

Операции над потоками (процессами)
1.1.6.1 ОС осуществляет управление потоками (процессами) посредством выполнения операций над ними, таких как:
– создание (образование)
– уничтожение (завершение);
– изменение приоритета;
– блокирование;
– пробуждение;
– запуск (выбор);
– приостановка;
– возобновление.
1.1.6.2 Рассмотрим содержание операций над потоками.
Создание потока включает:
– присвоение имени потоку;
– включение этого имени в список имён потоков, известных системе;
– определение начального приоритета потока (приоритет потока может динамически изменяться на интервале существования потока);
– определение прав доступа;
– формирование описателя потока;
– выделение потоку начальных ресурсов.
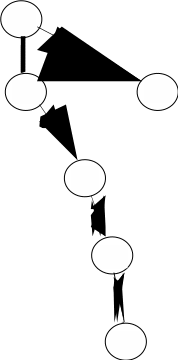
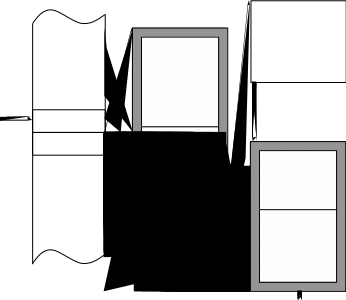
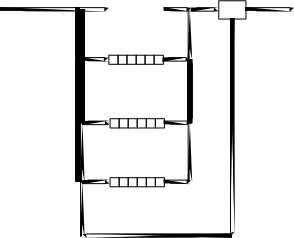
Во многих системах поток может обратиться к ОС с запросом на создание так называемых потоков-потомков (дочерних потоков). Для создания дочернего потока (процесса) необходим только один родительский поток (процесс). При таком подходе создаётся иерархическая структура потоков (рисунок 1.3), в которой у дочернего потока есть только один родительский
поток, но у каждого родительского поток может быть много дочерних потоков. Если потомок на интервале своего существования (от момента создания до момента завершения) в свою очередь выдаёт требование (системный вызов) на
50
А
 В1 В2 В3
В1 В2 В3
 С11 С21 С22
С11 С21 С22
D221
E2211
Рисунок 1.3 – Иерархия создания потоков (процессов)
порождение другого потока-потомка, то он одновременно становится и родителем (порождающим потоком). Во многих системах порождение потомков является основным механизмом создания процессов и потоков [например, создание процессов в системе UNIX System V Release 4 (в ней потоки не поддерживаются)
51
происходит в два этапа – сначала создаётся копия процесса-родителя, затем у нового процесса производится замена кодового сегмента на заданный; вновь созданному процессу ОС присваивает целочисленный идентификатор, уникальный на весь период функционирования системы].
Уничтожение (завершение) потока означает его удаление из системы, т.е. предусматривает возврат системе всех занимаемых уничтожаемым потоком ресурсов, стирание имени потока в любых системных списках или таблицах и освобождение описателя потока. В связи с этой операцией возникают проблемы с родительскими потоками. В разных ОС по-разному строятся отношения между потоками-потомками и их родителями. Например, в одних ОС выполнение родительского потока синхронизируется с его потомками, в частности, после завершения родительского потока ОС может снимать с выполнения всех его потомков. В других системах потоки-потомки
могут выполняться асинхронно по отношению к родительскому потоку, так что его уничтожение не оказывает влияния на потомков.
Суть операций блокирования, пробуждения и запуска потока рассмотрена ранее в пункте 1.1.5 по отношению к конкуренции потока за процессорное время.
Приостановка – операция, как правило, врéменной пассивизации процесса с освобождением оперативной памяти и, при необходимости, других ресурсов. Операция приостановки используется в следующих случаях:
– если система работает ненадёжно и есть признаки, что она может отказать, т.е. в случае обнаружения ошибок в работе ОС;
– необходимость обдумывания пользователем текущей информации и промежуточных результатов [пользователь, у которого отдельные промежуточные результаты работы процесса вызвали сомнение, может приостановить его (а не уничтожить), пока не выяснит, правильно ли работает
этот процесс];
– ликвидация пиковой нагрузки на систему (некоторые процессы можно приостанавливать в моменты кратковременных пиков нагрузки системы с тем, чтобы возобновлять их выполнение после того, как нагрузка возвратится к обычному времени).
Инициатором приостановки может быть либо сам процесс, либо другой процесс, имеющий необходимые полномочия. В однопроцессорной системе выполняющийся процесс может приостановить только сам себя, поскольку ни один другой процесс не может работать одновременно с ним, чтобы выдать сигнал приостановки. В мультипроцессорной ВС выполняющийся процесс может быть приостановлен и другим процессом, выполняющимся на другом процессоре. Перевод из состояний «готовность» и «ожидание» в состояния соответственно
«приостановлен-готов» и «приостановлен-ожидает» и обратно производится
другим процессом (рисунок 1.4). Заметим, что состояние «приостановлен-
выполняет» не бывает.
Приостановка процесса – важная операция, которая реализуется во многих
52
Активные состояния – поток (процесс) в основной памяти
Пробуждение
ГОТОВНОСТЬ ОЖИДАНИЕ
Приоста-
новка
Запуск
Истечение кванта
Возобнов-
ление
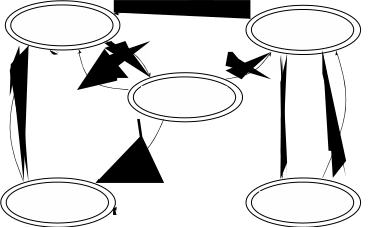 ВЫПОЛНЕНИЕ
ВЫПОЛНЕНИЕ
Блокирование
Приоста-
новка
Возобнов-
ление
Приостановка
ПРИОСТАНОВЛЕН И ГОТОВ
Пробуждение
ПРИОСТАНОВЛЕН И ОЖИДАЕТ
Пассивные состояния (состояния приостановки) –процесс не размещён в основной памяти, но его описатель существует
Рисунок 1.4 – Граф состояний процесса с операциями приостановки и возобновления
различных системах по-разному. Приостановки, как правило, длятся лишь небольшое время. В случае длительной приостановки процесса его ресурсы должны быть освобождены. Решение о необходимости освобождения конкретного ресурса в значительной степени зависит от природы этого ресурса. Основная память при приостановке процесса должна освобождаться немедленно. Закреплённое за процессом внешнее устройство в случае кратковременной
53
приостановки процесса может быть за ним сохранено, однако его необходимо освобождать, если процесс приостанавливается на длительный или неопределённый период времени.
Возобновление (или активация) процесса – это операция подготовки процесса к повторному запуску с той точки, в которой он был приостановлен. Может возникнуть вопрос, не лучше ли вместо перевода заблокированного процесса в состояние приостановки подождать, пока не завершится выполнение операции ввода-вывода или не произойдёт другое событие, необходимое для того, чтобы данный процесс стал готовым к выполнению. К сожалению, завершение операции ввода-вывода или ожидаемое событие может никогда не произойти или может задержаться на неопределённо долгий срок. Когда ожидаемое событие в конце концов происходит (если оно всё-таки происходит), то процесс, находящийся в состоянии «приостановлен-ожидает», пробуждается и переходит в
состояние «приостановлен-готов» (см. рисунок 1.4).
1.1.6.3 Операции приостановки и возобновления связаны с реализацией свопинга (swapping). В системах со свопингом программы пользователя не обязательно должны оставаться в основной памяти до момента своего завершения. Свопинг представляет собой частный случай виртуальной памяти (но не виртуальная память), когда образы процессов выгружаются на диск и возвращаются в ОП целиком. Однако подкачке (свопингу) свойственна избыточность: когда ОС решает активизировать процесс, для его выполнения, как правило, не требуется загружать в ОП все его сегменты полностью – достаточно загрузить небольшую часть кодового сегмента с подлежащей выполнению инструкцией и частью сегментов данных, с которыми работает эта инструкция, а также отвести место под сегмент стека. Аналогично при освобождении памяти для загрузки нового процесса очень часто вовсе не требуется выгружать другой
процесс на диск целиком, достаточно вытеснить на диск только часть его образа. Перемещение избыточной информации замедляет работу системы, а также приводит к неэффективному использованию памяти. Кроме того, сситемы, поддерживающие свопинг, имеют ещё один очень существенный недостаток: они не способны загрузить для выполнения процесс, виртуальное адресное пространство которого превышает имеющуюся в наличии свободную память. Именно из-за указанных недостатков свопинг в качестве основного механизма управления памятью почти не используется в современных ОС. На смену ему пришёл более совершенный механизм виртуальной памяти, который заключается в том, что при нехватке места в ОП на диск выгружаются только части образов процессов. В некоторых современных ОС, например версиях UNIX, основанных на коде SVR4, механизм свопинга используется как дополнительный к виртуальной памяти, включающийся только при серьёзных перегрузках системы (привести пример возможности использования свопинга для GPSS/PC в ОС MS-DOS).
Мультипрограммирование на основе прерываний
1.2.1 Назначение и типы прерываний. Состояние процессора
1.2.1.1 Прерывания представляют собой механизм, позволяющий координировать параллельное функционирование отдельных устройств ВС и
реагировать на события, т.е. прерывание (interrupt)– это принудительная передача
управления от выполняемой программы к системе (а через неё – к соответствующей программе обработки прерывания), происходящая при возникновении определённого события. Или вот ещё одно определение прерывания: под прерыванием понимают сигнал, по которому процессор
«узнаёт» о свершении в общем случае асинхронного (т.е. по сравнению с тактовой частотой процессора) события.
Идея прерывания была предложена ещё в середине 50-х годов прошлого века и внесла наиболее весомый вклад в развитие вычислительной техники. Основная цель введения прерываний – реализация асинхронного режима функционирования и распараллеливание работы отдельных устройств ВС.
Прерывания являются основной движущей силой любой ОС. По меткому
замечанию Скотта Максвелла «Прерывания названы так весьма удачно, поскольку они прерывают нормальную работу системы». Действительно, система прерываний переводит процессор на выполнение потока команд, отличного от
78
того, который выполнялся до сих пор, с последующим возвратом к исходному коду. Прерывание возникает либо в зависимости от внешних по отношению к процессу выполнения программы событий, либо при появлении непредвиденных аварийных ситуаций в процессе выполнения данной программы. Прерывания позволяют вызывать и выполнять заранее подготовленные программы для обработки некоторой конкретной ситуации (в этом их сходство с вызовом процедур в выполняющейся программе, если это, конечно, не системный вызов). Под системой (механизмом) прерываний понимают комплекс аппаратно- программных средств, обеспечивающих выявление и обработку прерываний. Структуры систем прерываний (в зависимости от аппаратной платформы) могут быть самыми разными, но все они имеют общую особенность – прерывание непременно влечёт за собой изменение порядка выполнения команд процессором.
1.2.1.2 В зависимости от источника прерывания делятся на три больших класса:
– внешние (аппаратные; асинхронные);
– внутренние [синхронные; захваты или исключения (exeption)];
– программные.
Внешние прерывания вызываются асинхронными событиями, которые происходят вне прерываемого процесса, например, прерывания от таймера, прерывания от внешних устройств (прерывания по вводу-выводу), прерывания по нарушению питания, прерывания с пульта оператора ВС, прерывания от другого процессора или другой ВС. Внешние прерывания называют также аппаратными, отражая тот факт, что прерывание возникает вследствие подачи некоторой аппаратурой (например, контроллером принтера) электрического сигнала, который передаётся (возможно, через контроллер прерываний) на специальный вход прерывания процессора. Данный класс прерываний является асинхронным по
отношению к потоку инструкций прерываемой программы. Аппаратура процессора работает таким образом, что возникающие в произвольные моменты времени сигналы прерывания воспринимаются процессором в ближайший следующий момент времени между выполнением двух соседних инструкций (команд), т.е. в так называемой точке наблюдения, при этом система после обработки прерывания продолжает выполнение процесса (потока), уже начиная со следующей инструкции (команды). Итак, внешнее прерывание не может прервать выполнение текущей команды, а будет обрабатываться только после её завершения.
Внутренние прерывания, называемые также захватами или исключениями (exeption), происходят синхронно выполнению программы при появлении аварийной ситуации в ходе выполнения некоторой инструкции программы. Другими словами, внутренние прерывания вызываются событиями, которые
связаны с работой процессора и являются синхронными с его операциями.
Примерами исключений (непредопределённых событий в процессе) являются
79
следующие запросы на прерывания, возникающие:
– при нарушении адресации (в адресной части выполняемой инструкции указан запрещённый или несуществующий адрес, обращение к отсутствующему в физической памяти сегменту или странице при организации механизмов виртуальной памяти);
– при наличии недопустимого кода операции, т.е. при наличии в поле кода операции незадействованной двоичной комбинации;
– из-за необычных ситуаций с данными (попытка деления на ноль, исчезновение порядка, переполнение разрядной сетки, потеря значимости) (overflow – переполнение – возникает тогда, когда результат арифметической операции переполняет разрядную сетку ячейки, предназначенной для приёма этого результата; underflow – потеря значимости или исчезновение значащих разрядов – ситуация, возникающая в том случае, когда результат арифметической
или какой-либо другой операции получается меньше нижней границы диапазона чисел, представляемых в данной ЭВМ);
– при попытке выполнить привилегированную инструкцию (команду) в пользовательском (исполнительском) режиме;
– от средств контроля (например, вследствие обнаружения ошибки чётности, ошибок в работе различных устройств).
Исключения возникают непосредственно в ходе выполнения тактов команды, т.е.
«внутри» выполнения. Исключения, например, в процессоре Pentium, в свою очередь подразделяются на
– отказы (faults);
– ловушки (traps);
– аварийные завершения (aborts).
Отказы соответствуют некорректным ситуациям, которые выявляются до выполнения инструкции, например, при обращении по адресу, находящемуся в
отсутствующей в оперативной памяти странице (страничный отказ). После
обработки исключения-отказа процессор повторяет выполнение команды, которую он не смог выполнить из-за отказа (отказ в данном примере возникает из-за отсутствия адреса в физической памяти на стадии формирования операндов команды). Ловушки обрабатываются процессором после выполнения инструкции, например, при возникновении переполнения. После обработки процессор выполняет инструкцию, следующую за той, которая вызвала исключение (если исключение замаскировано). Аварийные завершения соответствуют ситуациям, когда невозможно точно определить команду, вызвавшую прерывание. Чаще всего это происходит во время серьёзных отказов, связанных со сбоями в работе аппаратуры компьютера. Для обработки исключений в таблице прерываний отводятся номера 0-31. Таким образом, внутреннее прерывание сигнализирует об
аномалии при выполнении команды. Некоторые захваты можно исключить, например, захваты, связанные с арифметическими операциями, и ошибки будут только указываться. Однако из-за синхронного характера возникновения захвата
80
маскировка (блокировка), по существу, здесь не используется и захват может быть исключён, но не отсрочен, т.е. можно подавить причину захвата, да и то не во всех случаях.
