

Методи зберігання даних
В сучасних СУБД поняття “база даних” можна розділити на поняття “сховище даних” і “журнал транзакцій”. Сховище даних – це файли, які СУБД використовує для зберігання інших базових об’єктів (таблиць, індексів ...). Журнал транзакцій – це робочі області, які СУБД використовує для збереження транзакцій. Самі ж журнали транзакцій використовуються для отримання інформації про зміни в даних і відновлення стану, що був до транзакції.
Фізичні сховища даних
База даних фізично розташовується в апаратному сховищі у вигляді файлів певної структури.
У різних дістрибутивах СУБД сховища даних реалізовані по-різному. Крім того, відміни є не лише в структурі, а й в ідеї сховищ. Так, наприклад, в Oracle, сховище являє собою файл з розширенням .dbf (зрозуміло, що на цьому схожість з DBase III закінчується). Сховище має певний розмір, і навіть якщо всі дані не займають повністю ємність сховища, місце на диску зайнято файлом вказаного розміру. Наприклад, якщо файл сховища має декларований розмір 100 Мб, а дані за об’ємом займають лише 50 Мб, файл сховища, незалежно від даних, буде мати розмір 100 Мб. При повному заповненні і якщо недостатньо місця, системний адміністратор може розширити це сховище, збільшивши розмір файла (Oracle, SyBase SQL Anywhere) або додавши нове сховище (MS SQL Server, SyBase Adaptive Server Enterprise (system 11)). При цьому файл візьме на диску стільки місця, скільки йому потрібно для нового розміру. В SyBase Adaptive Server Enterprise сховище має фіксовану довжину. В SyBase SQL Anywhere сховище за своєю організацією нагадує випадок Oracle, але на відміну від нього володіє здатністю “розтягуватися”, коли це необхідно.
Журнал транзакцій
Транзакція – це логічна одиниця роботи, яку може виконати СУБД. Вона може включати в себе один або декілька SQL-операторів, тобто є послідовністю дій, які змінюють стан даних в базі даних або надають доступ до даних.
З поняттям транзакції часто зв’язують транзакцію на рівні архітектурного рішення, яка розуміє під собою послідовність транзакцій на рівні СУБД. Архітектурна транзакція змінює логічний стан об’єкта, який зберігається в базі. Наприклад, для об’єкта “платіж” транзакція – це зміна стану платежa з “новий” на стан “проведений” або “відбракований”. Причому, дана архітектурна транзакція породжує низку нових супутніх об’єктів типу “квитанція”, “платіжне доручeння” і т.д. В журналі транзакцій розуміється виключно транзакція на рівні СУБД.
Усі транзакції для бази даних необхідно десь зберігати, щоб можна було повернутися до попереднього стану, щоб можна було відслідкувати, хто виконав певну дію. Таким чином, схобище транзакцій буде більше нагадувати LOG (LOG – протокол дій, поставлених на слідкування (користувач 1 додав запис в таблицю N-table, користувач 2 знищив запис в таблиці M-table...)). У багатьох СУБД сховище транзакцій називається Transaction LOG. Всі SyBase, Oracle, Informix, MS SQL Server розміщують Transaction LOG в окремому совищі. Зазвичай СУБД має засоби для розшифрування Transaction LOG у вигляді SQL-скрипта.
Сховище транзакцій, як і сховище даних, може розташовуватися як в одному, так і в кількох окремих сховищах. Принцип використання одного сховища кількома базами в даному випадку працює лише у SyBase. В інших СУБД кожній окремій базі потрібний окремий набір сховищ транзакцій.
Зрозуміло, що Transaction LOG за довгий час роботи бази при її інтенсивному використанні може зрости до неймовірних розмірів. Щоб уникнути цього, сучасні СУБД пропонують чистити LOG або при досягненні критичного розміру (виставляється адміністративно), або при настанні часу “Ч”. Обмін даними
Як правило, користувачі працюють з даними, що знаходяться в базах даних, розташованих на різноманітних, часто віддалених, машинах. Забезпечуючи користувачам таку роботу, існуючі СУБД здійснюють обмін даними між локальними і віддаленими комп’ютерами.
Обмін даними між базами даних може відбуватися як в on-line, так і в off-line режимі. У першому випадку обмін даними здійснюється в режимі прямого “спілкування”. Функція підтримки on-line зв’язку входить до складу основних функцій кожної сучасної СУБД.
On-line режим
Зв’язок з віддаленою СУБД
При розподіленій архітектурі побудови БД потрібна взаємодія між віддаленими СУБД, яка дозволить отримати доступ, манипулювати, розділяти і зберігати дані в базах на віддалених серверах.
В сучасних СУБД підтримка on-line зв’язку є базовою функцією.
Розглянемо, як відбувається зв’язок з віддаленим сервером ( рис.2.3). Імена віддалених серверів визначаються на сервері Main, вказується ім’я сервера, його адреса і логін, під яким буде відбуватися під’єднання. При створенні розподіленої транзакції в імені об’єктів, що належать іншому серверу, вказується ім’я віддаленого сервера. Так, база base_x, яка знаходиться на сервері RS, для сервера Main буде мати ім’я RS.base_x.
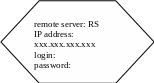




