


142
Глава 20
Соседи
Рисунок 20-4
Вкладка Анализ методом ближайших соседей: Соседи
Количество ближайших соседей (k). Задайте число ближайших соседей. Обратите внимание на то, что использование большего числа соседей необязательно приводит к более точной модели.
Если на вкладке Переменные задана целевая переменная, то в качестве альтернативы можно задать диапазон значений и позволить процедуре выбрать «наилучшее» число соседей в этом диапазоне. Метод определения числа ближайших соседей зависит от того, запрошен ли отбор показателей на вкладке Показатели.
Если задействован отбор показателей, то он выполняется для каждого значения k в заданном диапазоне, и выбирается k, а также набор показателей, дающие наименьший процент ошибок (или наименьшую сумму квадратов ошибок, если целевая переменная является количественной).
Если отбор показателей не задействован, то для выбора “наилучшего” числа соседей используется V-слойная перекрестная проверка. Для задания слоев перейдите на вкладку Группы.

143
Анализ методом ближайших соседей
Вычисление расстояний. Здесь задается метрика расстояния, используемая в качестве меры сходства наблюдений.
Метрика Евклида. Расстояние между двумя наблюдениями x и y представляет собой квадратный корень из суммы квадратов разностей значений наблюдений по всем измерениям.
Метрика «городского квартала». Расстояние между двумя наблюдениями представляет собой сумму абсолютных разностей значений наблюдений по всем измерениям. Эта метрика также называется Манхэттенским расстоянием.
Дополнительно, если на вкладке Переменные задана целевая переменная, то можно задать взвешивание показателей с помощью их нормализованной важности при вычислении расстояний. Важность показателя вычисляется для предиктора как отношение процента ошибок или ошибки в виде суммы квадратов для модели с удаленным рассматриваемым предиктором к проценту ошибок или ошибке в виде суммы квадратов для полной модели. Нормализованная важность вычисляется путем деления значений важностей показателей на одно и то же число, для того чтобы их сумма равнялась 1.
Предсказанные значения для количественной цели. Если на вкладке Переменные задана количественная целевая переменная, то здесь указывается, будет ли предсказанное значение вычислено по значению среднего или медианы ближайших соседей.
144
Глава 20
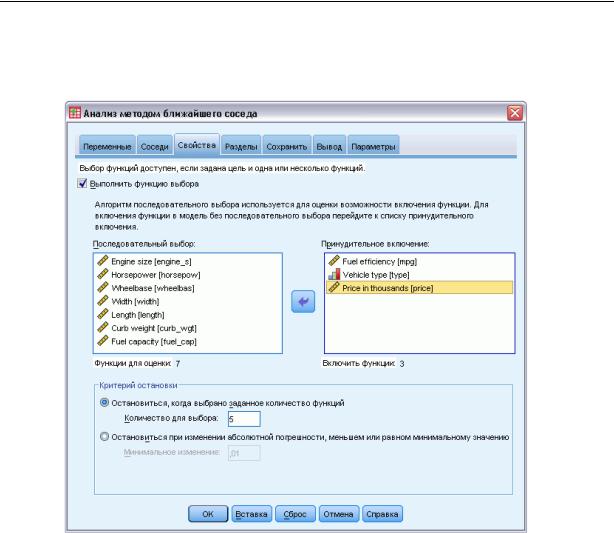
Показатели
Рисунок 20-5
Вкладка Метод ближайших соседей: Показатели
Вкладка Показатели позволяет запросить и задать параметры для отбора показателей, когда на вкладке Переменные задана целевая переменная. По умолчанию при отборе показателей рассматриваются все показатели, однако можно выделить часть показателей для принудительного включения в модель.
Критерий остановки. На каждом шаге в модель добавляется тот показатель, добавление которого в модель дает наименьшую ошибку (вычисляемую как процент ошибок для категориальной целевой переменной и как сумму квадратов ошибок для количественной целевой переменной). Отбор включением продолжается до тех пор, пока не выполнится заданное условие.
Заданное количество показателей. Алгоритм отбирает фиксированное число показателей в дополнение к тем, которые принудительно включаются в модель. Задайте целое положительное число. Уменьшение числа отбираемых показателей создает более компактную модель, повышая риск упустить важные показатели. Увеличение числа отбираемых показателей приведет к включению всех важных показателей,

145
Анализ методом ближайших соседей
повышая риск в итоге включить показатели, которые в действительности увеличивают модельную ошибку.
Минимум модуля относительного изменения ошибки. Алгоритм останавливается,
когда значение модуля относительного изменения ошибки указывает на то, что модель нельзя дальше улучшить путем добавления дополнительных показателей. Задайте положительное число. При уменьшении значения минимального изменения появляется тенденция включить больше показателей, при этом возникает риск включить показатели, которые не улучшают заметно качество модели. При увеличении значения минимального изменения появляется тенденция включить меньше показателей, при этом возникает риск потерять показатели, которые важны для модели. «Оптимальное» значение минимального изменения зависит от имеющихся данных и решаемой задачи. Смотрите диаграмму значений ошибок при отборе показателей в выводе, чтобы определить, какие показатели наиболее важны. Дополнительную информацию см. данная тема Значения ошибок при отборе показателей на стр. 159.
Группы
Рисунок 20-6
Вкладка Метод ближайших соседей: Группы
Вкладка Группы позволяет разделить набор данных на обучающий и контрольный наборы и, когда это возможно, приписать наблюдения слоям для перекрестной проверки.

146
Глава 20
Обучающая и контрольная группы. Здесь задается метод разбиения активного набора данных на обучающую и контрольную выборки. Обучающая выборка содержит записи данных, используемые для обучения модели ближайших соседей. Чтобы построить модель, необходимо некоторый процент наблюдений из набора данных включить в обучающую выборку. Контрольная выборка представляет собой независимый набор записей данных, используемый для проверки качества окончательной модели. Ошибка для контрольной выборки дает корректную оценку прогностической способности модели, поскольку контрольные наблюдения не использовались для построения модели.
Распределить наблюдения по группам случайным образом. Задайте процент наблюдений, приписываемых к обучающей выборке. Остальные наблюдения приписываются к контрольной выборке.
Для распределения наблюдений использовать переменную. Задайте числовую переменную, которая относит каждое наблюдение активного набора данных к обучающей или контрольной выборке. Наблюдения с положительным значением этой переменной относятся к обучающей выборке, а наблюдения с отрицательным или нулевым значением – к контрольной выборке. Наблюдения с системными пропущенными значениями исключаются из анализа. Любые пользовательские пропущенные значения группирующей переменной всегда рассматриваются как не пропущенные.
Слои для перекрестной проверки.V-слойная перекрестная проверка используется для определения «наилучшего» числа соседей. Она недоступна совместно с отбором показателей по причинам, связанным с эффективностью работы процедуры.
Для выполнения перекрестной проверки выборка делится на некоторое число подвыборок или слоев. Затем формируются модели ближайших соседей с поочередным исключением данных каждой подвыборки. Первая модель создается на основе всех наблюдений, кроме наблюдений из первого слоя выборки, вторая модель создается на основе всех наблюдений, кроме наблюдений из второго слоя выборки, и так далее. Для каждой модели оценивается ошибка путем применения модели к подвыборке, которая была исключена при ее создании. «Наилучшее» число ближайших соседей – это то, которое дает наименьшую среднюю ошибку по слоям.
Распределить наблюдения по слоям случайным образом. Задайте число слоев,
которое должно использоваться при перекрестной проверке. Процедура случайным образом распределяет наблюдения по слоям, пронумерованным от 1 до V, где V – число слоев.
Для распределения наблюдений использовать переменную. Задайте числовую переменную, которая относит каждое наблюдение в активном наборе данных к некоторому слою. Эта переменная должна быть числовой и принимать значения от 1 до V. Если пропущены какие-либо значения в этом диапазоне, а также по каким-либо расщеплениям, если используются расщепленные файлы, то это вызовет ошибку.
Задать начальное значение для Твистера Мерсенна. Установка начального значения позволяет воспроизводить результаты анализа. Применение этого элемента управления аналогично выбору Твистера Мерсенна в качестве активного генератора и заданию фиксированной начальной точки в диалоговом окне Генераторы случайных чисел с той существенной разницей, что задание значения в данном диалоговом окне запоминает