

V(b) – освободить критическую секцию
Начальные значения семафоров:
e=N; f=0 b=1
Буферный пул
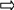
 f N
f N
e
Р(f) – если есть свобод- ные буферы, то умень- шить их количество на 1, если нет, то перейти в состояние ОЖИДАНИЕ
Р(b) – если критическая секция доступна, то уста- новить признак «Занято», если нет, то перейти в состояние ОЖИДАНИЕ
Критическая секция
V(b) – освободить критическую секцию
V(f) – нарастить число занятых буферов
V(е) – нарастить число свободных буферов


Поток-писатель Поток-читатель
Рисунок 2.5 – Пример использования двоичного семафора в задаче
«читатели-писатели»
– мониторы (monitor) и другие
и их набор зависит от конкретной ОС, которая создаёт эти объекты по запросам процессов. Чтобы процессы могли разделять синхронизирующие
объекты, в разных ОС используются разные методы. Некоторые ОС возвращают при запросе на создание синхронизирующего объекта указатель на него, т.е. адрес объекта. Этот указатель может быть доступен всем родственным процессам, наследующим характеристики общего родительского процесса. В других ОС процессы в запросах на создание объектов синхронизации указывают имена, которые должны быть им присвоены. Далее эти имена используются разными процессами для манипуляций с объектами синхронизации. В таком случае работа с синхронизирующими объектами подобна работе с файлами: их можно создавать, открывать, закрывать, уничтожать. Кроме того, для синхронизации могут быть использованы такие обычные объекты ОС, как файлы, процессы и потоки. Все эти объекты могут находиться в двух состояниях: сигнальном и несигнальном (свободном). Причём для каждого объекта смысл, вкладываемый в понятие «сигнальное состояние», зависит от типа объекта. Так, например, поток переходит в сигнальное состояние тогда, когда он завершается. Процесс переходит в сигнальное состояние тогда, когда завершаются все его потоки. Файл переходит в сигнальное состояние в том
109
случае, когда завершается операция ввода-вывода для этого файла. Для остальных объектов сигнальное состояние устанавливается в результате выполнения специальных системных вызовов. Приостановка и активизация потоков осуществляется в зависимости от состояния синхронизирующих объектов ОС.
Потоки с помощью специального системного вызова сообщают ОС о том, что они хотят синхронизировать своё выполнение с состоянием некоторого объекта. Будем далее называть этот системный вызов Wait(X), где Х – указатель на объект синхронизации. Системный вызов, с помощью которого поток может перевести объект синхронизации в сигнальное состояние, назовём Set(X).
Поток, выполнивший системный вызов Wait(X), переводится ОС в состояние ожидания до тех пор, пока объект Х не перейдёт в сигнальное
состояние. Примерами системных вызовов типа Wait() и Set() являются вызовы WaitForSingleObject() и SetEvent() в Windows NT; DosSemWait() и DosSemSet() в OS/2; sleep() и wakeup() в UNIX.
Поток может ожидать установки сигнального состояния не одного объекта, а нескольких. При этом поток может попросить ОС активизировать его при установке либо одного из указанных объектов, либо всех объектов. Поток может в качестве аргумента системного вызова Wait() указать также максимальное время, которое он будет ожидать перехода в сигнальное состояние, после чего ОС должна его активизировать в любом случае. Может случиться, что установки некоторого объекта в сигнальное состояние ожидают сразу несколько потоков. В зависимости от объекта синхронизации в состояние готовности могут переводиться либо все ожидающие это событие потоки, либо один из них.
Рассмотрим несколько примеров, когда в качестве синхронизирующих объектов используются файлы, потоки и процессы.
П ри ме ры
1 Пусть программа построена так, что для выполнения запросов, поступающих из сети, основой поток создаёт вспомогательные серверные потоки. При поступлении от пользователя команды завершения приложения основной поток должен дождаться завершения всех серверных потоков и только после этого
завершиться сам. Следовательно, процедура завершения должна включать вызов Wait(X1,X2,…), где Х1, Х2 и т.д. – указатели на серверные потоки. В результате выполнения данного системного вызова основной поток будет переведён в состояние ожидания и останется в нём до тех пор, пока все серверные потоки не перейдут в сигнальное состояние, т.е. завершатся. После этого ОС переведёт основной поток в состояние готовности. При получении доступа к ЦП основной поток завершится.
2 Пусть выполнение некоторого приложения требует последовательных
110
работ-этапов. Для каждого этапа имеется свой отдельный процесс. Сигналом для начала работы каждого следующего процесса является завершение предыдущего. Для реализации такой логики работы необходимо в каждом процессе, кроме первого, предусмотреть выполнение системного вызова Wait(X), в котором синхронизирующим объектом является предшествующий процесс.
3 Объект-файл, переход которого в сигнальное состояние соответствует завершению операции ввода-вывода с этим файлом, используется в тех случаях, когда поток, инициировавший эту операцию, решает дождаться её завершения, прежде чем продолжить свои вычисления.
2.6.2 Синхронизация тесно связана с планированием потоков. Во-первых, любое обращение потока с системным вызовом Wait(X) влечёт за собой действия в подсистеме планирования – этот поток снимается с выполнения и помещается в очередь ожидающих потоков, а из очереди готовых потоков выбирается и
активизируется новый поток. Во-вторых, при переходе объекта в сигнальное состояние (в результате выполнения некоторого потока – либо системного, либо прикладного) ожидающий этот объект поток (или потоки) переводится в очередь готовых к выполнению потоков. В обоих случаях осуществляется перепланировка потоков, при этом если в ОС предусмотрены динамические приоритеты и/или кванты времени, то они пересчитываются по правилам, принятым в этой ОС.
Мы отметили, что в качестве синхронизирующих объектов могут использоваться файлы, потоки и процессы. Однако круг событий, с которыми потоку может потребоваться синхронизировать своё выполнение, отнюдь не исчерпывается завершением потока, процесса или операции ввода-вывода (при работе с файлом). Поэтому в ОС имеются более универсальные объекты синхронизации, такие как системный семафор, мьютекс, событие, монитор и
другие.
2.6.3 Системный семафор доступен любому потоку в системе, т.е. он позволяет синхронизировать работу потоков, принадлежащих разным процессам. Многие системы предоставляют также сервисы, позволяющие просмотреть состояние семафора без его изменения и произвести
«неблокирующуюся» форму захвата, которая возвращает ошибку в ситуации, когда нормальный захват семафора привёл бы к блокировке (см. примитив захвата семафора в подразделе 2.5). Теоретики не очень любят такие примитивы, но при разработке сложных сценариев взаимодействия с участием многих семафоров они бывают полезны.
Мьютексы
(mutex – MUTual EXclusion semaphore – семафор взаимного исключения) – это двоичный семафор (см. подраздел 2.5) и это название вошло в широкое употребление не ранее конца 80-х годов прошлого века
(так, в разрабатывающейся в середине 80-х годов операционной системе OS/2 1.0
двоичные семафоры ещё называются семафорами, а в Win32, разработка
111
которой происходила в начале 90-х, уже появляется название mutex). Мьютексы реализованы во многих ОС; их основное назначение – организация взаимного исключения для задач (потоков выполнения) одного или нескольких процессов. В отличие от объектов-потоков, объектов-процессов и объектов-файлов, которые при переходе в сигнальное состояние переводят в состояние готовности все потоки, ожидающие этого события, объект-мьютекс «освобождает» из очереди ожидающих только один поток. Работа мьютекса хорошо поясняется в терминах «владения». Мьютекс может находиться в одном из двух состояний – отмеченном (сигнальном) и неотмеченном (несигнальном) (открыт и закрыт соответственно). Организация последовательного (а не параллельного) доступа к ресурсам с использованием мьютексов становится простой задачей, поскольку в каждый конкретный момент только один поток может владеть этим объектом. Когда какой-нибудь поток, принадлежащий любому процессу, становится владельцем мьютекса, последний переводится в неотмеченное состояние и поток входит в критическую секцию; после выполнения критической секции поток освобождает (отдаёт) мьютекс, устанавливая его в отмеченное (сигнальное) состояние. В этот момент мьютекс свободен и не принадлежит ни одному потоку. Если какой-либо поток ожидает его освобождения, то он становится следующим владельцем этого мьютекса; одновременно мьютекс переходит в неотмеченное состояние.
Для того чтобы мьютекс стал доступен потокам, принадлежащим разным процессам, при создании ему необходимо присвоить имя, впоследствии передаваемое «по наследству» задачам, которые должны его использовать для взаимодействия. Для этого вводится специальный системный вызов (CreateMutex), в котором указываются начальное значение мьютекса, его имя и, возможно, атрибуты защиты. Если начальное значение мьютекса равно true,
считается, что поток, создающий этот объект, сразу будет им владеть. Можно указать в качестве начального значение false – в этом случае мьютекс не будет принадлежать ни одному потоку, и только специальным обращением к нему удастся изменить его состояние. Для работы с мьютексом имеется несколько функций. Помимо уже упомянутой функции создания мьютекса есть функции открытия (OpenMutex), захвата (AcquireMutex) (соответствует входу в критическую секцию) и, наконец, освобождения этого объекта (ReleaseMutex) (соответствует выходу из неё). Конкретные обращения к этим функциям и перечни передаваемых и получаемых параметров имеются в документации на соответствующую операционную систему.
События
(в данном случае слово «событие» используется в узком смысле как обозначение конкретного вида объектов синхронизации) обычно используется не для доступа к данным, а для оповещения других потоков о том,
что некоторые действия завершены. Пусть, например, в некотором приложении работа организована таким образом, что один поток читает данные из файла в буфер памяти, а другие потоки обрабатывают эти данные; затем первый поток
112
считывает новую порцию данных, а другие потоки снова её обрабатывают и т.д. В начале работы первый поток устанавливает объект-событие в несигнальное состояние. Все остальные потоки выполнили вызов Wait(X), где Х – указатель события, и находятся в приостановленном состоянии, ожидая наступления этого события. Как только буфер заполняется, первый поток сообщает об этом ОС, выполняя вызов Set(X). ОС просматривает очередь ожидающих потоков и активизирует все потоки, ожидающие этого события
Почтовые ящики (mailboxes);
Конвейеры (pipes);
Именованные конвейеры (named pipes)
Очереди сообщений (message queues)
Разделяемая память (shared memory)
Для синхронизации потоков (процессов) можно использовать обмен сообщениями между ними. Обмен сообщениями между процессами, кроме функции передачи информации, может также служить для упорядочения событий в разных процессах, поскольку передача любого сообщения предшествует его приёму. Базовыми примитивами связи с помощью сообщений являются следующие:
ПОСЛАТЬ(СООБЩЕНИЕ,НАЗНАЧЕНИЕ) SEND получатель, приёмник ПОЛУЧИТЬ(СООБЩЕНИЕ,ИСТОЧНИК)
RECEIVE отправитель
Набор средств межпроцессного обмена данными (IPC; см. пункт 2.1.2) в большинстве современных ОС выглядит следующим образом:
– почтовые ящики (mailboxes);
– конвейеры (pipes);
– именованные конвейеры (named pipes);
– очереди сообщений (message queues);
– разделяемая память (shared memory).
Процессы, обменивающиеся сообщениями, могут различать друг друга по имени (прямое обозначение) или использовать имя некоторого промежуточного объекта – почтовый ящик (mailbox, mailslot в ОС компании Microsoft) или буфер сообщений (косвенное обозначение). В случае прямого обозначения параметр ИСТОЧНИК примитива ПОЛУЧИТЬ (receive) может быть интерпретирован двумя способами: либо как данные, т.е. приёмник явно указывает, что ожидает сообщение от конкретного источника (выборочный приём); либо как результат, т.е. приёмник получает сообщение, которое ему было адресовано. Обычно операционная система предоставляет для прикладных процессов специальный
примитив (системный вызов) для создания буферов сообщений. Такого рода примитив, назовём его, например, create_buffer (создать буфер), процесс должен использовать его перед тем, как отправлять или получать сообщения с помощью примитивов send и receive. При создании буфера его размер может либо устанавливаться по умолчанию, либо выбираться прикладным процессом.
Почтовые ящики облегчают динамическое изменение взаимных связей между процессами и их группировку. Почтовый ящик – это информационная структура, поддерживаемая ОС; она (структура) состоит из головного элемента, в котором находится информация о данном почтовом ящике, и несколько буферов (гнёзд) (mailslot), в которые помещают сообщения. Размер каждого буфера и их количество обычно задаются при образовании почтового ящика. Почтовый ящик может быть связан с парой процессов, только с отправителем, только с получателем, или его можно получить из множества
почтовых ящиков, которые используют все или несколько процессов. В
некоторых системах данному почтовому ящику может соответствовать
118
только один процесс-получатель; почтовые ящики с таким ограничением называются портами (port). В этом случае облегчается посылка сообщений от нескольких процессов в фиксированный пункт назначения. Однако один процесс может быть связан с несколькими разными портами. Если почтовый ящик не связан жёстко с процессами, то сообщение должно содержать идентификаторы и процесса-отправителя, и процесса-получателя.
