

Эти памяти имеют разное

 .
.ЗУ различаются также по выполняемым функциям, зависящим от места расположения в структуре ЭВМ.
Требования к емкости и быстродействию памяти являются противоречивыми. Чем выше быстродействие, тем технически сложнее и дороже достигается большой объем памяти. Поэтому память в ЭВМ организуется в виде иерархической структуры ЗУ, обладающих различными быстродействием и емкостью (рис. 4.8).

Рисунок 4.8. Система памяти ЭВМ общего назначения
Отметим, что в ПК имеется 3 основных уровня памяти:
- микропроцессорная память (МПП);
- основная память (ОП);
- внешняя память (ВЗУ).
К этим уровням добавляется промежуточная буферная память или КЭШ-память. Кроме этого, многие устройства ПК имеют собственную локальную память.
Важнейшие характеристики (емкость памяти и ее быстродействие) трех основных типов памяти ПК приведены в таблице 4.3.
Таблица 4.3.
Тип памяти
Емкость
Быстродействие
МПП
десятки байт
tобр= 0,001 – 0,002 мкс
ОП, в том числе
ОЗУ
сотни мегабайт
tобр= 0,004 – 0,006 мкс
ПЗУ
сотни килобайт
tобр = 0,035 – 0,1 мкс
ВЗУ, в том числе
НМД
сотни гигабайт
tдост = 5 – 30 мс
Vсчит = 500 – 5000 Кбайт/с
НГМД
единицы мегабайт
tдост = 65 – 1000 мс
Vсчит = 40 – 150 Кбайт/с
CD и DVD
тысячи мегабайт
tдост = 50 – 100 мс
Vсчит = 300 – 5000 Кбайт/с
4.5.2. Методы размещения и поиска информации в памяти
Запоминающее устройство, как правило, содержит множество одинаковых элементов, образующих запоминающий массив (ЗМ). Массив разделен на отдельные ячейки, каждая из которых предназначена для хранения двоичного кода, количество разрядов в котором определяется шириной выборки памяти.
Способ организации памяти зависит от методов размещения и поиска информации в ЗМ. По этому признаку различают адресную, ассоциативную, стековую и магазинную память [7].
Адресная память
В такой памяти размещение и поиск информации в ЗМ основаны на использовании номера ячейки ЗМ (адреса) хранения слова (команды, числа и т.д.), в которой это слово размещается. Для записи/чтения слова в ЗМ инициирующая эту операцию команда должна указать адрес (номер ячейки), по которому производится обращение (ЧТ/ЗП).
Схема памяти с адресной структурой и матричной организацией изображена на рисунке 4.9. Емкость ЗМ – N n-разрядных слов.
При матричной организации памяти адрес ячейки, поступающий в регистр адреса, делится на две равные части, например, по 12 разрядов, поступающие соответственно в регистр адреса X и регистр адреса Y. Из этих регистров коды полуадресов поступают в дешифратор X и дешифратор Y, каждый из которых выбирает одну из 4096 шин. По выбранным шинам подаются сигналы записи (считывания) в ячейку памяти, находящуюся на пересечении этих шин. Таким образом адресуется 10244 ячеек.
Считываемая или записываемая информация поступает в регистр данных, непосредственно связанный с кодовыми шинами данных. Управляющие сигналы, определяющие, какую операцию следует выполнить, поступают по кодовым шинам инструкций.

Рисунок 4.9. Структурная схема модуля основной памяти с матричной организацией
Ассоциативная память
В памяти этого типа поиск информации производится не по адресу ячейки, а по содержанию (по ассоциативному признаку (АП)). При этом поиск по АП производится параллельно во времени для всех ячеек ЗМ.
Во многих случаях поиск по АП позволяет существенно упростить и ускорить обработку данных. Это осуществляется за счет того, что в памяти этого типа операция считывания информации совмещена с выполнением ряда логических операций.
Структура ассоциативной памяти изображена на рис. 4.10.
ЗМ памяти с поиском по АП содержит N (n+1)-разрядных ячеек. Для указания занятости ячейки ЗМ используется дополнительный – служебный –n-й разряд (0 – ячейка свободна, 1 – ячейка занята (записано слово)).
По входной информационной шине ШиВх в РгАП (регистр ассоциативного признака) в разряды [0 - n-1] поступает n-разрядный ассоциативный запрос, а в регистр маски (РгМ) код маски поиска, при этом n-й разряд РгМ устанавливается в 0. Поиск по АП производится лишь для совокупности разрядов РгАП, которым соответствуют 1 в РгМ (незамаскированные разряды РгАП).
Для слов, в которых цифры разрядов совпали с незамаскированными разрядами в РгАП, КС устанавливает в "1" соответствующие разряды в регистре совпадения (РгСв) и в 0 – остальные разряды.
Таким образом, значение j-го разряда РгСв определяется выражением


где РгАП[i], РгМ [i] и ЗМ[i,j] – значения i-го разряда соответственно РгАП, РгМ и j-й ячейки ЗМ.

Рисунок 4.10. Структура памяти с ассоциативным доступом
Комбинационная схема (КС) формирования результата ассоциативного обращения в блоке формирования сигналов (ФС) формирует из слова, образовавшегося в РгСв, сигналы α0, α1, α2 – соответствующие случаям отсутствия слов в ЗМ, удовлетворяющих АП, наличию одного и более одного такого слова:
 –нет такого
слова;
–нет такого
слова;
 –имеется одно
слово;
–имеется одно
слово;  –имеется
несколько слов.
–имеется
несколько слов. Формирование содержимого РгСв и сигналов α0, α1, α2 по содержимому РгАП, РгМ и ЗМ является операцией контроля ассоциации. Эта операция является составной частью операции считывания и записи, хотя она имеет и самостоятельное значение.
При считывании:
вначале выполняется контроль ассоциации по АП в РгАП. Затем при α1= 1 считывается в РгИ найденное слово, а при α2 = 1 в РгИ считывается слово из ячейки, имеющей наименьший адрес из числа найденных в РгСв. Это слово из РгИ → ШиВых.
При записи:
сначала отыскиваются свободные ячейки. Для этого выполняется операция контроля ассоциации при РгАП = 111...10 и РгМ = 000...01. При этом свободные ячейки отмечаются "1" в РгСв. Для записи выбирается свободная ячейка с наименьшим номером, в нее записывается информация, поступившая из ШиВх в РгИ.
При помощи операции контроля ассоциации можно, не считывая слов из ЗМ, определить по содержимому РгСв, сколько в памяти слов, удовлетворяющих АП.
При использовании соответствующих КС в ассоциативной памяти можно выполнять достаточно сложные логические операции, например, такие, как:
- поиск > (<) числа;
- поиск числа в границах.
Для ассоциативной памяти нужны ЗУ без разрушения информации при считывании.
Стековая и магазинная память (СтП, МгП)
СП и МП, так же как и ассоциативная память, являются безадресными.
Стековая память (рис. 4.11, а) представляет собой одномерный массив, в котором соседние ячейки связаны друг с другом разрядными цепями передачи слов.
Стек заполняется с одной стороны (ШиВх), при этом ячейки записываются, начиная с адреса N-1, а считывание – с обратной стороны. При этом остальные слова сдвигаются в соседние ячейки с меньшими номерами. Стековая память работает в режиме «первым пришел – первым обслуживают» (FIFO).
В состав стековой памяти входит счетчик-указатель стека СчУСт. При записи нового слова в стек содержимое СчУСт увеличивается на 1, при считывании – уменьшается на 1.
Стековая память используется в ЭВМ для аппаратной организации различных очередей.
В магазинной памяти (рис. 4.11, б) запись нового слова производится в верхнюю ячейку (0), при этом все ранее записанные слова, включая и слово, находящееся в ячейке 0, сдвигаются вниз на один адрес.
Считывание производится только из верхней ячейки магазинной памяти. При этом если считывание с удалением, то все оставшиеся в МП слова сдвигаются на один адрес вверх (к 0-й ячейке).
Режим работы магазинной памяти – «последним пришел – первым обслуживают».
Магазинная память имеет счетчик-указатель магазина – СчУМг.
Магазинная память используется эффективно при обработке вложенных структур данных.