Программные прерывания отличаются от двух предыдущих классов тем, что они по своей сути не являются «истинными» прерываниями. Программное прерывание возникает при выполнении особой команды процессора (системного вызова), выполнение которой имитирует прерывание, т.е. переход на новую последовательность инструкций. Смысл программного прерывания в том, чтобы вызвать из программы пользователя процедуру ОС с расширенными правами. Через программное прерывание обеспечивается автоматическое переключение процессора в привилегированный режим работы с возможностью исполнения любых команд.
1.2.1.3 Сигналы, вызывающие прерывания, могут возникать одновременно
(по крайней мере, во время выполнения процессором текущей команды) и на них надо каким-то образом реагировать. Выбор одного из них для обработки осуществляется на основе приоритетов, приписанных каждому типу прерывания. Прерываниям приписывается приоритет (interrupt priority), с помощью которого они ранжируются по степени важности и срочности (рисунок 1.14). Очевидно,
 Средства
контроля
процессора
Средства
контроля
процессора
Высокий приоритет
Питание (сбой питания)
 Межпроцессорное
прерывание
Межпроцессорное
прерывание
Внешние устройства
Системный таймер
 Магнитные
диски
Сетевое
оборудование
Терминалы
Магнитные
диски
Сетевое
оборудование
Терминалы
Понижение приоритета
Программные прерывания
Низкий приоритет

 Обычные
потоки
Обычные
потоки
Рисунок 1.14 – Распределение прерываний по уровням приоритета
81
что прерывания от схем контроля процессора должны обладать наивысшим приоритетом (действительно, если аппаратура работает неправильно, то нет смысла продолжать обработку информации). Учёт приоритета может быть встроен в технические средства, а также определяться операционной системой, т.е. кроме аппаратно реализованных приоритетов прерывания большинство ЭВМ и вычислительных комплексов допускают программно-аппаратное управление порядком обработки сигналов прерывания. О прерываниях, имеющих одинаковое значение приоритета, говорят, что они относятся к одному уровню приоритета прерываний.
1.2.1.4 Прерывания обычно обрабатываются модулями ОС, так как действия, выполняемые по прерываниям, относятся к управлению разделяемыми ресурсами ВС – принтером, диском, таймером, процессором и т.п. Процедуры, вызываемые по прерываниям, обычно называют обработчиками прерываний
(Interrupt Handler – IH), или процедурами обслуживания прерываний (Interrupt Service Routine – ISR). Аппаратные прерывания обрабатываются драйверами соответствующих внешних устройств, исключения – специальными модулями ядра, а программные прерывания – процедурами ОС, обслуживающими системные вызовы. Кроме этих модулей в ОС может находиться так называемый диспетчер, или супервизор прерываний, который координирует работу отдельных обработчиков прерываний.
1.2.1.5 Рассмотрим такое понятие как состояние процессора, важное для понимания работы системы (механизма) прерываний как в мэйнфреймах (больших ЭВМ), так и в ПЭВМ. К регистрам, содержание которых определяет состояние процессора, относятся следующие:
– адресуемые, общие или регистры общего назначения (РОН),
используемые для врéменного хранения операндов арифметических, логических и других команд, а также для задания смещения адреса относительно начала
некоторого сегмента данных;
– специализированные регистры, предназначенные для некоторой синтетической информации, называемой словом состояния процессора [Processor Status Word – PSW или Mashine Status Word – MSW – в процессоре Pentium в управляющем регистре CR0 слово MSW занимает 2 младших байта (а в процессоре Intel 80286 так назывался весь регистр, т.е. MSW), или, по-русски, ССП]. Так, в частности, сюда входит регистр флагов [для хранения признаков, характеризующих результат выполнения операции (например, флага знака, флага нуля, флага переполнения, флага паритета, флага переноса и некоторых других), а также для хранения некоторых признаков, устанавливаемых и анализируемых механизмом прерываний, в частности, флага разрешения аппаратных прерываний IF], а также указатель инструкций (регистр адреса команд или,
иначе, счётчик команд), применяемый для выбора команд программы в текущем сегменте, содержащем код программы.
82
PSW процессора полностью описывает состояние процессора и содержит информацию по трём разделам:
а) информацию о состоянии процессора, включающую:
1) состояние выполнения [процессор может находиться либо в состоянии выполнения инструкций, т.е. в активном состоянии или, иначе, состоянии «работа», либо в состоянии ожидания (команды не выполняются); переход из активного состояния в состояние ожидания осуществляется загрузкой слова состояния или выполнением специальной инструкции (привилегированной команды останова процессора HALT); обратный переход из состояния ожидания в активное состояние может произойти лишь в результате прерывания];
2) режим [в целях защиты полезно зарезервировать выполнение некоторых инструкций (команд) только за программами ОС; на многих
машинах это реализуется введением двух режимов функционирования процессора, различающихся выделенным битом слова состояния: привилегированный режим или режим распорядителя (режим супервизора или супервизорный режим) и режим исполнителя (режим пользователя, задачи или программы); список команд, выполняемых в режиме исполнителя, составляет подмножество соответствующего множества команд для режима распорядителя; инструкции, выполняемые только в режиме распорядителя, называются привилегированными; к ним относятся: команды инициализации некоторых системных регистров процессора (команды для работы с управляющими регистрами, а также для загрузки регистров системных адресов); команды переключения режима работы ЦП; команда останова процессора HALT; команды запрета/разрешения маскируемых аппаратных прерываний CLI/STI; коман6ды ввода-вывода IN, INS, OUT, OUTS (список команд приведен для процессора Pentium); с помощью привилегированных команд осуществляется защита структур ОС от некорректного поведения пользовательских процессов, а также взаимная защита ресурсов этих процессов];
3) маски прерывания;
б) информацию о доступном контексте в памяти (таблицы сегментов: сегмент кода, сегменты данных) и соответствующих правах доступа (ключи или указатели защиты памяти);
в) информацию о ходе развития текущего процесса (условный код, являющийся признаком результата выполнения предыдущей команды, и порядковый счётчик, содержащий адрес следующей команды).
П рим е ч а н ие – На одних машинах для счётчика выделяется отдельный
регистр (в ПЭВМ), на других же для него выделяется специальное поле записи в слове состояния (в мэйнфреймах).
83
1.2.2 Механизм прерываний. Приоритеты прерываний и маскирование прерываний
1.2.2.1 Механизм прерываний поддерживается аппаратными средствами
компьютера и программными средствами операционной системы. Аппаратная поддержка прерываний имеет свои особенности, зависящие от типа процессора и других аппаратных компонентов, передающих сигнал запроса прерывания от внешнего устройства к процессору (таких как контроллер внешнего устройства; шины подключения внешних устройств; контроллер прерываний, являющийся посредником между сигналами шины и сигналами процессора). Особенности аппаратной реализации прерываний оказывают влияние на средства программной поддержки прерываний, работающие в составе ОС.
Существуют два основных способа, с помощью которых шины
(подключения внешних устройств) выполняют прерывания:
– векторный (vectored);
– опрашиваемый (polled).
В обоих способах процессору предоставляется информация об уровне приоритета прерывания на шине подключения внешних устройств. В случае векторных прерываний в процессор передаётся также информация о начальном адресе программы обработки возникшего прерывания – обработчика прерываний.
1.2.2.2 Устройствам, которые используют векторные прерывания, назначается вектор прерываний. Он представляет собой электрический сигнал, выставляемый на соответствующие шины процессора и несущий в себе информацию об определённом, закреплённом за данным устройством номере, который идентифицирует соответствующий обработчик прерываний. Этот вектор может быть фиксированным, конфигурируемым (например, с использованием переключателей) или программируемым. ОС может
предусматривать процедуру регистрации вектора обработки прерываний для определённого устройства, которая связывает некоторую подпрограмму обработки прерываний с определённым вектором. При получении сигнала запроса прерывания процессор выполняет специальный цикл подтверждения прерывания, в котором устройство должно идентифицировать себя. В течение этого цикла устройство отвечает, выставляя на шину вектор прерываний. Затем процессор использует этот вектор для нахождения обработчика данного прерывания. Примером шины подключения внешних устройств, которая поддерживает векторные прерывания, является шина VMEbus.
1.2.2.3 При использовании опрашиваемых прерываний процессор получает от запросившего прерывание устройства только информацию об уровне приоритета прерывания [например, номере IRQ (Interrupt ReQuest – запрос прерывания) на шине ISA или номере IPL на шине Sbus компьютеров SPARC]. С
каждым уровнем приоритета прерываний может быть связано несколько устройств и соответственно несколько программ – обработчиков прерываний. При возникновении прерывания процессор должен определить, какое устройство
84
из тех, которые связаны с данным уровнем приоритета прерываний, действительно запросило прерывание. Это достигается вызовом всех обработчиков прерываний для данного уровня приоритета, пока один из обработчиков не подтвердит, что прерывание пришло от обслуживаемого им устройства. Если же с каждым уровнем приоритета прерываний связано только одно устройство, то определение нужной программы обработки прерывания происходит немедленно, как и при векторном прерывании. Опрашиваемые прерывания поддерживают шины ISA, EISA, MCA, PCI и Sbus.
1.2.2.4 Механизм прерываний некоторой аппаратной платформы может сочетать векторный и опрашиваемый типы прерываний. Типичным примером такой реализации является платформа персональных компьютеров на основе процессоров Intel Pentium. Шины PCI, ISA, EISA или MCA, используемые в этой платформе для подключения внешних устройств, поддерживают механизм
опрашиваемых прерываний. Контроллеры периферийных устройств выставляют на шину не вектор, а сигнал запроса прерывания определённого уровня IRQ. Однако в процессоре Pentium система прерываний является векторной. Вектор прерываний в процессор Pentium поставляет контроллер прерываний, который отображает поступающий от шины сигнал IRQ на определённый номер вектора. В том случае, когда к каждой линии IRQ подключается только одно устройство, процедура обработки прерываний работает так, как если бы система прерываний была чисто векторной, т.е. процедура не выполняет никаких дополнительных опросов для выяснения того, какое именно устройство запросило прерывание. Однако при совместном использовании одного уровня IRQ несколькими устройствами программа обработки прерываний должна работать в соответствии со схемой опрашиваемых прерываний, т.е. дополнительно опросить все устройства, подключенные к данному уровню IRQ. Процессор Pentium поддерживает векторную схему прерываний, с помощью которой может быть вызвано 256 процедур обработки прерываний (вектор имеет длину в один байт). Соответственно таблица прерываний имеет 256 элементов, которые в реальном режиме (real mode) работы процессора состоят из дальних адресов (CS:IP) этих процедур, а в защищённом режиме (protected mode) – из дескрипторов. Таблица прерываний реального режима, каждый элемент которой имеет длину 4 байта, всегда находится в фиксированном месте физической памяти – с начального адреса 0000016 по адрес 003FF16 (т.е. с нулевого по 1023-й байт). Старшие два байта элемента таблицы содержат адрес обработчика прерывания в виде номера первого параграфа кодового сегмента CS (параграф – 16 байт), а младшие два байта – относительный адрес IP (внутрисегментное смещение). Каждый элемент таблицы прерываний однозначно адресуется путём сдвига вектора прерывания на два разряда влево, что эквивалентно умножению на 4. Так, например, 255-й номер вектора прерывания – в двоичном коде 1111 1111 –
после сдвига влево на два разряда – это уже 11 1111 1100 = 003FC16 = 3·162 +
85
15·161 + 12·160 = 1020-й байт, начиная с которого (т.е. 1020-й, 1021-й, 1022-й и
1023-й) располагаются четыре байта адреса обработчика 255-го прерывания. В защищённом режиме таблица прерываний носит название IDT (Interrupt Descriptor Table) и может располагаться в любом месте физической памяти. Её начало (32-разрядный физический адрес) и размер (16 бит) можно найти в регистре системных адресов IDTR. Каждый из 256 элементов таблицы прерываний представляет собой восьмибайтный дескриптор. В таблице прерываний могут находиться только дескрипторы определённого типа – дескрипторы шлюзов прерываний, шлюзов ловушек и шлюзов задач. Шлюзы (вентили) – привилегированные кодовые сегменты, вызывая которые, пользовательский код вызывает привилегированные процедуры, которые будут работать со своим высоким уровнем привилегий.
Основным режимом работы процессора Pentium является защищённый
режим (protected mode). Для совместимости с программным обеспечением, разработанным для предшествующих моделей процессоров Intel (главным образом, модели 8086) в процессорах Pentium предусмотрен так называемый реальный режим (real mode). В реальном режиме процессор Pentium выполняет шестнадцатиразрядные инструкции и адресует 1Мбайт памяти. Тридцатидвухразрядные процессоры семейства Intel: 80386, 80486, Pentium, Pentium Pro, Pentium II, Celeron, Pentium III и т.д.
1.2.2.5 Механизм прерываний чаще всего поддерживает приоритезацию и маскирование прерываний. Приоритезация означает, что все источники прерываний делятся на классы и каждому классу назначается свой уровень приоритета запроса на прерывание. Приоритеты могут обслуживаться как относительные и как абсолютные. Обслуживание запросов прерываний по схеме с относительными приоритетами заключается в том, что при одновременном
поступлении запросов прерываний из разных приоритетных классов выбирается запрос, имеющий высший приоритет. Однако в дальнейшем при обслуживании этого запроса процедура обработки прерывания уже не прерывается даже в том случае, когда появляются более приоритетные запросы – решение о выборе нового запроса принимается только в момент завершения обслуживания текущего прерывания. Для организации такой дисциплины обслуживания необходимо в программе обслуживания данного запроса наложить маски на все остальные сигналы прерывания или просто отключить систему прерываний. Если же более приоритетным прерываниям разрешается приостанавливать работу процедур обслуживания менее приоритетных прерываний, то это означает, что работает схема приоритезации с абсолютными приоритетами. Для реализации этого режима необходимо на время обработки прерывания замаскировать все запросы с таким же или более низким приоритетом (использование маскирования запросов на прерывания). Может быть и другой вариант реализации этой дисциплины: процессор (или компьютер, когда поддержка приоритезации прерываний вынесена во внешний по отношению к
86
процессору блок) поддерживает в одном из своих внутренних регистров переменную, фиксирующую уровень приоритета обслуживаемого в данный момент прерывания. При поступлении запроса на прерывание из определённого приоритетного класса его приоритет сравнивается с текущим приоритетом процессора, и если приоритет запроса выше, то текущая процедура обработки прерывания вытесняется, а по завершении обслуживания нового прерывания происходит возврат к прерванной процедуре.