Правила работы почтового ящика могут быть различными в зависимости от его сложности: однонаправленные, двунаправленные и многовходовые почтовые ящики. В простейшем случае сообщения передаются только в одном направлении. Процесс Р1 может посылать сообщения до тех пор, пока имеются свободные гнёзда. Если все гнёзда заполнены, то Р1 может либо ждать, либо заняться другими делами и попытаться послать сообщение позже. Аналогично процесс Р2 может получать сообщения до тех пор, пока имеются заполненные
гнёзда. Если сообщений нет, то он может либо ждать сообщений, либо продолжать свою работу.
Двунаправленный почтовый ящик, связанный с парой процессов, позволяет подтверждать приём сообщений. При наличии множества гнёзд каждое из них хранит либо сообщение, либо подтверждение. Чтобы гарантировать передачу подтверждений, когда все гнёзда заняты, подтверждение на сообщение помещается в то же гнездо, в котором находится сообщение, и это гнездо уже не используется для другого сообщения до тех пор, пока подтверждение не будет получено. Из-за того, что некоторые процессы не забрали свои сообщения, связь может быть приостановлена. Если каждое сообщение снабдить пометкой времени, то управляющая программа может периодически удалять старые сообщения.
Процессы могут быть также остановлены в связи с тем, что другие процессы не смогли послать им сообщения. Если время поступления каждого
остановленного процесса в очередь заблокированных процессов регистрируется, то управляющая программа может периодически посылать им пустые сообщения, чтобы они не ждали чересчур долго.
Для примитивов связи можно определить разные режимы синхронизации. При отсутствии сообщения операция приёма обычно блокирует процесс- получатель (приёмник). В некоторых системах вводят специальный примитив, который определяет пустой почтовый ящик, что позволяет избежать блокировки. При передаче и приёме используются следующие способы синхронизации:
– схема «производитель-потребитель» – передача не блокируется до тех пор, пока буфер не заполнится; использование буферов переменного размера с динамическим размещением уменьшает вероятность блокирования процесса- отправителя (передатчика);
– схема типа встречи, когда передатчик блокируется до тех пор, пока приёмник не получит сообщение;
119
– множественное ожидание – если при приёме процесс связан со многими портами, то прибытие сообщения в любой из портов активизирует процесс- получатель;
– схема «клиент-официант» (пользователь-устройство) – процесс- официант должен оказывать услуги (например, выполнение заранее определённой программы) процессам-клиентам. Процесс-официант связан с портом, где собираются заказы клиентов в виде запросов; при отсутствии заказов на услуги процесс-официант остаётся блокированным. В число услуг может входить пересылка результатов клиенту. В этом случае клиент должен передать в запросе имя порта, где он будет ждать результата в состоянии блокировки. Можно, не меняя приведённой схемы, предусмотреть множество однородных процессов-официантов (связанных с одним почтовым ящиком), каждый из которых может удовлетворять запрос на обслуживание.
Основные достоинства почтовых ящиков:
– процессу не нужно знать о существовании других процессов до тех пор,
пока он не получит сообщения от них;
– два процесса могут обмениваться более чем одним сообщением за один
раз;
– ОС может гарантировать, что никакой другой процесс не вмешается
во взаимодействие процессов, ведущих между собой «переписку»;
– очереди буферов позволяют процессу-отправителю продолжать работу, не обращая внимания на получателя.
Основным недостатком буферизации сообщений является появление ещё одного ресурса, которым нужно управлять – это сами почтовые ящики. К другому недостатку можно отнести статический характер этого ресурса: количество буферов для передачи сообщений через почтовый ящик фиксировано.
Кроме почтовых ящиков для обмена сообщениями между процессами можно также отметить такие системные ресурсы как программный канал связи (software-pipe или, просто, pipe) или, иначе, конвейер или транспортёр и именованные конвейеры (named pipes). Конвейеры как средство межпроцессного обмена данными впервые появились в ОС UNIX. Принцип работы конвейера основан на механизме ввода-вывода файлов в ОС UNIX, причём операции записи и чтения осуществляются не записями, как это делается в обычных файлах, а потоком байтов, как это принято в UNIX-системах. Конвейер представляет собой поток данных между двумя и более процессами и физически является буферной памятью, работающей по принципу FIFO (т.е. по принципу обычной очереди). Однако не следует путать конвейеры с очередями сообщений; последние реализуются иначе и имеют другие возможности. Конвейер имеет определённый размер, который не может превышать 64Кайт, и работает циклически. Он реализует очередь в массиве, когда имеются указатели начала (head) и конца (tail), которые перемещаются циклически по массиву. В начальный момент оба указателя равны нулю (массив пуст). Добавление самого первого элемента в
120
пустую очередь приводит к тому, что указатели на начало и на конец принимают значение, равное 1 (в массиве появляется первый элемент). В последующем добавление нового элемента вызывает изменение значения второго указателя, поскольку он отмечает расположение именно последнего элемента очереди. Чтение (и удаление) элемента (читается и удаляется всегда первый элемент из созданной очереди) приводит к необходимости модифицировать значение указателя на её начало. В результате операций записи (добавления) и чтения (удаления) элементов в массиве, моделирующем очередь элементов, указатели будут смещаться от начала массива к его концу. Как системная информационная структура конвейер описывается идентификатором, размером и двумя указателями. Для начала работы с конвейером процесс сначала должен заказать его у ОС и получить его в своё распоряжение [системный запрос на создание конвейера в API OS/2 – DosCreatePipe(…)]. Процессы, знающие идентификатор конвейера, могут через него обмениваться данными [функция чтения из конвейера
– DosRead(…); функция записи в конвейер – DosWrite(…)]. При работе с конвейером данные непосредственно помещаются в него. Отметим, что из-за ограничения на размер конвейера программисты сталкиваются и с ограничениями на размеры передаваемых через него сообщений. Таким образом, конвейер представляет собой буфер в ОП, поддерживающий очередь байт по дисциплине FIFO. Для программиста, использующего системный вызов pipe, этот буфер выглядит как безымянный файл, в который можно писать и читать, осуществляя тем самым обмен данными.
Именованные конвейеры представляют собой развитие механизма обычных конвейеров. Именованные конвейеры (named pipes) имеют имя, которое является записью в каталоге файловой системы ОС, поэтому они пригодны для обмена данными между двумя произвольными процессами или потоками этих
процессов. Именованный конвейер является специальным файлом типа FIFO и не имеет области данных на диске. Создаётся именованный конвейер с помощью того же системного вызова, который используется и для создания файлов любого типа, но только с указанием в качестве типа файла параметра FIFO. Системный вызов порождает в каталоге запись о файле типа FIFO с заданным именем, после чего любой процесс может открыть этот файл и передавать данные другому процессу, также открывшему файл с этим именем. Следует иметь в виду, что именованные конвейеры используют файловую систему только для хранения имени конвейера в каталоге, а данные между процессами передаются через буфер в ОП, как и в случае программного конвейера.
Очереди сообщений (message queues) предлагают более удобный способ связи между взаимодействующими процессами по сравнению с каналами, но в своей реализации они сложнее. С помощью очередей также можно из одной или
нескольких задач независимым образом посылать сообщения некоторой задаче-
приёмнику. При этом только процесс-приёмник может читать и удалять
121
сообщения из очереди, а процессы-клиенты имеют право лишь помещать в очередь свои сообщения. Таким образом, очередь сообщений работает только в одном направлении. Если же необходима двухсторонняя связь, то можно создать две очереди. Синхронизация в очереди осуществляется по сообщениям, т.е. процесс, пытающийся прочитать сообщение, переводится в состояние ожидания в том случае, если в очереди нет ни одного полного сообщения. Работа с очередями сообщений отличается от работы с конвейерами следующим:
– во-первых, очереди сообщений предоставляют возможность использовать несколько дисциплин обработки сообщений – FIFO, LIFO, приоритетный доступ, произвольный доступ, тогда как канал обеспечивает только дисциплину FIFO;
– во-вторых, если при чтении сообщения оно удаляется из конвейера, то при чтении из очереди сообщений этого может и не быть, и сообщение при желании может быть прочитано несколько раз;
– в-третьих, в очередях присутствуют не непосредственно сами сообщения, а только их адреса в памяти и размер. Эта информация размещается системой в сегменте памяти, доступном для всех задач, общающихся с помощью данной очереди.
Каждый процесс, использующий очередь, должен предварительно получить разрешение на доступ в общий сегмент памяти с помощью системных запросов API, ибо очередь – это системный механизм, и для работы с ним требуются системные ресурсы и, соответственно, обращение к самой ОС. Приведём перечень основных функций, управляющих работой очереди (без подробного описания передаваемых параметров, поскольку в различных ОС обращение к этим функциям могут существенно различаться):
– CreateQueue – создание новой очереди;
– OpenQueue – открытие существующей очереди;
– ReadQueue – чтение и удаление сообщения из очереди;
– PeekQueue – чтение сообщения без его последующего удаления из очереди;
– WriteQueue – добавление сообщения в очередь;
– CloseQueue – завершение использования очереди;
– PurgeQueue – удаление из очереди всех сообщений;
– QueruQueue – определение числа элементов в очереди.
Разделяемая память (shared memory) представляет собой сегмент физической памяти, отображённой в виртуальное адресное пространство двух и более процессов. Механизм разделяемой памяти поддерживается подсистемой виртуальной памяти, которая настраивает таблицы отображения адресов для процессов, запросивших разделение памяти, так что одни и те же адреса некоторой области физической памяти соответствуют виртуальным адресам
разных процессов.
Сигналы
Сигнал даёт возможность задаче реагировать на событие, источником которого может быть ОС или другая задача. Сигналы вызывают прерывание задачи и выполнение заранее предусмотренных действий. Сигналы могут вырабатываться синхронно, т.е. как результат работы самого процесса, а могут быть направлены процессу другим процессом, т.е. вырабатываться асинхронно. Синхронные сигналы чаще всего приходят от системы прерываний процессора и свидетельствуют о действиях процесса, блокируемых аппаратурой, например, деление на нуль, ошибка адресации, нарушение защиты памяти и т.д.
Примером асинхронного сигнала является сигнал с терминала. Во многих ОС предусматривается снятие процесса с выполнения. Для этого пользователь может нажать некоторую комбинацию клавиш (Ctrl+C, Ctrl+Break), в
результате чего ОС вырабатывает сигнал и направляет его активному процессу. Сигнал может поступить в любой момент выполнения процесса (т.е. он является асинхронным), требуя от процесса немедленного завершения работы. В данном случае реакцией на сигнал является безусловное завершение процесса.
В системе может быть определён набор сигналов. Процесс, которому поступил сигнал, может либо проигнорировать его, либо прореагировать на него стандартным действием (например, завершиться), либо выполнить специфические действия, определённые прикладным программистом. В последнем случае в программном коде необходимо предусмотреть специальные системные вызовы, с помощью которых ОС информируется, какую процедуру надо выполнить в ответ на поступление того или иного сигнала.
Сигналы обеспечивают логическую связь между процессами, а также между процессами и пользователями (терминалами). Поскольку посылка сигнала
предусматривает знание идентификатора процесса, то взаимодействие посредством сигналов возможно только между родственными процессами, которые могут получить данные об идентификаторе друг друга
Заметим, что в распределённых системах, состоящих из нескольких процессоров, каждый из которых имеет собственную оперативную память, блокирующие переменные, семафоры, сигналы и другие аналогичные средства, основанные на разделяемой памяти, оказываются непригодными. В таких системах синхронизация может быть реализована только посредством обмена сообщениями.
Тупики и методы их предвосхищения
2.8.1 Рассмотрим одну из самых серьёзных и трудноразрешимых проблем, возникающих при организации мультипрограммного режима работы, – проблему тупиков и основные подходы при борьбе с ними. При организации параллельного
123
выполнения нескольких вычислительных процессов одной из главных функций ОС является решение сложной задачи корректного распределения ресурсов между выполняющимися процессами и обеспечение последних средствами взаимной синхронизации и обмена данными.
При параллельном исполнении процессов могут возникать тупиковые ситуации, когда два или более процесса блокируют друг друга, вынуждая ожидать наступления события, связанного с освобождением ресурса. Самым простым является случай, когда каждый из двух процессов ожидает ресурс, занятый другим процессом. Из-за этого ожидания ни один из процессов не может продолжить исполнение и освободить в конечном итоге ресурс, необходимый другому процессу. Эта ситуация называется тупиком, взаимной блокировкой, дедлоком (dead lock – смертельное объятие), или клинчем (clinch). Говорят, что в мультипрограммной системе процесс находится в состоянии
тупика, если он ждёт события, которое никогда не произойдёт. Тупики чаще всего возникают из-за конкуренции несвязанных параллельных процессов за ресурсы ВС, но иногда к тупикам приводят и ошибки программирования взаимодействующих процессов. Покажем на примере (см. рисунок 2.5), что если переставить местами операции Р(е) и Р(b) в потоке-писателе, то при некотором стечении обстоятельств поток-писатель и поток-читатель могут взаимно блокировать друг друга. Пусть поток-писатель начинает свою работу с проверки доступности критической секции – операции Р(b), и пусть он первым войдёт в критическую секцию. Выполняя операцию Р(е), он может обнаружить отсутствие свободных буферов и перейти в состояние ожидания. Из этого состояния его может вывести только поток-читатель, который возьмёт очередную запись из буфера. Но поток-читатель не сможет этого сделать, так как для этого ему потребуется войти в критическую секцию, вход в которую заблокирован потоком- писателем. Таим образом, ни один из этих потоков не может завершить работу и возникает ситуация, которая не может разрешиться без внешнего вмешательства.