(а)
(б)
Рисунок 4.11. Структура стековой (а) и магазинной (б) памяти
4.5.3. Организация памяти в многопрограммных системах
В многопрограммных системах (МПС) размещение всех исполняемых программ (команд и данных) полностью в основную часть внутренней оперативной памяти (ОП) во многих случаях невозможно (из-за ограниченного ее объема), учитывая также, что в оперативной памяти должна располагаться резидентная часть операционной системы (ОС). Но в этом нет необходимости, так как в каждый момент работа программы производится с определенным ограниченным объемом памяти. Поэтому в оперативной памяти нужно хранить только используемые в данный момент данные, а остальные могут храниться во внешней памяти (ВЗУ на магнитных дисках или магнитных лентах).
Из этого следует:
1) в МПС должны быть ВЗУ большого объема со сравнительно быстрым временем доступа;
2) целевые пользовательские программы не должны привязываться к определенному месту (адресам) ОП.
При подготовке целевых или пользовательских программ используют условные адреса. Позднее, в процессе подготовки к запуску (выполнению) программ СУПЕРВИЗОР присваивает целевым адресам исполнительные адреса. Эта процедура получила название динамического распределения памяти [7, 14].
Для перевода условных адресов в исполнительные применяются следующие способы:
- базирование;
- организация виртуальной памяти.
При использовании базирования свободная память может состоять из несвязанных областей (фрагментация памяти), и для ввода нужной программы может понадобиться сдвиг содержимого памяти. На рисунке 4.12 приведен пример такого способа. В ОП размещены блоки (фрагменты) выполняемых программ (A, B, C и D). Предположим, что программы A и D завершены, и есть необходимость начать выполнять программу Е, для которой нужен фрагмент памяти Е, больший по объему, чем A или D. В этом случае необходим сдвиг фрагментов B и C вверх или вниз для того, чтобы в ОП мог разместиться фрагмент памяти программы Е.

Рисунок 4.12. Фрагментация памяти
Виртуальная память (ВП) – это способ организации памяти в МПС, при котором достигается гибкое динамическое распределение памяти, устраняется ее фрагментация и создаются значительные удобства для программистов [7]. Это удается достичь без снижения производительности ЭВМ путем усложнения аппаратуры и операционной системы и процессов их функционирования.
Программист имеет дело не с реальной, а с виртуальной (т.е. кажущейся) памятью, объем которой равен адресному пространству ЭВМ (в ЕС ЭВМ и S/370 – это было 224 = 16777216 байт, позже оно увеличилось до 232).
На всех этапах подготовки программ, включая загрузку в ОП, программа представляется в виртуальных адресах, и лишь при самом выполнении машинной команды производится преобразование виртуальных адресов в реальные физические адреса. Пользователь не знает об этом и о том, где (в ОП или на ВЗУ) в настоящий момент находятся его данные (и программа). Это устанавливается автоматически путем динамического распределения памяти в ходе вычислительного процесса.
Преобразование виртуальных адресов (ВА) в реальные (физические) адреса (ФА) упрощается и устраняется фрагментация памяти, если физическая память (ФП) и виртуальная память разбиты на блоки, называемые в этом случае страницами, содержащими одинаковое количество байтов.
Страницам ФП и ВП присваивают номера, называемые номерами физических и виртуальных страниц. Каждая физическая страница способна хранить одну из виртуальных страниц. Порядок расположения байтов (нумерация байтов) в физических и виртуальных страницах сохраняется одним и тем же (рисунок 4.13).

Рисунок 4.13. Соответствие между виртуальной
и физической страницами
Если таблица страниц указывает, что требуемый адрес находится в ВЗУ, то вначале производится обмен между внешней и внутренней памятями. В этом случае значение P(p) является для супервизора указанием для поиска информации в ВЗУ.
При многопрограммной работе ЭВМ таблица страниц должна указывать на принадлежность страниц различным пользователям. Тогда адрес P должен быть представлен как функция двух переменных:
- номера виртуальной страницы p;
- номера программы N.
Следовательно, виртуальный адрес, представляющий собой число 2βp+l, где β – количество разрядов номера байта в странице, преобразуется в физический адрес 2βP(p,N) + l (рисунок 4.14).

2βP(p,N) + l
P(p)
Рисунок 4.14. Перевод виртуального адреса в реальный
Аппаратная реализация преобразования адресов
Известны две основные структуры таблиц страниц:
1. Каждой виртуальной странице (ВС) соответствует одна строка таблицы страниц. Строка содержит номер физической страницы, хранящей данную виртуальную страницу.
2. Каждой физической странице (ФС) соответствует одна строка таблицы. Строка содержит номер виртуальной страницы, хранимой в данной физической странице.
В реальных ЭВМ применяется сочетание обеих этих структур. При этом для реализации таблицы страниц используется ассоциативная организация памяти.
Обычно программа состоит из нескольких массивов и подпрограмм. Удобнее, если при разработке программ каждый массив имеет независимую нумерацию байтов, начиная с 0. Для динамического преобразования адресов в этом случае используют особый метод преобразования ВА в ФА, называемый сегментной организацией памяти.
Структура такой организации памяти еще более усложняется, так как вводится еще один уровень – таблица сегментов.
Для ускорения процесса переадресации используется буфер быстрой переадресации (ББП), содержащий информацию о соответствии логических адресов и эквивалентных им реальных адресов, по которым производится обращение к ОП. Таким образом, учитывая, что обращение процессора к ОП обычно осуществляется по последовательным адресам и с большой вероятностью в пределах одной страницы, выборка строк таблиц из ОП производится только один раз.
В дальнейшем полученная при первом обращении информация остается в буфере и все последующие обращения к ОП, использующие строки таблиц переадресации из той же области ОП, выполняются с использованием ББП. Такой способ преобразования виртуальных адресов в физические получил название динамической трансляции адресов (ДТА).
4.5.4. Иерархическая организация внутренней памяти эвм
Использование иерархических систем внутренних памятей в вычислительной технике является устойчивой тенденцией. Иерархические системы памяти характеризуются следующим образом [14]:
1. Имеется несколько иерархических уровней хранения организованной в блоки информации.
2. Иерархические уровни отличаются по быстродействию и емкости, более быстродействующие памяти имеют меньшую емкость и располагаются либо в самом процессоре, либо ближе к нему – в устройстве управления (УУ) памятью.
3. Первое обращение к блоку информации приводит, как правило, к перемещению блока с более медленного уровня иерархии на более быстрый – последующие обращения к этому блоку приводят к выборке только из быстродействующей памяти.
Обычно внутренняя память имеет два уровня:
- собственно ОП;
- быстрая сверхоперативная память (БП).
БП предназначена для хранения отдельных, наиболее часто используемых участков программы и данных, что обеспечивает быстрый доступ к ним со стороны процессора. Эффект применения БП определяется временем цикла и вероятностью нахождения запрашиваемой информации в БП, что, в свою очередь, зависит от ее емкости, способа адресации и размера блока данных, которыми ОП и БП обмениваются между собой.
В идеальной системе БП должна размещать всю информацию, за которой процессор обращается в ОП. При этом вероятность обращения к БП равна 1, а эффективное время доступа к ОП равно времени цикла БП.
Однако в реальной системе вероятность обращения к БП P≠1 и изменяется в зависимости от параметров БП, подчиняясь закону, близкому к экспоненциальному:
P = 1 – exp (v / v0),
где v0– средний размер программы и ее рабочей области;
v – емкость БП.
Максимальная эффективность применения БП достигается при P=0,95–0,99, что соответствует емкости БП=16–128 Кбайт.
Применяется 2 типа адресации БП:
- прямая – на место определенного блока БП могут размещаться блоки ОП, кратные 64 (k, k + 64, k + 128,..);
- ассоциативная – любой блок ОП может размещаться на место любого блока БП, но для этого необходимы специальные средства.
Наибольшее распространение получила смешанная – адресно-ассоциативная организация памяти (типа КЭШ). Пример такой организации внутренней памяти приведен на рисунке 4.15.