Наличие сигнала прерывания не обязательно должно вызывать прерывание исполняющейся программы. Процессор может обладать средствами защиты от прерываний: отключение системы прерываний, маскирование (блокировка, запрет) отдельных сигналов прерывания. Упорядоченное обслуживание запросов прерываний (наряду со схемами приоритетной обработки запросов) может выполняться механизмом маскирования запросов на
прерывания. Замаскированное прерывание (замаскированный запрос на данный уровень прерывания) не может прервать процессор. Строго говоря, в описанной схеме абсолютных приоритетов выполняется маскирование – при обслуживании некоторого запроса все запросы с равным или более низким приоритетом маскúруются (блокируются), т.е. не обслуживаются. Схема маскúрования предполагает возможность врéменного маскирования прерываний любого класса независимо от уровня приоритета. Замаскúрованный запрос на прерывание может быть утерянным, либо ждать обработки, что означает, что он (запрос) всё ещё известен аппаратуре. Если замаскированный запрос ждёт обработки, то последующее демаскирование (размаскирование, разрешение) запроса инициализирует его обработку. Заметим, что маскирование и демаскирование запросов на прерывания всегда реализуются привилегированными командами в результате некоторого прерывания.
1.2.2.6 Механизм обработки прерываний независимо от архитектуры вычислительной системы предполагает следующую обобщённую последовательность шагов:
– шаг 1 (реализуется аппаратно) – при возникновении сигнала (для аппаратных прерываний) или условия (для внутренних прерываний) прерывания происходит первичное аппаратное распознавание типа прерывания. Если прерывания данного типа в настоящий момент запрещены (приоритетной схемой или механизмом маскирования), то процессор продолжает поддерживать естественный ход выполнения команд. В противном случае в зависимости от поступившей в процессор информации (уровень приоритета прерывания, вектор прерывания или тип условия внутреннего прерывания) происходит автоматический вызов процедуры обработки прерывания, адрес которой находится в специальной таблице ОС, размещаемой либо в регистрах процессора,
либо в определённом месте ОП;
– шаг 2 (реализуется аппаратно-программным способом) –
87
автоматически сохраняется некоторая часть контекста прерванного потока (напомним, что контекст потока или, иначе, область сохранения регистров – это информация о потоке, необходимая для возобновления выполнения потока с прерванного места; образ потока – совокупность его кодов и данных), которая позволит ядру ОС возобновить исполнение потока процесса после обработки прерывания. В эту часть контекста обычно включаются значения счётчика команд; слова состояния машины, хранящего признаки основных режимов работы процессора (пример такого слова – регистр EFLAGS и два младших байта регистра CR0 в Intel Pentium), а также нескольких регистров общего назначения, которые требуются программе обработки прерывания. Может быть сохранён и полный контекст процесса, если ОС обслуживает данное прерывание со сменой процесса. Решение о перепланировании процессов (потоков) может быть принято в ходе обработки прерывания, например, если это прерывание от таймера по истечении выделенного процессу (потоку) кванта времени. Однако в общем случае это не обязательно, часто обработка прерываний выполняется без вытеснения текущего процесса, например, приём очередной порции данных от контроллера внешнего устройства чаще всего происходит в рамках текущего процесса, хотя данные, скорее всего, предназначены совсем другому процессу;
– шаг 3 (реализуется аппаратно-программным способом) – одновременно с загрузкой адреса процедуры обработки прерываний в счётчик команд может автоматически выполняться загрузка нового значения слова состояния машины (или другой системной структуры, например, селектора кодового сегмента в процессоре Pentium), которое определяет режимы работы процессора при обработке прерывания, в том числе работу в привилегированном режиме. (Селектор однозначно определяет виртуальный сегмент, к которому относится
искомый адрес, т.е. он может интерпретироваться как номер сегмента, а смещение, как это и следует из его названия, фиксирует положение искомого адреса относительно начала сегмента. Смещение задаётся в машинной инструкции, а селектор помещается в один из сегментных регистров процессора. Под смещение отводится 32 бита, что обеспечивает максимальный размер сегмента 232=4Гбайта). В некоторых моделях процессоров переход в привилегированный режим за счёт смены состояния машины при обработке прерывания является единственным способом смены режима. Прерывания практически во всех мультипрограммных ОС обрабатываются в привилегированном режиме модулями ядра ОС, так как при этом обычно нужно выполнить ряд критических операций, от которых зависит жизнеспособность системы, – управлять внешними устройствами, перепланировать потоки и т.п.;
– шаг 4 (реализуется программно) – врéменно запрещаются прерывания
данного типа, чтобы не образовывалась очередь вложенных друг в друга потоков одной и той же процедуры, и происходит собственно выполнение программы (процедуры) обработки прерывания. Детали этой операции (запрета прерываний)
88
зависят от особенностей аппаратной платформы, например, может использоваться механизм маскирования прерываний. Многие процессоры автоматически устанавливают признак запрета прерываний в начале цикла обработки прерывания, в противном случае это делает программа обработки прерывания. Заметим, что собственно обработка прерывания может быть выполнена той же процедурой, на которую было передано управление на шаге 3, но в операционных системах достаточно часто она реализуется путём последующего вызова соответствующей подпрограммы обработки прерывания (в этом случае на шаге 3 управление может передаваться, например, диспетчеру прерываний);
– шаг 4 (реализуется программно) – после того как прерывание обработано ядром ОС контекст прерванного потока восстанавливается и тем самым возобновляется работа потока с прерванного места. Часть контекста
восстанавливается аппаратно по команде возврата из прерываний (например, адрес следующей команды и слово состояния машины), а часть – программным способом, с помощью явных команд извлечения данных из системного стека (system stack). При возврате из прерывания блокировка (маскирование) повторных прерываний данного типа снимается. Заметим, что в общем случае после обработки прерывания управление (через планировщик потоков) может быть передано другой задаче, а не прерванному потоку.
1.2.3 Программные прерывания
Программное прерывание реализует один из способов перехода к подпрограмме ОС с помощью специальной инструкции (команды) процессора, такой, например, как команда INT в процессорах Intel Pentium (trap в процессорах Motorola, syscall в процессорах MIPS или Ticc в процессорах SPARC). При выполнении команды программного прерывания процессор обрабатывает ту же
последовательность действий, что и при возникновении внешнего или внутреннего прерываний, но только происходит это в предсказуемой точке программы – там, где программист поместил данную команду.
Практически все современные процессоры имеют в системе команд инструкции программных прерываний. Одной из причин появления инструкций программных прерываний в системе команд процессоров является то, что их использование часто приводит к более компактному коду программ по сравнению с использованием стандартных команд выполнения процедур. Это объясняется тем, что разработчики процессора обычно резервируют для обработки всех прерываний небольшое число возможных подпрограмм, так что длина операнда в команде программного прерывания, указывающего на нужную подпрограмму, меньше, чем в команде перехода на обычную подпрограмму. Например, в процессоре i80х86 (i – Intel) предусмотрена возможность применения
256 программ обработки прерываний, поэтому в инструкции INT операнд имеет длину в один байт (а инструкция INT 3, которая предназначена для вызова
89
отладчика, вся имеет длину один байт). Значение операнда команды INT просто является индексом в таблице из 256 адресов подпрограмм обработки прерываний, один из которых и используется для перехода по команде INT. При использовании же команды CALL потребовалось бы уже не однобайтовый, а двух- или четырёхбайтовый операнд.
Другой причиной применения программных прерываний вместо обычных инструкций вызова подпрограмм является возможность смены пользовательского режима на привилегированный одновременно с вызовом процедуры – это свойство программных прерываний поддерживается большинством процессоров.
В результате программные прерывания часто используются для выполнения ограниченного количества вызовов функций ядра ОС, т.е. системных вызовов.
1.2.4 Диспетчеризация и приоритезация прерываний в ОС
1.2.4.1 ОС должна играть активную роль в организации обработки прерываний. Прерывания выполняют очень полезную для ВС функцию – они позволяют реагировать на асинхронные по отношению к вычислительному процессу события. В то же время прерывания создают дополнительные трудности для ОС в организации вычислительного процесса. Эти трудности связаны с непредвиденными переходами управления от одной процедуры к другой, возникающими в результате прерываний от контроллеров внешних устройств. Возможно также возникновение в непредвиденные моменты времени исключений, связанных с ошибками во время выполнения инструкций. Усложняют задачу планирования вычислительных работ и запросы на выполнение системных работ (т.е. системные вызовы) от пользовательских приложений, выполняемые с помощью программных прерываний. Сами модули ОС также
часто вызывают друг друга с помощью программных прерываний, ещё больше запутывая общую картину вычислительного процесса.
ОС не может терять контроль над ходом выполнения системных процедур, вызываемых по прерываниям. Она должна упорядочивать их во времени так же, как планировщик упорядочивает многочисленные пользовательские поток. Кроме того, сам планировщик потоков является системной процедурой, вызываемой по прерываниям (аппаратным – от системного таймера или контроллера устройства ввода-вывода, или программным – от приложения или модуля ОС). Поэтому правильное планирование процедур, вызываемых по прерываниям, является необходимым условием правильного планирования пользовательских потоков. В противном случае в системе могут возникать, например, такие ситуации, когда ОС будет длительное время заниматься не требующей мгновенной реакции задачей управления стримером, архивирующим
данные, в то время как высокоскоростной диск будет простаивать и тормозить работу многочисленных приложений, обменивающихся данными с этим диском.
1.2.4.2 Для упорядочения работы обработчиков прерываний в ОС
90
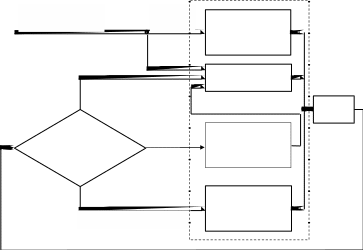
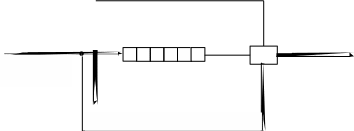
применяется тот же механизм, что и для упорядочения работы пользовательских процессов – механизм приоритетных очередей. Все источники (сигналов) прерываний обычно делятся на несколько классов, причём каждому классу присваивается приоритет. В ОС выделяется программный модуль, который занимается диспетчеризацией обработчиков прерываний. Это модуль в разных ОС называется по-разному, но для определённости будем называть его диспетчером (супервизором) прерываний (например, диспетчер прерываний в OC Windows NT называется Trap Handler). Его работа происходит следующим образом. При возникновении прерывания диспетчер прерываний вызывается первым (рисунок 1.15). Он запрещает ненадолго все прерывания, а затем
Диспетчер прерываний
Выполнение кода подпрограммы обра-
Исполняемая программа
П р е
р Текущая ы команда в
и
е
а Следующаян команда
Отключение прерываний, со- хранение кон- текста прерван- ной программы в её дескрипто- ре, установка ре- жима работы системы преры- ваний (маскиро- вание)
Определение адреса програм-
мн
ботки прерывания
Эта подпрограмма уже не заботится о сохранении контекс- та прерванного по- тока
Планировщик потоков
 ого
ого
обслуж
го
модуля,
ивающе-
Выбор готовой
запрос на
прерывание, и
передача управ-
ления на него
к выполнению
задачи (на осно- ве принятой дисциплины об- служивания)
Восстановление контекста зада- чи, установка прежнего режи- ма работы сис- темы прерыва- ний и передача управления этой задаче
К другой задаче
Рисунок 1.15 – Обработка прерывания при участии диспетчера прерываний и планировщика потоков
91
выясняет причину прерывания. После этого диспетчер сравнивает назначенный данному источнику прерывания приоритет и сравнивает его с текущим приоритетом выполняемого процессором потока команд (в процессоре имеется внутренняя переменная, называемая уровнем прерываний процессора). В этот момент времени процессор уже может выполнять инструкции другого обработчика прерываний, также имеющего некоторый приоритет. Прерывание происходит только в том случае, когда уровень запроса на прерывание выше текущего уровня прерываний процессора; в этом случае выполнение текущего обработчика прерываний приостанавливается, и он помещается в соответствующую очередь обработчиков прерываний. В противном случае в очередь помещается обработчик нового запроса на прерывание.
П рим е ч а н ие – Приоритет обработчиков прерываний не совпадает в общем случае с приоритетом потоков, выполняемых в обычной последовательности, определяемой планировщиком потоков. По отношению к обработчикам прерываний любой поток, назначенный на выполнение планировщиком, имеет самый низкий приоритет, так что любой запрос на прерывание всегда может прервать выполнение этого потока (см. рисунок 1.14).
1.2.5 Системные вызовы
1.2.5.1 Системный вызов (запрос) позволяет приложению обратиться к ОС с просьбой выполнить то или иное действие, оформленное как процедура (или набор процедур) кодового сегмента ОС. Для прикладного программиста ОС выглядит как некая библиотека, предоставляющая некоторый набор полезных функций, с помощью которых можно упростить прикладную программу или выполнить действия, запрещённые в пользовательском режиме, например, обмен данными с устройством ввода-вывода. С момента системного вызова процесс считается системным. Таким образом, пользовательский и системный процессы
являются двумя фазами одного и того же процесса, но они никогда не пересекаются между собой. Каждая фаза пользуется своим собственным стеком. Стек задачи содержит аргументы, локальные переменные и другую информацию относительно функций, выполняемых в режиме задачи (пользовательском режиме).
Реализация системных вызовов должна удовлетворять следующим требованиям:
– обеспечивать переключение в привилегированный режим;
– обладать высокой скоростью вызова процедур ОС;
– обеспечивать по возможности единообразное обращение к системным вызовам для всех аппаратных платформах, на которых работает ОС;
– допускать лёгкое расширение набора системных вызовов;
– обеспечивать контроль со стороны ОС за корректным использованием системных вызовов.
92
Первое требование для большинства аппаратных платформ может быть выполнено только с помощью механизма программных прерываний. Поэтому будем считать, что остальные требования нужно обеспечить именно для такой реализации системных вызовов. Как это обычно бывает, некоторые из этих требований взаимно противоречивы.
Для обеспечения высокой скорости было бы полезно использовать векторные свойства системы программных прерываний, имеющиеся во многих процессорах, т.е. закрепить за каждым системным вызовом определённое значение вектора. Приложение при таком способе вызова непосредственно указывает в аргументе запроса значение вектора, после чего управление немедленно передаётся требуемой процедуре ОС (рисунок 1.16, а). Однако этот децентрализованный способ передачи управления привязан к особенностям аппаратной платформы, а также не позволяет ОС легко модифицировать набор
системных вызовов и контролировать их использование. Например, в процессоре Pentium количество системных вызовов определяется количеством векторов прерываний, выделенных для этой цели из общего пула в 256 элементов (часть которых используется под аппаратные прерывания и обработку исключений). [Пул (pool) – совокупность однородных динамически распределяемых объектов, например блоков памяти одинаковой длины]. Добавление нового системного вызова требует от системного программиста тщательного поиска свободного элемента в таблице прерываний, которого к тому же на каком-то этапе развития ОС может и не оказаться.
