3_Необходимость анализа данных
.pdfИспользуйте для:
◦Классификации: анализ рисков и перехода клиентов
◦Регрессии:
предсказание прибыли или дохода
◦Анализа ассоциаций, основанного на
предсказании
нескольких
переменных
Строит одно дерево для каждого предсказываемого
атрибута
Быстрый

Используется для:
◦Классификации
◦Ассоциации с несколькими предсказываемыми атрибутами
Предполагает, что все входные данные независимы
Простой механизм классификации, основанный на вероятности выполнения условий
Требует меньшего количества вычислений

Линейная регрессия
Находит лучшую прямую через набор точек
Логистическая регрессия
Находит кривую путем применения логистического преобразования
Используются для
предсказательного анализа (определения отношений между числовыми атрибутами)
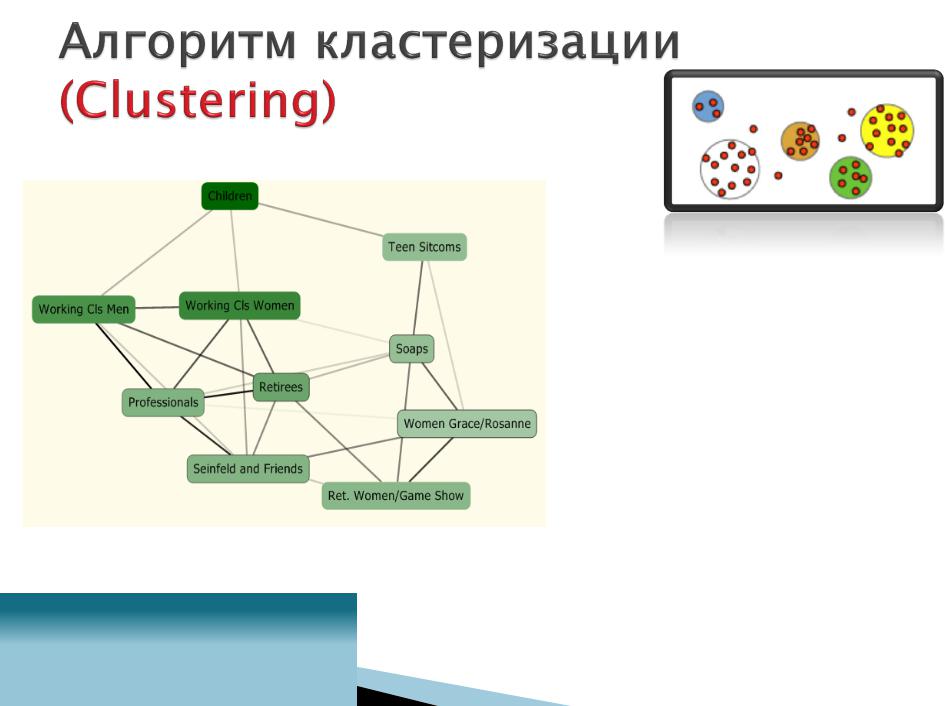
•Применим к:
•Сегментации: группировка клиентов, маркетинговая рассылка предложений
•Также: классификация и регрессия
•Обнаружение аномалий
•Дискретные и непрерывные атрибуты
•Замечания:
•Атрибуты «Predict Only»
нельзя использовать