Рассмотрим ещё один пример тупика (рисунок 2.8). В зависимости от соотношения скоростей потоков они могут либо взаимно блокировать друг друга (см рисунок 2.8, б), либо образовывать очереди к разделяемым ресурсам (см. рисунок 2.8, в), либо совершенно независимо использовать разделяемые ресурсы (см. рисунок 2.8, г). В рассмотренных примерах тупик был образован двумя потоками, но взаимно блокировать друг друга может и бóльшее число потоков. Простейший способ создания тупика проиллюстрировал Холт а программе, написанной на языке PL/1 и предназначенной для того, чтобы привести процесс к тупику при работе под управлением ОС OS/360:
REVENGE:PROCEDURE OPTION(MAIN,TASK); WAIT(EVENT);
END REVENGE;
Процесс, связанный с приведенной программой, будет всё время ждать, чтобы
124
Поток А
Поток В
…
А1 Занять ПОРТ
 А2 Занять
ДИСК
А2 Занять
ДИСК
…
А3 Освободить ПОРТ
А4 Освободить ДИСК
…
…
 В1 Занять
ДИСК
В2 Занять
ПОРТ
В1 Занять
ДИСК
В2 Занять
ПОРТ
…
В3 Освободить ДИСК В4 Освободить ПОРТ
…
а
 Поток
А Поток
В
Поток
А Поток
В
Поток А
Прерывание потока А
 А1 В1 В2
А1 В1 В2
 б
б
Прерывание потока А
 Блокировка
потока
А А2
Блокировка
потока
А А2
Блокировка потока В
Прерывание потока А
Поток В
А1 А2 В1
А3 А4
Блокировка потока В
в
В2 В3 В4
 Поток
А
Поток
А
Поток В
А1 А2
 А3 А4 В1 В2 В3 В4
А3 А4 В1 В2 В3 В4
г
 t
t
Рисунок 2.8 – Возникновение взаимных блокировок при выполнении программы
произошло событие EVENT; однако в этой программе (и ни в одной другой) не предусмотрена сигнализация о наступле6нии ожидаемого события. Системе придётся обнаруживать, что данный процесс «завис», а затем аннулировать
125
задание, чтобы выйти из тупиковой ситуации. Тупики подобного типа обнаруживать исключительно сложно.
П ри м е ч а н ие – Тупиковые ситуации надо отличать от простых очередей, хотя те и другие возникают при совместном использовании ресурсов и внешне выглядят похоже: поток приостанавливается и ждёт освобождения ресурса. Однако очередь – это нормальное явление, неотъемлемый признак высокого коэффициента использования ресурсов при случайном поступлении запросов. Очередь появляется тогда, когда ресурс недоступен в данный момент, но освободится через некоторое время, позволив потоку продолжить выполнение. Тупик же является в некотором роде неразрешимой ситуацией.
2.8.2 При рассмотрении проблемы тупиков целесообразно понятие ресурсов системы обобщить и разделить их на два класса:
– повторно используемые (Reusable Resource – RR), или системные (System
Resource – SR), ресурсы – представляют собой конечное множество идентичных единиц некоторого вида ресурсов, обладающих следующими свойствами:
1) число единиц в системе неизменно;
2) каждая единица ресурса либо доступна, либо выделена одному и только одному процессу;
3) процесс может освободить единицу ресурса (сделать её доступной), только если он ранее получил эту единицу, т.е. никакой процесс не может оказывать влияние на ресурс, если этот ресурс ему не принадлежит.
Данное определение выделяет существенные для изучения проблемы тупика свойства системных ресурсов, к которым мы относим компоненты аппаратуры, такие как основная память, вспомогательная (внешняя) память, периферийные устройства и, возможно, процессоры, а также программное и информационное
обеспечение, такое как файлы данных, таблицы и «разрешение войти в критическую секцию»;
– потребляемые, или расходуемые, ресурсы (Consumable Resource – CR) –
отличаются от ресурсов типа SR в нескольких важных отношениях:
1) число доступных единиц некоторого ресурса типа CR изменяется по мере того, как выполняющимися процессами они расходуются (приобретаются) и освобождаются (производятся). В общем случае число единиц расходуемых ресурсов является потенциально неограниченным, поскольку некий процесс-«производитель» может достаточно долго увеличивать число единиц ресурса, освобождая одну или более единиц, которые он «создал»;
2) процесс-«потребитель» уменьшает число единиц ресурса,
сначала запрашивая и затем приобретая (потребляя) одну или более единиц. Единицы ресурса, которые приобретены, в общем случае не
возвращаются ресурсу, а потребляются (расходуются). Эти свойства
126
потребляемых ресурсов присущи многим синхронизирующим сигналам, сообщениям и данным, порождаемым как аппаратурой, так и программным обеспечением, и могут рассматриваться как ресурсы типа CR при изучении тупиков. В их число входят: прерывания от таймера и устройств ввода-вывода; сигналы синхронизации процессов; сообщения, содержащие запросы на различные виды обслуживания или на данные, а также соответствующие ответы.
2.8.3 Проблема тупиков является чрезвычайно серьёзной и сложной. Разработано несколько подходов к разрешению этой проблемы, однако ни один из них нельзя считать панацеей. В некоторых случаях цена, которую приходится платить за то, чтобы освободить систему от тупиков, слишком высока. Кстати, именно по этой причине нам не так уж и редко приходится сталкиваться с тупиковыми ситуациями. В других случаях, например в системах
реального времени, просто нет иного выбора, как идти на значительные затраты, поскольку возникновение тупика может привести к катастрофическим последствиям.
Проблема борьбы с тупиками становится всё более актуальной и сложной по мере развития и внедрения параллельных вычислительных систем. При проектировании таких систем разработчики стараются проанализировать возможные тупиковые ситуации, используя модели и методы. Борьба с тупиковыми ситуациями основывается на одной из трёх стратегий:
– предотвращение тупика;
– обход тупика;
– распознавание (обнаружение) тупика с последующим восстановлением.
2.8.4 Предотвращение тупика основывается на предположении о чрезвычайно высокой его стоимости, поэтому лучше потратить
дополнительные ресурсы системы, чтобы исключить вероятность его возникновения при любых обстоятельствах. Этот подход используется в наиболее ответственных системах, обычно в системах реального времени.
Предотвращение можно рассматривать как запрет опасных состояний. Поэтому подсистема распределения ресурсов, предотвращающая тупик, должна гарантировать, что четыре условия, необходимых для его наступления, не возникнут одновременно (их сформулировали Коффман, Элфик и Шошани):
– условие взаимного исключения можно подавить путём разрешения неограниченного разделения ресурсов. Это удобно для повторно входимых программ и ряда драйверов, но совершенно неприемлемо для совместно используемых переменных в критических секциях;
– условие ожидания ресурсов можно подавить, предварительно выделяя ресурсы [так называемое предварительное (статическое) распределение
ресурсов (иначе, метод глобального распределения ресурсов)]. При этом процесс может начать исполнение, только получив все необходимые ресурсы заранее.
127
Следовательно, общее число затребованных параллельными процессами ресурсов должно быть не больше возможностей системы. Поэтому предварительное распределение ресурсов может привести к снижению эффективности работы ВС в целом. Необходимо отметить, что предварительное выделение ресурсов зачастую невозможно, так как реально необходимые ресурсы становятся известны системе только в ходе исполнения процесса;
– условие неперераспределяемости (отсутствия перераспределения) ресурсов можно исключить, позволяя операционной системе отнимать у процесса ресурсы (так называемое общее исключение). Для этого в операционной системе должен быть предусмотрен механизм запоминания состояния процесса с целью последующего восстановления хода вычислений. Перераспределение процессора реализуется достаточно легко, в то время как перераспределение устройств ввода-вывода крайне нежелательно;
– условие кругового ожидания можно исключить, предотвращая образование цепи запросов на ресурсы. Это можно обеспечить с помощью иерархического выделения ресурсов, называемого иначе распределением по стандартной последовательности, или методом упорядоченных классов. Все ресурсы образуют некоторую иерархию. Процесс, затребовавший ресурс на одном уровне, может затем потребовать ресурсы только на более высоком уровне. Далее он (процесс) может освободить ресурсы на данном уровне только после освобождения всех ресурсов на всех более высоких уровнях. Только после того как процесс получил, а потом освободил ресурсы данного уровня, он может снова запросить ресурсы на том же самом уровне. Пусть имеются процессы X и Y, которые могут иметь доступ к ресурсам Р1 и Р2, причём Р2 находится на более высоком уровне иерархии. Если процесс Ч захватил ресурс Р1, то процесс Y не может захватить ресурс Р2, так как доступ к нему проходит через доступ к ресурсу Р1, который уже захвачен процессом Х. Таким образом, создание замкнутой цепи исключается. Иерархическое выделение ресурсов часто не даёт никакого выигрыша, если порядок использования ресурсов, определённый в описании процессов, отличается от порядка уровней иерархии. В этом случае ресурсы будут расходоваться неэффективно.
В целом стратегия предотвращения тупиков – это очень дорогое решение проблемы тупиков, и эта стратегия используется нечасто.
Алгоритм банкира
5 Обход тупика можно интерпретировать как запрет входа в опасное состояние. Если ни одно из упомянутых выше четырёх условий не исключено (см. пункт 2.8.4), то вход в опасное (ненадёжное) состояние можно предотвратить при наличии у системы информации о последовательности запросов, связанных с каждым параллельным процессом. Доказано, что если вычисления находятся в любом неопасном (надёжном) состоянии, то существует, по крайней мере, одна
последовательность состояний, которая обходит опасное состояние. Следовательно, достаточно проверить, не приведёт ли выделение затребованного ресурса сразу же к опасному состоянию. Если да, то запрос отклоняется, если нет,
128
его можно выполнить. Определение того, является состояние опасным или нет,
требует анализа последующих запросов от процессов.
П р и м е ч а н ие – Термин «ненадёжное состояние» не предполагает, что в данный момент времени существует или в другой момент времени обязательно возникнет тупиковая ситуация. Он просто говорит о том, что в случае некоторой неблагоприятной последовательности событий система может зайти в тупик.
П р и м ер – Пусть имеется система из трёх вычислительных процессов, потребляющих некоторый ресурс R типа SR, который выделяется дискретными взаимозаменяемыми единицами, причём существует всего 10 единиц этого ресурса. В таблице 2.1 приведены сведения о текущем распределении единиц этого ресурса между процессами, об их текущих запросах на это ресурс и о максимальных потребностях процессов в ресурсе R.
Таблица 2.1 – Пример распределения ресурса
Имя процесса |
Выделено |
Запрос |
Максимальная потребность (анонс) |
Остаток потребностей |
А |
2 |
3 |
6 |
1 |
В |
3 |
2 |
7 |
2 |
С |
2 |
3 |
5 |
0 |
Остаток ресурса |
3 |
– |
– |
– |
Если запрос процесса А будет удовлетворён первым, то он в принципе может запросить ещё одну единицу ресурса R, и уже в этом случае мы получим тупик, поскольку ни один из процессов не сможет продолжить свои вычисления. Следовательно, при выполнении запроса процесса А мы попадаем в ненадёжное состояние. Если первым будет выполнен запрос процесса В, то у нас останется свободной ещё одна единица ресурса R. Однако, если процесс В запросит ещё две, а не одну единицу ресурса R (а он может это сделать), то мы опять получим тупик. Если же мы сначала выполним запрос процесса С и выделим ему все три единицы ресурса R, то у нас не останется никакого резерва, но процесс С сможет благополучно завершиться и вернуть системе все свои ресурсы, поскольку на этом его потребности в ресурсах заканчиваются. Это приведёт к тому, что свободное количество ресурса R станет равным пяти. После этого уже можно будет удовлетворить запрос либо процесса В, либо процесса А, но не обоих сразу.
Как правило, последовательность запросов, связанных с каждым процессом, заранее неизвестна. Но если заранее известен общий запрос на ресурсы каждого типа каждым процессом (анонс процесса), то выделение ресурсов можно контролировать. В этом случае необходимо для каждого требования (запроса) (в предположении, что оно удовлетворено) определить, существует ли среди общих запросов некоторая последовательность требований, которая может привести к опасному состоянию. Данный подход является примером контролируемого выделения ресурса.
129
Классическое решение этой задачи предложено Дийкстрой и известно как алгоритм банкира. Алгоритм банкира напоминает процедуру принятия решения о том, может ли банк безопасно для себя дать взаймы денег клиентам. Принятие решения основывается на информации о потребностях клиента (нынешних и максимально возможных в принципе) и учёте текущего баланса банка. Согласно алгоритму банкира система удовлетворяет только те запросы, при которых её состояние остаётся надёжным. Новое состояние безопасно тогда и только тогда, когда каждый процесс может завершиться. Именно это условие и проверяется в алгоритме банкира. Запросы процессов, приводящие к переходу системы в ненадёжное состояние, не удовлетворяются и откладываются до момента, когда их можно выполнить (эти моменты связаны с завершением какого-либо процесса и освобождения им всех занимаемых ресурсов).
