

6.6.Корреляционные нс
Другой важный класс НС с СО составляют сети, при обучении которых используется информация о зависимостях между входными сигналами, так называемые Хеббовские или корреляционные НС. Эти сети линейны по своей природе, хотя алгоритмы обучения имеют нелинейный характер. Применение основного правила Хебба основано на модели линейного нейрона, для которого выходной сигнал
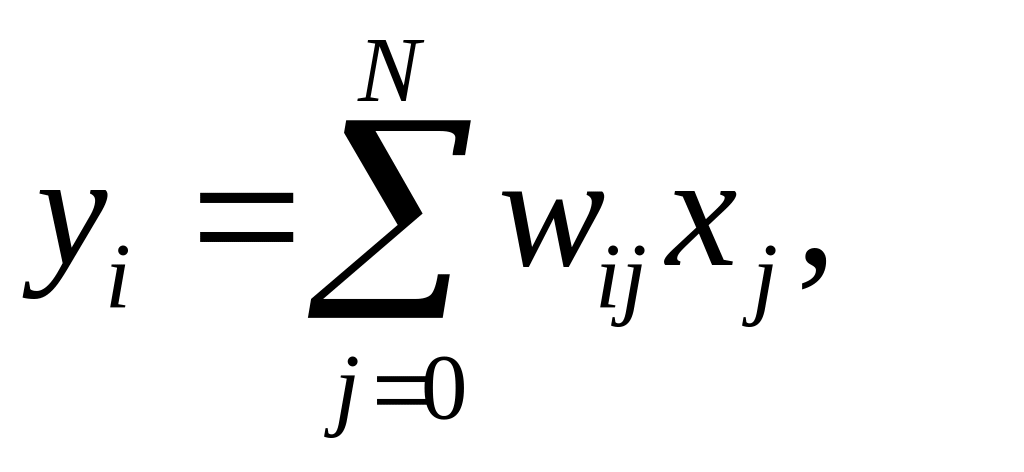 где
где
![]() (6.19)
(6.19)
В соответствии с постулатом Хебба изменение веса после предъявления производится по формуле
![]() (6.20)
(6.20)
где
![]() – константы. Если считать, что изменения
весов производятся в направлении
минимального уменьшения энергетической
функции Е
сети, для Р
обучающих выборок можно получить
– константы. Если считать, что изменения
весов производятся в направлении
минимального уменьшения энергетической
функции Е
сети, для Р
обучающих выборок можно получить
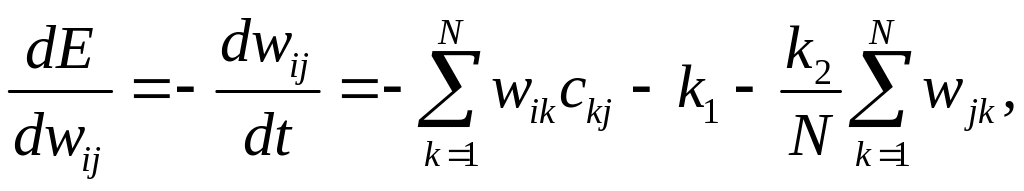 (6.21)
(6.21)
где k1,
k2
– константы, связанные с
;
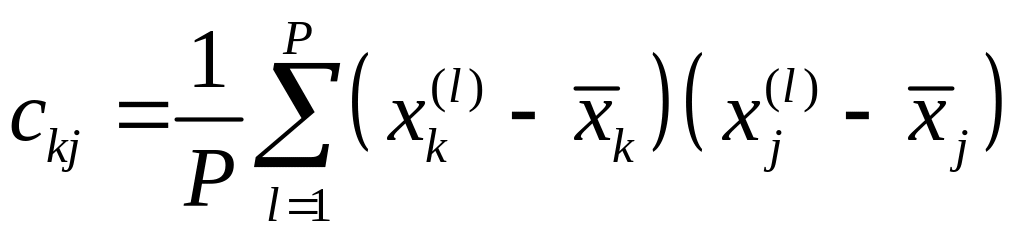 – усредненная ковариация активности
k–го
и j–го
нейронов;
– усредненная ковариация активности
k–го
и j–го
нейронов;
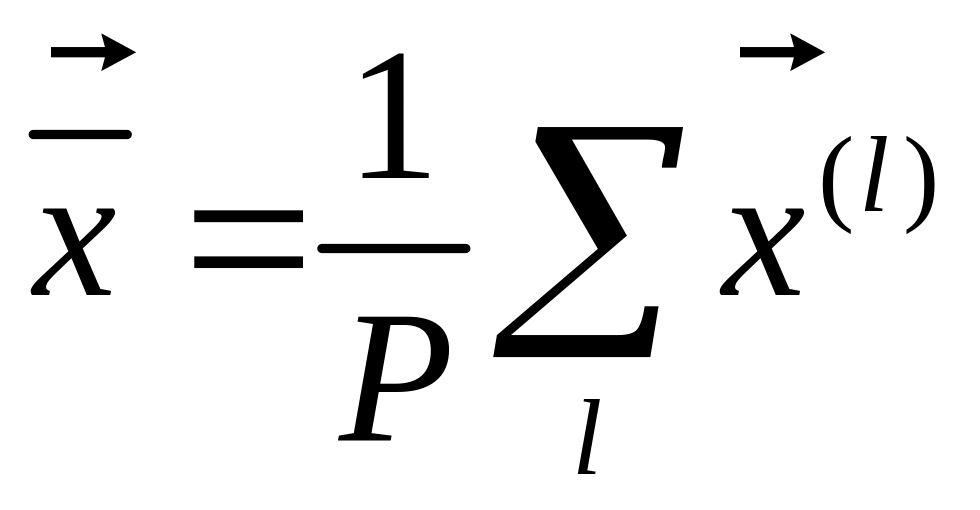 – усредненный вектор обучающих выборок.