В большинстве ОС системные вызовы обслуживаются по централизованной схеме, основанной на существовании диспетчера системных вызовов (рисунок 1.16, б). При любом системном вызове приложение выполняет программное прерывание с определённым и единственным номером вектора.
Например, ОС Linux использует для системных вызовов команду INT 80h, а ОС Windows NT (при работе на платформе Pentium) – INT 2Eh. Перед выполнением программного прерывания приложение тем или иным способом передаёт ОС номер системного вызова, который является индексом в таблице адресов процедур ОС, реализующих системные вызовы (таблица sysent на рисунке 1.16, б). Способ передачи зависит от реализации, например, номер можно поместить в определённый регистр общего назначения процессора или передать через стек (в этом случае после прерывания и перехода в привилегированный режим их нужно будет скопировать в системный стек из пользовательского; это действие в некоторых процессорах автоматизировано). Также некоторым способом передаются аргументы системного вызова, они могут как помещаться в регистры общего назначения, так и передаваться через стек или массив, находящийся в оперативной памяти. Массив удобен при большом объёме данных, передаваемых в качестве аргументов, при этом в регистре общего назначения указывается адрес этого массива.
93


 Таблица
прерываний
системы
Таблица
прерываний
системы
Виртуальное адресное пространство системы
 Системный
вызов
Системный
вызов
Вектор=22h
|
|
… |
|
|
|
Адрес процедуры 21h |
|
|
|
Адрес процедуры 22h |
|
|
|
Адрес процедуры 23h |
|
|
|
… |
|
|
|
|
|
Процедура обработки системного вызова 21h |
|
Процедура обработки системного вызова 22h |
|
Процедура обработки системного вызова 23h |
|
а
Системный вызов
Вектор=80h
R0=22h
Таблица прерываний системы
 R0
R0
Адрес диспетчера системных вызовов
Диспетчер системных вызовов
Процедура обработки системного вызова 21h
Таблица sysent
… |
Адрес процедуры 21h |
Адрес процедуры 22h |
Адрес процедуры 23h |
… |
Процедура обработки системного вызова 22h
Процедура обработки системного вызова 23h
б
Рисунок 1.16 – Децентрализованная (а) и централизованная (б)
схема обработки системных вызовов
Диспетчер системных вызовов обычно представляет собой простую программу, которая сохраняет содержимое регистров процессора в системном стеке (поскольку в результате программного прерывания процессор переходит в привилегированный режим), проверяет, попадает ли запрошенный номер вызова в
94
поддерживаемый ОС диапазон (т.е. не выходит ли номер за границы таблицы) и передаёт управление процедуре ОС, адрес которой задан в таблице системных вызовов. После завершения работы системного вызова управление возвращается диспетчеру, при этом он получает также код завершения этого вызова. Диспетчер восстанавливает регистры процессора, помещает в определённый регистр код возврата и выполняет инструкцию возврата из прерывания, которая восстанавливает непривилегированный режим работы процессора.
Описанный табличный централизованный способ организации системных
вызовов принят практически во всех операционных системах. Он позволяет легко модифицировать состав системных вызовов, просто добавив новый адрес и расширив диапазон допустимых номеров вызовов. Заметим, что в общем случае в ОС реализуется двухуровневый механизм планирования работ. Верхний уровень планирования выполняется диспетчером прерываний, который распределяет процессорное время между потоком поступающих запросов на прерывания различных типов – внешних, внутренних и программных. Оставшееся процессорное время распределяется планировщиком потоков на основании принятой дисциплины (алгоритма) планирования (см. пункты 1.1.7-1.1.11).
1.2.5.2 ОС может выполнять системные вызовы в синхронном или
асинхронном режимах. Синхронный системный вызов означает, что процесс, сделавший такой вызов, приостанавливается (переводится планировщиком ОС в состояние ожидания) до тех пор, пока системный вызов не выполнит всю требующуюся от него работу. После этого планировщик переводит процесс в состояние готовности и при очередном выполнении процесс гарантированно может воспользоваться результатами завершившегося к этому времени системного вызова. Синхронные вызовы называются также блокирующими, так как вызвавший системное действие процесс блокируется до его завершения.
Асинхронный системный вызов не приводит к переводу в состояние ожидания после выполнения некоторых начальных системных действий (например, запуска операции ввода-вывода) и управление возвращается прикладному процессу, который занимается другой работой и время от времени производит проверку события «завершение системного вызова».
Большинство системных вызовов в операционных системах являются синхронными, так как этот режим избавляет приложение от работы по выяснению момента появления результата вызова, т.е. момента его завершения. Вместе с тем в новых версиях ОС количество асинхронных системных вызовов постепенно увеличивается, что даёт больше свободы разработчикам сложных приложений. Особенно нужны асинхронные системные вызовы в ОС на основе микроядерного подхода (переноса основного объёма функций ядра в пользовательское пространство), так как при этом в пользовательском режиме работает часть ОС и ей необходимо иметь полную свободу в организации своей работы, а такую свободу даёт только асинхронный режим обслуживания вызовов микроядром (микроядро работает только в привилегированном режиме).
Вытесняющие и невытесняющие алгоритмы планирования
1.1.7.1 В самом общем виде всё множество алгоритмов планирования
можно разделить на два класса:
– невытесняющие (non-preemptive) (без переключения, без перераспределения или без реквизиции) алгоритмы планирования основаны на том, что активному потоку позволяется выполняться до тех пор, пока он сам, по собственной инициативе, не отдаст управление ОС для того, чтобы та выбрала из очереди другой готовый к выполнению поток;
– вытесняющие (preemptive) (с переключением, с перераспределением или с реквизицией) алгоритмы планирования предполагают, что решение о переключении процессора с выполнения одного потока на выполнение другого потока принимается операционной системой, а не активной задачей.
1.1.7.2 Основным различием между вытесняющими и невытесняющими алгоритмами планирования является степень централизации механизма планирования потоков. При вытесняющем мультипрограммировании функции
планирования потоков целиком сосредоточены в ОС и программист пишет своё приложение, не заботясь о том, что оно будет выполняться одновременно с другими задачами. При этом ОС выполняет следующие задачи: определяет момент снятия с выполнения активного потока, запоминает его контекст, выбирает из очереди готовых потоков следующий, запускает новый поток на выполнение, загружая его контекст. При невытесняющем мультипрограммировании механизм планирования распределён между ОС и прикладными программами. Прикладная программа, получив управление от ОС, сама определяет момент завершения очередного цикла своего выполнения и только затем передаёт управление ОС с помощью какого-либо системного вызова. ОС формирует очереди потоков и выбирает в соответствии с некоторым правилом (например, с учётом приоритетов) следующий поток на выполнение. Такой механизм создаёт проблемы как для пользователей, так и для разработчиков приложений.
Для пользователей это означает, что управление системой теряется на произвольный период времени, который определяется приложением (а не пользователем). Поэтому разработчики приложений для ОС с невытесняющей многозадачностью (кооперативной многозадачностью) вынуждены, возлагая на себя часть функций планировщика, создавать приложения так, чтобы они выполняли свои задачи небольшими частями. Подобный метод разделения времени между задачами работает, но он существенно затрудняет разработку программ и предъявляет повышенные требования к квалификации программиста. Программист должен обеспечить «дружественное» отношение своей программы к другим выполняемым одновременно с ней программам. Для этого в программе должны быть предусмотрены частые передачи управления операционной системе. Крайним проявлением «недружественности» приложения
является его зависание, которое приводит к общему краху системы. В системах же с вытесняющей многозадачностью такие ситуации, как правило, исключены,
55
так как центральный планирующий механизм имеет возможность снять зависшую задачу с выполнения.
Однако распределение функций планирования потоков между системой и
приложениями не всегда является недостатком, а при определённых условиях может быть и преимуществом, потому что даёт возможность разработчику приложений самому проектировать алгоритм планирования, наиболее подходящий для данного фиксированного набора задач. Так как разработчик сам определяет в программе момент возвращения управления, то при этом исключаются нерациональные прерывания программ в «неудобные» для них моменты времени. Кроме того, легко разрешаются проблемы совместного использования данных: задача во время каждого цикла выполнения использует их монопольно и уверена, что на протяжении этого периода никто другой не изменит данные. Существенным преимуществом невытесняющего планирования является
более высокая скорость переключения с потока на поток.
1.1.7.3 Почти во всех современных ОС, ориентированных на высокопроизводительное выполнение приложений (UNIX, Windows NT/2000/ХР, OS/2, VAX/VMS), реализованы вытесняющие алгоритмы планирования потоков (процессов). Они также реализованы и в ОС класса настольных систем, таких как OS/2 Warp и Windows 95 и выше. Примером эффективного использования невытесняющего планирования являются файл-серверы NetWare 3.x и 4.x, в которых в значительной степени благодаря такому планированию достигнута высокая скорость выполнения файловых операций. В соответствии с концепцией невытесняющего планирования, чтобы не занимать процессор слишком долго, поток в NetWare сам отдаёт управление планировщику ОС, используя следующие системные вызовы:
– ThreadSwitch – поток, вызвавший эту функцию, считает себя готовым к
немедленному выполнению, но отдаёт управление для того, чтобы могли выполняться и другие потоки;
– TreadSwitchWithDelay – функция аналогична предыдущей, но поток считает, что будет готов к выполнению только через определённое количество переключений с потока на поток;
– Delay – функция аналогична предыдущей, но задержка даётся в миллисекундах;
– ThreadSwitchLowPriority – функция передачи управления, отличается от ThreadSwitch тем, что поток просит поместить его в очередь готовых к выполнению, но низкоприоритетных потоков.
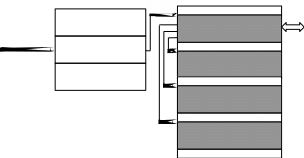
Планировщик NetWare использует несколько очередей готовых потоков (рисунок 1.5). Только что созданный поток попадает в конец очереди RunList, которая содержит готовые к выполнению потоки. После отказа от процессора
поток попадает в ту или иную очередь в зависимости от того, какой из системных вызовов был использован при передаче управления. Очередь WorkToDoList является в системе самой приоритетной. В эту очередь попадают
56
Очередь готовых потоков
Только что создан-
ные потоки
Рабочие потоки
Высокоприоритет- ная очередь гото- вых рабочих пото- ков WorkToDoList
ThreadSwitch
Какой вызов
был использован для
передачи управле-
ния?
 Delay
или
ThreadSwitch-
WithDelay
Delay
или
ThreadSwitch-
WithDelay
Основная очередь
RunList
завершение условия ожидания
Готовность с задержкой DelayedWorkToDo List
Выполнение
Процес сор
отказ от процес- сора
ThreadSwitchLowPriority
Низкоприоритет- ная очередь LowPriorityRunList
Рисунок 1.5 – Схема невытесняющего механизма планирования потоков в ОС NetWare
так называемые рабочие потоки. Пул (pool – область памяти) рабочих потоков создаётся при старте системы для системных целей и выполнения срочных работ. Планировщик разрешает выполниться подряд только определённому количеству потоков из очереди WorkToDoList, а затем запускает поток из очереди RunList. Потоки, находящиеся в очереди LowPriorityRunList, запускаются на выполнение только в том случае, если очередь RunList пуста. Обычно в эту очередь назначаются потоки, выполняющие несрочную фоновую работу.
Описанный невытесняющий механизм организации многопоточной работы в ОС NetWare v.3.x и v.4.x потенциально очень производителен, но для достижения высокой производительности к разработчикам приложений для ОС
NetWare предъявляются высокие требования, так как распределение процессорного времени между различными приложениями зависит, в конечном
57
счёте, от искусства программиста.
Алгоритмы планирования на основе квантования
1.1.8.1 В основе многих вытесняющих алгоритмов планирования лежит концепция квантования. Она реализуется в системах разделения времени (СРВ). В соответствии с этой концепцией каждому потоку поочередно для выполнения выделяется ограниченный непрерывный период процессорного времени – квант. Смена активного потока происходит, если:
– поток завершился и покинул систему;
– произошла ошибка;
– поток перешёл в состояние ожидания;
– истёк квант процессорного времени, отведённый данному потоку.
Граф состояний потока, планируемого на основе квантования (разделения времени), представлен на рисунке 1.6.
Запуск (по- току предо- ставлен квант)
ВЫПОЛНЕНИЕ
Истечение кванта времени (поток исчерпал квант)
Поток завершён или ошибка
Блокировка (поток инициировал ввод- вывод)
ГОТОВНОСТЬ ОЖИДАНИЕ
Создание потока
Пробуждение (ввод-
 вывод
завершён)
вывод
завершён)
Рисунок 1.6 – Граф состояний потока в системе разделения времени
Кванты, выделяемые потокам, могут быть одинаковыми для всех потоков или различными (например, величина кванта, выделяемого потоку, может рассчитываться на основе приоритета потока). В СРВ используются две основных дисциплины планирования:
– циклическое планирование (RR) (модель «вертушка»);
– многоуровневые очереди с обратными связями (ТМ) (модель
«многоуровневая вертушка»).
1.1.8.2 При циклическом или, иначе, круговом планировании (RR – Round
58
Robin) планирование потоков осуществляется по принципу FIFO, однако каждый раз потоку предоставляется квант одинакового размера q (рисунок 1.7)
 Переключение
Переключение
Прибытие потоков Очередь (FIFO)
готовых потоков
ЦП
Завершение или
q блокировка
Рисунок 1.7 – Планирование по циклическому принципу (RR)
Если в системе имеется n потоков, то время, которое поток проводит в ожидании следующего кванта, можно грубо оценить как q(n–1). Если квант q мал, то суммарное время Wож, которое поток проводит в ожидании ЦП, приблизительно равно
Wож
B q (n 1)
q
B (n
1) , (1.1)
где В – требуемое время выполнения (B/q – количество циклов выполнения).
Соотношение (1.1) весьма приблизительно и основано на предположении, что В>>q, при этом не учитывается то, что потоки могут использовать кванты не полностью, что часть времени они могут тратить на ввод-вывод, что количество потоков в системе (n) может динамически меняться и т.д.
Чем больше квант q, тем выше вероятность того, что потоки завершатся в результате первого же цикла выполнения, и тем менее явной
становится зависимость времени ожидания (Wож) потоков от времени их выполнения (В) [см. (1.1)]. При достаточно большом кванте алгоритм квантования вырождается в планирование по принципу FIFO (одна из разновидностей бесприоритетной дисциплины планирования без переключения), при котором время ожидания задачи в очереди вообще никак не зависит от её длительности. «Оптимальное» значение кванта выбирается из двух условий:
– он (квант) должен быть больше времени переключения процессора (это необходимое условие);
– большинство (свыше 50%) потоков, обрабатывающих интерактивные
запросы, должно выполняться в течение кванта.