Адрес байта
Матрица адресов
ОП
Рисунок 4.15. Адресно-ассоциативная организация внутренней памяти
На рисунке 4.15 показано размещение информации в ОП и БП.
Содержимое БП однозначно отображает содержимое отдельных фрагментов ОП. Фрагменты определяют адресную единицу в БП: чем больше фрагмент, тем меньше различных адресов в БП, при этом уменьшается объем эффективно используемой БП.
Все поля ОП разбиты (для иллюстрации) на отдельные страницы – по горизонтали и колонки – по вертикали. Количество страниц зависит от Еоп. Так, например, при Еоп= 8 Мбайт ОП может содержать 4096 страниц по 2 Кбайт. При блоке информации, равном 32 байта, количество колонок постоянно и равно 64. В результате разбиения каждая страница содержит 64 блока данных ОП по 32 байта. Обмен между ОП и БП производится блоками.
БП тоже делится на блоки. БП может содержать блоки информации разных страниц ОП. Любой блок данных из определенной колонки ОП можно разместить в одном из блоков той же колонки БП.
БП управляется двумя массивами: матрицей адресов (МА) и таблицей активности.
Деление МА на строки и колонки соответствует делению БП.
В МА хранятся адреса тех блоков информации ОП, которые находятся в БП.
Структура адреса в МА:
- адрес страницы ОП, из которой пересылается блок данных;
- разряды достоверности данных.
Рассмотрим алгоритм работы БП
 ОП.
ОП.При обращении центрального процессора (ЦП) на выборку из ОП по адресу колонки из МА одновременно считываются адреса всех блоков данных, содержащихся в данной колонке (адресуемой колонке). Эти адреса сравниваются с адресом страницы ОП.
Если требуемая информация находится в БП (сравнение произошло), то данные выбираются из БП и передаются в ЦП. При этом адрес БП определяется следующим образом:
- номер блока данных определяется сигналом с соответствующей схемы сравнения;
- адрес колонки – разрядами 13 - 18;
- адрес байта – разрядами 19 - 23 адреса обращения.
Если сравнение не происходит, значит, требуемого блока данных в БП нет и требуется обращение к ОП. В этом случае блок данных считывается из ОП, записывается в БП и передается в ЦП.
Блок данных из ОП записывается в колонку БП, номер которой определяется соответствующими разрядами адреса обращения.
Имеются определенные трудности при обмене информацией между ОП (БП) и ПФУ – должны осуществляться определенные действия по копированию содержимого БП и ОП.
Алгоритмы замещения информации в БП
Применяются в основном два способа (алгоритма):
- точные – точно вычисляющие номер блока, к которому долго не было обращения;
- неточные – определяющие блок и группу блоков информации, к которым были направлены последние по времени обращения и которые замещать не следует, т.е. номер блока для замещения определяется по некоторому приближенному правилу.
Для оценки неточных алгоритмов вводится коэффициент качества k, определяющий математическое ожидание номера замещаемого блока:
 ,
, где n – число блоков в колонке БП;
Pi – вероятность замещения i-го блока;
i – номер блока в гипотетически жесткой очередности замещения по точному алгоритму, причем самый активный (новый) блок имеет номер 1, а самый неактивный (старый) – номер n.
Для точных алгоритмов k = n.
В ПК буферная память (КЭШ-память) имеет несколько уровней. Уровни L1, L2 и L3 – это регистровая КЭШ-память, высокоскоростная память сравнительно небольшой емкости, являющаяся буфером между ОП и МП и позволяющая увеличить скорость выполнения операций. Регистры КЭШ-памяти недоступны пользователю, отсюда и название «КЭШ» (Cache), что в переводе с английского означает «тайник».
По принципу записи результатов в ОП различают два типа КЭШ-памяти:
- в КЭШ-памяти с обратной записью результаты операций, прежде чем быть записанными в ОП, фиксируются, а затем контроллер КЭШ-памяти самостоятельно переписывает данные в ОП;
- в КЭШ-памяти со сквозной записью результаты операций одновременно параллельно записываются и в КЭШ-память, и в ОП.
Микропроцессоры, начиная с МП80486, обладают встроенной в основное ядро МП КЭШ-памятью (или КЭШ-памятью 1-го уровня – L1), чем, в частности, и обусловлена их высокая производительность. В МП Pentium имеется КЭШ-память отдельно для данных и отдельно для команд. Емкость КЭШ-памяти у разных МП составляет 8-32 Кбайт. У Pentium Pro кроме КЭШ-памяти 1-го уровня (L1) есть и встроенная на микропроцессорную плату КЭШ-память 2-го уровня (L2) емкостью от 128 Кбайт до 2048 Кбайт. Эта КЭШ-память работает либо на полной тактовой частоте, либо на его половинной частоте.
В некоторых МП имеется также размещенная на системной плате КЭШ-память 3-го уровня (L3) емкостью несколько мегабайт. Время обращения к КЭШ-памяти зависит от тактовой частоты, и составляет обычно 1-2 такта.
В современных ПК применяется также КЭШ-память между ВЗУ и ОП, так называемая КЭШ-память 4-го уровня (L4) емкостью 4-32 Мбайт.
Использование КЭШ-памяти существенно увеличивает производительность системы. Отметим, что зависимость производительности системы от емкости КЭШ-памяти нелинейная. Имеет место постепенное уменьшение скорости роста общей производительности компьютера с ростом размера КЭШ-памяти и практически прекращается после 1 Мбайт КЭШ-памяти L2. КЭШ-памяти L1, L2 и L3 создаются на основе микросхем статической памяти.
4.5.5. Защита памяти в многопрограммных эвм
Средства защиты памяти (СЗП) обеспечивают проверку адреса при каждом обращении к памяти. Адрес считается корректным, если он принадлежит области ОП, которая выделена программе, выполняемой процессором или периферийным устройством (ПФУ), и, следовательно, некорректен, если не принадлежит. В этом случае выполнение программы блокируется, и программа прерывается по причине нарушения защиты.
Контроль по защите памяти может происходить в любом режиме работы оперативной памяти - чтении или записи. В традиционных ЭВМ общего назначения применяются различные способы защиты адреса оперативной памяти, в частности:
1) по граничным адресам - этот способ неудобен, так как требует выделения сплошного участка оперативной памяти;
2) по ключам и другие.
Организация защиты памяти в ЭВМ общего назначения рассмотрена в [7, 12] и других источниках.
Защита памяти (точнее, защита информации от несанкционированного доступа) в ПК рассмотрена в [2].
В соответствии с требованиями по защите информации, обрабатываемой средствами вычислительной техники, в качестве основных мер защиты информации рекомендуются:
- документальное оформление перечня сведений конфиденциального характера с учетом ведомственной и отраслевой специфики этих сведений;
- реализация разрешительной системы допуска исполнителей (пользователей, обслуживающего персонала) к информации и связанным с ее использованием работам, документам;
- ограничение доступа персонала и посторонних лиц в защищаемые помещения и помещения, где размещены средства информации и коммуникации, а также хранятся носители информации;
- разграничение доступа пользователей и обслуживающего персонала к информационным ресурсам, программным средствам обработки и передачи информации;
- регистрация действий пользователей автоматизированной системы и обслуживающего персонала;
- учет и надежное хранение бумажных и машинных носителей информации, ключей (ключевой информации) и их обращение, исключающее их хищение, подмену и уничтожение;
- использование средств защиты записи (СЗЗ), создаваемых на основе физико-химических технологий для контроля доступа к объектам защиты и для защиты документов от подделки;
- необходимое резервирование технических средств и дублирование массивов и носителей информации;
- использование сертифицированных серийно-выпускаемых в защищенном исполнении технических средств обработки, передачи и хранения информации;
- криптографическое преобразование информации, обрабатываемой и передаваемой средствами вычислительной техники;
- предотвращение внедрения в автоматизированные системы программ-вирусов, программных закладок и другие.
Тема 4.6. Организация ввода-вывода в многопрограммных эвм
Для обеспечения параллельной работы процессора и системы ввода-вывода, начиная с ЭВМ 3-го поколения, был введен ряд специальных управляющих слов для обеспечения работы системы ввода-вывода. В структуре системы ввода-вывода ЭВМ можно выделить следующие уровни (устройства):
- каналы ввода-вывода;
- устройства управления внешними (периферийными) устройствами (в ПК это различные адаптеры, см. рисунок 4.2.);
- внешние устройства (механизмы).
Организация ввода-вывода в традиционных ЭВМ общего назначения подробно рассмотрена в [7, 12].
Пример структуры слов управления вводом-выводом адресного слова канала (АСК), командного слова канала (КСК), управляющего слова устройства (УСУ) и слова состояния канала (ССК) и их взаимосвязь приведены на рисунке 4.16.