– усредненный вектор обучающих выборок.
Решение дифференциального уравнения (6.21) позволяет представить энергетическую функцию в виде
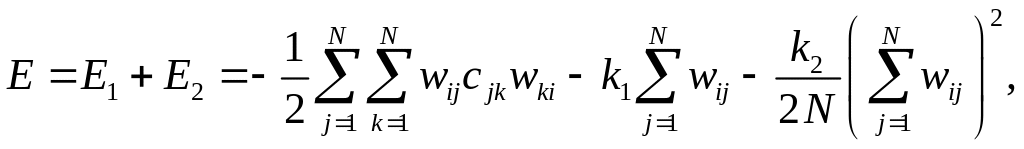 (6.22)
(6.22)
где слагаемое
![]() определяет вариацию
определяет вариацию
![]() активности i–го
нейрона, Е2
– стоимостную или целевую функцию. При
фиксированных значениях весов функция
Е
будет минимальна при максимуме
,
т.е. обучение по Хеббу приводит к
максимизации вариации активности
нейронов при ограничении значений их
весов.
активности i–го
нейрона, Е2
– стоимостную или целевую функцию. При
фиксированных значениях весов функция
Е
будет минимальна при максимуме
,
т.е. обучение по Хеббу приводит к
максимизации вариации активности
нейронов при ограничении значений их
весов.
6.6.1.Нейронные сети рса
Нейронные
сети РСА (Principal
Component
Analysis)
предназначены для анализа и выделения
независимых главных компонентов,
сохраняющих наиболее важную информацию,
из множества взаимно коррелирующих
входных данных, иными словами, они
трансформируют входной вектор
![]() в выходной
в выходной
![]() посредством матрицы
посредством матрицы
![]() при K<N
таким образом, что выходное пространство
меньшей размерности содержит все
наиболее важные данные об исходном
процессе. Обычные методы реализации
такой формы компрессии данных
(преобразования Карьюнена–Лёве) требуют
создания и определения собственных
значений матрицы автокорреляции
при K<N
таким образом, что выходное пространство
меньшей размерности содержит все
наиболее важные данные об исходном
процессе. Обычные методы реализации
такой формы компрессии данных
(преобразования Карьюнена–Лёве) требуют
создания и определения собственных
значений матрицы автокорреляции
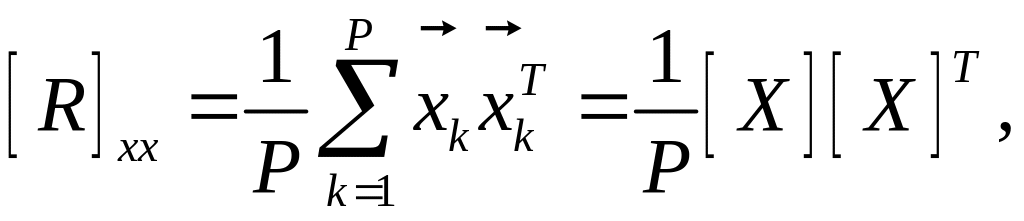 (6.23)
(6.23)
где
– случайный вектор с нулевым средним
значением, [X]
– матрица последовательности обучающих
векторов
![]() ,
P
– количество обучающих выборок.
Собственные значения i
и собственные векторы
матрицы [R]хх
связаны зависимостью
,
P
– количество обучающих выборок.
Собственные значения i
и собственные векторы
матрицы [R]хх
связаны зависимостью
![]() (6.24)
(6.24)
что позволяет определить преобразование РСА как линейное
![]() (6.25)
(6.25)
где
![]() – матрица преобразования, в которой
оставлены К
собственных векторов с максимальными
собственными значениями 1>2>…>K.
– матрица преобразования, в которой
оставлены К
собственных векторов с максимальными
собственными значениями 1>2>…>K.
Стандартные
методы определения собственных векторов
матрицы [R]хх
при больших
размерностях
требуют значительных вычислительных
затрат, поэтому на практике более
эффективны адаптивные методы, основанные
на обобщенном правиле Хебба и
непосредственно преобразующие
![]() без явного определения [R]хх,
тем более что при поступлении данных в
режиме «online»
создание явной формы матрицы [R]хх,
просто невозможно. Здесь основную роль
играют хеббовские однослойные ИНС с
линейными функциями активации (рис.
6.8), где количество выделяемых главных
компонентов определяется числом нейронов
К.
В случае определения первого главного
компонента (К=1)
выходной сигнал
без явного определения [R]хх,
тем более что при поступлении данных в
режиме «online»
создание явной формы матрицы [R]хх,
просто невозможно. Здесь основную роль
играют хеббовские однослойные ИНС с
линейными функциями активации (рис.
6.8), где количество выделяемых главных
компонентов определяется числом нейронов
К.