Алгоритм банкира позволяет продолжать выполнение таких процессов,
которым в случае системы с предотвращением тупиков пришлось бы ждать. Хотя суть алгоритма банкира относительно проста, его реализация может обойтись довольно дорого. Основным накладным расходом стратегии обхода тупика с помощью контролируемого выделения ресурса является время выполнения алгоритма, так как он выполняется при каждом запросе ресурса. При этом алгоритм работает наиболее медленно, когда система близка к тупику. Необходимо отметить, что обход тупика неприменим при отсутствии предварительной информации о требованиях процессов на ресурсы.
Алгоритм банкира не получил распространения из-за следующих основных своих недостатков:
– требуются анонсы процессов (трудно заранее указать, какие ресурсы и в каком количестве потребуются, тем более это реализовать);
– фиксированное количество распределяемых ресурсов (трудно
поддерживать);
– постоянное число работающих процессов (в системах общего назначения оно непрерывно меняется, и соблюсти это требование, в общем, нереалистично);
– требуется гарантия конечности использования ресурсов процессами
(для реальных систем требуются гораздо более конкретные гарантии).
Сети Петри и синхронизация процессов
Модель пространства состояний
Модель Холта
Для исследования параллельных процессов и, в частности, задачи распознавания тупиков было разработано несколько моделей (сети Петри, модель пространства состояний, модель Холта и др.). Одной из них является модель повторно используемых ресурсов Холта. Согласно этой модели система представляется в виде набора (множества) процессов и набора ресурсов, причём каждый из ресурсов состоит из фиксированного числа единиц. Любой процесс может изменять состояние системы путём выдачи запроса на получение или
освобождение единицы ресурса. Модель представляется в графической форме в виде орграфа. Квадраты обозначают процессы, а большие кружки – разные классы идентичных ресурсов. Малые кружочки (иначе, маркеры или фишки),
130
находящиеся внутри больших, обозначают количество идентичных ресурсов каждого класса. Дуга, указывающая из «процесса» на «ресурс», означает запрос одной единицы этого ресурса; дуга, указывающая из «ресурса» на «процесс», представляет выделение одной единицы ресурса процессу. Поскольку каждая единица любого ресурса типа SR может быть выделена одновременно не более чем одному процессу, то число дуг, исходящих из ресурса к различным процессам, не может превышать общего числа единиц этого ресурса. Такая модель называется графом запросов и распределения повторно используемых ресурсов. На рисунке 2.9 показаны отношения, которые могут встретиться на графе
Р1 R1
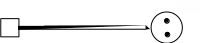 а
а
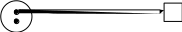 R2 Р2
R2 Р2
б
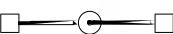 Р3 R3 Р4
Р3 R3 Р4
в
 R4
R4
Р5 Р6
R5
г
Рисунок 2.9 – Примеры графа запросов и распределения повторно используемых ресурсов: а – процесс Р1 запрашивает единицу ресурса типа R1; б – единица ресурса типа R2 выделена процессу Р2; в – процесс Р3 запрашивает ресурс R3, который выделен процессу Р4; г – процессу Р5 выделен ресурс R5, необходимый процессу Р6, которому выделен ресурс R4, необходимый процессу Р5 («круговое ожидание»)
131
запросов и распределения повторно используемых ресурсов. Графы запросов и распределения ресурсов динамично меняются по мере того, как процессы запрашивают ресурсы, получают их в своё распоряжение, а через некоторое время возвращают ОС.
Задача механизма обнаружения тупиков – определить, не возникла ли в системе тупиковая ситуация. Одним из способов обнаружения тупиков является редукция (приведение или сокращение) графа повторно используемых ресурсов, – это позволяет определять процессы, которые могут завершиться, и процессы, которые будут оставаться в тупиковой ситуации. Редукция графа может быть описана следующим образом:
– граф повторно используемых ресурсов сокращается процессом Pi (редуцируется на процесс Pi), который не является ни заблокированной, ни изолированной вершиной, путём удаления всех рёбер, входящих в вершину Pi и выходящих из Pi. Эта процедура эквивалентна приобретению процессом Pi неких ресурсов, на которые он ранее выдавал запросы, а затем освобождению всех его ресурсов. Тогда процесс Pi становится изолированной вершиной;
– граф повторно используемых ресурсов несокращаем (не редуцируется),
если он не может быть сокращён ни одним процессом;
– граф ресурсов типа SR является полностью сокращаемым, если существует последовательность сокращений (редукций), которая удаляет все дуги графа (граф в этом случае состоит из изолированных вершин);
– для ресурсов типа SR порядок сокращений дуг графа повторно используемых ресурсов несущественен; окончательный результат при любой последовательности сокращений будет один и тот же. Следовательно, выполняя редукцию графа повторно используемых ресурсов, надо стараться упорядочивать сокращения удобным способом.
Теорема о тупике: состояние SТ есть состояние тупика тогда и только тогда, когда граф повторно используемых ресурсов в состоянии SТ не является полностью сокращаемым.
Из теоремы о тупике непосредственно следует и алгоритм обнаружения тупиков. Следует просто попытаться сократить граф по возможности эффективным способом и если граф полностью не сокращается, то начальное состояние было состоянием тупика для тех процессов, вершины которых остались в несокращённом графе.
Структура графа обеспечивает простое необходимое (но недостаточное) условие для тупика. Для любого графа G=<X,E> и вершины x X через Р(х) обозначим множество вершин, достижимых из вершины х. Другими словами, в орграфе G потомством вершины х, обозначенным как Р(х), называется множество всех вершин, в которые ведут пути из х. Тогда если существует
некоторая вершина x X: x Р(х), то в графе G имеется цикл.
Первая теорема: цикл в графе повторно используемых ресурсов является необходимым условием тупика.
132
P
Вторая теорема: если S не является состоянием тупика и S i
ST, где
ST есть состояние тупика, то это произойдёт в том и только в том случае,
когда операция процесса Рi есть запрос на ресурс и Рi находится в тупике в ST.
Это следует понимать таким образом, что тупик может быть вызван только
при запросе, который не удовлетворён немедленно. Учитывая эту теорему, можно сделать вывод, что проверка на тупиковое состояние может быть выполнена более эффективно, если она проводится непрерывно, т.е. по мере развития процессов. Тогда надо применять редукцию графа только после запроса от некоторого процесса Рi и на любой стадии необходимо сначала попытаться сократить граф с помощью процесса Рi. Если процесс Рi смог провести сокращение (редукцию) графа, то никакие дальнейшие сокращения не являются необходимыми. Заметим, что ограничения, накладываемые на распределители ресурсов, на число ресурсов, запрошенных одновременно, и на количество единиц ресурсов, приводят к более простым условиям для тупика.
Пучок, или узел в ориентированном графе G=<X,E> – это подмножество вершин Z X таких, что x Z Р(х)=Z, т.е. потомство каждой вершины из Z является само множество Z. Каждая вершина в узле достижима из каждой другой вершины этого узла, и узел есть максимальное подмножество с этим свойством (рисунок 2.10). Следует заметить, что наличие цикла – это необходимое, но не достаточное условие для узла. В узел должны входить дуги, но они не должны из него выходить.
R1
Р1 Р2
 Р3
Р3
R3
R2
Рисунок 2.10 – Пример узла (вершины R1, P2, P3, R3) в модели Холта
Если состояние системы таково, что удовлетворены все запросы, которые могут быть удовлетворены, то существует простое достаточное условие существования тупика. Эта ситуация возникает, если распределители ресурсов не откладывают запросы, которые могут быть удовлетворены, а выполняют их по
133
возможности немедленно (большинство распределителей ресурсов следуют именно этой дисциплине). Состояние называется фиксированным, если каждый процесс, выдавший запрос, заблокирован.
Третья теорема: если состояние системы фиксированное, то наличие узла в соответствующем графе повторно используемых ресурсов является достаточным условием тупика (см. рисунок 2.10). В этом случае все процессы в узле Z находятся в тупике.
Допустим, что каждый ресурс имеет единичную ёмкость (по одной единице ресурса). При этом ограничении наличие цикла также становится достаточным условием тупика.
Четвёртая теорема: граф повторно используемых ресурсов с единичной ёмкостью каждого ресурса указывает на состояние тупика тогда и только тогда, когда он содержит цикл. Таким образом, чтобы обнаружить тупик в
случае ресурса единичной ёмкости, мы должны просто проверить граф повторно используемых ресурсов на наличие циклов (рисунок 2.11). Тупиковая ситуация для этих условий будет и в графе на рисунке 2.9, г.
R5
R1
Р1
R2
 Р2
Р2
R4
Р3
R3
Рисунок 2.11 – Тупиковая ситуация в графе повторно используемых ресурсов единичной ёмкости (наличие цикла P3–R5–P1– R3–P2–R2–P3)
На рисунке 2.12 показан пример редукции графа повторно используемых ресурсов, для которого тупика нет.
Программная реализация распознавания тупиков основана на представлении графа повторно используемых ресурсов в виде таблиц (или списков) распределения (назначения) ресурсов и запросов к занятым ресурсам (таблицы заблокированных процессов) и анализе этих таблиц.
134
 R1
R1
Р2
Р1 R2
Р3
 Редуцирование
на
процесс
Р3
Редуцирование
на
процесс
Р3
 R1
R1
Р2
Р1 R2
Р3
Редуцирование на процесс Р1
R1
R1


 Р2 Р2
Р2 Р2
 R2
R2
R2
Р1
Р1
Р3 Р3
Редуцирование на процесс Р2
Рисунок 2.12 – Редукция графа запросов и распределения повторно используемых ресурсов (тупика нет)
Распознавание (обнаружение) тупика требует дальнейшего восстановления вычислений. Восстановление можно интерпретировать как запрет постоянного пребывания в опасном состоянии. Существуют следующие методы восстановления:
– принудительный перезапуск системы, характеризующийся потерей информации обо всех процессах, существующих до перезапуска;
135
– принудительное завершение процессов, находящихся в тупике;
– принудительное последовательное завершение процессов, находящихся в тупике, с последующим вызовом алгоритма распознания после каждого завершения до исчезновения тупика;
– перезапуск процессов, находящихся в тупике, с некоторой контрольной точки, т.е. из состояния, предшествовавшего запросу на ресурс (в контрольной точке запоминается вся информация, необходимая для восстановления программы с данного места, поэтому операции «контрольная точка» расставляются в программе в тех местах, после которых возможно возникновение тупика, т.е., как правило, перед запросом на ресурс);
– перераспределение ресурсов с последующим последовательным перезапуском процессов, находящихся в тупике.
Основные издержки восстановления составляют потери времени на
повторные вычисления, которые могут оказаться весьма существенными. К сожалению, в ряде случаев восстановление может стать невозможным, например исходные данные, поступившие с каких-либо датчиков, могут измениться, тогда предыдущие значения будут безвозвратно потеряны.
Функции операционных систем по управлению памятью
3.1.1 Память (memory) является важнейшим ресурсом (вторым по важности после ЦП), требующим тщательного управления со стороны мультипрограммной ОС. Здесь под памятью подразумевается оперативная (вернее сказать, внутренняя) память компьютера, которая в отличие от внешней памяти (storage), например, НЖМД, требует для сохранения информации постоянного электропитания.
Особая роль памяти объясняется тем, что процессор может выполнять инструкции программы только в том случае, если они находятся в памяти. Память распределяется как между модулями прикладных программ, так и между модулями самой ОС.
В ранних ОС управление памятью сводилось просто к загрузке программы и её данных из некоторого внешнего накопителя (перфоленты, магнитной ленты или магнитного диска) в память. С появлением мультипрограммирования перед ОС были поставлены новые задачи, связанные с распределением имеющейся памяти между несколькими одновременно выполняющимися программами.
136
Функциями ОС по управлению памятью (memory management) в мультипрограммной системе являются:
– отслеживание свободной и занятой памяти;
– выделение памяти процессам и освобождение памяти по завершении процессов;
– вытеснение кодов и данных процессов из оперативной памяти на диск (полное или частичное), когда размеры основной памяти недостаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место;
– настройка адресов программы на конкретную область физической памяти.
3.1.2 Помимо первоначального выделения памяти процессам при их создании ОС должна также заниматься динамическим распределением памяти, т.е.
выполнять запросы приложений на выделение им дополнительной памяти во время выполнения. После того как приложение перестаёт нуждаться в дополнительной памяти, оно может возвратить её системе. Выделение памяти случайной длины в случайные моменты времени из общего пула памяти приводит к фрагментации и, вследствие этого, к неэффективному её использованию. Дефрагментация памяти тоже является функцией ОС по управлению памятью.
Во время работы ОС ей часто приходится создавать новые служебные информационные структуры, такие как: описатели процессов и потоков; различные таблицы распределения ресурсов; буферы, используемые процессами для обмена данными; синхронизирующие объекты и т.п. Все эти системные объекты требуют памяти. В некоторых ОС заранее (во время установки) резервируется некоторый фиксированный объём памяти для системных нужд. В других же ОС используется более гибкий подход, при котором память для
системных целей выделяется динамически. В таком случае разные подсистемы ОС при создании своих таблиц, объектов, структур и т.п. обращаются к подсистеме управления памятью с запросами.