Если время выполнения потока В считать случайной величиной с экспоненциальным законом распределения с параметром μ=1/mB (mB – математическое ожидание времени выполнения), то величина кванта может
59
быть определена из следующего соотношения:
P{B
q} F (q)
F (0)
0,5;
1 e mq
(1 e
m 0 )
0,5;
e mq
mq
0,5;
ln 0,5;
q 1 ln 2
m
mB ln 2
0,693
mB . (1.2)
Заметим, что типичное значение кванта в СРВ составляет десятки миллисекунд.
Дисциплина циклического обслуживания называется иногда моделью типа
«вертушка» (круговоротом). Анализ модели «вертушка» довольно сложен [мы не имеем в виду формулы (1.1), (1.2), выведенные при больших допущениях], однако при стремлении q→0 (при стремлении кванта к нулю), т.е. пренебрегаем временем переключения процессора, модель оказывается очень простой. В этой модели, называемой «разделённый процессор», всё происходит таким образом, как если бы каждому потоку мгновенно (без задержки) выделялся процессор, скорость работы которого равнялась бы скорости реального процессора в
данный момент, делённой на текущее число выполняемых потоков. В модели
«разделённого процессора» время ожидания в очереди готовности равно
Wож (B)
r B /(1
r ) , (1.3)
а время ответа (реакции)
Wотв (B)
B /(1
r ) , (1.4)
где r
l m – степень загруженности системы (для работоспособных систем ρ<1);
λ – интенсивность поступления потоков в систему.
Таким образом [см. формулу (1.4)], модель «разделённого процессора» реализует «справедливое» распределение, т.е. время, отводимое в системе потоку, пропорционально длительности (В) запрашиваемого обслуживания.
Разновидностями циклического планирования являются дисциплины с квантом переменного размера, т.е. кванты, выделяемые одному потоку, могут изменяться в разные периоды жизненного цикла потока. Пусть, например, первоначально каждому потоку назначается достаточно большой квант, а величина каждого следующего кванта уменьшается до некоторой заданной величины. В таком случае преимущество получают короткие задачи, которые успевают выполняться в течение первого кванта, а длительные вычисления (длинные задачи) будут проводиться в фоновом режиме.
Можно также представить себе алгоритм планирования, в котором
60
каждый следующий квант, выделяемый определённому потоку, больше предыдущего. Такой подход позволяет уменьшить накладные расходы на переключение задач в том случае, когда сразу несколько задач выполняют длительные вычисления.
Общим для дисциплины планирования RR и её разновидностей является их бесприоритетность, поскольку во всех случаях прибывающие потоки и реквизированные потоки ставятся в очередь готовности по правилу FIFO.
1.1.8.3 Дисциплиной планирования, в которой дополнительно уменьшается время обслуживания коротких потоков, является модель многоуровневой
«вертушки». Многоуровневые очереди с обратной связью состоят из N подочередей: F1,…,FN. С каждой очередью Fi связан квант qi, величина которого обычно растёт с увеличением i. Когда квант времени израсходован на поток из очереди Fi, а соответствующий поток ещё не завершён, то он помещается в очередь Fi+1; потоки из последней очереди FN возвращаются в эту же очередь. Новые потоки поступают в очередь F1; поток из очереди Fi обрабатывается только в том случае, если все очереди с мéньшими номерами i пусты (рисунок 1.8). Многоуровневая «вертушка» имеет несколько разновидностей, в частности:
– на каждом уровне выделяется квант и по его истечении поток переходит на следующий уровень и так вплоть до очереди самого нижнего уровня, которая реализует принцип циклического обслуживания RR и в которой данный поток циркулирует вплоть до завершения (квант может быть постоянным, либо увеличиваться при переходе потока в каждую очередь более низкого уровня);
– в очереди Fi поток получает Ni порций обслуживания размером Ii прежде чем перейти в очередь Fi+1; обычно Ni>Nj и Ii>Ij при i>j; попав в очередь FN поток остаётся в ней до полного завершения;
– может быть предусмотрено использование не относительных, а абсолютных приоритетов; в этом случае выполняющийся поток прерывается (уровня j), если поступает новый поток в очередь более высокого уровня i (i<j).
Многоуровневая «вертушка» реагирует на различные типы потоков. Этот механизм оказывает предпочтение коротким потокам и потокам, лимитируемым вводом-выводом. Для этого квант времени для первой очереди выбирается достаточно большим с тем, чтобы подавляющее большинство потоков, связанных с вводом-выводом, успевало выдать запрос ввода-вывода ещё до истечения первого кванта. Когда подобный поток выдаёт запрос ввода- вывода, то он выходит из сети очередей, причём, получив истинно приоритетное обслуживание, что и требовалось. Данная дисциплина планирования допускает при этом риск отстранения от ЦП длинных потоков.
Многоуровневые очереди с обратными связями – это идеальный механизм,
позволяющий разделять потоки на категории в соответствии с их
61
qi
ЦП Уровень 1 (под-
|
|
|
|
|
|
Прибытие Очередь (FIFO)
потоков готовых потоков
Очередь (FIFO)
готовых потоков
 …
…
Завершение или блокировка
очередь F1)
Уровень 2 (под-
очередь F2)
…
Очередь (FIFO)
готовых потоков
Очередь (FIFO)
готовых потоков
Уровень N-1 (подочередь FN-1)
Уровень N (подочередь FN)
Переключение
Рисунок 1.8 – Многоуровневые очереди с обратными связями
потребностями во времени ЦП. В СРВ каждый раз, когда поток выходит из сети очередей, он может быть помечен признаком очереди самого низкого уровня, в которой он побывал. Когда этот поток впоследствии вновь войдёт в сеть очередей, он будет направлен прямо в ту очередь, в которой он последний раз завершал свою работу. Здесь планировщик действует на основе следующего эвристического правила: поведение потока в недавнем прошлом может служить хорошим ориентиром для определения его поведения в ближайшем будущем. Поэтому поток, лимитируемый ЦП, при своём возвращении в сеть очередей не будет помещаться в очереди более высоких уровней, где он только мешал бы обслуживать короткие потоки высокого приоритета или потоки, лимитируемые вводом-выводом. Заметим, что именно по такому алгоритму действует планировщик в операционных системах OS/2, Windows 9x, Windows NT/2000/XP и многих других. Отличия в основном заключаются в количестве очередей и в правилах, касающихся перемещения задач из одной очереди в другую.
1.1.8.4 В СРВ может использоваться квантование с предпочтением потоков, интенсивно обращающихся к вводу-выводу. Дело в том, что некоторые
62
потоки используют выделенный квант времени не полностью, например, из-за необходимости выполнения операции ввода-вывода. В результате возникает ситуация, когда потоки с интенсивными обращениями к вводу-выводу используют только небольшую часть выделенного им процессорного времени. Алгоритм планирования может исправить эту «несправедливость». В качестве компенсации за неиспользованные полностью кванты потоки получают привилегии при последующем обслуживании. Для этого планировщик создаёт две очереди готовых потоков (рисунок 1.9): очередь 1 образована потоками, которые пришли в состояние готовности в результате исчерпания кванта времени (а также вновь прибывшие потоки и потоки, которые ранее блокировались, но не в связи с осуществлением операции ввода-вывода), а очередь 2 – потоками, у которых завершилась операция ввода-вывода. При выборе потока для выполнения прежде всего просматривается вторая очередь, и только если она пуста, квант выделяется потоку из первой очереди.
Квант исчерпан
Назначен квант
ВЫПОЛНЕНИЕ
 Назначен
Назначен
Поток завершён или ошибка
Требуется ввод-вывод
Очередь готовых потоков 1
квант
ГОТОВНОСТЬ
Очередь готовых потоков 2
ОЖИДАНИЕ
Только что созданные потоки
Ввод-вывод завершён
Рисунок 1.9 – Квантование с предпочтением потоков, интенсивно обращающихся к вводу-выводу
1.1.8.5 Рассмотрим ещё один алгоритм планирования, основанный на квантовании, который может быть принципиально применим в СРВ – планирование по принципу SRT (Shortest Rest Time – «по наименьшему остающемуся времени»). Принцип SRT – это аналог принципа SJF [принцип SJF
63
(Shortest Job First – «кратчайшее задание – первым») является дисциплиной планирования без переключения, согласно которой следующим для выполнения выбирается ожидающее задание с минимальным оценочным рабочим временем, остающимся до завершения], но с переключением. По принципу SRT всегда выполняется процесс, имеющий минимальное оценочное время до завершения, причём с учётом новых поступающих процессов. Если по принципу SJF задание, которое запущено в работу, выполняется до завершения, то по принципу же SRT выполняющийся процесс может быть прерван при поступлении нового процесса, имеющего более короткое оценочное время работы (рисунок 1.10)
 Переключение
Переключение
процессы
ПоступающиеОчередь готовых процессов,
упорядоченных «по наи- меньшему остающемуся вре- мени» (по SRT)
Завершение или блокировка
ЦП
q
Прерывание обслуживаемого процесса
Рисунок 1.10 – Планирование по принципу SRT
Дисциплина SRT характеризуется более высокими накладными расходами, чем SJF (накладные расходы системы – это затраты процессорного времени для выполнения вспомогательных работ во время переключения контекстов задач). Механизм SRT должен следить за текущим временем обслуживания выполняющегося задания и обрабатывать возникающие прерывания. Поступающие в систему небольшие процессы будут выполняться почти немедленно. Однако более длительные задания будут иметь даже бόльшее среднее время ожидания и бόльший разброс времени ожидания, чем в случае SJF. Теоретически принцип SRT обеспечивает минимальные времена ожидания, однако из-за задержек на переключения может оказаться так, что в определённых ситуациях в действительности лучшие показатели будет иметь SJF.
Предположим, что поступает задание, оценочное время которого лишь немногим меньше времени, необходимого для завершения текущего задания, причём в основном процессорного времени. В этом случае механизм, реализующий
64
принцип SRT в чистом виде, пошёл бы на переключение (прерывание) обслуживаемого процесса. При этом если затраты на переключение превышают разность времён обслуживания обоих заданий, то прерывание текущего задания фактически приведёт к снижению производительности системы. Поэтому для решения данной проблемы можно предусмотреть в системе предотвращение прерывания при возникновении таких ситуаций.
В практическом плане принцип SRT имеет крупный недостаток: необходимо заранее точно знать время обслуживания процесса. В современных же СРВ не используется никакой предварительной информации о задачах. При поступлении при поступлении задачи на обработку ОС, реализующая режим разделения времени, не имеет никаких сведений о том, является ли она короткой или длинной, насколько интенсивными будут её запросы к устройствам ввода- вывода, насколько важно её быстрое выполнение и т.д. Дифференциация же
обслуживания при квантовании базируется на «истории существования» потока в системе.
Алгоритмы планирования на основе приоритетов
1.1.9.1 Другой важной концепцией, лежащей в основе многих вытесняющих алгоритмов планирования, является приоритетное обслуживание. Приоритет – это число, характеризующее степень привилегированности потока при использовании ресурсов вычислительной машины, в частности, процессорного времени: чем выше приоритет, тем выше привилегии, тем меньше времени будет проводить поток в очередях. Приоритет может выражаться целым или дробным, положительным или отрицательным значением. В одних ОС принято, что приоритет потока тем выше, чем больше (в арифметическом плане) число, обозначающее приоритет; в других системах, наоборот, чем меньше число, тем выше приоритет.
В большинстве ОС, поддерживающих потоки, приоритет потока непосредственно связан с приоритетом процесса, в рамках которого выполняется данный поток. Приоритет процесса назначается ОС при его создании, включается в его описатель и используется при назначении приоритета потокам этого процесса. При назначении приоритета вновь созданному процессу ОС учитывает, является этот процесс системным или прикладным, каков статус пользователя, запустившего процесс, было ли явное указание пользователя на присвоение процессу определённого уровня приоритета. В случае, если поток был инициирован в результате системного вызова другим потоком (а не по команде пользователя), при назначении приоритета новому потоку ОС должна принимать во внимание значение параметров системного вызова.
1.1.9.2 Приоритеты бывают:
– динамическими, если ОС сама может изменять приоритеты потоков в зависимости от ситуации, складывающейся в системе;
– статическими (фиксированными), если приоритеты остаются
65
неизменными в течение жизни потока или же изменяются либо по инициативе самого потока при обращении его с соответствующим вызовом к ОС, либо по инициативе пользователя, когда он выполняет соответствующую команду;
– относительными, если из очереди готовых потоков после освобождения
ЦП выбирается поток, имеющий наивысший приоритет (рисунок 1.11,а);
– абсолютными, если готовый поток с приоритетом, превосходящим приоритет активного потока, может прервать его выполнение (рисунок 1.11,б).
Выбор по
ВЫПОЛНЕНИЕ
Поток завершён или ошибка
приоритету Требуется ввод-вывод
ГОТОВНОСТЬ ОЖИДАНИЕ
Создание потока
 Ввод-вывод
завершён
Ввод-вывод
завершён
а
Выбор по приоритету
ВЫПОЛНЕНИЕ
В очереди появился
Требуется
Поток завершён или ошибка
поток с более вы-
 соким
приоритетом
соким
приоритетом
ввод-вывод
ГОТОВНОСТЬ ОЖИДАНИЕ
Создание потока
Ввод-вывод завершён
б
Рисунок 1.11 – Граф состояний потоков в системах с относительными
(а) и абсолютными (б) приоритетами
1.1.9.3 В современных ОС во избежание разбалансировки системы,
66
которая может возникнуть при неправильном назначении приоритетов, возможности пользователей влиять на приоритеты процессов и потоков стараются ограничивать и в большинстве случаев ОС присваивает приоритеты потокам по умолчанию.
В качестве примера рассмотрим схему назначения приоритетов потокам,
принятую в ОС Windows NT/2000/ХР (рисунок 1.12). В системе определено
32 уровня приоритетов и 2 класса потоков – потоки реального времени и потоки с переменными приоритетами (variable priority).
Потоки с переменным приоритетом
Потоки реального времени
Динамический приоритет потоков процесса
Базовый приоритет потоков процесса
 Базовый
приоритет
процесса
Базовый
приоритет
процесса
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
Рисунок 1.12 – Схема назначения приоритетов в Windows NT/2000/ХР
Заметим, что в операционных системах Windows NT/2000/ХР используется один и тот же планировщик задач. Здесь имеется группа очередей – по одной для каждого приоритета. Диапазон от 1 до 15 включительно отведён для потоков с переменными приоритетами, а от 16 до 31 – для более критичных по времени выполнения потоков реального времени (приоритет 0 зарезервирован для системных целей). При создании процесса он получает по умолчанию базовый приоритет k, который в дальнейшем может быть повышен или понижен ОС. Все потоки данного процесса получают базовые приоритеты из диапазона [k–2, k+2]. Отсюда видно, что, изменяя базовый приоритет процесса, ОС может влиять на базовые приоритеты его потоков.