В случае определения первого главного
компонента (К=1)
выходной сигнал
 (6.26)
(6.26)
где веса
![]() подбираются согласно нормализованному
правилу Хебба–Ойя, которое в векторном
виде может быть записано как
подбираются согласно нормализованному
правилу Хебба–Ойя, которое в векторном
виде может быть записано как
![]() (6.27)
(6.27)
причем для хорошей
сходимости алгоритма коэффициент
обучения
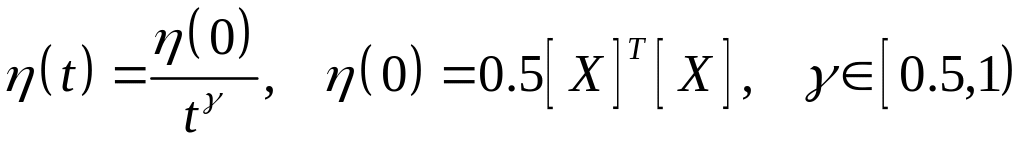 .
В процессе обучения одни и те же обучающие
данные предъявляются многократно вплоть
до стабилизации весов сети.
.
В процессе обучения одни и те же обучающие
данные предъявляются многократно вплоть
до стабилизации весов сети.

В общем случае К линейных нейронов выходного слоя генерируют выходные сигналы согласно
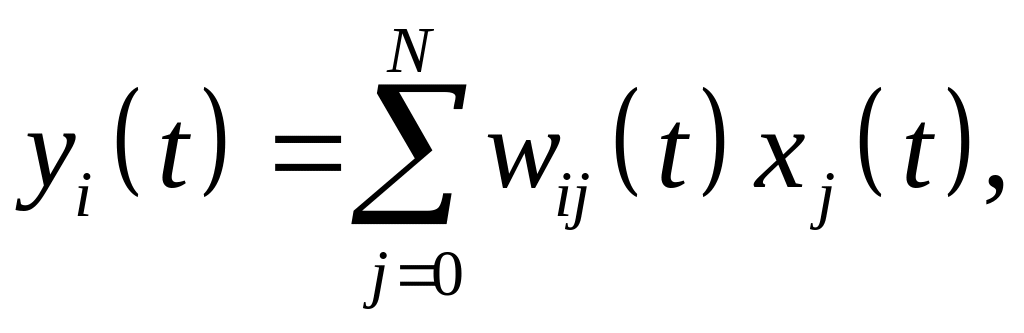 (6.28)
(6.28)
а уточнение весов производится по формуле
![]() (6.29)
(6.29)
где
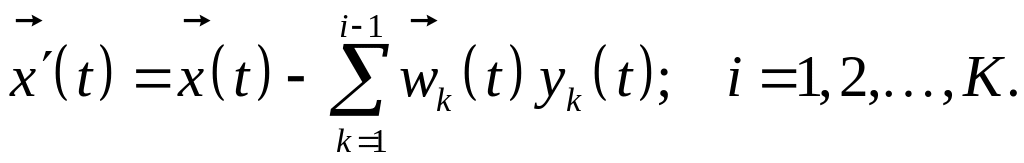 (6.30)
(6.30)
Рассмотренные
правила имеют локальный характер,
поскольку уточнение весов одного нейрона
не требует решения уравнений, описывающих
всю сеть. Заметим, что для первого нейрона
(первого главного компонента
![]() ,
для второго –
,
для второго –
![]() ,
для третьего –
,
для третьего –
![]() и т.д., т.е. для определения весов i–го
нейрона используются уже известные
веса 1–го, 2–го, …, (i-1)–го.
и т.д., т.е. для определения весов i–го
нейрона используются уже известные
веса 1–го, 2–го, …, (i-1)–го.
НС РСА чаще всего применяются для компрессии данных, при которой большое количество входной информации заменяется их частью, содержащейся в векторах и . В зависимости от степени сжатия (количества главных компонентов РСА) можно получить различное качество восстановления данных, которое производится в соответствие с формулой
![]() (6.31)
(6.31)
где
![]() матрица
реконструкции, транспонированная по
отношению к матрице разложения
матрица
реконструкции, транспонированная по
отношению к матрице разложения
![]() .
Компьютерные эксперименты по сжатию –
восстановлению телевизионных изображений
показывают, что использование 3…5 главных
компонентов обеспечивает качественное
восстановление оригинала при коэффициентах
компрессии порядка 10…20.
.
Компьютерные эксперименты по сжатию –
восстановлению телевизионных изображений
показывают, что использование 3…5 главных
компонентов обеспечивает качественное
восстановление оригинала при коэффициентах
компрессии порядка 10…20.
6.6.2.ICA–НС Херольта–Джуттена
Концепция НС ICA (Independent Component Analysis) была сформулирована в середине 80х годов 20 века для так называемой слепой сепарации сигналов. Первичная структура НС была рекуррентной, в настоящее время часто используются однонаправленные сети. Независимо от способа соединения нейронов эти сети обычно имеют адаптивную линейную структуру, обрабатывающую сигналы в режиме реального времени. При этом нелинейные функции, применяемые в алгоритмах обучения весов, не оказывают влияния на саму структуру взвешенных связей.