Защита памяти – это ещё одна важная задача ОС, которая состоит в том, чтобы не позволить выполняемому процессу записывать или читать данные из памяти, назначенной другому процессу. Эта функция, как правило, реализуется программными модулями ОС в тесном взаимодействии с аппаратными средствами.
Типы адресов
3.2.1 Типы адресов
Для идентификации переменных и команд на разных этапах жизненного цикла программы используются (рисунок 3.1):
– символьные имена – их присваивает пользователь при написании
137
Символьные имена
Транслятор
 Виртуальные
адреса
Виртуальные
адреса
Физические адреса
Идентификаторы переменных в программе на алгоритмическом языке
Условные адреса,
вырабатываемые транслятором
Номера ячеек физической памяти

Рисунок 3.1 – Типы адресов
программы на алгоритмическом языке или ассемблере;
– виртуальные (математические или, иначе, логические) адреса – их вырабатывает транслятор, переводящий программу на машинный язык. Поскольку во время трансляции в общем случае неизвестно, в какое место оперативной памяти будет загружена программа, то транслятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что начальным адресом программы будет нулевой адрес;
– физические адреса – соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды.
Виртуальное адресное пространство
Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Диапазон возможных адресов виртуального
пространства у всех процессов является одним и тем же. Например, при использовании 32–разрядных виртуальных адресов этот диапазон задаётся границами 0000000016 и FFFFFFFF16. Тем не менее каждый процесс имеет собственное виртуальное адресное пространство – транслятор присваивает виртуальные адреса переменным и кодам каждой программы независимо друг от друга. Причём совпадение виртуальных адресов переменных и команд различных процессов не приводит к конфликтам, так как в том случае, когда эти переменные одновременно присутствуют в памяти, ОС отображает их на разные физические адреса.
П ри м е ч а н ие – В том случае, когда необходимо, чтобы несколько процессов разделяли общие данные или коды, операционная система отображает соответствующие участки виртуального адресного пространства этих процессов на один и тот же участок физической памяти.
138
Необходимо различать максимально возможное виртуальное адресное пространство процесса и назначенное (выделенное) процессу виртуальное адресное пространство. В первом случае речь идёт о максимальном размере виртуального адресного пространства, определяемом архитектурой компьютера, в частности разрядностью его схем адресации (32–битная, 64– битная и т.п.). Например, при работе на компьютерах с 32-разрядными процессорами Intel Pentium ОС может предоставить каждому процессу виртуальное адресное пространство до 4Гбайт (232). Однако это значение
представляет собой только потенциально возможный размер виртуального адресного пространства, который редко на практике бывает необходим процессу. Процесс использует только часть доступного ему виртуального адресного пространства. Заметим, что максимальный размер виртуального адресного пространства, как правило, не совпадает с объёмом физической памяти, имеющимся в компьютере (именно на этом факте и использовании внешней памяти основана виртуальная память). Назначенное же виртуальное адресное пространство представляет собой набор виртуальных адресов, действительно нужных процессу для работы. Эти адреса первоначально назначает программе транслятор на основании текста программы, когда создаёт кодовый сегмент, а также сегмент (сегменты) данных, с которыми программа работает. Затем при создании процесса ОС фиксирует назначенное виртуальное адресное пространство в своих системных таблицах. В ходе своего выполнения процесс может увеличить размер первоначального назначенного ему виртуального адресного пространства, запросив у ОС создания дополнительных сегментов или увеличения размера существующих. В любом случае операционная система обычно следит за корректностью использования процессом виртуальных адресов – процессу не разрешается оперировать с виртуальным адресом, выходящим за пределы назначенных ему сегментов.
Максимальный размер виртуального адресного пространства, как отмечалось выше, ограничивается только разрядностью адреса, присущей данной архитектуре компьютера, и, как правило, не совпадает с объёмом физической памяти, имеющимся в компьютере (чаще всего превосходит её). Сегодня для машин универсального назначения типична ситуация, когда объём виртуального адресного пространства превышает доступный объём оперативной памяти. В таком случае ОС для хранения данных виртуального адресного пространства процесса, не помещающихся в оперативную память, использует внешнюю память, которая в современных компьютерах представлена жёсткими дисками (рисунок 3.2, а). Именно на этом принципе основана виртуальная память – наиболее совершенный механизм, используемый в ОС для управления памятью.
Однако соотношение объёмов виртуальной и физической памяти может
быть и обратным. Так, в мини-компьютерах 80-х годов прошлого века разрядности поля адреса нередко не хватало для того, чтобы охватить всю
139
имеющуюся оперативную память. Несколько процессов могло быть загружено в память одновременно и целиком (см. рисунок 3.2, б).
FFFFFF
 000000
000000
ОП
Дисковая память
а б
Рисунок 3.2 – Соотношение объёмов виртуального адресного пространства и физической памяти: а – виртуальное адресное пространство превосходит объём физической памяти; б – виртуальное адресное пространство меньше объёма физической памяти
Необходимо подчеркнуть, что виртуальное адресное пространство и виртуальная память – это различные механизмы, и они не обязательно реализуются в операционной системе одновременно. Можно представить себе ОС, в которой поддерживаются виртуальные адресные пространства для процессов, но отсутствует механизм виртуальной памяти. Это возможно только в том случае, если размер виртуального адресного пространства каждого процесса меньше объёма физической памяти.
Способы структуризации вирт-го адресного пространства
В разных ОС используются разные способы структуризации виртуального адресного пространства (рисунок 3.3):
140
– в виде непрерывной линейной последовательности виртуальных адресов – такую структуру адресного пространства, подобную физической памяти, называют также плоской (flat), при этом виртуальным адресом является единственное число m, называемое линейным виртуальным адресом и представляющим собой смещение относительно начала (обычно это значение
000...000) виртуального адресного пространства (см. рисунок 3.3, а);
– в виде частей, называемых сегментами (секциями, областями или другими терминами) – в этом случае (помимо линейного адреса) может быть использован виртуальный адрес в виде пары чисел (n, m), где n определяет сегмент, а m – внутрисегментное смещение (смещение внутри сегмента) (см. рисунок 3.3, б).
Существуют и более сложные способы структуризации виртуального адресного пространства, когда виртуальный адрес образуется тремя и даже более
числами.
 Сегмент
K
Сегмент
K
(n,m)
m
 Сегмент
n
Сегмент
n
…
 m
m
Сегмент 1
а б
Рисунок 3.3 – Типы виртуальных адресных пространств: а – плоское;
б – сегментированное
Классификация методов распределения памяти
Рассмотрим наиболее общие подходы к распределению памяти, которые были характерны для разных периодов развития операционных систем. Некоторые из них сохранили актуальность и широко используются в современных ОС, другие же представляют в основном только познавательный интерес, хотя их и сегодня можно встретить в специализированных системах.
Все алгоритмы распределения памяти разделены на два класса
(рисунок 3.6): алгоритмы, в которых используется перемещение сегментов процессов между ОП и диском, и алгоритмы, в которых внешняя память не
привлекается.
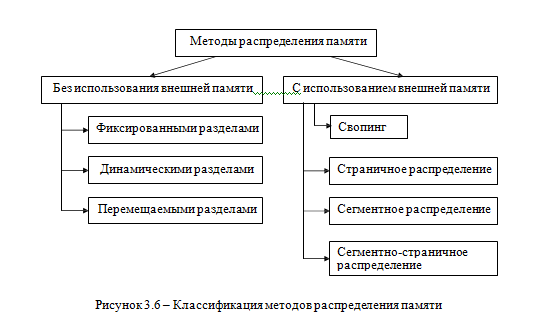
Распределения памяти без использования внешней памяти
3.4.1 Распределение памяти фиксированными разделами (с общей и с раздельными очередями)
145
Методы распределения памяти
Без использования внешней памяти С использованием внешней памяти
Фиксированными разделами
Свопинг
Динамическими разделами
Страничное распределение
Перемещаемыми разделами
Сегментное распределение

Сегментно-страничное распределение
Рисунок 3.6 – Классификация методов распределения памяти
Простейший способ управления оперативной памятью состоит в том, что память разбивается на несколько непрерывных областей фиксированной величины, называемых фиксированными (статическими) разделами (partitions, regions). Такое разбиение может быть выполнено вручную оператором во время старта системы или во время её установки, после чего границы разделов не изменяются. В каждом разделе могло размещаться одно задание. ЦП быстро переключался с задания на задание, создавая иллюзию одновременного их выполнения.
Очередной новый процесс, поступивший на выполнение, помещается либо в общую очередь (рисунок 3.7, а), либо в очередь к некоторому разделу
(рисунок 3.7, б). Здесь ОС осуществляет загрузку программы в один из разделов,
причём уже на этапе трансляции разработчик программы может задать раздел, в котором её следует выполнять. Это позволяет сразу, без использования перемещающего загрузчика (см. пункт 3.2.4), получить машинный код, настроенный на конкретную область памяти.
Трансляция заданий производилась при помощи ассемблеров и компиляторов в абсолютных адресах с расчётом на выполнение только в конкретном разделе (см. рисунок 3.7, б). Если задание было готово для выполнения, а его раздел в это время был занят, то заданию приходилось ждать, несмотря на то, что другие разделы были свободны. Это приводило к неэффективному использованию ресурсов памяти, однако позволяло относительно
146
 Очередь
задач
Очередь
задач
а
Раздел 1
Раздел 2
ОС |
|
|
|
|
|
|
 Раздел
3
Раздел
3

 Очереди
к разделам
Очереди
к разделам
 Раздел
1
Раздел
1
Раздел 2
ОС |
|
|
|
|
|
Раздел 3
б

 –
свободная
память
–
свободная
память
Рисунок 3.7 – Распределение памяти фиксированными разделами: а –
с общей очередью; б – с отдельными очередями
просто реализовать функции ОС по управлению памятью. Перемещающие компиляторы, ассемблеры и загрузчики применяются для трансляции и загрузки перемещаемых модулей, которые могут работать в любом свободном разделе, достаточно большом для их размещения (см. рисунок 3.7, а). Такой подход свободен от некоторых принципиальных недостатков в использовании памяти, присущих мультипрограммированию с трансляцией и загрузкой в абсолютных адресах (т.е. распределению памяти фиксированными разделами с отдельными очередьми). Однако трансляторы и загрузчики перемещаемых модулей гораздо сложнее, чем трансляторы и загрузчики в абсолютных адресах.
При очевидном преимуществе – простоте реализации данный метод
управления памятью имеет существенный недостаток – жёсткость. Так как в
каждом разделе может выполняться только один процесс, то уровень мультипрограммирования заранее ограничен числом разделов (считается, что
147
независимо от размера программы она будет занимать весь раздел). С другой стороны, разбиение памяти на разделы не позволяет выполнять процессы, программы которых не помещаются ни в один из разделов, но для которых было бы достаточно памяти нескольких разделов.
Такой способ управления памятью применялся в ранних мультипрограммных ОС. Однако и сейчас метод распределения памяти фиксированными разделами находит применение в системах реального времени, в основном благодаря небольшим затратам на реализацию. Детерминированность вычислительного процесса систем реального времени (т.е. заранее известен набор выполняемых задач, их требования к памяти, а иногда и моменты запуска) компенсирует недостаточную гибкость данного способа управления памятью.
3.4.2 Распределение памяти динамическими разделами
В случае распределения памяти динамическими разделами память машины не делится заранее на разделы, и сначала вся память, отводимая для приложений, свободна. Каждому вновь поступающему на выполнение приложению на этапе создания процесса выделяется вся необходимая ему память (если достаточный объём памяти отсутствует, то приложение не
принимается на выполнение и процесс для него не создаётся). После завершения процесса память освобождается, и на это место может быть загружен другой процесс. На рисунке 3.8 показано распределение памяти динамическими разделами.
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает бóльшей гибкостью, но ему присущ очень серьёзный недостаток – фрагментация памяти. Фрагментация – это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков целиком, хотя суммарный объём фрагментов может составить значительную величину, намного превышающую требуемый объём памяти. В принципе фрагментация
памяти имеет место в любой вычислительной машине независимо от организации её памяти. В мультипрограммных системах с фиксированными разделами фрагментация происходит либо потому, что задания пользователя в действительности не полностью занимают выделенные им разделы (хотя при этом считается, что процесс полностью занимает раздел), либо в случае, когда некоторый раздел остаётся незанятым из-за того, что он слишком мал для размещения ожидающего задания.
Распределение памяти динамическими разделами лежит в основе подсистем управления памятью многих мультипрограммных ОС 60-70-х годов прошлого века, в частности такой популярной ОС, как OS/360.
3.4.3 Распределение памяти перемещаемыми разделами
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших или младших адресов с тем, чтобы вся
148
П6
 ОС
ОС
ОС |
П1 |
П2 |
П3 |
П4 |
П5 |
|
ОС |
П1 |
П2 |
П3 |
|
П5 |
|
ОС |
П1 |
П2 |
П3 |
П6 |
|
П5 |
|
t0 t1 t2
t3 tk
ОС |
|
|
|
|
|
|
|
|
 .
. .
.
. .

 –
свободная
область; –
занятая
область; П
–
процесс
–
свободная
область; –
занятая
область; П
–
процесс
Рисунок 3.8 – Распределение памяти динамическими разделами
свободная память образовала единую свободную область. В дополнение к функциям, которые выполняет ОС при распределении памяти динамическими разделами в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется сжатием (компрессией, уплотнением) памяти или сборкой мусора (garbage collection). Такой метод распределения памяти носит название распределения памяти перемещаемыми разделами (рисунок 3.9).
