

10-11 вопросы Express.Концепция последовательной шины. Уровни
Шина PCI Express
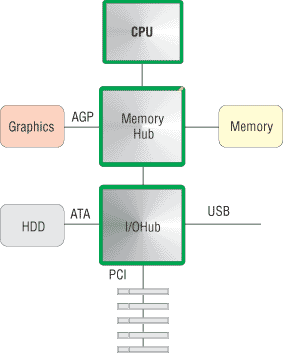
Шина PCI Express разрабатывается корпорацией Intel совместно с многочисленными ведущими компаниями, такими как Dell, Hewlett-Packard, IBM и т.д. Она относится уже к третьему поколению архитектуры ввода-вывода и называется также 3GIO (Third Generation Input Output). Особенно важно, что новая архитектура PCI Express будет совместима на программном уровне с шиной PCI. Концептуальные идеи, заложенные в архитектуре PCI Express, таковы.
В современных компьютерах имеется достаточно большое количество самых разнообразных шин: шина памяти, процессорная шина, PCI-шина, шина связи северного и южного мостов чипсета, шина AGP. Все они являются параллельными, что накладывает определенные ограничения на увеличение их тактовой частоты. Кроме того, появление более высокоскоростных процессоров, типов памяти, графических адаптеров и периферийных устройств требует и увеличения полосы пропускания соответствующих шин, что создает определенные трудности при разработке чипсетов, так как каждый раз приходится перерабатывать интерфейс взаимодействия чипсета с соответствующим устройством. Конечно, хорошо было бы иметь некую универсальную шину, которая бы связывала устройства друг с другом внутри компьютера и в то же время имела достаточно большой запас по масштабируемости, то есть обеспечивала требуемую полосу пропускания.
Итак, масштабируемость и универсальность — вот две основные концепции, заложенные в архитектуре новой шины PCI Express.
Универсальность шины PCI Express должна заключаться в том, чтобы она заменила шину, связывающую северный мост чипсета с графическим адаптером, шину, объединяющую северный и южный мосты чипсета, а также PCI-шину.
Масштабируемость шины PCI Express состоит в том, что шина позволяет наращивать пропускную способность от 2,5 Гбит/с вплоть до 10 Гбайт/с (80 Гбит/с). Для сравнения отметим, что пропускная способность шины PCI-X c частотой 133 МГц составляет 1,06 Гбит/с.
О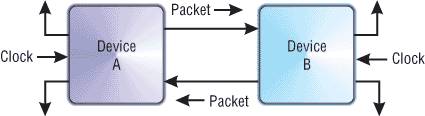 сновная
особенность новой шины PCI Express заключается
в том, что это не традиционная параллельная,
а последовательная (!) шина, работающая
по принципу «точка-точка» (peer-to-peer). На
физическом уровне шина образована двумя
парами проводников: одна пара служит
для передачи данных, а вторая — для их
приема. Две такие пары позволяют
организовать полосу пропускания 2,5
Гбит/с в одном направлении.
сновная
особенность новой шины PCI Express заключается
в том, что это не традиционная параллельная,
а последовательная (!) шина, работающая
по принципу «точка-точка» (peer-to-peer). На
физическом уровне шина образована двумя
парами проводников: одна пара служит
для передачи данных, а вторая — для их
приема. Две такие пары позволяют
организовать полосу пропускания 2,5
Гбит/с в одном направлении.
Для того чтобы обеспечить большую пропускную способность, поддерживается не одна, а несколько рассмотренных линий. Ширина одной линии с пропускной способностью 2,5 Гбит/с обозначается как x1; если используются две линии, то ширина линии будет х2. Первоначально на физическом уровне будет поддерживаться ширина линий х1, х2, х4, х8, х16 и х32. При этом при ширине линии х32 пропускная способность составит 80 Гбит/с или 10 Гбайт/с в одном направлении. Кроме того, 2,5 Гбит/с — это только начало. В дальнейшем скорость передачи по одной магистрали предполагается увеличить вплоть до 10 Гбит/с, что является теоретическим пределом для «медной пары».
Физический уровень шины PCI Express можно разделить на два подуровня: подуровень физического доступа к среде передачи данных (Physical Media Attachment Layer, PMA) и подуровень физического кодирования (Physical Coding Sublayer, PCS).
|
|
|
|
Физический уровень шины PCI Express |
|
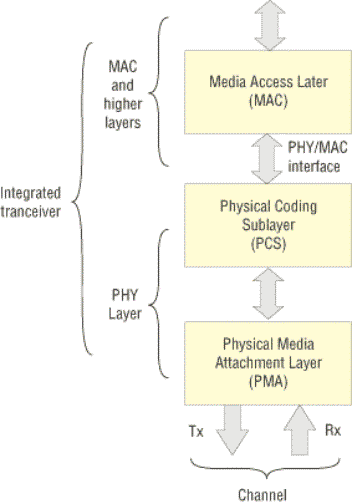
На физическом уровне линия PCI Express представляет собой две низковольтные дифференциальные пары проводов. Использование именно низковольтных дифференциальных сигналов (когда уровень сигнала в одном проводе измеряется относительно уровня сигнала в другом проводе) позволяет уменьшить влияние электромагнитных помех. Кроме того, с целью увеличения помехоустойчивости при передаче используется кодирование 8b/10b, которое производится на подуровне PCS.
Смысл такого кодирования достаточно прост — каждая последовательность 8 бит при передаче заменяется последовательностью 10 бит в соответствии со специальной таблицей замены. При этом в исходной последовательности 8 бит содержится 256 различных комбинаций нулей и единиц, а в результирующей — 1024. Данный подход позволяет избежать нежелательных последовательностей бит при передаче. Например, длинные последовательности логических нулей или единиц приводят к потере синхронизации. В результирующей последовательности можно отобрать комбинации (всего потребуется 256 комбинаций из 1024), в которых не встречаются длинные последовательности нулей и единиц — это приведет к улучшению самосинхронизирующих свойств кода. Кроме того, не все комбинации считаются разрешенными при передаче — обнаружение запрещенной последовательности при приеме трактуется как наличие ошибки. Таким образом, избыточное кодирование позволяет приемнику распознавать ошибки.
|
|
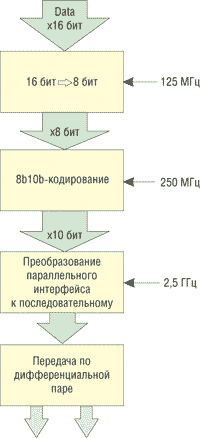
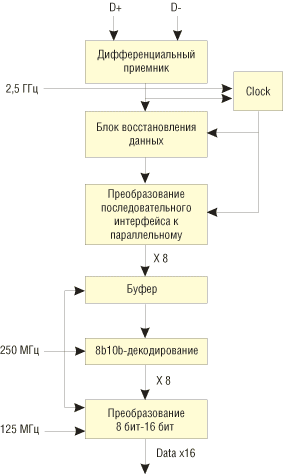
Подуровень физического кодирования связан по 16-битному интерфейсу с верхним уровнем доступа к среде передачи данных (Media Access Level, MAC). Поэтому первоначально полученные по параллельному 16-битному интерфейсу данные разбиваются на группы по 8 бит, то есть частично сериализуются. Частота параллельного 16-битного интерфейса составляет 125 МГц, а после преобразования к 8-битному параллельному интерфейсу частота шины становится уже 250 МГц. После этого данные подвергаются кодированию 8b/10b и уже по 10-битному параллельному интерфейсу поступают на подуровень PMA, где преобразуются к последовательному типу и передаются непосредственно по линии связи, но уже на частоте 2,5 ГГц. |
Преобразование данных на физическом уровне при передаче |
|
|
При приеме данные на физическом уровне претерпевают обратный порядок преобразования, то есть первоначально данные с частотой 2,5 ГГц поступают в дифференциальный приемник, после чего преобразуются к параллельному 10-битному интерфейсу. По этому интерфейсу данные, уже с частотой 250 МГц, подвергаются декодированию 10b/8b и по 8-битному интерфейсу поступают в блок преобразования к параллельному 16-битному типу. По 16-битной шине с частотой 125 МГц данные передаются на верхние уровни. |
|
|
|
|
Преобразование данных на физическом уровне при приеме |
Конечно, такое представление о преобразовании данных является весьма упрощенным. К примеру, мы не рассматривали промежуточные буферы и блоки контроля за возникновением ошибок. Впрочем, даже такой упрощенный подход позволяет понять принцип действия шины PCI Express.
|
|
В случае когда используется не одна линия для передачи данных, то есть при организации многомагистральной шины PCI Express (шины с шириной линий х1, х2, х4, х8, х16 или х32), управлением потока данных занимается специальный агент PCI Express, который распределяет поток данных перед тем, как отправить его по различным физическим линиям, а при приеме аналогичный агент собирает разные потоки данных в один. |
Организация шины PCI Express при наличии нескольких магистральных линий передачи |
|
|

Мы рассмотрели только физический уровень архитектуры PCI Express. Конечно, полное описание архитектуры этим не ограничивается. Кроме физического уровня, есть также уровень представления данных (Data Link Layer), уровень транзакций (Transaction Layer) и программный уровень (Software layer).
|
|
|
|
Обработка данных на различных уровнях в архитектуре PCI Express |
|

Уровень представления данных отвечает за достоверность получаемых данных. На этом уровне каждому пакету присваивается свой порядковый номер и добавляется контрольная сумма CRC. При приеме данных на уровне представления контрольная сумма проверяется и, если пакет данных регистрируется как битый, формируется запрос на повторную передачу пакета.
Уровень транзакций получает запросы на запись или чтение от программного уровня и формирует пакеты запросов на передачу. Некоторые запросы требуют подтверждения, и уровень транзакций также получает ответные пакеты от уровня представления данных.
На уровне транзакций каждый пакет данных снабжается заголовком, в котором содержится уникальный идентификатор пакета, а также степень приоритета пакета.
Всего предусматривается три уровня приоритета: no-snoop, relaxedordering и priority.
Первый уровень приоритета (no-snoop) означает отсутствие всякого приоритета. Пакеты с такой меткой передаются в последнюю очередь.
Второй уровень приоритета (relaxedordering) — это уровень промежуточного приоритета, то есть пакеты с таким уровнем будут обрабатываться во вторую очередь.
Ну и последний уровень приоритета (priority) — это наивысший уровень приоритета. Пакеты с данным уровнем обрабатываются в первую очередь. Такое деление пакетов данных по уровням приоритета позволяет организовать сложные алгоритмы обработки, чтобы потоки данных, требовательные к пропускной способности (например, потоки данных мультимедийных приложений), обрабатывались в первую очередь.
12 Вопрос Интерфейс HyperTransport Принцип передачи информации по дифференциальной линии. Уровни. Характеристики.
Этот
стандарт продвигается на рынок
HyperTransport Technology Consortium, который в настоящий
момент насчитывает около 150 участников,
больших и малых фирм, занимающихся
разработкой программного и аппаратного
обеспечения. Консорциум был организован
в 1997 году с целью развития архитектуры
системной шины компьютера. Большое
число фирм объявили о своем участии в
проекте после того, как один из участников
консорциума, NVIDIA, заявил о поддержке
HyperTransport в своем чипcете nForce. Наиболее
яркие представители являются известными
сторонниками открытой архитектуры.
Кроме
выпуска первых десктопных 64 битных
процессоров, чем АМД конечно годится,(
причем гордится настолько, что решила
отказаться от магических циферок 64 в
названии процессора -мол если написано
Athlon, то и так ясно, что процессор 64 битный)
у компании есть еще один мощный предмет
для гордости.
Шина HyperTransport (HT),
ранее известная как Lightning Data Transport (LDT),
- это двунаправленная последовательно/параллельная
компьютерная шина, с высокой пропускной
способностью и малыми задержками.
Исторически
HyperTransport разрабатывался AMD в качестве
процессорной шины нового поколения
специально для чипов с интегрированным
контроллером памяти (архитектура AMD64).
В многопроцессорных системах на основе
AMD Opteron подсистема памяти “размазана”
по всем процессорам - у каждого есть
своя локальная память, подключенная
через интегрированный контроллер, и
каждый может обращаться к памяти любого
другого процессора. Локальная память
“быстрая”, а память соседа - “медленная”,
причем чем “дальше” расположен сосед,
тем медленнее память. Медлительность
является следствием того, что для
обращения к соседу требуется проделать
целый ряд операций - переслать по
межпроцессорной шине запрос, дождаться
его выполнения контроллером памяти
адресата, вернуть данные по шине обратно.
Очевидно, что чем быстрее при этом шина,
тем более “однородна” память.
Исходя
из этих соображений и проектировалась
новая шина, призванная обеспечить
пропускную способность не меньшую, чем
у оперативной памяти, и минимальные
задержки на передачу данных и сообщений.
Получилось действительно неплохо, что
даже дало AMD повод назвать свою архитектуру
не NUMA, а SUMA - Slightly Uniform Memory Architecture, то есть
“почти однородная” архитектура
памяти.(напомню NUMA -неоднородный доступ
к памяти).
Но разработчики не стали
делать типичную быструю узкоспециализированную
процессорную (системную) шину. Напротив,
в соответствии с веяниями времени они
соорудили очень быструю последовательную
шину данных и предусмотрели возможности
для ее “переноса” в более простые и
медленные варианты с уменьшенными
частотами и разрядностью (в отличие от
PCI Express, которая масштабируется “вверх”
- от x1 к х16 и x32).
Поэтому HT (минимальная
ширина которой - 2 бита) с полным правом
может называться последовательной
шиной - любые данные, передаваемые по
ней, упаковываются в пакеты стандартного
вида. Правда, требования скорости
наложили на протокол передачи данных
сильнейшие ограничения - столь изящной
“layered architecture”, как у Intel, мы здесь не
увидим, да и влияние физической реализации
линков HT на общую архитектуру шины очень
заметно.
^
2. Обзор, характеристики, принцип
работы
HyperTransport
работает на частотах от 200 МГц до 2,6 ГГц
(сравните с шиной PCI и её 33 или 66 МГц).
Кроме того, она использует DDR, что
означает, что данные посылаются как по
переднему, так и по заднему фронтам
сигнала синхронизации, что позволяет
осуществлять до 5200 миллионов посылок
в секунду при частоте сигнала синхронизации
2,6 ГГц; частота сигнала синхронизации
настраивается автоматически.
HyperTransport
поддерживает автоматическое определение
ширины шины, от 2-х битных линий до 32-х
битных линий. Полноразмерная,
полноскоростная, 32-х битная шина в
двунаправленном режиме способна
обеспечить пропускную способность до
41600 МБ/с (2[ddr]*2*(32/8)*2600) (20800 МБ/с - max в одном
направлении), являясь, таким образом,
самой быстрой шиной среди себе подобных.
Шина HyperTransport основана на передаче
пакетов. Каждый пакет состоит из 32
разрядных слов, вне зависимости от
физической ширины шины (количества
информационных линий). Первое слово в
пакете — всегда управляющее слово. Если
пакет содержит адрес, то последние 8 бит
управляющего слова сцеплены со следующим
32-битным словом, в результате образуя
40 битный адрес. Шина поддерживает 64
разрядную адресацию — в этом случае
пакет начинается со специального 32
разрядного управляющего слова,
указывающего на 64 разрядную адресацию,
и содержащего разряды адреса с 40 по 63
(разряды адреса нумеруются начиная с
0). Остальные 32-х битные слова пакета
содержат непосредственно передаваемые
данные. Данные всегда передаются 32-х
битными словами, вне зависимости от их
реальной длины (например, в ответ на
запрос на чтение одного байта по шине
будет передан пакет, содержащий 32 бита
данных и флагом-признаком того, что
значимыми из этих 32 бит являются только
8).
Пакеты HyperTransport передаются по
шине последовательно. Увеличение
пропускной способности влечёт за собой
увеличение ширины шины.
Операция
записи на шине бывает двух видов —
posted
и non-posted.
Posted-операция записи заключается в
передаче единственного пакета, содержащего
адрес, по которому необходимо произвести
запись, и данные. Эта операция обычно
используется для обмена данными с
высокоскоростными устройствами,
например, для DMA передачи. Non-posted операция
записи состоит из посылки двух пакетов:
устройство, инициирующее операцию
записи посылает устройству-адресату
пакет, содержащий адрес и данные.
Устройство-адресат, получив такой пакет,
проводит операцию записи и отсылает
устройству-инициатору пакет, содержащий
информацию о том, успешно ли произведена
запись.
Электрический интерфейс
HyperTransport/LDT — низковольтные дифференциальные
сигналы (Low Voltage Differential Signaling (LVDS)), с
напряжением 2,5 В.
^
3. Основные достоинства
Давайте
попробуем выделить основные
приемущества:
1). HyperTransport, ранее
носившая название, позиционируется как
дополнение к технологии InfiniBand на рынок
телекоммуникационных и встроенных
систем, что налагает свои требования
на спецификацию, реализующую преимущества
обоих направлений. По заявлению
руководства HTTC, технология может быть
с одинаковым успехом использована как
в серверных системах, так и в настольных
и мобильных устройствах. Результатом
этого станет некоторое изменение в
архитектуре компьютера: связь между
контроллерами периферийных устройств
будет обеспечивать шина HyperTransport.
 2).
Технология позволяет производителям
аппаратного обеспечения изменять
количество сигнальных линий, что влечет
за собой изменение количества выводов
на плате, если этого требует реализация,
а также изменение потребляемой мощности,
так как лишние выводы требуют
дополнительного питания. Этот факт
может повлиять на широкое распространение
технологии в мобильных системах. Кроме
того, HyperTransport— это peer-to-peer шина, позволяющая
обмениваться информацией между
периферийными устройствами без
задействования процессора и памяти.
Протокол использует пакетированную
передачу данных; за передачу данных
между устройствами отвечает контроллер
шины. Подключение контроллера в
двухпроцессорной системе показано на
рисунке:
2).
Технология позволяет производителям
аппаратного обеспечения изменять
количество сигнальных линий, что влечет
за собой изменение количества выводов
на плате, если этого требует реализация,
а также изменение потребляемой мощности,
так как лишние выводы требуют
дополнительного питания. Этот факт
может повлиять на широкое распространение
технологии в мобильных системах. Кроме
того, HyperTransport— это peer-to-peer шина, позволяющая
обмениваться информацией между
периферийными устройствами без
задействования процессора и памяти.
Протокол использует пакетированную
передачу данных; за передачу данных
между устройствами отвечает контроллер
шины. Подключение контроллера в
двухпроцессорной системе показано на
рисунке:
 3).
Возможность передачи асимметричных
потоков данных от(к) периферийных(м)
устройств(ам). Симметричная, то есть
одинаковая в обоих направлениях,
пропускная способность не всегда нужна
в компьютере. Примером могут служить
системы, преимущественно отображающие
графическую информацию, или системы,
активно посылающие запросы в сеть для
получения больших объемов информации.
4).
Шина HyperTransport поддерживает технологии
энергосбережения, а именно ACPI. Это
значит, что при изменении состояния
процессора (C-state) на энергосберегающее,
изменяется также и состояние устройств
(D-state). Например, при отключении процессора
НЖМД также отключаются.
5). Высокая
скорость работы (до 12.8 ГБ/с).
4.
Применение. Реализации
^
3).
Возможность передачи асимметричных
потоков данных от(к) периферийных(м)
устройств(ам). Симметричная, то есть
одинаковая в обоих направлениях,
пропускная способность не всегда нужна
в компьютере. Примером могут служить
системы, преимущественно отображающие
графическую информацию, или системы,
активно посылающие запросы в сеть для
получения больших объемов информации.
4).
Шина HyperTransport поддерживает технологии
энергосбережения, а именно ACPI. Это
значит, что при изменении состояния
процессора (C-state) на энергосберегающее,
изменяется также и состояние устройств
(D-state). Например, при отключении процессора
НЖМД также отключаются.
5). Высокая
скорость работы (до 12.8 ГБ/с).
4.
Применение. Реализации
^