Рис.2.3
SQL*net
SQL*net дозволяє інструментам і додаткам Oracle отримувати доступ, манипулювати, розділяти і зберігати дані в БД Oracle на віддалених серверах. Крім цього, SQL*net забезпечує доступ до даних в середовищі багатьох серверів баз даних.
SQL*net 2.1 – це програмне забезпечення віддаленого доступу до даних, яке належить корпорації Oracle. Цей продукт здійснює всі комунікації (як клієнт/сервер, так і сервер/сервер) через будь-яку мережу. Завдяки SQL*net бази даних і їх додатки можуть розташовуватися на всіх комп’ютерах і спілкуватися як рівні додатки. Використовуючи SQL*net 2.1, можна отримати переваги всіх засобів сервера Oracle. При розподіленій обробці клієнти і сервери взаємодіють для розрішення єдиної транзакції даних, – навіть якщо додатки і бази даних є розділеними логічними сутностями, в тому числі і на різних фізичних машинах. Транзакція розподіляється між місцезнаходженням клієнта і серверів; клієнт і сервери повинні кооперуватися, щоб виконати транзакцію. Розподілена обробка дозволяє відокремлювати відповідні ресурси від ресурсів, що надходять з мережі. Клієнт, наприклад, може виконуватися на дружній до користувача графічній робочій станції чи настільному комп’ютері, тоді як сервер може знаходитися на машині, яка більш придатна для обробки даних. Розподілена обробка також дозволяє централізувати обробляємі дані, це надає можливість багатьом клієнтським додаткам одночасно звертатися до одного сервера.
SQL*net в розподіленій обробці. SQL*net відповідає за забезпечення зв’язків між скооперованими партнерами в розподіленій транзакції, чи то клієнт/сервер, чи сервер/сервер. Зокрема, SQL*net дозволяє клієнтам і серверам з’єднуватися один з іншим, передавати речення SQL i відповідні виборки даних, ініціювати переривання від клієнта чи сервера, і роз’єднуватися по закінченню сесії. Протягом часу, коли відбувається з’єднання, SQL*net дозволяє будь-які відміни між внутрішніми представленнями даних і/або наборами символів комп’ютерів, що застосовуються.
Коли клієнт або сервер робить запит на з’єднання, SQL*net приймає запит і, якщо в ньому задіяно кілька машин, передає його своєму нижчерозташованому рівню, прозорому мережному субстрату (TNS), для передачі через комунікаційний протокол відповідному серверу. На сервері SQL*net приймає запит від TNS і передає його базі даних у вигляді мережного повідомлення з одним або декількома параметрами (наприклад, речення SQL). За виключенням початкового з’єднання, всі додатки, як локальні, так і віддалені, генерують одні й ті ж самі запити, незалежно від того, чи виконуються вони на одному й тому ж комп’ютері, чи розподілені між кількома комп’ютерами. Початкове з’єднання відрізняється лише тим, що додатком або користувачем повинно бути вказано ім’я віддаленої бази даних.
Рис.2.4 показує локальний додаток (ліворуч) в протилежність додатку “клієнт-сервер“ (праворуч). В обох випадках додаток являє собою екран введення даних SQL*Forms.
Функціональними перевагами SQL*net вважаються:
мережна прозорість;
незалежність від протоколів;
незалежність від середовища/топології;
здатність працювати в гетерогенному мережному середовищі;
прозорість місцезнаходження;
гарні діагностичні засоби.