Рисунок 4.16. Структура управляющих слов системы ввода-вывода
В традиционных ЭВМ для управления вводом-выводом использовалось несколько типов команд, таких, как SIO (начать ввод-вывод), TIO (проверить ввод-вывод), HIO (остановить ввод-вывод) и другие.
Как уже отмечалось, для организации в ЭВМ параллельной работы устройств ввода-вывода и процессора используется ряд специальных управляющих слов (АСК, КСК, УСУ и ССК). Назначение отдельных полей этих управляющих слов видно из рисунка 4.16. Требуется добавить только о назначении и составе полей «флажки» и «состояние».
В поле «Флажки» указываются специальные признаки, которые позволяют организовывать без прерывания работы процессора последовательности команд обращения к устройствам ввода-вывода (канальных программ) с разными кодами команд или одинаковыми кодами, но с разными адресами памяти, информировать процессор о ходе выполнения программ и организовывать другие режимы.
Процессор участвует в организации ввода-вывода до момента формирования УСУ, далее процессор переходит к выборке и выполнению следующей команды своей программы, а выполнение канальной программы осуществляется параллельно с работой процессора под управлением УСУ. Отметим, что может быть столько УСУ, сколько операций ввода-вывода необходимо одновременно выполнять.
В процессе выполнения передачи информации между ВнУ и памятью ЭВМ содержимое счетчика байтов уменьшается на величину переданных данных и после успешного завершения текущей команды обеспечивается выборка следующего КСК канальной программы, если в поле «Флажки» установлен соответствующий признак.
После завершения операции ввода-вывода, успешного или вынужденного (например, из-за сбоя в устройстве ввода-вывода) канал формирует специальное управляющее слово - ССК, структура которого показана на рисунке 4.5. Назначение полей ССК ясно из их названия. Отметим только, что в поле «Состояние» записывается информация о состоянии канала ввода-вывода и устройства ввода-вывода.
Информация, записанная в ССК, используется при выполнении прерывания по вводу-выводу и позволяет точно определить, как завершилась операция ввода-вывода.
В персональных компьютерах организация ввода-вывода информации имеет свои особенности [2].
Напомним, что в ПК имеется достаточно широкий спектр ВнУ, включающий:
- внешние запоминающие устройства (ВЗУ);
- диалоговые средства пользователя (видеомонитор, клавиатура и др.);
- устройства ввода-вывода информации;
- средства связи и телекоммуникаций.
ВнУ, применяемые в ПК, хорошо известны, и нет необходимости приводить их описания еще раз.
Для организации ввода-вывода в ПК используются:
- специальные адаптеры, подключенные к системной шине (см. рисунок 4.2.);
- контроллер прямого доступа к памяти (DMA – Direct Memory Access), обеспечивающий обмен данными между ВнУ и ОП без участия микропроцессора, что существенно повышает эффективное быстродействие ПК;
- сопроцессор ввода-вывода, обеспечивающий за счет параллельной работы с МП ускорение выполнения процедур ввода-вывода при обслуживании нескольких ВнУ (дисплея, принтера, НМД, НГМД и т.д.) и освобождающий МП от выполнения процедур ввода-вывода, в том числе реализующий режим прямого доступа к памяти.
Все ВнУ в ПК подключаются к своим адаптерам через соответствующие интерфейсы (ATA/IDE, SCSI, SATA, RS-232, USB и другие - проводные и беспроводные).
Раздел 5. Развитие структуры и архитектуры эвм
Тема 5.1. Основные тенденции и направления развития структуры эвм и подсистем эвм
5.1.1 Общие сведения об основных тенденциях и направлениях развития структуры эвм
Развитие архитектуры неизбежно ведет к развитию структуры ЭВМ. Реализация принципов интеллектуализации, которые все больше определяют развитие архитектуры традиционных ЭВМ, возможна при совершенствовании структурной организации, обеспечивающей повышение эффективности вычислительного процесса, и как следствие этого - рост производительности ЭВМ. В конечном счете, условием и критерием развития структуры ЭВМ является рост их производительности.
Эффективность структуры ЭВМ определяется отношением стоимость/производительность. Требования к ЭВМ разной производительности (малых, средних и высокопроизводительных) различные [14].
Для ЭВМ малой производительности, как наиболее массовой, особенно важен вопрос рентабельности (требование минимизации стоимости, габаритов, эксплуатационных расходов). Выполнение этого требования предполагает использование таких методов оптимизации структуры, которые позволяют реализовать простую и надежную ЭВМ с минимальным объемом оборудования. Это достигается за счет разработки структуры на базе универсальных устройств (микропроцессоров, памяти, адаптеров и др.).
ЭВМ средней производительности используют дополнительное специализированное оборудование, ускоряющее выполнение отдельных операций и более высокую разрядность операционных блоков и шин.
Основное требование, предъявляемое к ЭВМ высокой производительности, – это обеспечение максимальной производительности и высокой точности вычислений. Для этих машин емкость основного и внешнего ЗУ, пропускная способность каналов ввода-вывода, степень мультипрограммируемости, состав внешних устройств выбираются из условий обеспечения полной загрузки центрального процессора при различных сочетаниях класса задач и режимов использования. Поэтому в ЭВМ высокой производительности используют все методы структурной оптимизации, высокую степень специализации составляющих ее устройств и повышенную разрядность (64-128 битов) операционных блоков.
Основными тенденциями в развитии структуры традиционных ЭВМ общего назначения являются разделение функций системы и максимальная специализация подсистем для выполнения этих функций.
В общем виде основные направления развития структуры для каждой подсистемы ЭВМ показаны на рисунке 5.1. и рассмотрены ниже.
5.1.2. Развитие обрабатывающей подсистемы
Развитие обрабатывающей подсистемы ЭВМ общего назначения в большей степени, чем всех остальных подсистем, идет по пути разделения функций и повышения специализации составляющих ее устройств. Создаются специальные средства, которые осуществляют функции управления системой, освобождая от этих функций средства обработки. Такое распределение функций сокращает эффективное время обработки информации и повышает производительность ЭВМ. В то же время средства управления, как и средства обработки, становятся более специализированными. Устройство управления памятью реализует эффективные методы передачи больших объемов данных между средствами обработки и подсистемой памяти.
Меняются функции центрального устройства управления – ряд функций передается в другие подсистемы (например функции ввода-вывода), развиваются средства организации многопотоковой обработки команд с одновременным повышением темпа обработки в каждом потоке, для чего применяются методы конвейерной обработки наряду с совершенствованием алгоритмов диспетчеризации и исполнения команд. Развиваются средства управления межпроцессорным обменом.
Арифметико-логические устройства обрабатывающей подсистемы кроме традиционных средств скалярной или логической обработки все шире стали включать специальные средства для векторной обработки. При этом время выполнения операций можно резко сократить как за счет увеличения количества арифметических конвейеров, а также за счет сокращения такта конвейера. Возможности задач к распараллеливанию алгоритма счета снимают потенциальные ограничения к организации существенно параллельной обработки информации и использованию структур с глубокой конвейеризацией.
В устройствах скалярной обработки все шире используются специальные операционные блоки, оптимизированные на эффективное выполнение отдельных операций [7, 13].
Рассмотрим направления развития обрабатывающих подсистем персональных компьютеров, для реализации функций которых в ЭВМ этого класса используются микропроцессоры [2].
Микропроцессор (МП) или Central Processing Unit (CPU) – это