Оригинальное решение Херольта–Джуттена касалось задачи разделения независимых сигналов si(t) на основе информации, содержащейся в их линейной суперпозиции
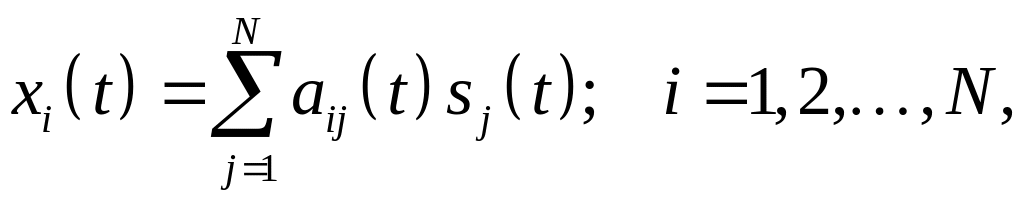 (6.32)
(6.32)
где aij – компоненты смешивающей матрицы
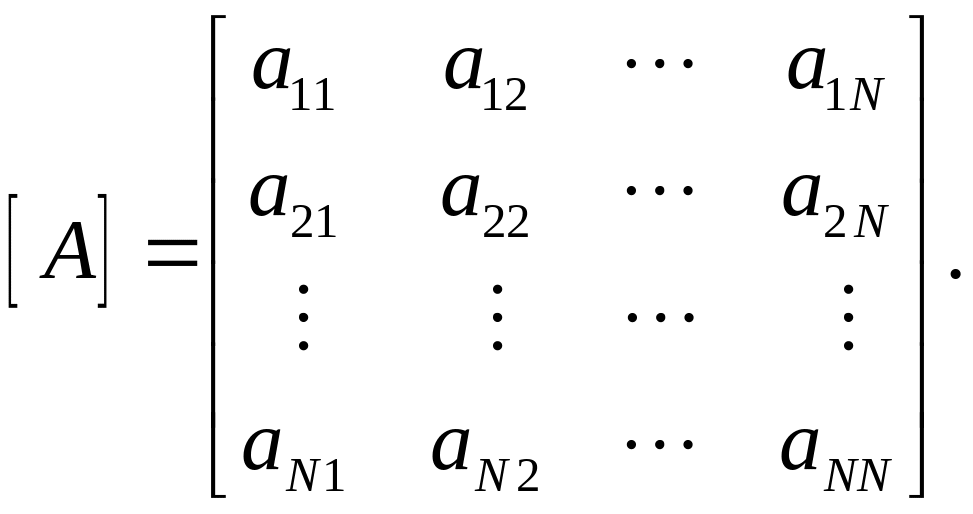 (6.33)
(6.33)
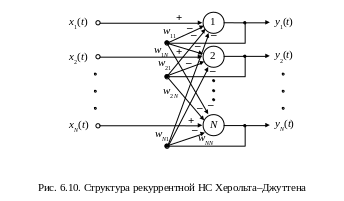
Основная трудность задачи состояла в том, что как aij, так и si(t) были неизвестны, но на основании гипотезы о статистической независимости si(t) Дж. Херольт и К. Джуттен предложили ее решение согласно измерительной схеме рис. 6.9, где в качестве разделяющей НС использовалась рекуррентная структура типа НС Хопфилда из N линейных нейронов (рис. 6.10), в которой собственные ОС отсутствуют.
Выходные сигналы НС рис. 6.10 определяются выражением
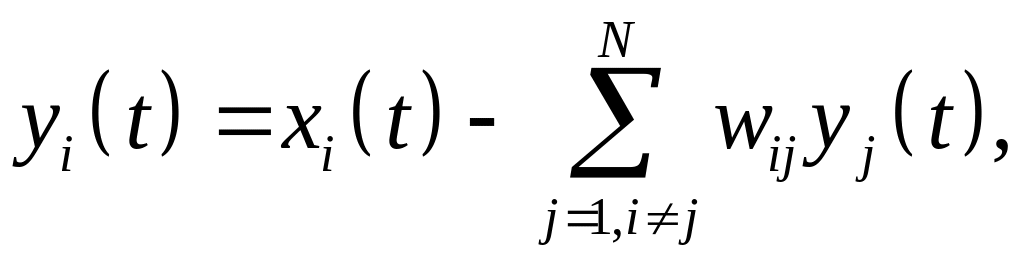 (6.34)
(6.34)
где диагональные элементы матрицы весов равны нулю. Из (6.34) следует, что функционирование измерительной схемы рис. 6.9 можно описать матричными уравнениями:
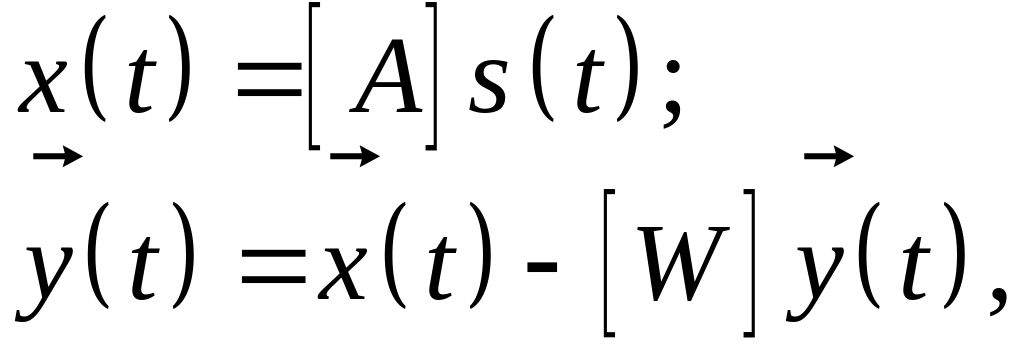 (6.35)
(6.35)
согласно которым при статистической независимости si(t) задача НС состоит в определении такого выхода
![]() (6.36)
(6.36)
который позволит с некоторой степенью точности di восстановить исходные сигналы si(t) в соответствии с
![]() (6.37)
(6.37)
где [D] – диагональная матрица; dii=di, i=1,2,…,N.