Большинство задач в системе относятся к классу переменного приоритета с
67
уровнями приоритета (номером очереди) от 1 до 15. В Windows NT/2000/ХР с течением времени приоритет потока, относящегося к классу потоков с переменными приоритетами, может отклоняться от базового приоритета потока, причём эти изменения могут быть не связаны с изменениями базового приоритета процесса. ОС может повышать приоритет потока в тех случаях, когда поток не полностью использовал отведённый ему квант (процессорного времени), или понижать приоритет до базового, если квант был использован полностью или поток выполняет вычисления. Причём ОС наращивает приоритет дифференцированно в зависимости от того, какого типа событие не дало потоку полностью использовать квант. В частности, ОС повышает приоритет в бóльшей степени потокам, которые ожидают ввода с клавиатуры (интерактивным приложениям), и в мéньшей степени – потокам, выполняющим дисковые операции. Именно на основе динамических приоритетов осуществляется планирование потоков. Планировщик просматривает очереди, начиная с самой приоритетной. При этом если очередь пуста, т.е. в ней нет готовых к выполнению потоков с таким приоритетом, то осуществляется переход к следующей очереди. Следовательно, если есть задачи, требующие процессор немедленно, то они будут обслужены в первую очередь. Причём система прекращает исполнение, или, иначе, вытесняет (preempts), текущий поток, если становится готовым к выполнению другой поток с более высоким приоритетом.
1.1.9.4 В системах, в которых планирование осуществляется на основе относительных приоритетов, минимизируются затраты на переключение процессора с одной работы на другую (пример такой системы приведен в пункте 1.1.7 на рисунке 1.5). Ясно, что для систем разделения времени и реального времени такая дисциплина обслуживания не подходит (по крайней мере, в чистом виде): интерактивное приложение может ждать своей очереди
часами, пока вычислительной задаче не потребуется ввод-вывод (относительные приоритеты в сочетании с квантованием используются в СРВ – см. пункт 1.1.8). В системах же пакетной обработки (например, в ОС OS/360) относительные приоритеты используются широко. Планирование на основе абсолютных приоритетов является подходящим для систем управления объектами, в которых важна быстрая реакция на событие.
Смешанные алгоритмы планирования
1.1.10.1 Во многих ОС алгоритмы планирования построены с использованием как концепции квантования, так и приоритетов. Например, в основе планирования лежит квантование, но величина кванта и/или порядок выбора потока из очереди готовых определяется приоритетами потоков. Именно так реализовано планирование в операционных системах Windows NT/2000/ХР, в которых квантование сочетается с динамическими
абсолютными приоритетами. На выполнение выбирается готовый поток с наивысшим приоритетом. Ему выделяется квант времени. Если во время выполнения в очереди готовых появляется поток с более высоким приоритетом,
68
то он вытесняет выполняемый поток. Вытесненный поток возвращается в очередь готовых, причём он становится впереди всех остальных потоков, имеющих такой же приоритет.
1.1.10.2 Другим примером использования смешанных алгоритмов планирования является ОС UNIX System V Release 4. В этой ОС понятие «поток» отсутствует, и планирование осуществляется на уровне процессов. В системе UNIX System V Release 4 реализована вытесняющая многозадачность, основанная на использовании приоритетов и квантования.
Каждый процесс в зависимости от задачи, которую он решает,
относится к одному из трёх определённых в системе приоритетных классов:
– классу реального времени;
– классу системных процессов;
– классу процессов разделения времени.
Назначение и обработка приоритетов выполняются для разных классов по-разному. Процессы системного класса, зарезервированные для ядра ОС, используют стратегию фиксированных приоритетов. Уровень приоритета процессу назначается ядром ОС и никогда не изменяется. [Ядро – модули, выполняющие основные функции ОС (управление процессами, памятью, устройствами ввода-вывода и т.п.; ядро составляет сердцевину ОС, без него ОС является полностью неработоспособной и не сможет выполнить ни одну из своих функций. В состав ядра входят функции, решающие внутрисистемные задачи организации вычислительного процесса, такие как переключение контекстов, загрузка/выгрузка страниц, обработка прерываний. Другой класс функций ядра служит для поддержки приложений, создавая для них так называемую прикладную программную среду (API). Вообще, термин «ядро» в разных ОС трактуется по-разному. Одним из определяющих свойств ядра является работа в привилегированном режиме]. Процессы реального времени также используют стратегию фиксированных приоритетов, но пользователь может их изменять. Так как при наличии готовых к выполнению процессов реального времени другие процессы не рассматриваются, то процессы реального времени надо тщательно проектировать, чтобы они не захватывали процессор на слишком долгое время. Характеристики планирования процессов реального времени включают две величины: уровень глобального приоритета и квант времени. Для каждого уровня приоритета по умолчанию имеется своя величина кванта времени. Процессу разрешается захватывать процессор на указанный квант времени, а по истечении его планировщик снимает процесс с выполнения.
Процессы разделения времени были до появления ОС UNIX System V Release 4 единственным классом процессов, и по умолчанию ОС UNIX System V Release 4 назначает новому процессу именно этот класс. Состав класса процессов
разделения времени наиболее неопределённый и часто меняющийся в отличие от системных процессов и процессов реального времени. Для справедливого
69
распределения времени процессора между процессами в этом классе используется стратегия динамических приоритетов. Причём величина приоритета, назначаемого процессам разделения времени, вычисляется пропорционально значениям двух составляющих: пользовательской части и системной части. Пользовательская часть приоритета может быть изменена администратором и владельцем процесса, но в последнем случае только в сторону его снижения. Системная составляющая позволяет планировщику управлять процессами в зависимости от того, как долго они занимают процессор, не уходя в состояние ожидания (блокировки). У тех процессов, которые потребляют большие периоды процессорного времени без ухода в состояние ожидания, приоритет снижается, а у тех процессов, которые часто уходят в состояние ожидания после короткого периода использования процессора, приоритет повышается. Таким образом, процессам, ведущим себя не «по-джентльменски», даётся низкий приоритет. Это означает, что они реже выбираются для выполнения. Это ущемление в правах компенсируется тем, что низкоприоритетным процессам даются бóльшие кванты времени, чем процессам с высокими приоритетами (похоже на многоуровневую вертушку). Таким образом, хотя низкоприоритетный процесс и не работает так часто, как высокоприоритетный, но зато, когда он, наконец, выбирается для выполнения, ему отводится больше процессорного времени.
1.1.10.3 Ещё один пример относится к ОС OS/2. Планирование здесь основано на использовании квантования и абсолютных динамических приоритетов и немного похоже на планирование в ОС Windows NT/2000/ХР. Как известно, одно время компания Microsoft принимала активное участие в разработке OS/2 совместно с фирмой IBM. Поэтому после прекращения совместных работ над этой операционной системой и начале нового проекта многие решения из OS/2 были унаследованы в варианте OS/2 v.3.0, названной
впоследствии Windows NT. В OS/2 определены четыре класса приоритетов:
 –
критический
(time
critical)
(реального
времени);
–
критический
(time
critical)
(реального
времени);
– серверный (server) (приоритетный); понижение
– стандартный (regular) (регулярный); приоритета
– остаточный (idle),
в каждом из которых имеется 32 приоритетных уровня. Итого, 128 различных уровней и, соответственно, 128 возможных очередей готовых к выполнению потоков. Потоки критического класса, называемые в обиходе потоками реального времени, имеют наивысший приоритет. К этому классу могут быть отнесены, например, системные потоки, выполняющие задачи коммуникаций (например, задача управления последовательным портом, на который приходят биты по коммутируемой линии с подключённым модемом, или задачи управления сетевым оборудованием). Если такие задачи не получат управление в нужный момент
времени, то сеанс связи может прерваться. Следующий по приоритетности класс, как это следует из его названия, предназначен для потоков, выполняющих по отношению к остальным задачам функции сервера (модель «клиент-сервер»
70
предполагает наличие программного компонента – потребителя какого-либо сервиса, называемого клиентом, и программного компонента – поставщика этого сервиса, или сервера; по модели «клиент-сервер» строятся современные ОС с микроядерной архитектурой). Большинство задач относят к стандартному классу; по умолчанию система программирования порождает задачу, относящуюся к этому классу. Потоки, входящие в остаточный класс, имеют самый низкий приоритет. К этому классу относятся фоновые задачи, например, поток, выводящий на экран заставку, или программа проверки электронной почты, выполняющиеся тогда, когда в системе не выполняется никакой другой работы. Поток из менее приоритетного класса не может быть выбран для выполнения, пока в очереди более приоритетного класса имеется хотя бы один поток. Внутри каждого класса потоки выбираются также по приоритетам. Потоки с одинаковым приоритетом обслуживаются в циклическом порядке в соответствии с дисциплиной RR. OS/2 самостоятельно изменяет приоритет выполняющихся программ; независимо от уровня, установленного самим приложением; этот механизм называется повышением приоритета (priority boost). Приоритеты могут изменяться планировщиком в следующих случаях:
– повышение приоритета «забытой» задачи (starvation boost) – если поток находится в ожидании процессора дольше, чем это задано системной переменной MAXWAIT, то планировщик временно присвоит ему уровень приоритета, не превышающий нижней границы критического класса (этот промежуток времени в секундах задаёт оператор MAXWAIT в файле CONFIG.SYS). В результате переключение на такую «забытую» программу происходит быстрее. После выполнения потока в течение одного кванта времени его приоритет вновь снижается до остаточного. В сильно загруженных системах этот механизм позволяет программам с остаточным приоритетом
работать хотя бы в краткие интервалы времени; в противном случае они вообще никогда бы не получили управление;
– повышение приоритета ввода-вывода (Input/Output boost) – если поток ушёл на выполнение операции ввода-вывода, то после её завершения он получит наивысшее значение приоритета своего класса;
– повышение приоритета активного потока (foreground boost) – приоритет потока автоматически повышается, когда он поступает на выполнение; это снижает время ответа активного приложения на действия пользователя по сравнению с фоновыми программами.
Заметим, что если нет необходимости в OS/2 использовать метод динамического изменения приоритета, то с помощью оператора PRIORITY=ABSOLUTE в файле CONFIG.SYS можно ввести дисциплину абсолютных приоритетов – по умолчанию оператор PRIORITY имеет значение
DYNAMIC.
ОС динамически устанавливает величину кванта, отводимого потоку для
71
выполнения. Величина кванта зависит от загрузки системы и интенсивности подкачки. Параметры настройки системы позволяют явно задать границы изменения кванта. В любом случае он не может быть меньше 32мс и больше
65536мс. Если поток был прерван до истечения кванта, то следующий выделенный ему интервал выполнения будет увеличен на время, равное одному периоду таймера (около 32мс), и так до тех пор, пока квант не достигнет заранее заданного при настройке ОС предела. Благодаря такому алгоритму планирования в OS/2 ни один поток не будет «забыт» системой и получит достаточно процессорного времени.
Стратегии перепланировки потоков
1.1.12.1 Для реализации алгоритма планирования ОС должна получать управление всякий раз, когда в системе происходит событие, требующее перераспределение процессорного времени (вмешательство планировщика). К таким событиям относятся (это неполный список событий):
– прерывание от таймера по истечении кванта времени, выделенного активной задаче (планировщик переводит задачу в состояние готовности и выполняет перепланирование);
– активная задача выполнила системный вызов, связанный с запросом на ввод-вывод или на доступ к ресурсу, который в настоящий момент занят
75
(например, файл данных) (планировщик переводит задачу в состояние ожидания и выполняет перепланирование);
– активная задача выполнила системный вызов, связанный с
освобождением ресурса (планировщик проверяет, не ожидает ли этот ресурс какая-либо задача; если «да», то эта задача переводится из состояния ожидания в состояние готовности; при этом, возможно, задача, которая получила «добро» на ресурс, имеет более высокий приоритет, чем текущая задача; после перепланирования более приоритетная задача получает доступ к процессору, вытесняя текущую задачу);
– внешнее (аппаратное) прерывание, которое сигнализирует о завершении периферийным устройством операции ввода-вывода (планировщик переводит соответствующую задачу в очередь готовых и выполняет перепланировку);
– внутреннее прерывание сигнализирует об ошибке, которая произошла в
результате выполнения активной задачи (планировщик снимает задачу и выполняет перепланирование).
При возник4новении каждого из этих событий (и не только этих) планировщик выполняет просмотр очередей и решает вопрос о том, какая задача будет выполняться следующей. Помимо указанных существует и ряд других событий (часто связанных с системными вызовами), требующих перепланировки. Например, запросы приложений и пользователей на создание новой задачи или повышение приоритета уже существующей задачи создают новую ситуацию, которая требует пересмотра очередей и, возможно, переключения процессора на выполнение другой задачи.
1.1.12.2 На рисунке 1.13 показан фрагмент временнóй диаграммы работы планировщика в системе с четырьмя потоками. В данном случае неважно, по какому правилу выбираются потоки на выполнение и каким образом изменяются
их приоритеты; существенное значение имеют лишь события, вызывающие активизацию планировщика.
Первые четыре цикла работы планировщика (интервалы 1-4) были инициированы прерываниями от таймера по истечении квантов времени (событие Т).
Следующая передача управления планировщику была осуществлена в результате выполнения потоком 3 системного запроса на ввод-вывод (событие I/O). Планировщик перевёл этот поток в состояние ожидания (интервал
5), а затем переключил процессор на поток 2. Поток 2 полностью использовал свой квант, произошло прерывание от таймера, и планировщик активизировал поток 1 (интервал 6).
При выполнении потока 1 произошло событие R – системный вызов, в результате которого освободился некоторый ресурс (например, был закрыт файл).
Это событие вызвало перепланировку потоков (интервал 7): планировщик просмотрел очередь ожидающих потоков и обнаружил, что поток 4 ждёт освобождения данного ресурса. Этот поток был переведен в состояние готовности,
76
но поскольку приоритет выполняющегося (прерванного на интервал 7 событием R) в данный момент потока 1 выше приоритета потока 4, планировщик вернул процессор потоку 1.
Плани-
ровщик
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Поток 1
Поток 2
Поток 3
Поток 4
T↑ T↑ R↑ T↑ T↑ S↑ S↑ R↑ T↑
 T↑ T↑ ER↑
T↑ T↑ ER↑
T↑ I/O↑ T↑
T↑ T↑
Условные обозначения событий: t
Т – истечение кванта времени;
I/O – запрос на ввод-вывод;
R – системный вызов, связанный с освобождением
некоторого ресурса (например, закрытие файла); ER – возникновение ошибки (внутреннее прерывание);
S – завершение операции ввода-вывода (внешнее прерывание)
Рисунок 1.13 – Моменты перепланировки потоков
В следующем цикле (интервал 8) работы планировщик активизировал поток 4, а затем, после истечения кванта и сигнала от таймера, управление получил поток 2 (интервал 9). Поток 2 не успел использовать свой квант, так как был снят с выполнения в результате возникшей ошибки (событие ER).