Рисунок 5.1. Структура ЭВМ и основные направления ее развития
функционально законченное программно-управляемое устройство обработки
информации, выполненное в виде одной или нескольких больших (БИС) и сверхбольших (СБИС) интегральных схем.
Микропроцессоры выполняют следующие функции:
- вычисление адресов команд и операндов;
- выборку и дешифрацию команд из ОП;
- выборку данных из ОП, регистров МПП и регистров адаптеров внешних устройств (ВнУ);
- прием и обработку запросов и команд от адаптеров на обслуживание ВнУ;
- обработку данных и их запись в ОП, регистры МПП и регистры адаптеров ВнУ;
- выработку управляющих сигналов для всех прочих узлов и блоков ПК;
- переход к следующей команде.
Основными параметрами МП являются:
- разрядность;
- рабочая тактовая частота;
- виды и размер КЭШ-памяти;
- состав инструкций;
- конструктив;
- энергопотребление;
- рабочее напряжение и т.д.
Определения каждого из параметров ПК понятны из их названий. При необходимости уточнения определения и роли отдельных параметров ПК можно обратиться к источникам (например, к [2]).
Все МП можно разделить на следующие группы:
- CISC (Complex Instruction Set Command) с малым набором системы команд;
- RISC (Reduced Instruction Set Command) с усеченным набором команд;
-VLIW (Very Length Instruction Word) со сверхдлинным командным словом;
- MISC (Minimum Instruction Set Command) с минимальным набором системы команд и весьма высоким быстродействием.
Рассмотрим кратко особенности МП указанных выше групп.
Микропроцессоры типа CISC
Выпускаются многими фирмами: Intel, AMD, IBM и др. и используются во многих современных ПК, совместимых с IBM PC. Законодателем здесь пока является фирма Intel.
Можно отметить следующее:
- У МП, начиная с 80386 (386), имеется много модификаций, отличающихся разрядностью системной шины, тактовой частотой, габаритами, потреблением энергии, уровнем напряжения питания и другими параметрами.
- У МП, начиная с МП80286, имеется возможность конвейерного выполнения команд, имеется встроенный математический сопроцессор, обеспечена возможность работы в вычислительной сети, имеется возможность работы в многопрограммном режиме и соответствующая ей защита памяти.
- В МП, начиная с 80386 (т.е. у МП 486, Pentium, Xeon,...) предоставляется доступ к ОП емкостью до 64-128 Гбайт и организации виртуальной памяти до 16 Тбайт каждой задаче. В этом режиме осуществляется автоматическое распределение памяти между выполняемыми программами и соответствующая ее защита. Защищенный режим поддерживается операционными системами Windows, OS/2, UNIX и др.
- У МП 80486 и выше имеется поддержка КЭШ-памяти.
- У МП 80486 и выше имеются RISC-элементы, позволяющие выполнять усеченные команды за 1 такт.
Характеристики и особенности МП типа CISC (80286, 80386, 80486, Pentium, Pentium Pro, Pentium MMX, Pentium II, Pentium III, Pentium 4, Pentium D, Celeron D и др.) приведены во многих источниках, и, в частности, в [2].
Отметим только, что за годы развития МП (с момента их появления в 1971 г.) прошли путь значительного развития их параметров, и современные МП имеют такие параметры и возможности, как:
- технология НТ;
- технология гиперконвейерной обработки данных;
- частота системной шины 400, 533, 800 и 1066 МГц;
- КЭШ-память первого уровня с отслеживанием выполнения команд;
- расширенные функции выполнения операций с плавающей точкой и мультимедийных операций;
- набор потоковых SIMD-расширений SS2 или SS3;
- поддержка технологии RAID.
Поскольку повышение быстродействия МП путем увеличения частоты их работы исчерпало себя, фирма Intel (и другие) решили увеличивать производительность МП путем параллельного выполнения вычислений. Это было реализовано в высокопараллельных многопроцессорных системах и серверных двухъядерных МП Xeon (Intel) и Opteron (AMD). Применение таких МП потребовало разработки новых системных плат и чипсетов.
Позже появились и 4-х, 8-и и более ядерные МП. Разработана линейка МП под названием Core, включающая более 15 типов МП с параметрами:
- количество ядер – от 1 до 4-х;
- технология – 0,065 – 0,045 мкм;
- тактовая частота – от 1,06 ГГц до 3,16 ГГц;
- частота системной шины – от 533 до 1333 МГц;
- энергопотребление – от 5,5 до 95 Вт;
- размер КЭШ – от 2 до 12 Мбайт.
Микропроцессоры линейки Core содержат от 200 до 400 млн. транзисторов. Они способны выполнять 4 инструкции за такт и совершать 128-битные SIMD-операции без потери темпа работы.
МП линейки Core имеют КЭШ уровня L1 64 Кбайт (32 Кбайт – для данных и 32 Кбайт – для команд) в каждом ядре и имеют общий на два ядра КЭШ уровня L2.
Кроме этого необходимо отметить, что в МП Core поддерживаются следующие технологии:
- эффективный механизм предварительной выборки данных, позволяющий ускорить работу МП;
- технологию виртуализации (VT), которая позволяет снизить стоимость ресурсов, повысить производительность системы, увеличить адаптивность ресурсов к меняющимся запросам;
- технологию защиты программ от некоторых вирусов;
- технологию, поддерживающую с использованием 64-битных регистров МПП адресацию более 4 Гбайт оперативной памяти.
Отметим, что многие перспективные технологии компании Intel и компоненты (МП, чипсеты и др.) пригодны для использования в «цифровом доме», концепция которого имеет ввиду создание комплекса взаимодействующих домашних и офисных устройств, представляющих возможность интерактивного доступа в любой момент времени к любой информации, необходимой для работы и отдыха [2].
Микропроцессоры типа RISC
МП типа RISC содержат только набор элементарных команд. При необходимости выполнения более сложных команд в МП производится их автоматическая сборка из элементарных.
В этих МП все элементарные команды имеют одинаковый размер и на выполнение каждой из них тратится один машинный такт (на выполнение даже самой короткой команды в системе CISC тратится 4 такта). Одним из первых МП такого типа был МП ARM, на основе которого был создан ПК IBM PC RT – 32-разрядный, имеющий 118 различных команд. Современные 64-разрядные RISC – МП выпускаются многими фирмами: Apple (Power PC), IBM (PPC), DEC (Alpha), HP (PA), Sun (Ultra SPARC) и др.
Такие МП (типа RISC) применяются в ПК и серверах. Они имеют тактовую частоту 800-1800 МГц, характеризуются очень высоким быстродействием, но они программно несовместимы с CISC-процессорами. Они могут лишь эмулировать (моделировать) МП типа CISC на программном уровне, что приводит к резкому уменьшению их эффективной производительности.
Микропроцессоры типа VLIW
Очень перспективные МП типа VLIW выпускают фирмы:
- Transmeta - МП Crusoe;
- Intel – модель Merced (торговая марка Itanium);
- Hewlett-Packard – McKinley.
МП Merced – первый процессор, использующий полный набор 64-битных инструкций (Intel Architecture - 64).
К VLIW-типу можно отнести и МП Elbrus-2000-E2k, разработанный компанией «Эльбрус» (Москва).
Фирма Intel представила МП Itanium2: в 2004 г. Madison, в 2006 г. –Montecito, а в 2007г. – Montvale.
Программы доступа к внутренним VLIW-командам не имеют: все программы (даже операционная система) работают поверх специального низкоуровневого программного обеспечения (Code Morphing), которое обеспечивает трансляцию команд CISC-микропроцессоров в команды VLIW.
МП типа VLIW в отличие от сложной схемной логики, обеспечивающей в современных микропроцессорах параллельное выполнение команд, опираются на программное обеспечение. Это позволило упростить аппаратуру, уменьшить габариты МП и потребление электроэнергии (иногда эти МП называют «холодными»).
Архитектура CISC появилась в 1978 г. МП этого типа представляли собой скалярные устройства (т.е. в каждый момент могли выполнять только одну команду), при этом конвейеров практически не было. Процессоры содержали десятки тысяч транзисторов.
МП RISC были разработаны в 1981 г., когда технология суперскалярных конвейеров только начала развиваться. Процессоры содержали сотни тысяч транзисторов.
В конце 90-х гг. XX в. наиболее совершенные МП содержали уже миллионы и десятки миллионов транзисторов.
Первые МП архитектуры IA-64 содержат уже десятки миллионов транзисторов. На пороге – МП, которые содержат сотни миллионов транзисторов.
Архитектура IA-64 не является ни 64-разрядным расширением архитектуры CISC, ни переработкой архитектуры RISC. IA-64 представляет собой новую архитектуру, использующую длинные слова команд (LIW), предикаты команд, исключение ветвлений, предварительную загрузку данных и другие средства для того, чтобы обеспечить большой параллелизм выполнения программ. Но тем не менее, IA-64 – это компромисс между CISC и RISC, попытка сделать их совместимыми. Существуют два режима декодирования команд – VLIW и старый CISC. Программы автоматически переключаются в необходимый режим исполнения. Для работы с VLIW операционные системы должны содержать и 64-разрядную часть на IA-64 и старую – 32-разрядную.
5.1.3. Развитие подсистемы внутренней памяти
Развитие подсистемы внутренней памяти идет в направлении увеличения ее объема и пропускной способности. Увеличение объема оперативной памяти позволяет существенно сократить потери времени на обмен обрабатывающей подсистемы с внешней памятью.
Характеристики оперативной памяти можно улучшить, применяя программно-доступную двухуровневую структуру. Первый уровень представляет собой основную оперативную память (емкостью до нескольких гигабайтов), второй уровень – расширенную оперативную память емкостью в сотни терабайтов, реализованную также на интегральных схемах, и являющуюся в общем случае буфером между основной оперативной памятью и подсистемой ввода-вывода. Введение расширенной оперативной памяти позволяет увеличить пропускную способность подсистемы в 300–400 раз по сравнению с пропускной способностью существующих накопителей на магнитных дисках.
Увеличение пропускной способности оперативной и расширенной памяти достигается также за счет увеличения их расслоения и секционирования.