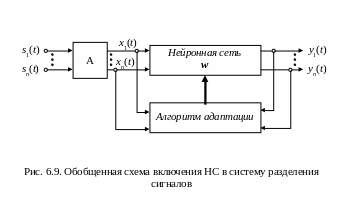
Если количество источников si(t) больше двух, а значения aij заранее неизвестны, то сигналы можно разделить только с помощью адаптивного алгоритма подбора wij сети. Для рекуррентной НС рис. 6.10 Дж. Херольт и К. Джуттен представили такой алгоритм в виде системы дифференциальных уравнений, которая в обобщенной матричной форме выглядит как
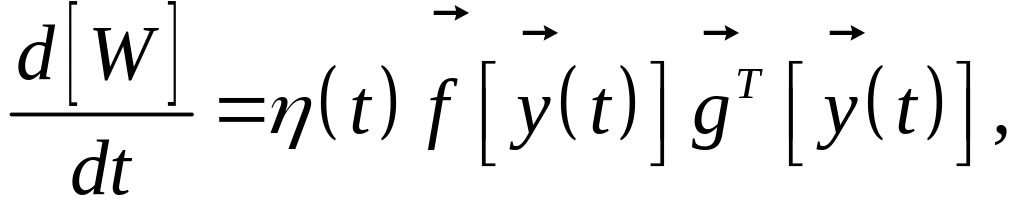 (6.38)
(6.38)
где
![]() ;
(t)
– уменьшающийся по показательному
закону коэффициент обучения. Зависимость
(6.38) представляет собой нелинейное
обобщение простого правила обучения
Хебба (2.17). Функции f(y)
и g(y)
нечетны и не равны между собой, чаще
всего одна из них имеет выпуклую, а
другая – вогнутую форму. В практических
приложениях наиболее популярны f(x)=x3
или f(x)=x5,
g(x)=th x,
x,
arctg x,
sign
x.
;
(t)
– уменьшающийся по показательному
закону коэффициент обучения. Зависимость
(6.38) представляет собой нелинейное
обобщение простого правила обучения
Хебба (2.17). Функции f(y)
и g(y)
нечетны и не равны между собой, чаще
всего одна из них имеет выпуклую, а
другая – вогнутую форму. В практических
приложениях наиболее популярны f(x)=x3
или f(x)=x5,
g(x)=th x,
x,
arctg x,
sign
x.
Следует отметить, что адаптивная зависимость (6.38) относится только к переменным компонентам сигналов, при наличии постоянной составляющей ее следует отфильтровать с помощью ФВЧ 1го или 2го порядка. Компьютерное моделирование НС Херольта–Джуттена, как и ее практическая реализация, подтвердили возможность разделения многих статистически независимых сигналов различной структуры, единственным ограничением являлось соотношение амплитуд отдельных компонентов сигналов si(t), обычно меньшее, чем 1:100. При более сильном отличии амплитуд si(t) эффективнее работает алгоритм Сичоки, в котором вводятся собственные ОС нейронов с wii0, адаптивный механизм уточнения весов описывается формулой
 (6.39)
(6.39)
которая использует
те же обозначения, что и (6.38), а
![]() в каждый момент времени рассчитывается
согласно (6.36). Главный источник высокой
эффективности алгоритма (6.39) –
самонормализация выходных значений
yi(t),
поскольку в стабилизированном состоянии
в каждый момент времени рассчитывается
согласно (6.36). Главный источник высокой
эффективности алгоритма (6.39) –
самонормализация выходных значений
yi(t),
поскольку в стабилизированном состоянии
![]() ,
следовательно, <fi(t)gi(t)>=1,
т.е. независимо от уровней si(t)
в НС происходит масштабирование всех
сигналов до единичного уровня. Имитационный
анализ НС с алгоритмом (6.39) показал
возможность разделения сигналов с
амплитудами, различающимися до 1010
раз.
,
следовательно, <fi(t)gi(t)>=1,
т.е. независимо от уровней si(t)
в НС происходит масштабирование всех
сигналов до единичного уровня. Имитационный
анализ НС с алгоритмом (6.39) показал
возможность разделения сигналов с
амплитудами, различающимися до 1010
раз.
Серьезным
недостатком рекуррентной НС
Херольта–Джуттена является сложность
обеспечения стабильности функционирования
сети, особенно когда матрица [A]
плохо обусловлена, а исходные сигналы
сильно отличаются по амплитуде. Кроме
того, в рекуррентной НС на каждом шаге
необходимо инвертировать матрицу [W]
(выражение (6.36)), что значительно
увеличивает вычислительные затраты
алгоритма. Устранить эти проблемы
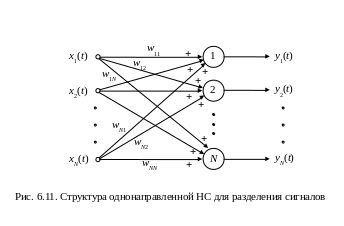
позволяет применение однонаправленной
НС (рис. 6.11) с выходным сигналом
![]() ,
где матрица [W]
является полной. Очевидно, что при
,
где матрица [W]
является полной. Очевидно, что при
![]() ,
где
,
где
![]() – матрица весов рекуррентной НС,
рассматриваемые сети будут равнозначны.
Элементарным преобразованием нетрудно
получить
– матрица весов рекуррентной НС,
рассматриваемые сети будут равнозначны.
Элементарным преобразованием нетрудно
получить
![]() ,
откуда следует
,
откуда следует
![]() .
Поскольку
.
Поскольку
![]() ,
,
то
![]() ,
и, соответственно, для любого правила
обучения рекуррентной НС можно получить
его аналог для однонаправленной сети.
,
и, соответственно, для любого правила
обучения рекуррентной НС можно получить
его аналог для однонаправленной сети.
Например, для модифицированного правила Сичоки (6.39) будем иметь
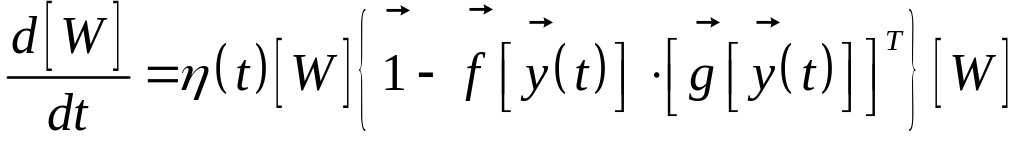 (6.40)
(6.40)
с начальным условием
![]() .
В отличие от формулы обучения рекуррентной
сети, в выражении (6.40) изменения весов
определяются их фактическими значениями.
К настоящему времени известно немало
вариантов обучающей формулы (6.40) для
однонаправленных НС, особенно эффективных
при плохой обусловленности матрицы
смешивания [A]
и/или большой разнице амплитуд исходных
сигналов si(t).
Среди них можно выделить:
.
В отличие от формулы обучения рекуррентной
сети, в выражении (6.40) изменения весов
определяются их фактическими значениями.
К настоящему времени известно немало
вариантов обучающей формулы (6.40) для
однонаправленных НС, особенно эффективных
при плохой обусловленности матрицы
смешивания [A]
и/или большой разнице амплитуд исходных
сигналов si(t).
Среди них можно выделить:
алгоритм Сичоки–Амари–Янга
![]() (6.41)
(6.41)
алгоритм, основанный на естественном градиенте,
![]() (6.42)
(6.42)
алгоритм Кардосо
![]() (6.43)
(6.43)
где так же как и в
рекуррентных НС, коэффициент обучения
(t)
обычно представляется функцией вида
![]() с постоянными 0
и ,
индивидуально подбираемыми в каждом
конкретном случае. Особенно хорошими
качествами обладает алгоритм (6.42), для
которого процесс сепарации практически
не зависит от соотношения амплитуд
si(t)
и степени обусловленности смешивающей
матрицы [A].
с постоянными 0
и ,
индивидуально подбираемыми в каждом
конкретном случае. Особенно хорошими
качествами обладает алгоритм (6.42), для
которого процесс сепарации практически
не зависит от соотношения амплитуд
si(t)
и степени обусловленности смешивающей
матрицы [A].
Компьютерное моделирование однонаправленной ICA–НС (рис. 6.11) проводилось с помощью пакета расширения ICALAB3 среды MATLAB 7.1 на примере разделения смесей 4–х типичных биологических сигналов S1, S2, S3, S4 (рис. 6.12), полученных с помощью смешивающей матрицы
 ,
,
результатом действия которой оказались сигналы х1, х2, х3, х4, показанные на рис. 6.13. Выбор конкретного алгоритма адаптации весов был обусловлен требованием неинвертированности выходных сигналов НС относительно сигналов источников, чему удовлетворял алгоритм SOBI (Second Order Blind Identification Algorithm), аналогичный (6.41). Форма восстановленных сетью сигналов источников y1, y2, y3, y4 приведена на рис. 6.14. Спектральный анализ искажений, внесенных НС при восстановлении Si (рис. 6.15), свидетельствует о правильности и высокой точности работы сети.
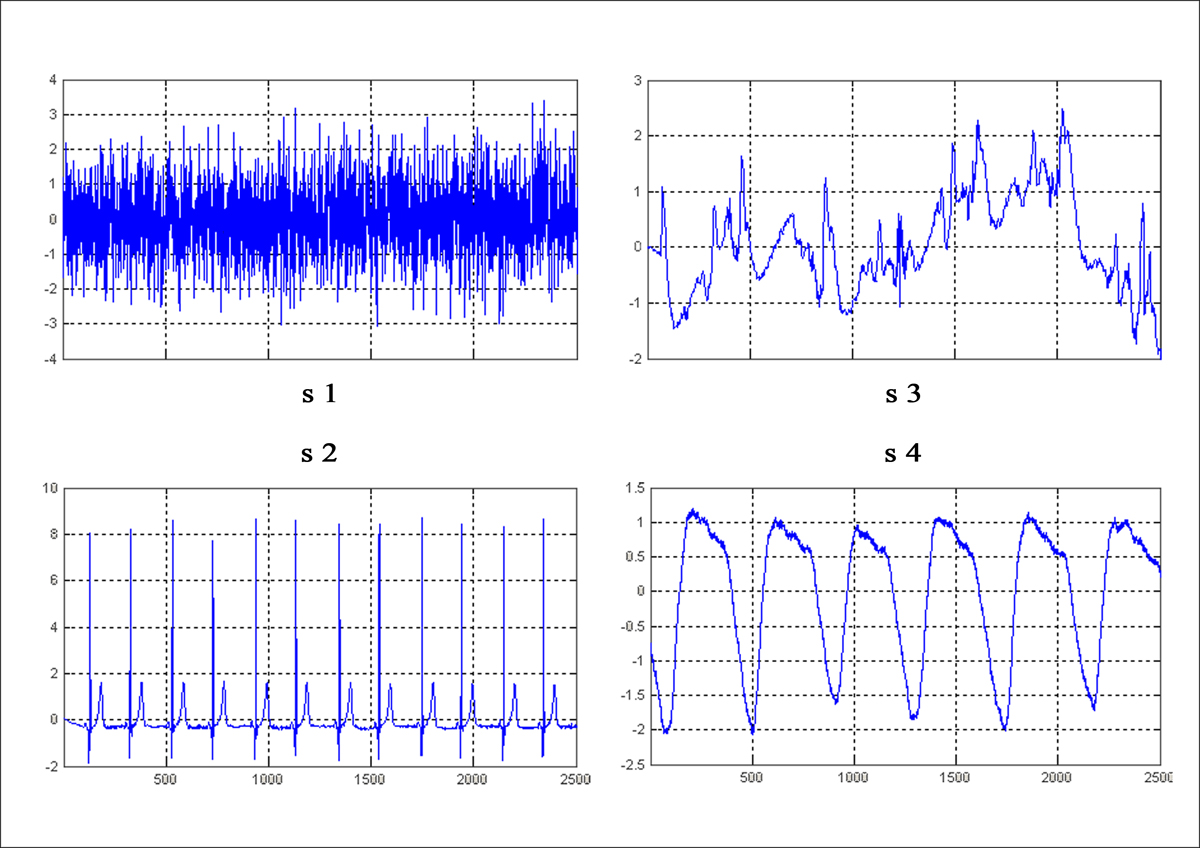
Рис. 6.12. Исходные сигналы источников
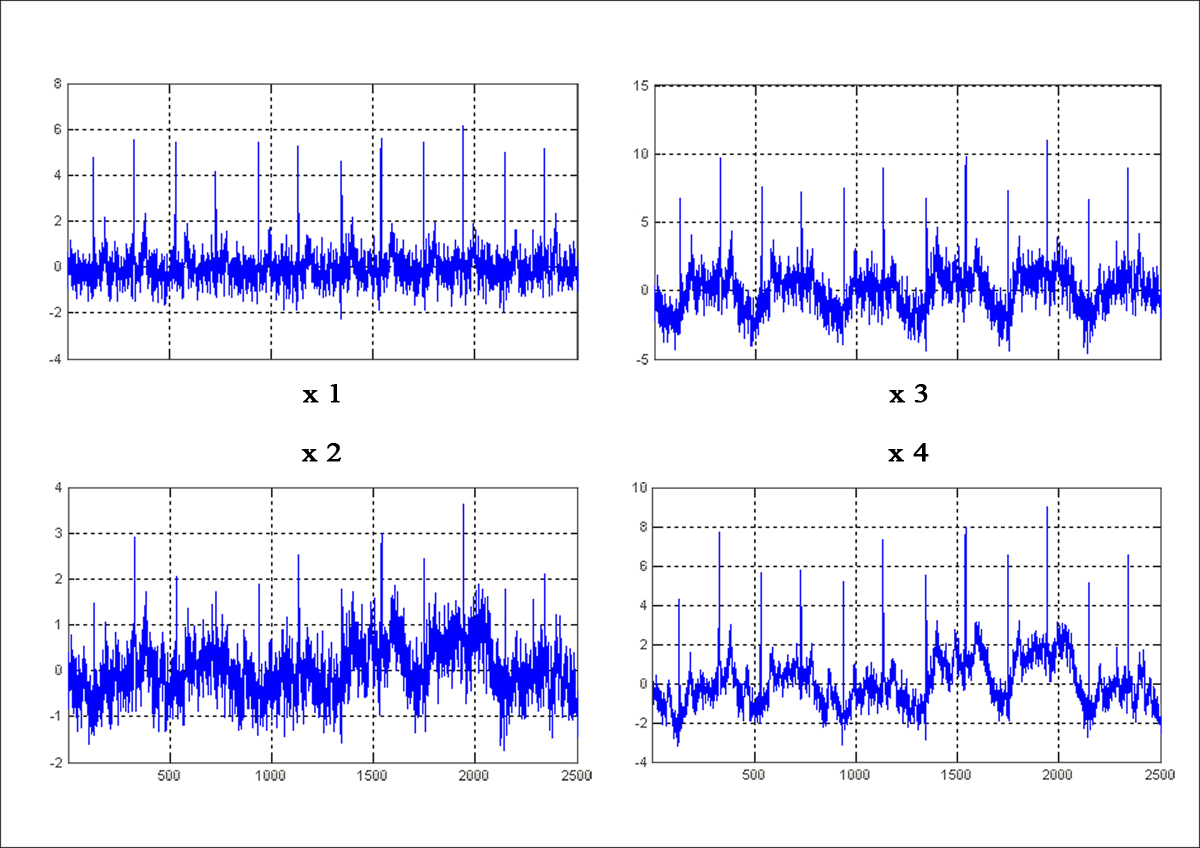
Рис. 6.13. Смесь сигналов

Рис. 6.14. Форма восстановленных сетью сигналов
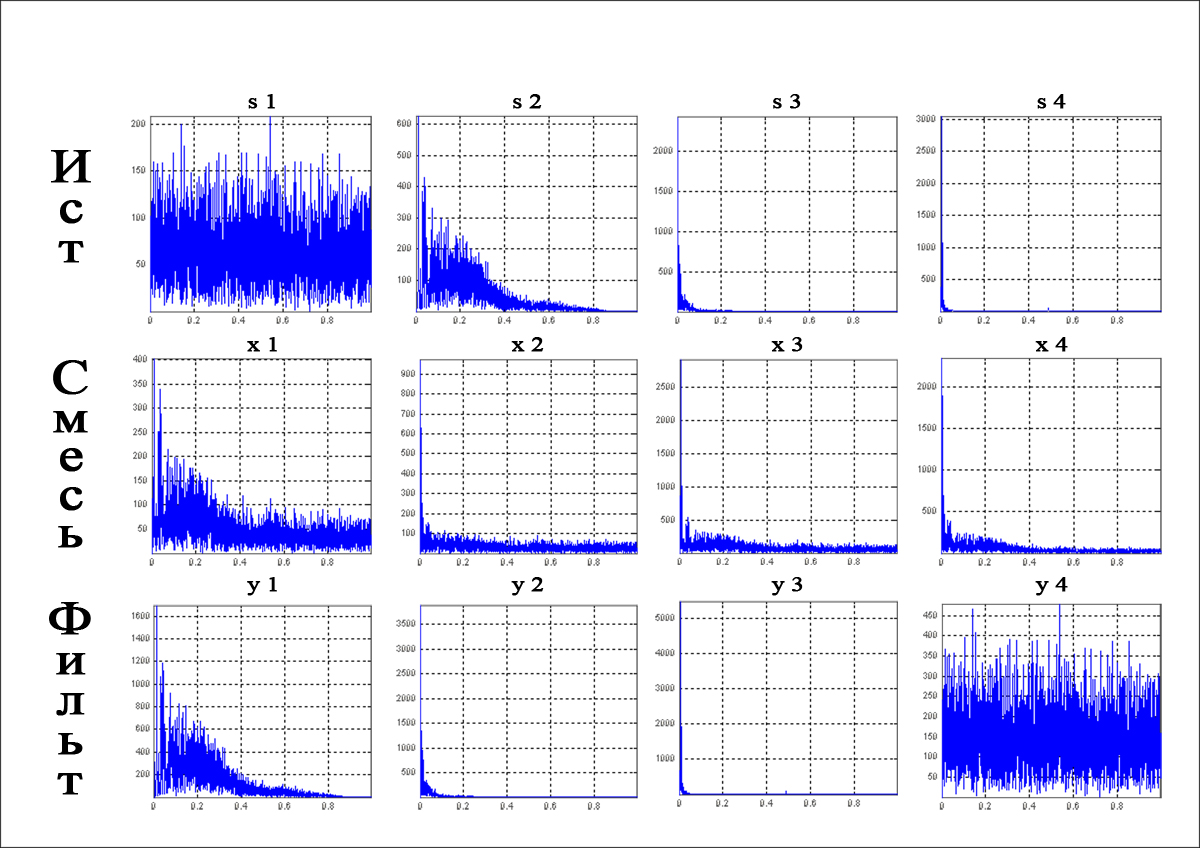
Рис. 6.15. Спектры всех использовавшихся сигналов
Контрольные вопросы
Что лежит в основе и какие механизмы СО Вы знаете?
Какова особенность процесса обучения НС с СО?
Приведите структурную схему СО Кохонена. Как происходит обучение нейронов этой структуры?
Чем отличаются алгоритмы WTA и WTM обучения НС? Когда при обучении нейронов используют алгоритм CWTA?
Какова идея построения гибридной НС Кохонена с МСП? Опишите основные этапы ее процесса обучения.
Представьте структурную схему НС встречного распространения. В чем особенность обучения и функционирования этой сети?
Для решения каких задач используются НС с обучением по правилу Кохонена? Почему?
Чем было вызвано создание НС АРТ? Опишите упрощенную структурную схему НС АРТ–1 и назначение ее элементов.
Перечислите основные этапы функционирования НС АРТ–1 и дайте их краткую характеристику.
Как организована модель биосистемы обработки зрительной информации – когнитрон?
Каково назначение механизма латерального торможения в структуре когнитрона?
Дайте краткое описание процесса обучения когнитрона.
В чем сходство и в чем отличие моделей когнитрона и неокогнитрона? Обладают ли они способностью к самовосстановлению?
Каковы общие принципы построения и обучения корреляционных НС?
На чем основан и как реализуется механизм обучения и функционирования НС РСА? Какова область их применения?
Расскажите о структуре, обучении и применении рекуррентной ICA–НС Херольта–Джуттена.
Почему однонаправленные ICA–НС оказались эффективнее рекуррентных? Как выглядят алгоритмы их обучения?
Как оценить погрешность распознавания сигналов в ICA–НС?