Далее планировщик предоставлял процессорное время потокам 1, 4 и снова
77
1 (интервалы 10-12). Во время выполнения потока 1 произошло прерывание S от внешнего устройства, сигнализирующее о том, что операция передачи данных (I/O) завершена. Это событие активизировало работу планировщика (интервал 13), в результате которой поток 3, ожидавший завершения ввода-вывода, вытеснил поток 1, так как имел в этот момент более высокий приоритет.
Последний показанный на диаграмме период выполнения потока 1 прерывался несколько раз. Вначале это было прерывание от внешнего устройства (S), затем программное прерывание (R), вызвавшее освобождение ресурса, и, наконец, прерывание от таймера (Т). Каждое из этих трёх прерываний вызвало перепланировку потоков. В двух первых случаях планировщик (интервалы 15, 16) оставил выполняться поток 1, так как в очереди не оказалось более приоритетных потоков, а квант времени, выделенный потоку 1, ещё не был исчерпан. Переключение потоков (интервал 17) было выполнено только по прерыванию от
таймера (Т).
В системах реального времени для отработки статического расписания планировщик активизируется по прерываниям от таймера. Эти прерывания пронизывают всю временнýю ось, возникая через короткие постоянные интервалы времени. После каждого прерывания планировщик просматривает расписание и проверяет, не пора ли переключить задачи. Кроме прерываний от таймера в СРМВ перепланирование задач может происходить по прерываниям от внешних устройств – датчиков и исполнительных механизмов.
Цели и средства синхронизации
2.1.1 Основной особенностью мультипрограммных ОС является то, что в их среде параллельно развивается несколько (последовательных) вычислительных процессов. [Слово «последовательный» в большинстве случаев опускается. Считается, что речь идёт о вычислениях, осуществляемых на обычных
«последовательных» процессорах, которые выполняют команду за командой, а не параллельно несколько команд за один такт]. С точки зрения внешнего наблюдателя эти последовательные вычислительные процессы выполняются одновременно, мы же будем говорить «параллельно». При этом под параллельными понимаются не только процессы, одновременно развивающиеся на различных процессорах, каналах и устройствах ввода-вывода, но и те последовательные процессы, которые разделяют центральный процессор и в своём выполнении хотя бы частично перекрываются во времени. Итак, параллельными мы будем называть такие последовательные вычислительные процессы, которые одновременно находятся в каком-нибудь из активных
состояний (выполнения, готовности или ожидания). Два параллельных процесса могут быть независимыми (independed processes) либо взаимодействующими (cooperating processes).
Независимыми являются процессы, множества переменных которых не пересекаются. Под переменными в этом случае понимают файлы данных, а также области оперативной памяти, сопоставленные промежуточным и определённым в программе переменным. Независимые процессы не влияют на результаты работы друг друга, так как не могут изменять значения переменных друг друга. Они могут только явиться причиной в задержках исполнения друг друга, так как вынуждены разделять ресурсы системы.
Взаимодействующие процессы совместно используют некоторые (общие) переменные, и выполнение одного процесса может повлиять на выполнение другого. Многие ресурсы вычислительной системы могут совместно
использоваться несколькими процессами, но в каждый момент времени к разделяемому ресурсу может иметь доступ только один процесс. Ресурсы, которые не допускают одновременного использования несколькими процессами, называются критическими.
Если несколько вычислительных процессов хотят пользоваться критическим ресурсом в режиме разделения, им следует синхронизировать свои действия таким образом, чтобы ресурс всегда находился в распоряжении не более чем одного из них. Если один процесс пользуется в данный момент критическим ресурсом, то все остальные процессы, которым нужен этот ресурс,
96
должны ждать, пока он не освободится. Если в ОС не предусмотрена защита от одновременного доступа процессов к критическим ресурсам, в ней могут возникать ошибки, которые трудно обнаружить и исправить. Основной причиной возникновения этих ошибок является то, что процессы в мультипрограммных ОС развиваются с различными скоростями (асинхронно) и относительные скорости развития каждого из взаимодействующих процессов не подвластны и не известны ни одному из них. Более того, на их скорости могут влиять решения планировщиков, касающиеся других процессов, с которыми ни одна из этих программ не взаимодействует. Кроме того, содержание и скорость исполнения одного из них обычно не известны другому процессу. Поэтому влияние, которое оказывают друг на друга взаимодействующие процессы, не всегда предсказуемо и воспроизводимо.
Взаимодействовать могут либо конкурирующие процессы, либо процессы,
обрабатывающие информацию совместно. Конкурирующие процессы действуют относительно независимо друг от друга, однако они имеют доступ к некоторым общим переменным. Их независимость заключается в том, что они могут работать друг без друга, поодиночке. Но при своём выполнении они могут работать и параллельно, и тогда они иногда начинают конкурировать при обращении к этим общим переменным. Таким образом, их независимость относительна.
2.1.2 Существует достаточно обширный класс средств ОС, с помощью которых обеспечивается взаимная синхронизация процессов и потоков. Мы будем говорить о синхронизации потоков, имея в виду, что если ОС не поддерживает потоки, то всё сказанное относится к синхронизации процессов, хотя может решаться и задача синхронизации процессов в многопоточной ОС. Любое взаимодействие процессов или потоков связано с их синхронизацией, которая
заключается в согласовании их скоростей путём приостановки потока до наступления некоторого события и последующей его активизации при наступлении этого события. Таким образом, синхронизация (synchronization) – это такая связь между потоками, при которой один поток не может выполняться, начиная с определённого места (точки синхронизации), до тех пор, пока другой поток не достигнет своей определённой точки. Синхронизация лежит в основе любого взаимодействия потоков, связано ли это взаимодействие с разделением ресурсов или с обменом данными. Например, поток-получатель должен обращаться за данными только после того, как они помещены в буфер потоком-отправителем. Если же поток-получатель обратился к данным до момента их поступления в буфер, то он должен быть приостановлен.
Синхронизация также обязательна и при совместном использовании аппаратных ресурсов. Например, когда активному потоку требуется доступ к
последовательному порту, а с этим портом в монопольном режиме работает другой поток, находящийся в данный момент в состоянии ожидания, то ОС
97
приостанавливает активный поток и не активизирует его до тех пор, пока нужный ему порт не освободится. Ежесекундно в системе происходит сотни событий, связанных с распределением и освобождением ресурсов, и ОС должна иметь надёжные и производительные средства, которые бы позволяли синхронизировать потоки с происходящими в системе событиями. Во многих ОС эти средства называются средствами межпроцессного взаимодействия (Inter Process Communications – IPC), что отражает историческую первичность понятия
«процесс» по отношению к понятию «поток». Обычно к средствам IPC относят не только собственно средства межпроцессной синхронизации, но и средства межпроцессного обмена данными.
Для синхронизации потоков прикладных программ программист может использовать как собственные средства и приёмы синхронизации, так и средства операционной системы. Например, два потока одного прикладного процесса
могут координировать свою работу с помощью доступной для них обоих глобальной логической переменной, которая устанавливается в единицу при осуществлении некоторого события, например выработки одним потоком данных, нужных для продолжения работы другого. Однако, во многих случаях более эффективными или даже единственно возможными являются средства синхронизации, предоставляемые ОС в форме системных вызовов. Так, потоки, принадлежащие разным процессам, не имеют возможности вмешиваться каким- либо образом в работу друг друга. Без посредничества ОС они не могут приостановить друг друга или оповестить о произошедшем событии. Заметим, что средства синхронизации используются не только для синхронизации прикладных процессов, но и для её внутренних нужд.
Обычно разработчики ОС предоставляют в распоряжение прикладных и системных программистов широкий спектр средств синхронизации. Эти средства
могут образовывать иерархию, когда на основе более простых средств строятся более сложные, а также быть функционально специализированными, например средства для синхронизации потоков одного процесса, средства для синхронизации потоков разных процессов при обмене данными и т.д. Часто функциональные возможности разных системных вызовов синхронизации перекрываются, так что для решения одной задачи программист может воспользоваться несколькими вызовами в зависимости от своих личных предпочтений.
Необходимость синхронизации и гонки
Пренебрежение вопросами синхронизации в многопоточной системе может привести к неправильному решению задачи или даже к краху системы. Рассмотрим, например, задачу ведения базы данных (БД) клиентов некоторого предприятия. Каждому клиенту отводится отдельная запись в БЛ, в которой среди прочих полей имеются поля Заказ и Оплата. Программа, ведущая БД,
98
оформлена как единый процесс, имеющий несколько потоков, в том числе поток А, который заносит в БД информацию о заказах, поступивших от клиентов, и поток В, который фиксирует в БД сведения об оплате клиентами выставленных счетов. Оба эти потока совместно работают над общим файлом БД, используя однотипные алгоритмы из трёх шагов:
– шаг 1 – считать из файла БД в буфер запись о клиенте с заданным идентификатором (у каждого потока свой буфер);
– шаг 2 – внести новое значение в поле Заказ (для потока А) или Оплата
(для потока В);
– шаг 3 – вернуть модифицированную запись в файл БД.
Обозначим соответствующие шаги для потока А через А1, А2 и А3, а для потока В – через В1, В2 и В3. Если не предпринимать никаких усилий для синхронизации этих потоков, то результат решения задачи по ведению БД может быть непредсказуем (рисунок 2.1). Например, в БД могут быть зафиксированы сведения о том, что клиент N произвёл оплату, но информация о его заказе окажется потерянной (см. рисунок 2.1, а), или может быть потеряна информация не о заказе, а об оплате (см. рисунок 2.1, б), или, напротив, все исправления будут успешно внесены (см. рисунок 2.1, в). Все перечисленные исходы определяются взаимными скоростями потоков ми моментами их прерывания. Поэтому отладка взаимодействующих (в данном случае по информационному ресурсу – БД) потоков является сложной задачей. Ситуации, когда два или более потоков обрабатывают разделяемые данные и конечный результат зависит от соотношения скоростей потоков, называются гонками.
Критическая секция
2.3.1 Важным понятием синхронизации потоков является понятие
«критической секции» программы. В последнем примере (см. подраздел 2.2) два потока А и В взаимосвязаны по общему информационному ресурсу – файлу БД – и их называют конкурирующими. По мере своего развития они используют один и тот же ресурс, но для правильной работы над ним в каждый момент времени его может использовать только один из потоков. В этом случае говорят, что данный ресурс является для потоков критическим, или потоки находятся в состоянии взаимного исключения (конкуренции) за обладание ресурсом. Действия (программы) потоков А и В в этом случае образуют критические секции. Критическая секция (интервал, область) (critical section) – это часть программы, результат выполнения которой может непредсказуемо меняться, если переменные, относящиеся к этой части программы, изменяются другими потоками в то время, когда выполнение этой части ещё не завершено.
Критическая секция всегда определяется по отношению к определённому
99
Поток А Поток В
 А1 А2
А1 А2
 В1 В2 А3 В3
В1 В2 А3 В3
а
Поток А Поток В
 А1 В1 В2 В3 А2 А3
А1 В1 В2 В3 А2 А3
б
 Поток
А
Поток
А
Поток В
 А1 А2 А3 В1 В2 В3
А1 А2 А3 В1 В2 В3
в
 t
t
Рисунок 2.1 – Влияние относительных скоростей потоков на результат решения задачи
критическому ресурсу, например, критическим данным, при несогласованном изменении которых могут возникнуть нежелательные эффекты. В последнем примере (см. подраздел 2.2) такими критическими данными являлись записи файла БД. Во всех потоках, работающих с критическим ресурсом, должна быть определена критическая секция. Заметим, что в разных потоках критическая секция состоит в общем случае из разных последовательностей команд.
Обеспечение взаимного исключения является одной ключевых проблем параллельного программирования и любая мультипрограммная ОС должна обеспечивать тот или иной способ реализации её решения. При этом можно перечислить требования к критическим секциям:
– в любой момент времени только один поток может находиться в своей критической секции, причём неважно, находится этот поток в активном или приостановленном состоянии (состоянии ожидания);
– ни один поток не должен бесконечно долго находиться в своей критической секции;
– ни один поток не должен бесконечно долго ожидать разрешение на вход в свою критическую секцию, в частности:
1) никакой поток, бесконечно долго находящийся вне своей критической секции (что допустимо), не должен задерживать выполнение
100
других потоков, ожидающих входа в свои критические секции (другими словами, поток, работающий вне своей критической секции, не должен блокировать критическую секцию другого потока);
2) если два потока хотят войти в свои критические секции, то принятие решения о том, кто первым войдёт в критическую секцию, не должно быть бесконечно долгим;
– если поток, находящийся в своей критической секции, завершается естественным или аварийным путём, то режим взаимного исключения должен быть отменён, с тем, чтобы другие потоки получили возможность входить в свои критические секции.
2.3.2 Было предложено несколько способов решения проблемы взаимного исключения: программных и аппаратных; локальных низкоуровневых и глобальных высокоуровневых; предусматривающих свободное взаимодействие
между процессами и требующих строгого соблюдения протоколов; пригодных для потоков одного процесса и пригодных для потоков разных процессов.
Самый простой и в то же время самый неэффективный способ обеспечения взаимного исключения состоит в том, что ОС позволяет потоку запрещать любые прерывания на время его нахождения в критической секции (механизм синхронизации на основе использования системы прерываний). Очевидно, что текст программы потока, ограниченный командами блокировки и деблокирования прерываний (логические скобки), состоит из команд обработки некоторого критического ресурса, составляющих критическую секцию. В данном случае для реализации взаимного исключения критическая секция (за счёт блокировки прерываний) наделяется свойством непрерываемости (неделимости или атомарности). Данный способ в силу своей простоты является очень негибким средством, имеет низкую эффективность из-за чрезмерных задержек в
развитии потоков (процессов) и практически не применяется, так как опасно доверять управление системой пользовательскому потоку – он может надолго занять процессор, а при крахе потока в критической секции крах потерпит вся система, потому что прерывания никогда не будут разрешены. Таким образом, самый простой способ предоставить процессорное время только одному потоку (процессу) – отключить систему прерываний, поскольку тогда никакое внешнее событие не сможет прервать выполняющийся поток. Однако, это приведёт к тому, что система не сможет реагировать на внешние события.
Блокирующие переменные
2.4.1 Другим низкоуровневым аппаратным средством синхронизации потоков являются глобальные блокирующие переменные (переменные состояния), над которыми осуществляются неделимые команды (операции) «проверки-и- установки» (TS – testandset). С этими переменными, к которым все потоки
101
процесса имеют прямой доступ, программист работает, не обращаясь к системным вызовам ОС. Операция проверки и установки является, так же как и блокировка памяти (о ней будет сказано ниже), одним из аппаратных средств, которые могут быть использованы для решения задачи взаимного исключения при выполнении критической секции. Данная операция реализована во многих компьютерах.