Вопросы построения и функционирования подсистемы памяти подробно рассмотрены в подразделе 4.6. данного пособия.
Рассмотрим особенности развития подсистемы внутренней памяти в персональных компьютерах.
Основу оперативных запоминающих устройств (ОЗУ) ПК составляют микросхемы динамической памяти DRAM. Это большие интегральные схемы, содержащие матрицы МОП-транзисторов, использующих для хранения информации либо собственные паразитные емкости, либо дополнительные конденсаторы.
Конструктивно элементы ОЗУ выполняются в виде отдельных модулей памяти. Эти модули вставляются в слоты (разъемы) на системной плате, на которой может быть несколько групп слотов для установки модулей памяти с различным количеством контактов.
Модули памяти характеризуются конструктивом, емкостью, временем обращения и надежностью его работы.
В ПК применяются различные типы модулей памяти – DIP, SIP, SIPP, SIMM, DIMM, RIMM, имеющих различное конструктивное исполнение. Описание таких модулей памяти приведено в [2].
В ПК используются различные типы оперативной памяти: FRAM, DRAM, RAM EDO, BE DO, SDRAM, DDR SDRAM, DRDRAM, в которых используются различные методы доступа к информации. Они отличаются организацией обмена информацией с ОЗУ, тактовой частотой, величиной пропускной способности и другими характеристиками [2].
Развитие технологии хранения информации привело к появлению новых типов оперативной памяти.
Появились ферроэлектрические микросхемы энергонезависимой памяти FeRAM емкостью 32 Мбайт. Эти микросхемы потребляют меньше энергии, быстрее, чем флэш-память выполняют операции чтения (записи), обладают большим сроком службы, но они значительно дороже, чем DRAM (в 30-50 раз).
Фирма IBM совместно с Infineon Technologies разработали технологию магнитной ОП с произвольной выборкой (MRAM), энергонезависимую. По мнению фирмы IBM, микросхемы MRAM в будущем смогут заменить существующие разновидности DRAM. ПК с MRAM будет загружаться практически мгновенно.
Следует отметить, что развитие технологии хранения информации наглядно свидетельствует о движении технического прогресса по спирали: на следующем витке спирали используются старые принципы, реализованные на более прогрессивной технологии. Действительно, первые ОЗУ строились на базе электромагнитных линий задержки (динамические ОЗУ), затем на базе магнитных тороидальных сердечников и пленок (МОЗУ), далее – снова на динамических элементах (CMOS – транзисторах, DIMM), и грядет MRAM (опять МОЗУ).
В последние годы появилось еще несколько типов микросхем памяти, в частности [2]:
- энергонезависимая память с изменением фаз (PCM);
- память на базе программируемых металлизированных ячеек (PMC);
- молекулярная память на основе химического процесса создания ячеек памяти DRAM с молекулярным конденсатором;
- нанопамять (NRAM) на базе углеродных нанотрубок.
Новые микросхемы имеют очень высокие технические характеристики, сочетают в себе лучшие качества ОЗУ – дешевизну (DRAM) и энергонезависимость (флэш-память), а также будут обладать высокой стойкостью к воздействию температуры и магнитных полей.
5.1.4. Развитие подсистемы ввода-вывода
В состав подсистемы ввода-вывода входит набор специализированных устройств, между которыми распределены функции ввода-вывода, что позволяет свести к минимуму потери производительности системы при выполнении операций ввода-вывода.
Краткие сведения об организации ввода-вывода ЭВМ общего назначения и персональных компьютерах приведены в подразделе 4.4.6.
Основные направления развития подсистемы ввода-вывода ЭВМ общего назначения, направленные на расширение функциональных возможностей и повышение уровня независимости этой подсистемы, рассмотрены в [12].
Рассмотрим основные направления развития подсистемы ввода-вывода в персональных компьютерах (ПК).
Современные ПК характеризуются [2]:
- стремительным ростом быстродействия микропроцессоров и некоторых внешних устройств (так, например, для отображения цифрового полноэкранного видео с высоким качеством необходима пропускная способность 22 Мбайт/с);
- появлением программ, требующих выполнения большого количества периферийных операций (например, программы обработки графики в Windows, мультимедиа).
В этих условиях пропускной способности шин расширения, обслуживающих одновременно несколько устройств, оказалось недостаточно для комфортной работы пользователя, поскольку компьютеры стали надолго «задумываться». Разработчики интерфейсов пошли по пути создания локальных шин, подключаемых непосредственно к шине МП, работающих на тактовой частоте, поддерживаемой МП и обеспечивающих связь с некоторыми скоростными внешними по отношению к МП устройствами: основной и внешней памятью, видеосистемами и т.д.
Существует три основных универсальных стандарта параллельных локальных шин: VLB, PCI и AGP, основные характеристики которых приведены в таблице 5.1.
Таблица 5.1.
Характеристика
ISA
EISA
MCA
VLB
PCI 1.0
AGP
AGP 3/04x
Разрядность шины данных и адреса (бит)
16/24
32
32
32/64
32/64
64
64
Рабочая частота (МГц)
8
8-33
10-20
до 33
до 66
66/133
66
Пропускная способность (Мбайт/с)
16
33
76
133
133-533
533- 2132
2132- 4264
Количество подключаемых устройств
6
15
15
4
10
2
2
Обозначения:
ISA – Industry Standard Architecture
EISA – Extended Industry Standard Architecture
MCA – Micro Channel Architecture
VLB – VESA local bus
PCI – Peripheral component interconnect
AGP – Accelerated Graphics Port
5.1.5. Развитие подсистемы управления и обслуживания
Подсистема управления и обслуживания лишь косвенно влияла на производительность ЭВМ. Однако с включением в ее состав сервисного процессора она все больше начинает принимать участие в вычислительном процессе, так, она непосредственно участвует в организации передачи сообщений от одного процессора к другому в мультипроцессорной системе. Сервисный процессор эффективно участвует во взаимодействии устройств обрабатывающей подсистемы, поддерживая быстрое восстановление вычислительного процесса после сбоев, в организации необходимого технического обслуживания отдельных устройств (одновременно и параллельно с решением задач на ЭВМ).
Подсистема управления и обслуживания (ПУО) позволяет поднять на качественно новый уровень эксплуатации современных ЭВМ, усложнение которых выражается в росте количества уровней иерархии ЭВМ, росте числа элементов на каждом уровне иерархии, усложнение межэлементных связей на каждом уровне, усложнение настройки, усложнение протоколов межуровневых взаимоотношений, жестких временных ограничений снизу на скорость прохождения информационных потоков.
Выделение ПУО в самостоятельную структурную единицу – логическое развитие принципа постоянного усложнения ЭВМ.
ПУО современных ЭВМ представляет собой аппаратно-программный комплекс, выполняющий широкий спектр задач, основными из которых являются:
- инициализация ЭВМ;
- поддержка ручных операций оператора;
- обеспечение автоматической и интерактивной диагностики сбоев и отказов и передача информации для систем обработки сбоев и восстановления после них;
- автоматическая перезагрузка операционной системы и содержимого памяти микропрограммы;
- накапливание долговременных и текущих статистических сведений о загрузке и состоянии вычислительного процесса;
- определение потери производительности как функции деградации вследствие неисправности отдельных устройств;
- обеспечение блокировки несанкционированного доступа при случайных или преднамеренных действиях;
- обеспечение связи с центром техобслуживания через удаленный доступ, по инициативе оператора;
- обеспечение совмещения ремонта отказавших ресурсов с управлением остальной части вычислительного комплекса;
- управление электропитанием, охлаждением, синхронизацией системы;
- поддержка средств мультипроцессирования;
- поддержка справочно-информационной системы;
- предоставление «интеллектуального» интерфейса различным категориям обслуживающего персонала.
Круг задач, решаемых ПУО, постоянно расширяется.
Тема 5.2. Развитие операционных сред (архитектур) в эвм
С развитием поколений ЭВМ изменялась их операционная среда.
Рассмотрим наиболее развитые операционные среды поколений ЭВМ – виртуальную и последующие.
5.2.1. Архитектура виртуальных эвм
Основной концепцией ЭВМ третьего поколения являлось совместное использование (разделение) ресурсов многими пользователями (заданиями). Дальнейшее развитие архитектуры ЭВМ происходит в направлении более широкого применения принципа виртуального распределения ресурсов [13].
Основным свойством архитектуры виртуальной машины (ВМ) является отсутствие в интерфейсе пользователя с ЭВМ ограничений на предоставляемые ресурсы.
Архитектура ВМ обладает рядом важных достоинств:
- одно и то же задание может быть выполнено на ЭВМ с различными конфигурациями устройств;
- возможны дальнейшее развитие ЭВМ и адаптация новых ТС;
- каждая ВМ абсолютно надежна и имеет высокую степень защиты от "вмешательства" извне.
Основным недостатком ВМ являются большие системные потери по организации виртуальных средств.
Концептуальная модель виртуальной ЭВМ приведена на рисунке 5.2.
5.2.2. Архитектура объектной эвм
Дальнейшим развитием архитектуры ВМ является архитектура так называемой объектной ЭВМ (ОМ), характерным свойством которой является операционная среда более высокого уровня, определяемая в терминах процессов и данных, что позволяет полностью исключить из интерфейса пользователя с ЭВМ понятие реальной машины [18].
Концепция объектно-ориентированной архитектуры (архитектуры объектной машины) предусматривает:
1) высокоуровневый объектный машинный язык (ОМЯ), использующий единое представление для всех объектов задачи (программы, данные, файлы и др.) и команды высокого уровня для управления объектами;
2) одноуровневую память с практически неограниченным адресным пространством и уникальными идентификаторами объектов, что делает возможным аппаратное управление доступом к информации во внешней памяти;
3) интегрированные в объектный язык средства управления