Сжатие может выполняться либо при каждом завершении процесса, либо
только тогда, когда для вновь создаваемого процесса нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц свободных и занятых областей, а во втором – реже выполняется процедура сжатия. Так как программы перемещаются по ОП в ходе своего выполнения, то в данном случае невозможно выполнить настройку адресов с помощью перемещающего загрузчика. Здесь более подходящим оказывается динамическое преобразование адресов (см. пункт 3.2.4). Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени (накладных расходов), что часто
149
перевешивает преимущества данного метода (заметим, что во время уплотнения памяти система должна прекращать любые другие работы).
ОС


 П1
a П2
П1
a П2


 b П3
b П3

 c П4
c П4
Процедура сжатия

ОС |
|
П1 |
|
|
|
П2 |
|
|
|
П3 |
|
|
|
П4 |
|
|
|
 d
d
a+b+c+d
t1 t2
Рисунок 3.9 – Распределение памяти перемещаемыми разделами
Концепция сжатия применяется и при использовании других методов распределения памяти, когда отдельному процессу выделяется не одна сплошная область памяти, а несколько несмежных участков памяти произвольного размера (сегментов). Такой подход был использован в ранних версиях OS/2, в которых память распределялась сегментами, а возникавшая при этом фрагментация устранялась путём периодического перемещения сегментов.
Мультипрограммирование со свопингом
3.5.1 Необходимым условием для того, чтобы программа могла выполняться, является её нахождение в оперативной памяти. Только в этом случае процессор может извлекать команды из памяти и интерпретировать их, выполняя заданные действия.
Одним из первых решений проблемы размещения в памяти программы, размер которой превышает имеющуюся в наличии свободную память, было разбиение программы на части, называемые оверлеями (перекрытиями) (over-lay
– лежащий сверху). Смысл оверлея состоит в том, чтобы не загружать программу в память целиком, а разбить её на несколько модулей и помещать их в память по
150
мере необходимости. При этом на одни и те же адреса в различные моменты времени будут отображены разные модули. Когда первый оверлей заканчивал своё выполнение, он вызывал другой оверлей. Все оверлеи хранились на диске и перемещались между памятью и диском средствами ОС на основании явных директив программиста, содержащихся в программе. Этот способ, несмотря на внешнее сходство, имеет принципиальное отличие от виртуальной памяти, заключающееся в том, что разбиение программы на части и планирование их загрузки в ОП должны были выполняться заранее программистом во время написания программы.
3.5.2 Объём оперативной памяти, который имеется в компьютере, существенно сказывается на характере протекания вычислительного процесса. Он ограничивает число одновременно выполняющихся программ и размеры их виртуальных адресных пространств. Подмена (виртуализация) оперативной
памяти дисковой (т.е. внешней) памятью позволяет повысить уровень мультипрограммирования – объём ОП компьютера в этом случае не столь жёстко ограничивает количество одновременно выполняемых процессов, поскольку суммарный объём памяти, занимаемый образами этих процессов, может существенно превосходить имеющийся объём ОП. Виртуальным называется ресурс, который пользователю или пользовательской программе представляется обладающим свойствами, которыми он в действительности не обладает. В данном случае в распоряжение прикладного программиста предоставляется виртуальная оперативная память, размер которой намного превосходит всю имеющуюся в системе реальную ОП. Пользователь пишет программу, а после её трансляции система, используя виртуальные адреса, переводит её в машинные коды так, как будто в распоряжении программы имеется однородная ОП большого объёма. В действительности же все (или почти все) коды и данные, используемые программой, хранятся на дисках и только при необходимости загружаются в реальную ОП. Понятно, что работа такой «оперативной памяти» происходит значительно медленнее, чем реальной. Виртуализация ОП осуществляется ОС и аппаратурой процессора автоматически, без участия программиста, и никак не сказывается на логике работы приложений. Заметим, что концепция виртуальной памяти является далеко не новой. Впервые она была реализована в вычислительной машине Atlas, созданной в Манчестерском университете в Англии ещё в 1960г.
3.5.3 В условиях, когда для обеспечения приемлемого уровня мультипрограммирования имеющейся оперативной памяти недостаточно, был предложен метод организации вычислительного процесса, при котором образы некоторых процессов целиком временно выгружаются на диск.
Свопинг (swapping – обмен) представляет собой частный (крайний) случай
виртуальной памяти, когда образы приостановленных процессов (ожидающих завершения ввода-вывода или освобождения ресурсов), а также образы готовых
151
процессов могут быть временно, до следующего цикла активности, выгружены на диск. Несмотря на то, что коды и данные процесса отсутствуют в ОП, ОС
«знает» о его существовании и в полной мере учитывает это при распределении
процессорного времени и других системных ресурсов. К моменту, когда подходит очередь выполнения выгруженного процесса, его образ возвращается с диска в ОП. Если при этом обнаруживается, что свободного места в ОП не хватает, то на диск выгружается другой процесс.
Свопингу свойственна избыточность. Когда ОС решает активизировать процесс, то для его выполнения, как правило, не требуется загружать в ОП все его сегменты полностью – достаточно загрузить небольшую часть кодового сегмента с подлежащей выполнению инструкцией и часть сегмента данных, с которыми работает эта инструкция, а также отвести место под сегмент стека. Аналогично, при освобождении памяти для загрузки нового процесса очень часто вовсе не
требуется выгружать другой процесс на диск целиком, достаточно вытеснить на диск только часть его образа. Перемещение избыточной информации замедляет работу системы, а также приводит к неэффективному использованию памяти. Кроме того, системы, поддерживающие свопинг, имеют ещё один существенный недостаток: они не способны загрузить для выполнения процесс, виртуальное адресное пространство которого превышает имеющуюся в наличии свободную память.
Именно из-за указанных недостатков свопинг в качестве основного механизма управления памятью почти не используется в современных ОС. В некоторых современных ОС, например версиях UNIX, основанных на коде SVR4, механизм свопинга используется как дополнительный к виртуальной памяти, включающийся только при серьёзных перегрузках системы.
Виртуальная память
Память стандартной и дополнительных куч
Замещение страниц виртуальной памяти
Сегментная виртуальная память
Сегментно-страничная виртуальная память
3.6.1 Основные концепции
Виртуализация оперативной памяти осуществляется совокупностью программных модулей ОС и аппаратных схем процессора и включает решение следующих задач:
– размещение данных в запоминающих устройствах разного типа,
например часть кодов программы – в оперативной памяти, а часть – на диске;
– выбор образов процессов или их частей для перемещения из оперативной памяти на диск и обратно;
– перемещение по мере необходимости данных между памятью и диском;
– преобразование виртуальных адресов в физические.
Виртуализация памяти может быть осуществлена на основе двух различных подходов:
152
– свопинг (swapping – обмен) – образы процессов выгружаются на диск и возвращаются в ОП целиком (см. пункт 3.5.3);
– виртуальная память (virtual memory) – между оперативной памятью и
диском перемещаются части (сегменты, страницы и т.п.) образов процессов.
Суть концепции виртуальной памяти заключается в том, что адреса, к которым обращается выполняющийся процесс, отделяются от адресов, реально существующих в первичной (оперативной, основной, физической, реальной) памяти. Те адреса, на которые делает ссылки выполняющийся процесс, называются виртуальными адресами, а те адреса, которые существуют в первичной памяти, называются реальными (или физическими) адресами. Диапазон виртуальных адресов, к которым может обращаться выполняющийся процесс, называется пространством виртуальных адресов V этого процесса. Диапазон реальных адресов, существующих в конкретной ЭВМ, называется
пространством реальных адресов R этой машины. Виртуальная память представляет собой моделируемую на внешней (вторичной, вспомогательной) памяти основную память машины.
Несмотря на то, что процессы обращаются только к виртуальным адресам, в действительности же они должны работать с реальной памятью. Таким образом, во время выполнения процесса виртуальные адреса необходимо преобразовывать в реальные, причём это нужно делать быстро, ибо в противном случае производительность ЭВМ будет снижаться до неприемлемых уровней и тем самым практически сведутся на нет те преимущества, которые и призвана обеспечить прежде всего концепция виртуальной памяти. Перевод виртуальных адресов в реальные во время выполнения процесса называется динамическим преобразованием адресов (DAT – Dynamic Address Translation) (см. пункт 3.2.4). Динамическое преобразование адресов выполняет сама система, причём это
делается прозрачно (невидимо) для пользователя. Все системы DAT обладают общим свойством, называемым «искусственной смежностью». Искусственная смежность, или непрерывность означает, что адреса, смежные в виртуальном адресном пространстве процесса V, не обязательно будут смежными в реальном адресном пространстве R (рисунок 3.10).
Таким образом, ключевой проблемой виртуальной памяти, возникающей в
результате многократного изменения местоположения в ОП образов процессов или их частей, является преобразование виртуальных адресов в физические.
Решение этой проблемы, в свою очередь, зависит от того, какой способ структуризации виртуального адресного пространства принят в данной системе управления памятью. В настоящее время всё множество реализаций виртуальной
памяти может быть представлено тремя классами:
– страничная виртуальная память – организует перемещение данных между памятью и диском страницами, т.е. частями виртуального адресного
пространства фиксированного и сравнительно небольшого размера;
153
…
…
Смежные ячейки (блоки) виртуальной памяти
 DAT
DAT
…
Виртуальная память
Механизм отображения адресов
Реальная (оперативная) память
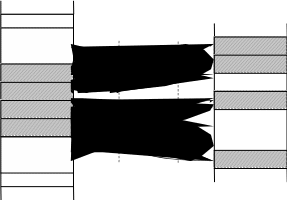
Рисунок 3.10 – Искусственная смежность
– сегментная виртуальная память (свопинг сегментов) – предусматривает перемещение данных сегментами, т.е. частями виртуального адресного пространства произвольного размера, полученными с учётом смыслового значения данных;
– сегментно–страничная виртуальная память – использует двухуровневое
деление: виртуальное адресное пространство делится на сегменты, а сегменты в свою очередь делятся на страницы. Единицей перемещения данных здесь является страница. Этот способ управления памятью объединяет в себе элементы обоих предыдущих подходов.
Для врéменного хранения сегментов и страниц на диске отводится либо специальная область, либо специальный файл, которые во многих ОС по традиции продолжают называть областью или файлом свопинга, хотя перемещение информации между ОП и диском осуществляется уже не в форме полного замещения одного процесса другим, а частями. Другое популярное название этой области – страничный файл (page file, или paging file). Текущий размер страничного файла является важным параметром, оказывающим влияние на возможности ОС: чем больше страничный файл, тем больше приложений может одновременно выполнять ОС (при фиксированном объёме ОП). Однако
154
необходимо помнить, что увеличение числа одновременно работающих приложений за счёт увеличения размера страничного файла замедляет их работу, так как значительная часть времени при этом тратится на перекачку кодов и данных из ОП на диск и обратно.
3.6.2 Страничная виртуальная память
3.6.2.1 В этом случае адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами (virtual pages). В общем случае размер виртуального
адресного пространства процесса не кратен размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью.
Вся ОП машины также делится на части такого же размера, называемые физическими страницами (блоками, или кадрами). Размер страницы выбирается равным степени двойки – 512, 1024, 4096байт и т.д., что позволяет упростить механизм преобразования адресов.
При создании процесса ОС загружает в ОП несколько его виртуальных страниц (начальные страницы кодового сегмента и сегмента данных). Копия всего виртуального адресного пространства процесса находится на диске. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. Для каждого процесса ОС создаёт таблицу (дескрипторов) страниц (AT – Allocation Table) – информационную структуру, содержащую записи обо всех виртуальных страницах процесса. Запись таблицы, называемая
дескриптором страницы, включает следующую информацию:
– номер физической страницы, в которую загружена данная виртуальная страница;
– признак (бит) присутствия, устанавливаемый в единицу, если виртуальная страница находится в ОП;
– признак модификации страницы, который устанавливается в единицу всякий раз, когда производится запись по адресу, относящемуся к данной странице;
– признак обращения к странице, называемый также битом доступа, который устанавливается в единицу при каждом обращении по адресу, относящемуся к данной странице.
Информация из таблиц страниц используется для решения вопроса о необходимости перемещения той или иной страницы между памятью и диском, а
также для преобразования виртуального адреса в физический. Сами таблицы страниц, так же как и описываемые ими страницы, размещаются в ОП. Адрес таблицы страниц (AT) включается в контекст соответствующего процесса. При активизации очередного процесса ОС загружает адрес его таблицы страниц в специальный регистр процессора.