Каждому критическому ресурсу ставится в соответствие двоичная переменная F, которая в любой момент времени характеризует состояние критического ресурса. Эта переменная принимает два значения:
– F=1 (true) – ресурс свободен, т.е. ни один из конкурирующих потоков не находится в критической секции относительно данного ресурса;
– F=0 (false) – ресурс занят,
и должна быть доступна (разделяема) всем потокам, которые с её помощью хотят использовать критический ресурс. Когда поток входит в критическую
секцию, он присваивает ей значение 0, а когда покидает её, – значение 1. Главным
фактором, обеспечивающим успех в решении задачи взаимоисключения с помощью блокирующей переменной F, является наличие единой, неделимой команды анализа и присвоения значения логической переменной F – команды
«проверки-установки» (TS – testandset) [например, команды BTC, BTR и BTS (Bit Test and Set) процессора Pentium]. При отсутствии такой команды в процессоре соответствующие действия должны реализовываться специальными системными примитивами (примитив – базовая функция ОС), которые бы запрещали прерывания на протяжении всей операции «проверки-и-установки».
2.4.2 На рисунке 2.2 показан фрагмент алгоритма потока, использующего для реализации взаимоисключающего доступа к критическому ресурсу D блокирующую переменную F(D). Перед входом в критическую секцию поток
проверяет, не работает ли уже какой-нибудь поток с критическим ресурсом D. Если переменная F(D) установлена в 0, то ресурс занят, и проверка циклически повторяется. Если же критический ресурс свободен, т.е. F(D)=1, то значение переменной F(D) устанавливается в 0 и поток входит в критическую секцию. После того как поток выполнит все действия с ресурсом D, значение переменной F(D) снова устанавливается равным 1. Если все потоки написаны с учётом вышеописанных соглашений, то взаимное исключение гарантируется. При этом потоки могут быть прерваны ОС в любой момент времени и в любом месте, в том числе в критической секции, но нельзя прервать поток между выполнением операций проверки и установки, т.е. нельзя прервать примитив захвата ресурса (поэтому он и называется примитивом). При таких особенностях использования блокирующей переменной F она сама становится критическим ресурсом. Чтобы захватить основной критический ресурс D, необходимо предварительно захватить вспомогательный – блокирующую переменную F. Каким же образом реализуется доступ взаимодействующих потоков к блокирующей переменной F? Заметим, что любая реализация доступа в конечном счёте должна основываться
102
 Попытка
доступа
к разделяемому
ресурсу
D
Попытка
доступа
к разделяемому
ресурсу
D
Неделимая операция
«проверки-установки» (примитив захвата ре- сурса)
Ресурс свободен F(D)=1?
Да

 Нет
Нет
Зацикливание пото- ка на опрос блоки- рующей перемен- ной F(D) (режим
«жужжания»)
Занять ресурс
F(D):=0
Критическая сек- ция (работа с ре- сурсом D)
Примитив освобождения ресурса
Освободить ресурс
F(D):=1

Продолжение вычислений
Рисунок 2.2 – Реализация критических секций с использованием блокирующих переменных в режиме активного (занятого) ожидания
на взаимном исключении, обеспечиваемом аппаратными средствами. Все ЭВМ имеют средство для организации взаимного исключения, называемое блокировкой (блокированием) памяти (схемой защитной блокировки памяти). Это средство запрещает одновременное исполнение двух (и более) команд, которые обращаются к одной и той же ячейке памяти. Блокировка памяти имеет место всегда, т.е. это обязательное условие функционирования компьютера. Если в этой ячейке памяти хранится значение разделяемой переменной, то во время исполнения команды обращения получить доступ к ней может только один поток, несмотря на возможное совмещение выполнения команд во времени на различных процессорах (или на одном процессоре, но с конвейерной организацией
103
параллельного выполнения команд). Таким образом, блокировка памяти предотвращает одновременный доступ, но не предотвращает чередование доступов. Кстати, пользуясь только блокировкой памяти, голландский математик Дж.Деккер впервые осуществил программную реализацию задачи взаимного исключения для двух параллельных процессов, т.е. не используя никаких средств синхронизации, а основываясь лишь на средствах языков программирования (основан на использовании трёх переменных). Реализации критических секций на основе алгоритма Деккера практически не встречаются из- за их чрезмерной сложности, особенно тогда, когда требуется обобщить алгоритм Деккера с двух до N процессов.
2.4.3 При рассмотрении двухэтапной схемы решения задачи взаимного исключения (см. рисунок 2.2) выявляется существенный недостаток режима активного (занятого) ожидания: в течение времени, когда один поток находится
в критической секции, другой поток, которому требуется тот же ресурс, получив доступ к процессору, будет непрерывно опрашивать блокирующую переменную, бесполезно тратя выделяемое ему процессорное время, которое могло бы быть использовано для выполнения какого-нибудь другого потока. Для устранения этого недостатка во многих ОС предусматриваются специальные системные вызовы для работы с критическими секциями, реализующие режим пассивного ожидания (рисунок 2.3). Перед тем как начать работу с критическим ресурсом, поток выполняет системный вызов EnterCriticalSection(). В рамках этого вызова сначала выполняется, как и в предыдущем случае (см. рисунок 2.2), проверка блокирующей переменной, отражающей состояние критического ресурса. Если системный вызов определил, что ресурс занят, т.е. F(D)=0, он в отличие от предыдущего случая не выполняет циклический опрос, а переводит поток в состояние ожидания ресурса D и делает отметку о том, что данный поток должен быть активизирован, когда соответствующий ресурс освободится. Поток, который в это время использует данный ресурс, после выхода из критической секции должен выполнить системную функцию LeaveCriticalSection(), в результате чего блокирующая переменная принимает значение, соответствующее свободному состоянию ресурса, т.е. F(D):=1, а ОС просматривает очередь ожидающих этот ресурс потоков и переводит первый поток из очереди в состояние готовности. Здесь исключается непроизводительная потеря процессорного времени на циклическую проверку освобождения занятого ресурса. Однако в тех случаях, когда объём работы в критической секции небольшой и существует высокая вероятность в очень скором доступе к разделяемому ресурсу, более предпочтительным может оказаться использование блокирующих переменных и режим активного ожидания. Действительно, в такой ситуации накладные расходы ОС по реализации режима пассивного ожидания при доступе к ресурсу могут превысить полученную экономию (опять компромисс!).
104
Попытка доступа к разделяемому ресурсу D
Примитив захвата ресурса
Системный вызов
EnterCriticalSection()
Ресурс свободен F(D)=1?
Нет
Перевести дан- ный поток в состояние ОЖИДАНИЕ(D)
Да
Занять ресурс
F(D):=0
ния ресурса
 Примитив
освобожде-
Примитив
освобожде-
Системный вызов
LeaveCriticalSection()
Критическая сек- ция (работа с ре- сурсом D)
Освободить ресурс
 F(D):=1
F(D):=1
Перевести поток,
ожидающий ресурс D, в состояние ГОТОВНОСТЬ
Продолжение вычислений
Рисунок 2.3 – Реализация критических секций (взаимного исключения) с использованием системных вызовов (режим пассивного ожидания) в ОС Windows NT
Семафоры (семафор Дийкстры)
2.5.1 Понятие семафорного механизма было введено Э.Дийкстрой (Dijkstra) в 1965 году для синхронизации процессов. Семафор S (semaphore) – это защищённая переменная целочисленного типа (счётчик в общем случае), которая доступна параллельным процессам для проведения над ней только двух операций (не считая операции инициализации): P-операции (операции захвата, закрытия, ожидания или занятия) и V-операции (операции открытия, освобождения или сигнализации) [P – от голландского Proberen (проверить); V – от голландского
105
Verhogen (увеличить)]. Они, т.е. операции P и V, являются примитивами (если они начинаются, то их нельзя прервать) в отношении семафора S, который указывается в качестве параметра операций, т.е. P(S) и V(S). С каждым семафором связывается список (не обязательно очередь) потоков, ожидающих разрешения пройти семафор. Для простоты мы будем предполагать, что это очередь и обозначать её S.ОЧ, причём потоки в очереди к семафору обслуживаются в соответствии с дисциплиной FIFО. При инициализации семафора он принимает начальное значение S0≥0, а очередь S.ОЧ считается пустой (S.ОЧ:=0). В частном случае семафор может принимать только два значения – 0 (закрытый семафор) и 1 (открытый семафор) – и в этом случае он превращается (по своей мощности) в блокирующую переменную и называется двоичным семафором. P- и V-операции неделимы при своём выполнении и взаимоисключают друг друга; значение семафора S и состояние очереди S.ОЧ недоступны другим операциям даже для чтения (всё это могут читать только P- и V-операции). Семафор исполняет роль вспомогательного критического ресурса при доступе потоков к ресурсу, т.е. семафорный механизм работает по двухэтапной схеме (см. подраздел 2.4) и использует при этом режим пассивного ожидания.
Рассмотрим обобщённый смысл P- и V-операций для простых семафоров с допустимым диапазоном значений S, охватывающих положительные и отрицательные целые значения (могут быть только положительные, в частности, 0 и 1 – двоичные семафоры):
– P(S)-операция закрытия – уменьшить значение семафора (в общем случае – его счётчика) на единицу, т.е. S:=S-1, и проверить его значение: если S≥0, то перейти к следующей за примитивом операции; если же значение семафора S<0, то поток, пытающийся выполнить примитив, должен быть
переведён в состояние пассивного ожидания (блокировки): S.ОЧ:=S.ОЧ+1, или,
иначе, поток «засыпает» на семафоре;
– V(S)-операция открытия – увеличить значение семафора на единицу, т.е. S:=S+1, и, помимо этого, провести «побудку» одного или нескольких потоков, которые «спят» на семафоре (если S.ОЧ>0). «Побудка» (как правило) заключается в переводе потока из очереди ожидания к семафору S, т.е. S.ОЧ:=S.ОЧ-1, в очередь готовности к ЦП.
Заметим, что только примитив Р может блокировать поток, который можно активизировать лишь с помощью другого потока, выполняющего примитив V с тем же семафором. Выполнение же примитива V никогда не приводит к блокировке потока.
Известно порядка десяти видов семафорных механизмов, причём каждый вид может иметь модификации. Варьируемыми параметрами, которые отличают
различные виды, являются: начальное значение и диапазон изменения значений семафора; логика действий над семафорами; количество семафоров, доступных для обработки при исполнении отдельного примитива.
106
2.5.2 Рассмотрим использование семафоров на классическом примере взаимодействия двух выполняющихся в режиме мультипрограммирования потоков, один из которых пишет данные в буферный пул, а другой считывает их из него. Пусть буферный пул состоит из N буферов, каждый из которых может содержать одну запись. В общем случае поток-писатель и поток-читатель могут иметь различные скорости и обращаться к буферному пулу с переменной интенсивностью, т.е. в один период скорость записи может превышать скорость чтения, в другой – наоборот. Для правильной совместной работы поток-писатель должен приостанавливаться, когда все буферы оказываются занятыми, и активизироваться при освобождении хотя бы одного буфера. Напротив, поток-читатель должен приостанавливаться, когда все буферы пусты, и активизироваться при появлении хотя бы одной записи.
Введём два семафора: е – число пустых буферов; f – число заполненных буферов, причём в исходном состоянии e=N, f=0. Тогда работа потоков с общим
буферным пулом может быть проиллюстрирована рисунком 2.4. Поток-
Р(е)
 Работа с
разделяемым
ресурсом
Работа с
разделяемым
ресурсом
V(f)
Начальные значения семафоров:
e=N
Начальные значения семафоров:
e=N
f=0
 f=0
f=0
Буферный пул

|
|
|
|
|
 f
f  N
N
e
Р(f)
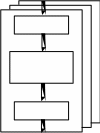 Работа с
разделяемым
ресурсом
Работа с
разделяемым
ресурсом
V(e)
Потоки-писатели Потоки-читатели
Рисунок 2.4 – Использование семафоров для синхронизации потоков
(для решения задачи «читатели-писатели»)
писатель прежде всего выполняет операцию Р(е), с помощью которой он проверяет, есть ли в буферном пуле незаполненные буферы. В соответствии с семантикой Р-операции, если семафор е равен 0 (т.е. свободных буферов в данный момент нет), то поток-писатель переходит в состояние ожидания. Если же значение е>0, то он уменьшает число свободных буферов, записывает данные в очередной свободный буфер и после этого наращивает число занятых буферов
107
операцией V(f). Поток-читатель действует аналогичным образом, только он начинает работу с проверки наличия заполненных буферов, а после чтения данных наращивает количество свободных буферов. В данном случае использование семафоров предпочтительнее блокирующих переменных. Действительно, критическим ресурсом здесь является буферный пул, который может быть представлен как набор идентичных ресурсов – отдельных буферов, а значит, с буферным пулом могут работать сразу несколько потоков, число которых равно числу содержащихся в пуле буферов. Использование двоичной переменной не позволяет организовать доступ к критическому ресурсу более чем одному потоку. Семафор же решает задачу синхронизации более гибко, допуская к разделяемому пулу ресурсов заданное количество потоков – максимум N потоков, часть из которых может быть «писателями» (е), а часть – «читателями (f).
Таким образом, если начальное значение семафора установить бóльшим единицы, то такой семафор может быть использован в качестве регулятора
числа потоков, которым одновременно разрешено использовать некоторый
разделяемый ресурс, например набор идентичных в функциональном отношении внешних устройств (модемов, принтеров, портов), или набор областей памяти одинаковой величины, или информационных структур. Такие семафоры называются семафорами общего вида, а в современной литературе по ОС – семафорами-счётчиками (counting semaphore) или N-ичными семафорами.
2.5.3 Семафор может использоваться и в качестве блокирующей переменной. В рассмотренном выше примере для исключения коллизии при работе с разделяемой областью памяти будем считать, что запись в буфер и считывание из буфера являются критическими секциями (т.е. выполняются в режиме взаимоисключения). Взаимное исключение будем обеспечивать с помощью двоичного семафора b (рисунок 2.5). Оба потока после проверки
доступности буферов должны выполнить проверку доступности критической секции.
Синхронизирующие объекты
2.6.1 Рассмотренные выше механизмы синхронизации, основанные на использовании глобальных переменных процесса, обладают существенным недостатком, касающимся области применения, – они не подходят для синхронизации потоков разных процессов. В таких случаях ОС должна предоставлять потокам системные объекты синхронизации, которые были бы
«видны» для всех потоков (даже если они принадлежат разным процессам и работают в разных адресных пространствах).
Примерами таких синхронизирующих объектов ОС являются:
– системные семафоры;
– мьютексы (мутексы) (mutex);
– события (event);
108
Р(е) – если есть свобод- ные буферы, то умень- шить их количество на 1, если нет, то перейти в состояние ОЖИДАНИЕ
Р(b) – если критическая секция доступна, то уста- новить признак «Занято», если нет, то перейти в состояние ОЖИДАНИЕ
Критическая секция