Пользователи
Реальная машина
Рисунок 5.2. Концептуальная модель виртуальной ЭВМ
процессами и данными, в том числе организации базы данных, что существенно упрощает программирование;
4) интегрированные в аппаратуру средства управления ресурсами физического уровня, что упрощает функции операционной системы и делает их выполнение более эффективным.
Наиболее значительное отличие архитектуры ОМ от архитектуры ВМ заключается в организации одноуровневой схемы управления памятью, при которой и внешняя, и оперативная памяти рассматриваются как единое целое, одинаково адресуемое пространство, разделенное на сегменты.
Объекты, которые представляют собой высокоуровневые конструкции (программы, наборы данных и др.), размещаются в одном или нескольких сегментах.
Сегменты имеют оглавление, которое определяет тип и атрибуты объекта, а также дополнительные сегменты данного объекта. В них вместо адресов используются указатели, отсутствуют регистры и не осуществляется адресация отдельных сегментов внутри объектов.
Указатель является логическим адресом – уникальным идентификатором объекта в системе, содержащим виртуальный адрес и другую информацию доступа.
Другое важное отличие ОМ – интеграция основных функций управления на уровень микропрограмм, что следует непосредственно из свойств объектного уровня машинного языка, который не содержит традиционных команд управления ресурсами. Отсутствие прямой связи между объектами и ресурсами делает возможным интерпретацию ОМ на различных ВМ.
Это требует огромных аппаратных средств поддержки на реальной машине (РМ). Эффективность работы системы обеспечивается переносом функций управления системой на специализированные процессоры, например, процессор ввода-вывода, сервисный процессор и др. Поэтому одним из сопутствующих свойств ОМ является функционально-ориентированная организация (ФО) - отдельные системные функции выполняются независимыми специализированными устройствами.
Архитектура ОМ еще более приспособлена к возможным эволюциям в будущем. Своеобразная гибкость архитектуры обеспечивается принципиальными преимуществами микропрограммного управления. С внедрением этой архитектуры в системах снижается объем управляющего системного программного обеспечения (СПО), полностью исключаются ресурсы системы из средств программирования, обеспечиваются высокие надежность, уровень защиты, гибкость реализации (рисунок 5.3).
5.2.3. Архитектура интеллектуальной эвм
ЭВМ пятого поколения – это естественное развитие ЭВМ в направлении повышения доступности для конечного пользователя, т.е. удовлетворение требований пользователей различных профессий и разной квалификации [13, 15].
Для этого ЭВМ пятого поколения должна иметь следующие основные возможности:
- интеллектуальный интерфейс, обеспечивающий доступ пользователя к ЭВМ на языке проблемной области в естественной для пользователя форме (текст, речь и т.д.);
- развитые инструментальные системы программирования, обеспечивающие создание пользователем прикладных систем и их настройку на конкретную предметную область;
- базу разнообразных в семантическом и синтаксическом отношениях знаний с развитыми механизмами упорядочивания и поиска информации;
- средства организации распределенного доступа пользователя к средствам хранения и обработки информации в виде общей сети интеллектуальных персональных ЭВМ, работающих в качестве сетевых абонентских пунктов (рисунок 5.4).
ЭВМ пятого поколения должна будет иметь следующие подсистемы:
1. Подсистема общения с пользователем (интеллектуальный интерфейс), в состав которой могут быть включены процессоры речевого и визуального ввода, коммуникационный процессор, процессор управления объектами.
2. Подсистема анализа и логического вывода, обеспечивающая выбор методов решения и синтез программ с учетом контекста и содержания задачи, которые дополняются знаниями общего характера из базы знаний (БЗ) ЭВМ. Результатом является формирование алгоритма решения.
Формирование программы обработки данных осуществляется с использованием методов решения из БЗ. Соответственно осуществляется выбор вычислительных и логических средств ЭВМ.
В состав подсистемы анализа и логического вывода должны входить:
- лингвистический процессор (языковой) – программа или аппаратно-программный комплекс, предназначенный для перевода текста на естественном языке в машинное представления и обратно;
- символьные (Лисп, Пролог) процессоры;
- процессор распознавания.
Напомним, что Лисп и Пролог – это алгоритмические языки, предназначенные для обработки списков (Лисп) и логического программирования (Пролог), и относящиеся к языкам 5-го поколения. Особенности этих языков рассмотрены в подразделе 5.3.
3. Подсистема решения задач – потребует средств высокой производительности.
4. Подсистема управления и обслуживания (сервисная подсистема) – обеспечивающая надежность ВС, в том числе – перемещаемость программ и данных, автоматический контроль и восстановление с целью поддержания живучести.
5. База знаний – обеспечивающая накопление, обработку и хранение разнообразных знаний, поддерживающих функциональные возможности интеллектуальной ЭВМ: базу интерфейсных знаний, базу проблемных знаний и базу системных знаний.
Напомним, что знания – это закономерности предметной области (принципы, связи, законы), полученные в результате практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи в этой области [16].
Объектные машины пользователей