Локальний додаток
З’єднання
SQL*net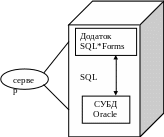



Рис. 2.4
Додатки Oracle, розроблені на локальній базі даних, можуть бути розгорнуті в мережі для доступу до аналогічної, або так само структурованої, бази даних Oracle без будь-яких змін в додатку. SQL*net відповідає за передачу запитів даних додатка від клієнта чи сервера Oracle до сервера і за повернення результатів ініціатору запитів.
З точки зору розробника чи користувача додатка весь обмін даними через SQL*net невидимий для користувача додатка. Крім того, можна змінювати структуру мережі під додатком, не змінюючи сам додаток. Ця здатність залишатися невидимою і відома як мережна прозорість.
SQL*net забезпечує своїм додаткам незалежність від протоколів. Додаток, що використовує SQL*net, може працювати через будь-який мережний протокол. Будь-який додаток, розроблений на будь-якому комп’ютері, що використовував будь-який протокол, може бути перенесений без змін на інші комп’ютери, використовуючі інші протоколи.
Коли SQL*net передає управління з’єднанням нижчерозташованому протоколу, SQL*net неявно наслідує всі середовища і/або топології, які підтримують цей мережний протокол. SQL*net дозволяє мережному протоколу використовувати будь-які засоби передачі даних, такі як Ethernet, Token Ring, FDDI чи SDLC, для забезпечення низькорівневого зв’язку між двома комп’ютерами.
Моделі Oracle клієнт/сервер і сервер/сервер забезпечують зв’язаність через множинні мережні протоколи, причому кожний протокол працює властивим для нього чином.
Off-line режим (синхронізація транзакцій методом реплікації)
З
База
Base_pub
Сервер Main
 а
неможливості організувати on-line
з’єднання, сучасні СУБД пропонують
свої засоби для организації зв’язку.
Метод организації off-line
зв’язку полягає у вилученні інформації
з логу транзакцій (Тansaction
LOG),
конвертації її в SQL-скрипт,
передачі отриманої інформації віддаленому
серверу і застосуванні SQL-скрипта
на ньому.
а
неможливості організувати on-line
з’єднання, сучасні СУБД пропонують
свої засоби для организації зв’язку.
Метод организації off-line
зв’язку полягає у вилученні інформації
з логу транзакцій (Тansaction
LOG),
конвертації її в SQL-скрипт,
передачі отриманої інформації віддаленому
серверу і застосуванні SQL-скрипта
на ньому.
В різних СУБД подібні засоби розрізняються , об’єднує їх принцип дії і однаковий принцип підготовки інформації для отримання з лога.
Сервер Main


База
Base_pub

База
Base_sub
Сервер RS

Table_1
Table_2
Table_3
Рис.2.5
В СУБД Sybase SQL Anywhere реплікаційним засобом є SQL Remotе. SyBase Adaptive Server Enterprise для зв’язку з SQL Anywhere використовує SQL Remote, а для зв’язку з до себе подібним сервером - SyBase Replication Server. Oracle використовує власну розробку - Oracle Replication.
Н
Мал 2.6