Возраст
Мужчина Женщина
Сын
Дочь
Родитель
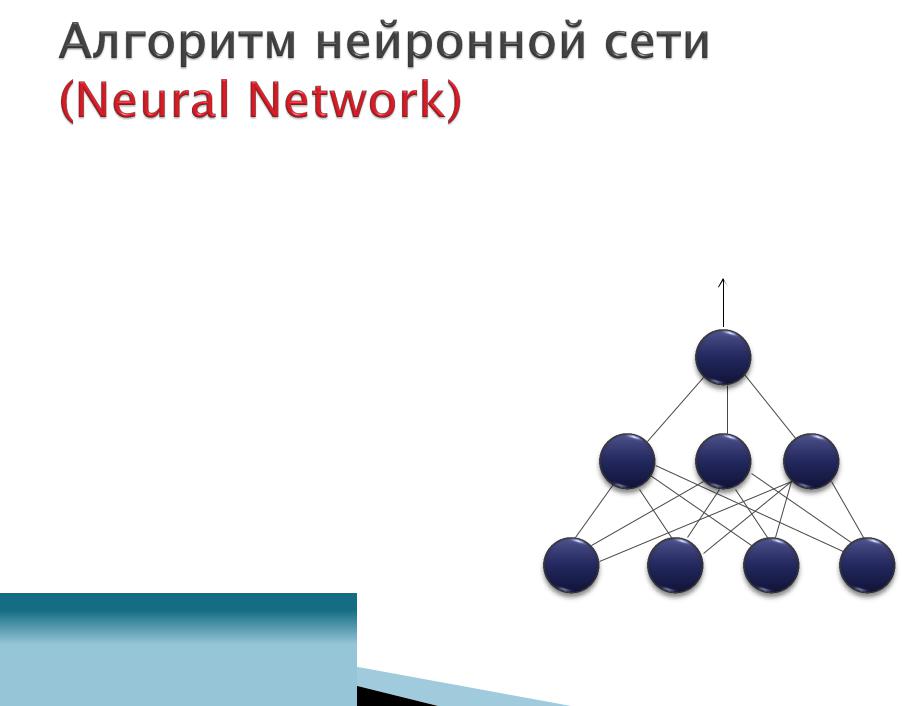
Применим к:
◦Классификаци
ии
◦Регрессии
Хорош для
нахождения
сложных
взаимосвязей
между
атрибутами
◦Но сложно интерпретиров
ать результаты
Loyalty
y
Output
Layer
Hidden
Layers
Input
Layer
Age |
Education |
Floor |
Income |
x1 |
x2 |
x3 |
x4 |
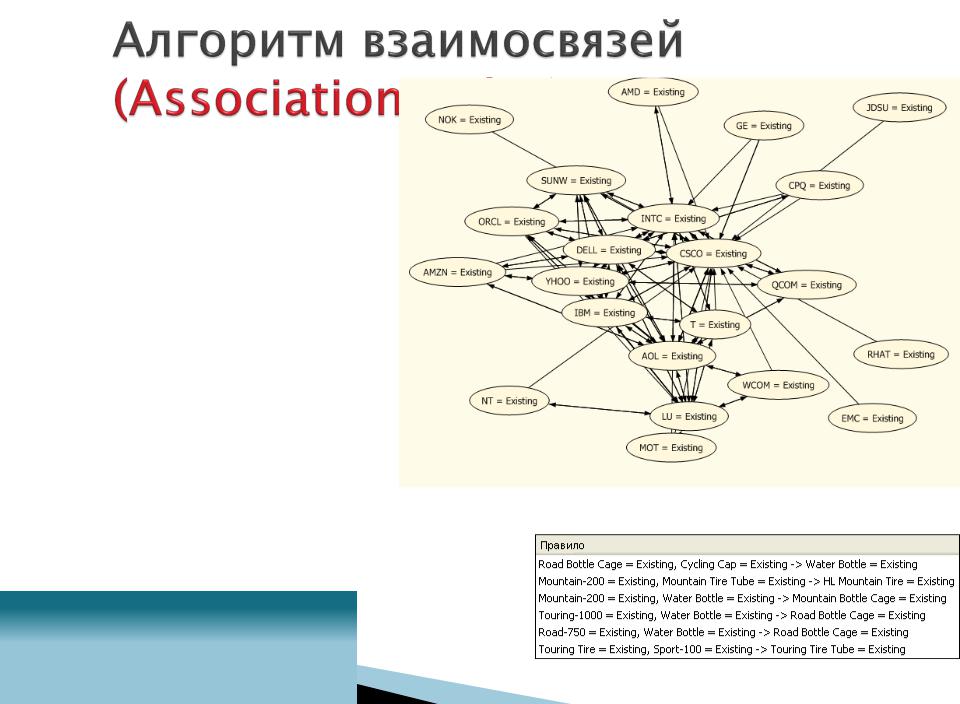
Используйте для анализа:
◦Анализа рыночной
корзины
◦Кросс-продаж и рекомендаций
Находит часто встречающиеся наборы
элементов и связей
Чувствителен к параметрам

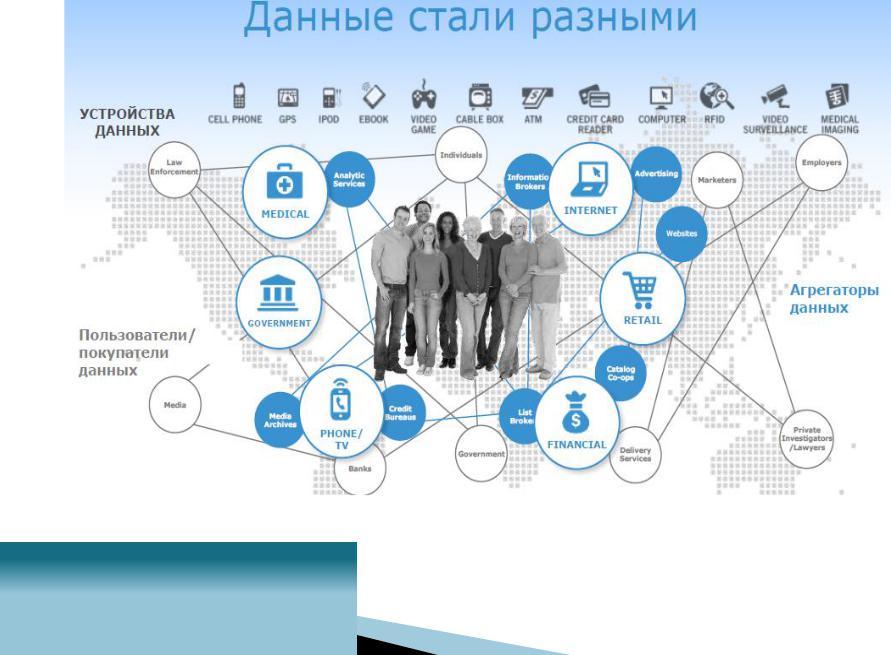
2 BIG DATA
Мы создаем 2,5 экзабайта (1018 или 260 байт)
ежедневно – это значит, что более 90% всех хранимых данных созданы за последние два года.
В новом цифровом мире выигрывает не тот, кто
накопит больше информации, а тот, кто быстрее и
корректнее сумеет ее обработать и использовать.
В 2000 году во всём мире создаётся два экзабайта (1018 или 260 байтам) новых данных. В 2011 году во
всём мире создаётся пять экзабайтов новых данных в
день!
В 2012 г. во всех странах будет сгенерировано 2,43 Зеттабайт (1 ЗБ = около 1 млрд Гб), это более чем в 2
раза превосходит объем информации в цифровом
виде в 2010 г. (1,2 ЗБ). Данные поступают из все большего количества источников. Данные не структурированы => Идея «больших данных»

За ближайшие 8 лет количество данных в мире достигнет 40 ЗБ
(1021 или 270 байт), а это значит, что на каждого жителя Земли будет приходиться по 5200 ГБ данных, по оценке IDC. Взглянув на этот вопрос с другой стороны, аналитики сравнили 40 ЗБ с
природным показателем и пришли к выводу, что к 2020 г.
информационные системы будут иметь дело с количеством данных примерно в 57 раз большим, чем количество песчинок на пляжах на всей поверхности Земли.
Данные прогнозы были сделаны в рамках исследования Digital Universe, которое проводится при поддержке EMC с 2005 г. Причем в последней редакции от декабря 2012 г. прогноз был изменен, и вместо 35 ЗБ, которые ожидали эксперты в июне 2011 г., количество данных в мире в 2020 г. достигнет 40 ЗБ.
Также, по данным исследования Microsoft, уже сегодня более
60% компаний хранят у себя более 10 ТБ данных, с которыми, естественно, нужно что-то делать. Более того, половина из них ожидает, что количество накапливаемых данных удвоится в
ближайшие 2-3 года. Быть может, в будущем эксперты снова
изменят оценку в сторону увеличения. Ясно одно – курс на Big Data неизбежен.