Реальная машина
Рисунок 5.3. Концептуальная модель объектной ЭВМ

Интеллектуальные терминалы
ПЭВМ
Терминальная ЭВМ
Системы мини-ЭВМ
Рисунок 5.4. Концептуальная схема ЭВМ пятого поколения
Тема 5.3. Языки функционального и логического программирования и соответствующие им компьютеры
5.3.1. Общие сведения об языках функционального и логического типов
В основе языков программирования функционального типа лежит понятие функции в математическом смысле, а в основе логических языков программирования лежит понятие отношения, восходящее к предикатным логикам.
Если исходить из отношений, то функция

представляет собой отношение
 ,
,которое для наборов значений

 однозначно задает значения
однозначно задает значения
 .
Наоборот, если исходить из функций, то
отношение
.
Наоборот, если исходить из функций, то
отношение
можно считать функцией
 истина или ложь,
истина или ложь,которая для наборов значений

 задает логические значения «истина»
или «ложь». Таким образом, тот и другой
подходы в некотором смысле взаимно
дополняют друг друга и не противоречат
один другому. В данном подразделе
рассматриваются языки обоих типов.
задает логические значения «истина»
или «ложь». Таким образом, тот и другой
подходы в некотором смысле взаимно
дополняют друг друга и не противоречат
один другому. В данном подразделе
рассматриваются языки обоих типов.5.3.2 Языки программирования логического типа
Известно, что во всей предшествующей истории культуры наиболее точная формализация человеческой мысли, хотя и в простейших формах, осуществлялась в математической форме, в частности, в логической форме с использованием логической дедукции с четким выделением объектов мышления. Одним из основанных на этом подходов является создание языков программирования по типу предикатных логик [18]. Примером такого языка является Пролог (programming in logic), разработанный в 1972 г. во Франции. Рассмотрим некоторые преимущества, обусловливающие перспективу использования языков программирования логического типа.
Во-первых, логика предикатов является в некотором роде формализацией человеческого мышления, в частности формализацией доказательств в математике, поэтому полагают, что основанные на ней языки программирования будут наиболее пригодны для обработки информации, в особенности для работы со знаниями, чем существующие языки последовательного типа.
Во-вторых, существует проблема верификации программ: исследования того, удовлетворяют ли они предъявляемым требованиям, а также проблема того, как, исходя из предъявляемых требований, составить нужную программу. Для решения этих проблем желательно осуществить взаимодействие языков, на которых записываются требования к программам, и языков программирования. Кроме того, необходимо исходить из одних и тех же посылок при выполнении операций по верификации и составлению программ. Понятие языков программирования логического типа позволяет использовать единую основу – исчисление предикатов для решения этих задач.
В-третьих, если обратиться к проблеме отображения моделей предметных областей в базах данных, то можно с уверенностью говорить о том, что характер базы данных определяется структурой хранимого в ней множества фактов, а также методами доступа к ним. В языках программирования логического типа факты представляются выражениями в которых константы играют роль термов. Следовательно, множество этих выражений можно рассматривать как базу данных, и, как показано в [18], теорию реляционных баз данных можно считать одним из разделов логики предикатов. Предполагается, что должно происходить постепенное объединение языков программирования логического типа и теории реляционных баз данных на общей основе логики предикатов.
Языки программирования логического типа связаны также и с естественными языками. Одним из истоков символической логики была формализация естественного языка. Логика предикатов как форма выражения этого формального смысла является первым приближением. В качестве семантики естественного языка можно назвать теорию (выдвинутую Монтегю), которая дает формализм перевода предложений естественного языка в формулы интенсиональной логики, но в результате их можно свести к предикатному формализму. Отметим, что и в области лингвистики ведутся исследования предикатных логик в условиях их семантической интерпретации. Эти работы вливаются в русло исследований языков программирования логического типа. Результаты этих исследований могут обеспечить более успешное развитие языков описания спецификаций на основе естественного языка.
В области экспертных систем, использующих методы работы со знаниями, активно применяются языки программирования, называемые производственными системами, однако эти языки носят сугубо эмпирический характер и подвергаются, естественно, существенному пересмотру. Ожидается, что будущее развитие этой семантической теории и других исследований все больше будет склоняться к логике предикатов.
Как известно, логика создана для того, чтобы четко выражать человеческую мысль. Однако, если использовать в языках программирования исчисление предикатов (1 порядка) в непосредственном виде, то это приведет к чрезвычайно большим объемам вычислений, что неприменимо на практике. Поэтому был разработан язык программирования Пролог, в котором ограничиваются специальными выражениями, называемыми выражениями Хорна. Рассмотрим кратко на примере языка Пролог суть языков логического программирования, а также параллелизм, существующий в языке Пролог (И- и ИЛИ- параллелизм).
Выражение Хорна имеет вид:
 (5.1)
(5.1)где

 ,
,
 ,
… - логические формулы.
,
… - логические формулы.Как видно из (5.1), в нем имеется единственная логическая формула без отрицания, и все формулы связаны логической суммой (ИЛИ). Это можно описать в другом виде:
 (5.2)
(5.2)Это выражение читается так «Из

 и
и
 и так далее до
и так далее до
 следует
следует
 ».
Здесь слово «и» соответствует английскому
слову «AND».
На языке Пролог в синтаксисе системы
DEC-10
Пролог это записывается в другом виде:
».
Здесь слово «и» соответствует английскому
слову «AND».
На языке Пролог в синтаксисе системы
DEC-10
Пролог это записывается в другом виде: (5.3)
(5.3)Программа на языке Пролог представляет собой некоторое выражение Хорна и выполняется она путем проведения рассуждений от целевого утверждения в обратном направлении. Если логических формул, подлежащих унификации [18] много, то производится унификация для одной из них. Если эта унификация удовлетворительна, то программа выполняется дальше. Если унификация оказывается неудовлетворительной, то происходит возврат (бэктрекинг) и выполняются другие возможные унификации. Таким образом, в языке Пролог рассуждение ведется в обратном направлении методом проб и ошибок. Пример такого рассуждения приведен в [18].
Рассмотрим прологовский параллелизм. Обратимся вначале к ИЛИ-параллелизму. Как было отмечено выше, при существовании нескольких логических формул, в которых общим переменным можно придать некоторое значение, это делается лишь для одной из них.
Однако, если в машине используется не один процессор, а несколько, то замену общих переменных некоторым значением можно выполнить над несколькими такими формулами одновременно, т.е. над формулами с одинаковыми предикатными буквами и одинаковыми термами.
В языке Пролог все логические формулы (члены формы Хорна) находятся в отношении ИЛИ, тогда параллельное выполнение операций по приписыванию значений общим переменным над несколькими формулами, находящимися в отношении ИЛИ, являются ИЛИ-параллелизмом.
С другой стороны, прологовое правило-оператор может иметь следующий вид

и его правая часть читается как
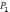
 и
и
 и … и
и … и
 .
Таким образом, подцели в правой части
связаны отношением И. При этом можно
выполнять
.
Таким образом, подцели в правой части
связаны отношением И. При этом можно
выполнять
 ,
,
 ,
… ,
,
… ,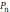
 параллельно, а не в порядке следования
слева направо. В этом случае, поскольку
параллельно, а не в порядке следования
слева направо. В этом случае, поскольку
 ,
,
 ,
… ,
,
… ,
 находятся в отношении И, необходимо
проверять непротиворечивость
находятся в отношении И, необходимо
проверять непротиворечивость
 ,
,
 ,
… ,
,
… ,
 (например, непротиворечивость переменных
с одинаковыми именами). Таким образом,
параллельную обработку подцелей в
правой части прологовcкого
правила-оператора можно назвать
И-параллелизм. Можно одновременно
реализовать И- и ИЛИ- параллелизм.
(например, непротиворечивость переменных
с одинаковыми именами). