение операции true; ‘o’ in soglasn значение операции false;
Операция сравнения на равенство множественных типов Паскаля. Множества считаются равными (эквивалентными), если все элементы одного множества присутствуют в другом и наоборот. Для операции сравнения на равенство или неравенство используются символы ‘=’ и ‘<>’.
A:= [2,1,3]; D:= [1,3,2];
Тогда операция A=D имеет значение true, а операция A<>D имеет значение false.
Проверка включения. Одно множество считается включенным в другое (одно множество является подмножеством другого), если все его элементы содержатся во втором множестве. Обратное утверждение может быть и несправедливым. Операции проверки включения обозначаются ‘<=’ и ‘>=’.
letter >= glasn; soglan <= letter;
Следует отметить, что применение операций < и > над операндами множественного типа недопустимо.
ТИП ДАННЫХ ФАЙЛ.ОПИСАНИЕ РАЗЛИЧНЫХ КАТЕГОРИЙ ФАЙЛОВ.ПРОЦЕДУРЫ И ФУНКЦИИ, ИСПОЛЬЗУЕМЫЕ ДЛЯ РАБОТЫ С ФАЙЛАМИ В ЯЗЫКЕ ПАСКАЛЬ.
Файлы Pascal-Паскаль
Существенной особенностью всех рассмотренных до сих пор значений производных типов является наличие в них конечного, наперед заданного числа компонент. Так, в значении многомерного массива это число можно определить, зная количество компонент по каждому измерению, а в значении записи это число определяется количеством и типом полей. Таким образом, заранее, еще до выполнения программы, по этому описанию можно выделить необходимый объем памяти машины для хранения значений переменных этих типов. Но существует определенный класс задач и определенные ситуации, когда количество компонент (пусть даже одного и того же из известных уже типов) заранее определить невозможно, оно выясняется только в процессе решения задачи. Поэтому возникает необходимость в специальном типе значений, которые представляют собой произвольные последовательности элементов одного и того же типа, причем длина этих последовательностей заранее не определяется, а конкретизируется в процессе выполнения программы. Этот тип значений получил название файлового типа. Условно файл в Паскале можно изобразить как некоторую ленту, у которой есть начало, а конец не фиксируется. Элементы файла записываются на эту ленту последовательно друг за другом:
![]()
где F – имя файла, а F1, F2, F3, F4 – его элементы. Файл во многом напоминает магнитную ленту, начало которой заполнено записями, а конец пока свободен. В программировании существует несколько разновидностей файлов, отличающихся методом доступа к его компонентам:файлы последовательного доступа и файлы произвольного доступа.
Простейший метод доступа состоит в том, что по файлу можно двигаться только последовательно, начиная с первого его элемента, и, кроме этого, всегда существует возможность начать просмотр файла с его начала. Таким образом, чтобы добраться до пятого элемента файла, необходимо, начав с первого элемента, пройти через предыдущие четыре. Такие файлы называют файлами последовательного доступа. У последовательного файла доступен всегда лишь очередной элемент. Если в процессе решения задачи необходим какой-либо из предыдущих элементов, то необходимо вернуться в начало файла и последовательно пройти все его элементы до нужного.
Файлы произвольного доступа Паскаля позволяют вызывать компоненты в любом порядке по их номеру.
Важной особенностью файлов является то, что данные, содержащиеся в файле, переносятся на внешние носители. Файловый тип Паскаля – это единственный тип значений, посредством которого данные, обрабатываемые программой, могут быть получены извне, а результаты могут быть переданы во внешний мир. Это единственный тип значений, который связывает программу с внешними устройствами ЭВМ.
Работа с файлами в Паскале
Любой файл имеет три характерные особенности. Во-первых, у него есть имя, что дает возможность программе работать одновременно с несколькими файлами. Во-вторых, он содержит компоненты одного типа. Типом компонентов может быть любой тип Паскаля, кроме файлов. Иными словами, нельзя создать «файл файлов». В-третьих, длина вновь создаваемого файла никак не оговаривается при его объявлении и ограничивается только емкостью устройств внешней памяти.
Файловый тип или переменную файлового типа в Паскале можно задать одним из трех способов:
Type <имя_ф_типа>=file of<тип_элементов>; <имя_ф_типа>=text; <имя_ф_типа>=file;
Здесь <имя_ф_типа> – имя файлового типа (правильный идентификатор); File, of – зарезервированные слова (файл, из); <тип_элементов> – любой тип Паскаля, кроме файлов.
Пример описания файлового типа в Паскале
Type Product= record Name: string; Code: word; End; Text80= file of string[80]; Var F1: file of char; F2: text; F3: file; F4: Text80; F5: file of Product;
В зависимости от способа объявления можно выделить три вида файлов Паскаля:
типизированные файлы Паскаля(задаются предложением file of..);
текстовые файлы Паскаля(определяются типом text);
нетипизированные файлы Паскаля(определяются типом file).
Следует помнить, что физические файлы на магнитных дисках и переменные файлового типа в программе на Паскале – объекты различные. Переменные файлового типа в Паскале могут соответствовать не только физическим файлам, но и логическим устройствам, связанным с вводом/выводом информации. Например, клавиатуре и экрану соответствуют файлы со стандартными именами Input, Output.
Как известно, каждый тип данных в Паскале, вообще говоря, определяет множество значений и множество операций над значениями этого типа. Однако над значениями файлового типа Паскаля не определены какие-либо операции, в том числе операции отношения и присваивания, так что даже такое простое действие, как присваивание значения одной файловой переменной другой файловой переменной, имеющей тот же самый тип, запрещено. Все операции могут производиться лишь с элементами (компонентами) файлов. Естественно, что множество операций над компонентами файла определяется типом компонент.
Переменные файлового типа используются в программе только в качестве параметров собственных и стандартных процедур и функций.
Основные процедуры и функции для работы с файлами