

3.3. Управление диаграммами
В SQL Server 2000 имеется средство, облегчающее понимание структуры базы данных, позволяющее наглядно представлять структуру таблиц и связей между ними. Это средство называется диаграммой. Диаграммы определены только на уровне Enterprise Manager и являются надстройкой над объектами базы данных.
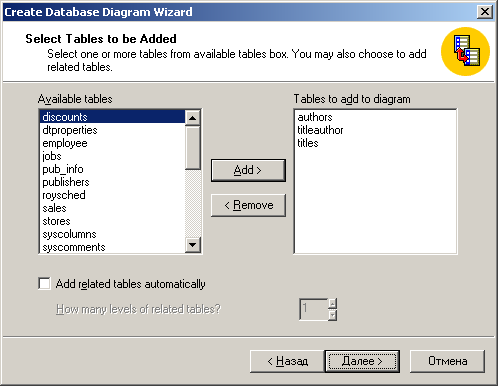
Рисунок 9. Второе окно мастера создания диаграмм.
Для создания диаграммы в контекстном меню папки Diagrams (Диаграмма) требуемой базы данных необходимо выбрать пункт меню New Database Diagrams (Новая диаграмма базы данных). Запустится мастер Create Database Diagram Wizard (Мастер создания диаграммы базы данных). Построение диаграммы при помощи данного мастера состоит из трех шагов.
В первом окне перечислены возможности мастера. Во втором окне мастера необходимо указать таблицы базы данных, которые должны войти в диаграмму (рисунок 9). Установленный флажок Add related tables automatically (Автоматически добавлять связанные таблицы) указывает мастеру на необходимость автоматически добавить в диаграмму все таблицы, которые были включены в диаграмму вручную.
В третьем окне будут представлены таблицы, которые предполагается включить в диаграмму. На этом мастер заканчивает свою работу.
Для просмотра созданных диаграмм необходимо в окне Enterprise Manager выбрать требуемую базу данных и открыть папку Diagram. Диаграмма не имеет свойств, для просмотра диаграммы необходимо дважды щелкнуть на ней левой клавишей мыши. Диаграмма в окне просмотра будет выглядеть в соответствии с рисунком 10.
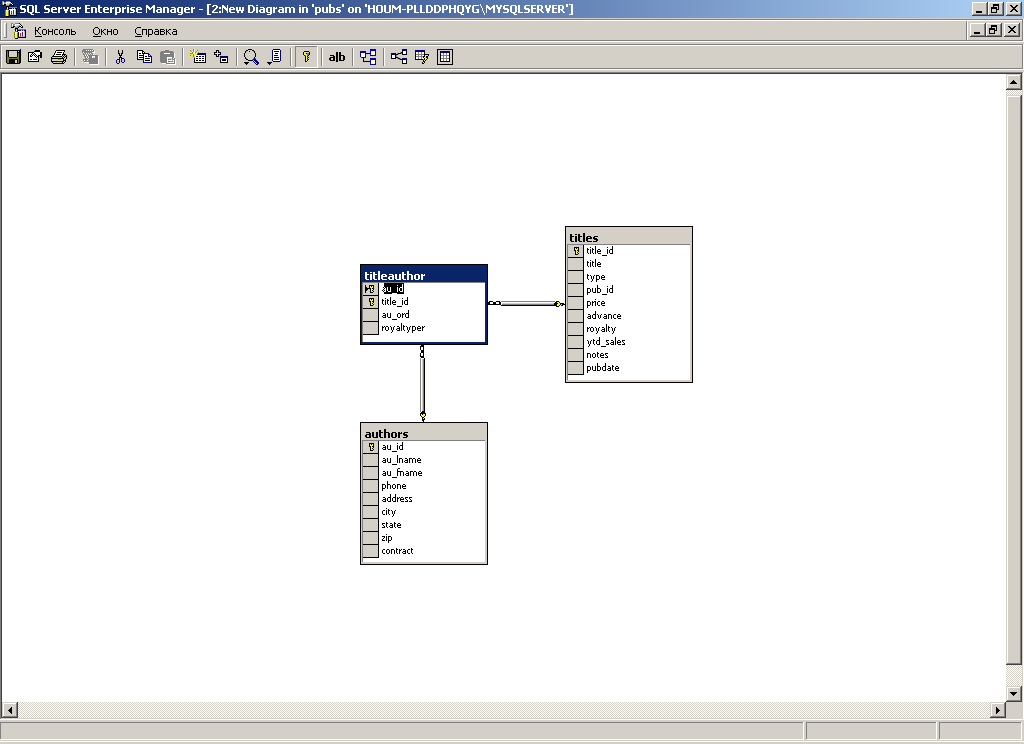
Рисунок 10. Окно просмотра диаграммы.
Каждая таблица может быть представлена в одном из пяти режимов:
Column Properties (Свойства столбцов);
Column Names (Имена столбцов);
Key Columns (Ключевые столбцы);
Table Names (Имена таблиц);
Custom (Пользовательский режим).
Для выбора одного из режимов просмотра можно воспользоваться раскрывающимся списком кнопки Show (Показать) на панели инструментов или контекстным меню таблицы.
В режиме просмотра Column Properties (Свойства столбцов) можно выполнять редактирование структуры таблицы. В окне свойств таблицы можно редактировать отношения, ограничения целостности, индексы и ключи.
Для каждой таблицы в диаграмме можно выполнить редактирование триггеров. Не выходя из диаграммы можно управлять разрешением на доступ к таблицам для объектов.
4. Создание и управление индексами средствами Enterprise manager
Современные базы данных часто содержат миллионы строк. По умолчанию данные хранятся в порядке их добавления в таблицу, т.е. неупорядоченно. Чтобы найти нужные данные, сервер должен перебрать все строки таблицы. Такой перебор называется сканированием таблицы. Подобное сканирование может потребовать довольно много времени. К тому же, если оно выполняется часто и многими пользователями, то ситуация еще более усугубляется. Кроме того, сюда следует добавить необходимость установки блокировок – и полное сканирование данных вообще становится неприемлемым при создании корпоративных баз данных с миллионами строк и сотнями пользователей, работающих одновременно.
Повышение производительности достигается за счет того, что данные представляются в упорядоченном виде. Механизмом, увеличивающим скорость поиска данных и обеспечивающим минимальные затраты времени на анализ таблиц, является индексирование. Индексы представляют собой набор ссылок на места физического размещения строк в структуре базы данных, упорядоченный по возрастанию или убыванию. При этом данные в самой таблице могут быть и неупорядоченными. Столбец, по которому была произведена индексация, называется индексированным. Необходимо отметить, что индекс представляет собой не сами строки данных, а лишь значения индексированного столбца и указатели на соответствующие строки. В таблице может быть создано более десяти столбцов, но индексированными будут всего один или два столбца. Обычно индекс хранится отдельно от самих данных, подобно тому, как предметный указатель в книге хранится отдельно от текста глав. Каждый элемент предметного указателя содержит ключевое слово и номер страницы, на которой расположена нужная информация. По такому же принципу устроен и индекс базы данных. Каждый элемент индекса хранит значение, соответствующее значению индексированного столбца конкретной строки, а также ссылку на исходную строку. Однако стоит обратить внимание, что индекс производит упорядочивание только конкретного столбца, а не всех данных таблицы.
Практически все алгоритмы ускорения поиска данных работают только с упорядоченными данными. Индексы позволяют упорядочить данные, даже если физически данные сохранены без всякого порядка. В большинстве систем управления данными индексы применяются автоматически.
SQL Server 2000 не является исключением. Если в ходе выполнения запроса происходит обращение к столбцу, для которого был определен индекс, то сервер автоматически производит поиск нужных значений непосредственно не в таблице, а в индексе. Когда в индексе находится искомое значение, сервер обращается к соответствующей строке таблицы и выбирает нужные данные уже из нее. Хотя на самом деле данные в столбце могут быть и неупорядочены, за счет того, что столбец будет иметь индекс, можно реализовать эффективные алгоритмы поиска информации. Это как раз и сделано в SQL Server 2000.
Одним из наиболее эффективных методов поиска, реализованных и в SQL Server 2000, является метод “деления пополам”, работающий с упорядоченным представлением данных, т.е. с индексами. При поиске конкретного значения в отсортированном по возрастанию наборе в простейшем случае берется значение из середины упорядоченной последовательности и сравнивается с искомым. Если искомое значение больше, то все значения левее выбранного отбрасываются. Тем самым промежуток поиска уменьшается вдвое. Искомое значение сравнивается со значением, расположенным в центре правой области данных. Если значения опять не совпали, то интервал снова уменьшается вдвое и процесс продолжается. Когда значения, наконец, совпадут, поиск прекращается. Этот метод позволяет очень быстро находить требуемые значения.
Метод деления пополам можно оптимизировать, если при выборе начальной точки выбирать не просто середину интервала, а применять специальные алгоритмы, использующие статистические методы обработки информации и позволяющие с большей вероятностью предсказать положение нужных данных в последовательности. Если, к примеру, вам нужно найти телефон человека с фамилией Бардин, то вряд ли вы будете открывать телефонный справочник в середине, а тем более в конце.
В идеале можно создать индексы для всех столбцов таблицы, но здесь есть одно существенное ограничение. Когда выполняется изменение строк таблицы, то помимо обновления самих данных необходимо выполнить обновление всех индексов. Обновление индексов требует практически столько же времени, сколько и обновление данных, поэтому на практике ограничиваются 4 или 5 индексами. Таким образом, основным преимуществом использования индексов является значительное ускорение выборки данных, а основным недостатком – замедление процесса обновление данных.
При определении столбца для индекса следует выбирать ключевые столбцы, которые задают критерии выборки данных, например, порядок сортировки. Не следует использовать столбцы с очень длинными данными. В крайнем случае, следует создавать укороченные варианты таких столбцов и использовать их для индексирования.
В MS SQL Server 2000 реализованы следующие типы индексов:
кластерные индексы;
не кластерные индексы;
уникальные индексы.
Не кластерные индексы являются наиболее типичными индексами. В отличии от кластерных, они не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки (указатели – row locator), которые включают в себя:
информацию об идентификационном номере файла (ID_file), в котором храниться строка;
идентификационный номер страницы данных;
номер соответствующей строки на странице;
содержимое столбца.
При определении кластерного индекса физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет скорее словарь, чем индекс. Естественно, в таблице может быть определен только один кластерный индекс. Он может включать несколько столбцов, которые наиболее часто используются при поиске. Однако количество таких столбцов следует по возможности свести к минимуму. Желательно, чтобы столбцы кластерного индекса не слишком часто изменялись, так как из-за этого будут часто физически переупорядочиваться строки таблицы.
При создании в таблице первичного ключа с помощью ключевых слов PRIMARI KEY сервер автоматически для него кластерный индекс, если он не был создан ранее или если при определении ключа не был явно указан не кластерный индекс (NONCLUSTERED). Если в таблице определяются другие индексы, то их указатели ссылаются не на физическое положение строки, а на соответствующий элемент кластерного индекса.
Уникальные индексы гарантируют уникальность значений в индексируемом столбце. Он является надстройкой для таблицы и может быть реализован как для кластерного, так и для не кластерного индекса. Уникальные индексы используются редко, а для обеспечения целостности данных следует использовать ограничения UNIQVE или PRIMARI KEY.
При определении индекса надо задавать параметр, который будет устанавливать плотность записи данных на странице - фактор заполнения (fill factor). Его значение определяет, какой процент доступного пространства индексных страниц будет заполнен данными при создании индекса, а какой процент будет заполняться постепенно по мере загрузки данных в таблицу. Если таблица используется только для чтения, то значение этого параметра надо задавать близким к 100%, если таблица часто обновляется и дополняться, то значение фактора дополнение должно быть задано небольшим.
Право на создание индекса имеет только владелец таблицы, и это право не может быть передано другому пользователю. Индекс можно создать одним из следующих способов:
с помощью команд языка Transact – SQL, которые предоставляют пользователю максимум возможностей;
с помощью Enterprise Manager;
средствами мастеров Create Index Wizard и Index Tuning Wizard.
Чтобы создать индекс с помощью Enterprise Manager, необходимо сначала открыть окно редактирования структуры таблицы (рисунок 8). Для этого для требуемой таблицы в контекстном меню выбирается пункт Design Table (Макет таблицы).
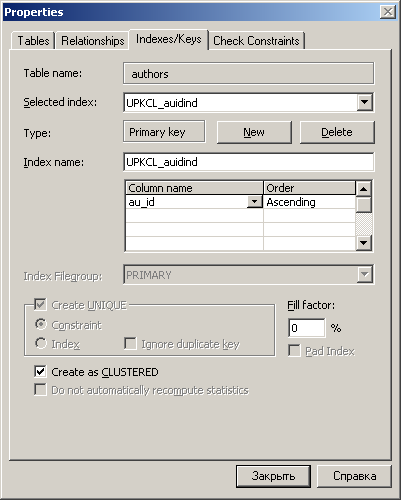
Рисунок 11. Вкладка Indexes/Keys окна свойств таблицы.
Для создания нового или просмотра существующих индексов на панели инструментов необходимо нажать кнопку Table and Index Properties (Свойства таблицы и индекса). При этом откроется диалоговое окно Properties (Свойства), с помощью которого можно управлять различными свойствами таблицы (рисунок 11). Окно свойств таблицы имеет четыре вкладки. Для создания и управления индексами используется вкладка Manage Indexes/Keys (Индексы и ключи).
В раскрывающемся списке Selected Index (Выбранный индекс) один из ранее созданных индексов. Для удаления индекса достаточно нажать кнопку Delete (Удалить).
Если же необходимо создать новый индекс, то следует нажать на кнопке New (Создать). В этом случае в список Selected Index (Выбранный индекс) будет автоматически добавлена новая строка, а индексу присвоено имя по умолчанию, например IX_authors. Далее потребуется указать столбцы, которые будут включены в индекс, выбрать группу файлов для сохранения индекса, определить фактор заполнения, тип индекса (по умолчанию - некластерный), метод упорядочивания и некоторые другие.
Статистика представляет собой данные о распределении в таблице упорядоченных с помощью индекса данных. Информация об индексах хранится в системной таблице sysindexes, имеющейся в каждой базе данных. Каждый индекс представлен отдельной строкой. Информация о статистике индекса хранится в столбце statblob, имеющем тип данных image, максимальный размер которого равен 2 Гбайт.
Логически статистика представлена в виде интервалов, охватывающих весь диапазон значений индексированного столбца. Для каждого интервала указывается степень насыщенности, что позволяет судить о местоположении искомого элемента. Оптимизатор запросов использует статистику для построения наиболее эффективного плана исполнения запроса. Однако статистика должна отображать реальную ситуацию. Если она содержит неверную информацию, то оптимизатор не сможет построить правильный план исполнения запроса.
Чтобы поддерживать статистику в “рабочем” состоянии, сервер периодически выполняет автоматическое сканирование индексированных столбцов. Конечно, подобное обновление требует определенных затрат процессорного времени и несколько снижает производительность операций вставки и изменения данных. При необходимости можно запретить обновление статистики и тем самым повысить производительность вставки и изменения данных. Однако скорость выполнения выборки данных может снизиться.
Для каждого индекса сервер автоматически создает статистику. В SQL Server 2000 разрешено создание статистики и для неиндексированных столбцов. Для создания статистики используется команда CREATE STATISTICS языка Transact-SQL, а также хранимые процедуры sp_createstats, sp_dboption.
Для обновления статистики используется команда UPDATE STATISTICS, а также хранимая процедура sp_updatestats.