При каждом обращении к памяти выполняется поиск номера виртуальной
страницы, содержащей требуемый адрес, затем по этому номеру определяется
155
нужный элемент таблицы страниц и из него извлекается описывающая страницу информация. Далее анализируется признак присутствия, и, если данная виртуальная страница находится в ОП, выполняется преобразование виртуального адреса в физический, т.е. виртуальный адрес заменяется указанным в записи таблицы физическим адресом (рисунок 3.11). Если же нужная
Виртуальный адрес (p,S) Номер виртуальной страницы – p
Cмещение в виртуальной странице – S
Номера физических страниц
Регистр процессора
Начальный адрес таблицы страниц – AT
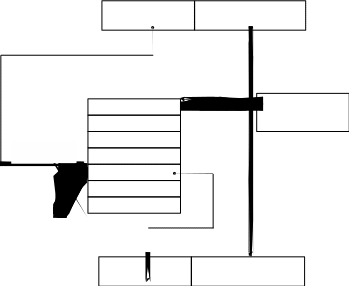 AT+(p*L)
AT+(p*L)
L – длина n
записи
Страничное прерывание
Физический адрес
Номер физической страницы – n
Смещение в физической странице – S
Рисунок 3.11 – Преобразование виртуального адреса в физический при страничной организации памяти
виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание: выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди процессов, находящихся в состоянии готовности. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу (для этого ОС должна помнить положение вытесненной страницы в страничном файле диска) и пытается загрузить её в ОП. Если в памяти имеется свободная физическая
156
страница, то загрузка выполняется немедленно; если же свободных страниц нет, то на основании принятой в данной системе стратегии замещения страниц решается вопрос о том, какую страницу следует выгрузить из ОП.
После того как выбрана страница, которая должна покинуть оперативную память, обнуляется её бит присутствия и анализируется её признак модификации. Если выталкиваемая страница за время последнего пребывания в ОП была модифицирована, то её новая версия должна быть переписана на диск. Если нет, то принимается во внимание, что на диске уже имеется предыдущая копия этой виртуальной страницы, и никакой записи на диск не производится. Физическая страница объявляется свободной. Из соображений безопасности в некоторых системах освобождаемая страница обнуляется с тем, чтобы невозможно было использовать содержимое выгруженной страницы.
3.6.2.2 Типичная машинная инструкция требует трёх, четырёх обращений к памяти (выборка команды, извлечение операндов, запись результата). И при
каждом обращении происходит либо преобразование виртуального адреса в физический, либо обработка страничного прерывания. Время выполнения этих операций в значительной степени влияет на общую производительность вычислительной системы. Поэтому именно для уменьшения времени преобразования адресов во всех процессорах предусмотрен аппаратный механизм получения физического адреса по виртуальному.
Другим важным фактором, влияющим на производительность системы, является частота страничных прерываний, на которую, в свою очередь, влияют размер страницы и принятые в данной системе правила выбора страниц для выгрузки и загрузки. Например, на диск может выталкиваться страница, к которой в будущем (начиная с данного момента) дольше всего не будет обращений, или критерием выбора страницы на выгрузку является число обращений к ней за последний период времени, или при возникновении страничного прерывания
может производиться так называемая упреждающая загрузка (загружается нужная виртуальная страница вместе с несколькими прилегающими к ней страницами). Вообще, для решения проблемы замещения (определения той страницы, которая должна быть перемещена во внешнюю память, либо просто замещена новой) используются следующие дисциплины замещения:
– правило FIFO (First In First Out – первый пришедший первым и выбывает);
– правило LRU (Least Recently Used – дольше других неиспользуемый);
– правило LFU (Least Frequently Used – реже других используемый);
– случайный (random) выбор страницы.
Если объём физической памяти небольшой и даже часто требуемые страницы не удаётся разместить в ОП, то возникает так называемая
«пробуксовка». Другими словами, пробуксовка – это ситуация, при которой
загрузка нужной страницы вызывает перемещение во внешнюю память той страницы, с которой мы тоже активно работаем. Очевидно, что это очень
157
плохое явление. Чтобы его не допускать, желательно увеличить объём ОП, уменьшить количество параллельно выполняемых задач или прибегнуть к более эффективным дисциплинам замещения.
Для абсолютного большинства современных ОС характерна дисциплина замещения страниц LRU как самая эффективная. Так, именно эта дисциплина используется в OS/2 и в Linux. Однако в ОС Windows NT/2000/XP разработчики, желая сделать их максимально независимыми от аппаратных возможностей процессора, отказались от этой дисциплины и применили правило FIFO. А для частичной компенсации неэффективности правила FIFO была введена
«буферизация» тех страниц, которые должны быть записаны в файл подкачки на диск (в ОС Windows NT/2000/XP страничный файл носит название pagefile.sys) или просто расформированы. Принцип буферизации прост. Прежде чем замещаемая страница действительно окажется во внешней памяти или просто
расформированной, она помечается как кандидат на выгрузку. Если в следующий раз произойдёт обращение к странице, находящейся в таком «буфере», то страница никуда не выгружается и уходит в конец списка FIFO. В противном случае страница действительно выгружается, а на её место в «буфер» попадает следующий «кандидат». Величина такого «буфера» не может быть большой, поэтому эффективность страничной реализации памяти в Windows NT/2000/XP намного ниже, чем в других ОС, и явление пробуксовки начинается даже при существенно бóльшем объёме ОП.
Эффективность страничной организации памяти существенно зависит от размера страниц. Так как все страницы имеют один и тот же фиксированный размер, то никакая часть ОП не остаётся нераспределённой и не требуется перемещение её областей. Однако фрагментация всё же остаётся, поскольку задачам произвольной длины отводится целое число страниц
фиксированного размера. Она известна как внутренняя фрагментация или незаполненность страниц. В среднем на каждую задачу незаполненность последней виртуальной страницы будет составлять половину страницы. Чем бóльше размер страницы, тем бóльше общая незаполненность, тем меньше страниц находится в ОП, а, следовательно, и меньше задач, хотя частота страничных прерываний при этом ниже. С другой стороны, маленькие страницы требуют бóльше памяти под таблицы страниц (при размере страницы 4Кбайт и длине записи 4байт для хранения таблицы страниц может потребоваться 4Мбайт памяти!), при этом увеличивается вероятность отсутствия требуемой страницы в ОП, т.е. вероятность страничного прерывания. И хотя общий объём информации, подлежащий откачке-подкачке, сравним в условиях малых и больших размеров страниц, каждый обмен с внешней памятью требует одного и того же времени для подвода магнитной головки, а число обменов при малом размере страниц бoльшее. Из приведенных рассуждений следует, что выбор размера страницы является сложной оптимизационной задачей, требующей учёта многих факторов. На практике же разработчики ОС и процессоров ограничиваются неким
158
рациональным (разумным) решением, пригодным для широкого класса вычислительных систем. Типичный размер страницы составляет несколько килобайт, например, наиболее распространённые процессоры х86 и Pentium компании Intel, а также ОС, устанавливаемые на этих процессорах, поддерживают страницы размером 4096байт (4Кбайт).
П р и м е ч а н ие – Процессор Pentium позволяет использовать также страницы размером до 4Мбайт одновременно со страницами объёмом 4Кбайт.
3.6.2.3 Страничное распределение памяти может быть реализовано в упрощённом варианте, без выгрузки страниц на диск. В этом случае все виртуальные страницы всех процессов постоянно находятся в ОП. Такой вариант страничной организации хотя и не предоставляет пользователю преимуществ работы с виртуальной памятью большого объёма, но сохраняет другое достоинство страничной организации – позволяет успешно бороться с фрагментацией физической памяти. Действительно, во-первых, программу можно разбить на части и загрузить в разрозненные участки свободной памяти, во- вторых, при загрузке виртуальных страниц никогда не образуется неиспользуемых остатков, так как размеры виртуальных и физических страниц совпадают. Такой режим работы системы управления памятью используется в некоторых специализированных ОС, когда требуется высокая реактивность системы и способность выполнять переменный набор приложений (пример – ОС NetWare 3.x и 4.x семейства Novell).
3.6.2.4 Основным достоинством страничного способа распределения памяти является минимальная фрагментация ОП. Поскольку на каждую задачу может приходиться по одной незаполненной странице, очевидно, что память можно использовать достаточно эффективно. Этот метод организации виртуальной памяти был бы одним из самых лучших, если бы не два следующих
недостатка:
– страничная организация виртуальной памяти требует существенных накладных расходов: таблицы страниц тоже нужно размещать в ОП (кстати, принципиально возможно врéменно вытеснять часть таблицы страниц из ОП!), кроме того, эти таблицы нужно обрабатывать (с ними работает диспетчер памяти);
– программы разбиваются компилятором на страницы случайно (произвольно), и в общем случае нет никаких гарантий, что страницы будут соответствовать логическим группам команд или данных. Это приводит, во- первых, к тому, что межстраничные переходы, как правило, осуществляются чаще, чем межсегментные (см. пункт 3.6.3), и, во-вторых, к тому, что становится трудно организовать разделение программных модулей между выполняющимися процессами.
3.6.3 Сегментная виртуальная память
3.6.3.1 При страничной организации виртуальное адресное пространство
159
процесса делится на равные части механически, без учёта смыслового значения данных. В одной странице могут оказаться и коды команд, и инициализируемые переменные, и массив исходных данных программы. Такой подход не позволяет обеспечить дифференцированный доступ к разным частям программы, а это свойство могло бы быть очень полезным во многих случаях. Например, можно было бы запретить обращаться с операциями записи в сегмент программы, содержащий коды команд, разрешив эту операцию для сегментов данных.
Кроме того, разбиение виртуального адресного пространства на
«осмысленные» части делает принципиально возможным совместное использование фрагментов программ разными процессами. Пусть, например, двум процессам требуется одна и та же подпрограмма, которая к тому же обладает свойством реентерабельности [реентерабельность (reentrantable) – свойство повторной входимости кода, которое позволяет одновременно использовать его
несколькими процессами; при выполнении реентерабельного кода процессы не изменяют его, поэтому в память достаточно загрузить только одну копию кода]. Тогда коды этой подпрограммы могут быть оформлены в виде отдельного сегмента и включены в виртуальные адресные пространства обоих процессов. При отображении в физическую память сегменты, содержащие коды подпрограммы из обоих виртуальных пространств, проецируются на одну и ту же область физической памяти. Таким образом, оба процесса получат доступ к одной и той же копии подпрограммы.
3.6.3.2 Итак, при сегментной организации памяти (сегментации памяти) виртуальное адресное пространство процесса делится на части – сегменты, размер которых определяется с учётом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. Каждая программа состоит, как минимум, из двух типов
сегментов: сегментов кода, содержащих команды программы, и сегментов данных, содержащих данные, подлежащие обработке. Деление виртуального адресного пространства на сегменты осуществляется компилятором на основе указаний программиста или по умолчанию, в соответствии с принятыми в системе соглашениями. Максимальный размер сегмента определяется разрядностью виртуального адреса, например при 32-разрядном процессоре он равен 232=4Гбайт. При этом максимально возможное виртуальное адресное пространство процесса представляет собой набор из N виртуальных сегментов, каждый размером по 4Гбайт. В каждом сегменте виртуальные адреса находятся в диапазоне от 0000000016 до FFFFFFFF16. Важно отметить, что сегменты взаимно независимы как с точки зрения физической, так и логической. Физически сегмент может быть размещён по любому адресу при условии, что он занимает смежные ячейки. Логически разные сегменты, управляемые системой,
независимы и должны рассматриваться как области с линейной адресацией. Таким образом, сегменты не упорядочиваются друг относительно друга, так что общего для сегментов линейного виртуального адреса не существует, и
160
виртуальный адрес задаётся парой чисел: номером сегмента (g) и линейным виртуальным адресом внутри сегмента (S) (внутрисегментное смещение). Использование отрицательного смещения или превышающего размер сегмента является ошибкой адресации.
При загрузке процесса в ОП помещается только часть его сегментов; полная же копия виртуального адресного пространства находится в дисковой памяти. Для каждого загружаемого сегмента ОС подыскивает непрерывный участок свободной памяти достаточного размера. Смежные в виртуальной памяти сегменты одного процесса могут занимать в ОП несмежные участки. Если во время выполнения процесса происходит обращение по виртуальному адресу, относящемуся к сегменту, который в данный момент отсутствует в памяти, то происходит прерывание (в этом случае говорят, что сегмент отсутствует). ОС приостанавливает активный процесс, запускает на
выполнение следующий процесс из очереди, а параллельно организует загрузку нужного сегмента с диска. При отсутствии в памяти места, необходимого для загрузки сегмента, ОС выбирает сегмент на выгрузку, при этом она использует критерии, аналогичные рассмотренным выше критериям выбора страниц при страничном способе управления памятью (см. подпункт 3.6.2.2).
На этапе создания процесса во время загрузки его образа в ОП система создаёт таблицу (дескрипторов) сегментов процесса (аналогичную таблице страниц). Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
3.6.3.3 Как видно, сегментное распределение памяти имеет очень много общего со страничным распределением. Механизмы преобразования адресов этих
двух способов управления памятью тоже весьма схожи, однако в них имеются и существенные отличия, которые являются следствием того, что сегменты (в отличие от страниц) имеют произвольный размер. Выполняющийся процесс обращается к памяти по виртуальному адресу v=(g, S), где g – номер сегмента, a S – смещение в сегменте. Физический (реальный) адрес получается путём сложения базового адреса сегмента, который определяется по номеру сегмента g из таблицы сегментов, и смещения S (рисунок 3.12). Система с сегментной организацией функционирует аналогично системе со страничной организацией: при каждом обращении к ОП выполняется преобразование виртуального адреса в физический (динамическое преобразование адресов); время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти; при необходимости освобождения памяти некоторые сегменты выгружаются.
3.6.3.4 Одним из существенных отличий сегментной организации памяти
от страничной является возможность задания дифференцированных прав доступа процесса к его сегментам. Например, один сегмент данных, содержащий
161
Регистр таблицы сегментов
Базовый адрес b
таблицы сегментов
b
g
Виртуальный адрес v=(g,S)
номер сегмен- смещение та g S
b+g
g
S
g’ g’+S
Реальный адрес
r = g’+S
r
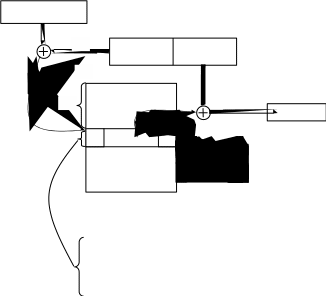 g’
g’
Дескриптор сегмента
Таблица сегментов текущего процесса
Прерывание по отсутствию сегмента
 Дескриптор
сегмента
Дескриптор
сегмента
-
Признак (бит) присутствия сегмента в ОП: 1 – в ОП;
0 – отсутству-
ет
Базовый фи- зический ад- рес сегмента g’ в ОП
Размер сегмен
-та
Правила доступа к сегменту, признаки модификации и об- ращения к сегменту, а также некоторая другая информация
 Таблица
сегментов
другого
процесса
Таблица
сегментов
другого
процесса
Рисунок 3.12 – Преобразование виртуального адреса при сегментной организации памяти
исходную информацию для приложения, может иметь права доступа «только чтение», а сегмент данных, представляющий результаты, – «чтение и запись». Это свойство даёт принципиальное преимущество сегментной модели памяти над страничной.
Недостатками сегментного распределения являются:
– использование операции сложения вместо конкатенации (склеивания) (см. рисунок 3.11) замедляет процедуру преобразования виртуального адреса в
162
физический по сравнению со страничной организацией;
– избыточность – при сегментной организации единицей перемещения между ОП и диском является сегмент, имеющий в общем случае объём бóльший, чем страница; однако во многих случаях для работы программы вовсе не требуется загружать весь сегмент целиком, достаточно было бы одной или двух страниц; аналогично, при отсутствии свободного места в памяти не стóит выгружать целый сегмент, когда можно обойтись выгрузкой нескольких страниц;
– внешняя фрагментация памяти (главный недостаток сегментного распределения) – возникает из-за непредсказуемости размеров сегментов. В процессе работы системы в памяти образуются небольшие участки свободной памяти, в которые не может быть загружен ни один сегмент (даже если суммарный объём этих участков превосходит требуемый для данного сегмента объём). Суммарный объём, занимаемый фрагментами свободной памяти, может
составить существенную часть общей памяти системы, приводя к её неэффективному использованию. Здесь в принципе может быть применено
«уплотнение памяти» (см. пункт 3.4.2).
П р и м е ч а н ие – Примером использования сегментного способа организации виртуальной памяти является операционная система OS/2 первого поколения (OS/2 v.1 начала создаваться в 1984 году и поступила в продажу в 1987 году), которая была создана для персональных компьютеров на базе процессора i80286. В этой ОС в полной мере использованы аппаратные средства микропроцессора, который специально проектировался для поддержки сегментного способа распределения памяти.
3.6.4 Сегментно-страничная виртуальная память
3.6.4.1 Сегментно-страничная виртуальная память обладает достоинствами сегментной и страничной видов памяти, но за счёт лишнего
обращения к памяти. Виртуальное адресное пространство процесса разделено на сегменты, содержащие разное, но целое число страниц. Это позволяет определять разные права доступа к разным частям кодов и данных программы. Перемещение же данных между памятью и диском осуществляется страницами. Для этого каждый виртуальный сегмент и физическая память делятся на страницы равного размера, что позволяет более эффективно использовать память, сократив до минимума фрагментацию (здесь будет лишь внутренняя фрагментация).
В большинстве современных реализаций сегментно-страничной организации памяти в отличие от набора виртуальных диапазонов адресов при сегментной организации памяти (см. пункт 3.6.3) все виртуальные сегменты образуют одно непрерывное линейное виртуальное адресное пространство.
Координаты байта в виртуальном адресном пространстве при
сегментно-страничной организации можно задать двумя способами. Во-первых,
линейным виртуальным адресом, который равен сдвигу данного байта
163
относительно границы общего линейного виртуального пространства, во- вторых, парой чисел, одно из которых является номером сегмента, а другое – смещением относительно начала сегмента. При этом в отличие от сегментной модели, для однозначного задания виртуального адреса вторым способом необходимо каким-то образом указать также начальный виртуальный адрес сегмента с данным номером. Системы виртуальной памяти ОС с сегментно- страничной организацией памяти используют второй способ, так как он позволяет непосредственно определить принадлежность адреса некоторому сегменту и проверить права доступа процесса к нему.
Для каждого процесса операционная система создает отдельную таблицу сегментов, в которой содержатся описатели (дескрипторы) всех сегментов процесса. Описание сегмента включает назначенные ему права доступа и другие характеристики, подобные тем, которые содержатся в дескрипторах
сегментов при сегментной организации памяти. Однако имеется и принципиальное отличие. В поле базового адреса указывается не начальный физический адрес сегмента, отведенный ему в результате загрузки в оперативную память, а начальный (базовый) линейный виртуальный адрес сегмента в пространстве виртуальных адресов. Наличие базового виртуального адреса сегмента в дескрипторе позволяет однозначно преобразовать адрес, заданный в виде пары (номер сегмента, смещение в сегменте), в линейный виртуальный адрес байта, который затем преобразуется в физический адрес страничным механизмом.
Деление общего линейного виртуального адресного пространства процесса и физической памяти на страницы осуществляется так же, как это делается при страничной организации памяти. Размер страниц выбирается равным степени двойки, что упрощает механизм преобразования виртуальных адресов в
физические. Виртуальные страницы нумеруются в пределах виртуального адресного пространства каждого процесса, а физические страницы – в пределах оперативной памяти. При создании процесса в память загружается только часть страниц, остальные загружаются по мере необходимости. Время от времени система выгружает уже ненужные страницы, освобождая память для новых страниц. ОС ведёт для каждого процесса таблицу страниц, в которой указывается соответствие виртуальных страниц физическим.
Базовые адреса таблицы сегментов и таблицы страниц процесса являются частью его контекста. При активизации процесса эти адреса загружаются в специальные регистры процессора и используются механизмом преобразования адресов.
Преобразование виртуального адреса v=(g,S) в физический r происходит в два этапа (рисунок 3.13):
– на первом этапе работает механизм сегментации и исходный виртуальный адрес (номер сегмента g, смещение S) преобразуется в линейный виртуальный адрес. Для этого на основании базового адреса таблицы сегментов и
164
Исходный виртуальный адрес v = (g,S)
Номер сегмента g Смещение S
Таблица сегментов процесса
Первый этап
Дескриптор сегмента
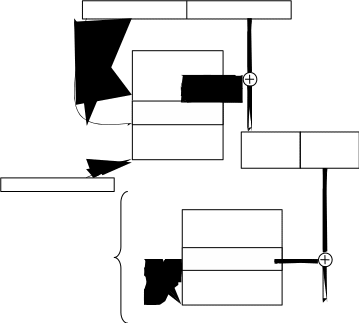 Базовый
виртуальный
адрес
сегмента
Базовый
виртуальный
адрес
сегмента
Линейный виртуальный адрес
Регистр процессора
Адрес таблицы сегментов
Номер виртуальной страницы
 Таблица
страниц
процесса
Таблица
страниц
процесса
Смещение в странице
Второй этап
Дескриптор страницы
Базовый физический адрес страницы
Страничное прерывание
Искомый физический адрес r
Рисунок 3.13 – Преобразование виртуального адреса v = (g,S) в физический при сегментно-страничной организации памяти
номера сегмента вычисляется адрес дескриптора сегмента. Анализируются поля дескриптора и выполняется проверка возможности выполнения заданной операции. Если доступ к сегменту разрешён, то вычисляется линейный виртуальный адрес путём сложения базового адреса сегмента, извлеченного из дескриптора, и смещения, заданного в исходном виртуальном адресе;
– на втором этапе работает страничный механизм и полученный линейный виртуальный адрес преобразуется в искомый физический адрес. В результате преобразования линейный виртуальный адрес представляется в том виде, в
165
котором он используется при страничной организации памяти – в виде пары (номер страницы, смещение в странице). Благодаря тому, что размер страницы выбран равным степени двойки, эта задача решается простым отделением некоторого количества младших двоичных разрядов. При этом в старших разрядах содержится номер виртуальной страницы, а в младших – смещение искомого элемента относительно начала страницы. Так, если размер страницы равен 2k, то смещением является содержимое младших k разрядов, а старшие разряды содержат номер виртуальной страницы, которой принадлежит искомый адрес.
Далее преобразование адреса происходит так же, как при страничной организации: старшие разряды линейного виртуального адреса, содержащие номер виртуальной страницы, заменяются номером физической страницы, взятым из таблицы страниц, а младшие разряды виртуального адреса, содержащие смещение, остаются без изменения.
Механизм сегментации и страничный механизм действуют достаточно независимо друг от друга. Поэтому нетрудно представить себе реализацию сегментно-страничного управления памятью, в которой механизм сегментации работает по вышеописанной схеме, а страничный механизм изменён. Он реализует двухуровневую схему, в которой виртуальное адресное пространство делится сначала на разделы, а уж потом на страницы. В таком случае преобразование виртуального адреса в физический происходит в несколько этапов. Сначала механизм сегментации обычным образом (используя таблицу сегментов) вычисляет линейный виртуальный адрес (см. рисунок 3.13). Затем из данного виртуального адреса вычленяются номер раздела, номер страницы и смещение. И далее по номеру раздела из таблицы разделов определяется адрес таблицы страниц, а затем по номеру виртуальной страницы из таблицы страниц определяется номер физической страницы, к которому пристыковывается смещение. Именно такой подход реализован компанией Intel в процессорах i386, i486 и Pentium.
Рассмотрим еще одну возможную схему сегментно-страничного управления памятью. Здесь всё виртуальное пространство процесса делится на сегменты, сегмент – на страницы, но страницы нумеруются не в пределах всего адресного пространства процесса, а в пределах сегмента. В этом случае виртуальный адрес является трёхкомпонентным (трёхмерным) и выражается упорядоченной тройкой v = (g,p,S) = (номер сегмента, номер страницы, смещение в странице).
Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в ОП, а часть — на диске. Для каждого процесса создаётся собственная таблица сегментов, а для каждого сегмента – своя таблица страниц. Адрес таблицы сегментов загружается в специальный
регистр процессора, когда активизируется соответствующий процесс.
Таблица страниц содержит дескрипторы страниц, содержимое которых полностью аналогично содержимому ранее описанных дескрипторов страниц. А
166
таблица сегментов состоит из дескрипторов сегментов, которые вместо информации о расположении сегментов в виртуальном адресном пространстве содержат описание расположения таблиц страниц в физической памяти. Схема преобразования виртуального адреса в физический для данного метода представлена на рисунке 3.14:
– по номеру сегмента, заданному в виртуальном адресе, из таблицы сегментов извлекается физический адрес соответствующей таблицы страниц;
– по номеру виртуальной страницы, заданному в виртуальном адресе, из таблицы страниц извлекается дескриптор, в котором указан номер физической страницы;
– к номеру физической страницы пристыковывается младшая часть виртуального адреса – смещение.
Виртуальный адрес v = (g,р,S)
Номер сегмента g Номер виртуальной страницы р
Смещение S
1 |
|
|
|
|
|
g |
|
|
|
|
|
|
|
|
|
Таблица сегментов процесса
Таблица страниц сегмента 1
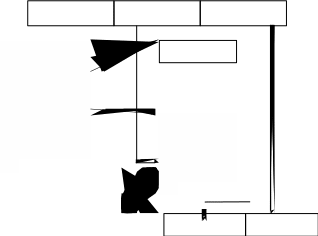 …
…
Таблица страниц сегмента g
-
p
n
Страничное прерывание
Номер физической страницы n
Смещение S
Физический адрес r = n&S
Рисунок 3.14 – Схема преобразования виртуального адреса v = (g,р,S) в физический для сегментно-страничной организации памяти
167
Примечание – Часть ядра Windows NT, которая занимается управлением виртуальной памятью, называется VMM – Virtual Memory Manager. Это независимый привилегированный процесс, постоянно находящийся в оперативной памяти компьютера.
Иерархия запоминающих устройств
Память (memory, storage) вычислительной машины является вторым по важности ресурсом и представляет собой иерархию запоминающих устройств (ЗУ), различающихся средним временем доступа к данным, объемом и стоимостью хранения одного бита (рисунок 3.15). Заметим, что приведенные на рисунке 2.15 численные значения характеристик ЗУ быстро изменяются по мере развития вычислительной техники, поэтому важны не их абсолютные значения, а их соотношения для разных типов запоминающих устройств.
Десятки байт
 1
СОП
(регистры
процессора)
1
СОП
(регистры
процессора)
~2-3нс
Время доступа уменьшает- ся
Десятки –
Внутренняя
память
сотни Кбайт
Десятки – 3
сотни Мбайт
Десятки и 4
сотни Гбайт