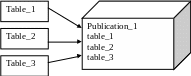
Для органiзації реплiкації на сервері Main була створена публікація Publication_1. Фактично публікація є переліком таблиць та їх атрибутів, підготовлених для вилучення і передачі даних реплікаційним пристроєм.
На сервері RS організовано підписку Subscription_1 на розсилання публікації Publication_1.
Під час роботи реплікаційниий пристрій (реплікаційний агент) переглядає в лозі транзакцій транзакції, що стосуються таблиць, які описані в публікації Publication_1. Знайдені транзакції групуються в пакет і пересилаються мережею, а потім використовуються на сервері RS в межах підписки Subscription_1.
У нашому прикладі підписка заповнює даними таблиці, такі ж самі за структурою і назвою, як на сервері Main. Публікація і підписка можуть бути налаштовані більш гнучко, і дані можуть братись як з усіх полів таблиці, так і з обраної їх частини. Також налаштовується можливість змінити ім’я таблиць-приймачів, аж до передачі даних на вхід збереженої процедури в якості параметрів. Таким чином поняття “приймач даних” для реплікації є таким, що налаштовується.
Передача даних може здійснюватись різними шляхами. Так, наприклад, в SyBase SQL Remote це може бути файловий обмін на єдиному диску, FTP-служба чи електрона пошта. Для цього працюють два реплікаційних агента: один у сервера Main, іший у сервера RS.
Схема на рис.2.6 демонструє двосторонній обмін між серверами Main і RS. На кожному з цих серверів створюються публікації. Сервер RS, як і в попередньому прикладі, підписується на публікацію сервера Main, a той, в свою чергу, підписується на публікацію сервера RS.
Рис.2.6
Дана схема є дійсною для роботи реплікації під управлінням SyBase SQL Remote. Зміст схеми, головним чином, полягає в забезпеченні надійності передачі. Після використання даних, переданих в напрямку сервера RS, реплікаційний агент RepAgent_RS формує “квитанцію” про коректність прийому-застосування. Квитанція пересилається реплікаційному агенту RepAgent_Main, і він вирішує, чи необхідно пересилати дані знов, чи видати серверу інформацію про проходження сеансу.
Засоби off-line зв’язку останнім часом продвинулися настільки далеко, що зараз вони є вже не просто засобами обміну даними між СУБД. Вони все більш і більш набувають рис мережних операційних систем, включаючи можливості маршрутизації, адміністрування доступу, контролю безпеки методами брандмауерів (брандмауер – це система, призначена для захисту від несанкціонованого доступу до/з закритої мережі). Репагенти можуть не тільки зв’язуватися з базою і вилучати дані, тепер вони володіють можливістю перенаправляти отримані дані в заданому напрямку, а також шифрувати пакети, що передаються,і блокувати під’єднання з недекларованих мереж.
Я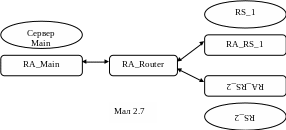 к
показано на рис. 2.7, репагент сервера
Main
(RA_Main)
пересилає дані окремій реплікаційній
машині RA_Router,
яка в свою чергу може відправити їх або
репагенту RA_RS_1,
або RA_RS_2,
в залежності від прописаних маршрутизованих
шляхів. Зворотній
зв’язок відбувається так само і залежить
лише від напрямку,
прописаного до сервера-відправника.
Для забезпечення безпеки обміну
інформацією можлива організація
брандмауера, тобто всі пакети, курсуючі
між реплікаційними машинами, будуть
шифруватися. Обмін ключами шифрації -
задача адміністратора системи.
к
показано на рис. 2.7, репагент сервера
Main
(RA_Main)
пересилає дані окремій реплікаційній
машині RA_Router,
яка в свою чергу може відправити їх або
репагенту RA_RS_1,
або RA_RS_2,
в залежності від прописаних маршрутизованих
шляхів. Зворотній
зв’язок відбувається так само і залежить
лише від напрямку,
прописаного до сервера-відправника.
Для забезпечення безпеки обміну
інформацією можлива організація
брандмауера, тобто всі пакети, курсуючі
між реплікаційними машинами, будуть
шифруватися. Обмін ключами шифрації -
задача адміністратора системи.
Для підвищення швидкості вилучення інформації з логу транзакцій, репагент може розпаралелити свій сеанс на декілька окремих процесів і одночасно вилучати інформацію. Наприклад, треба
вилучити велику кількість нових транзакцій з таблиці. Для цього репагент розподілить свій процес на декілька окремих процесів (thread), які не блокуючи один одного, будуть вилучати кожен свою частину інформації.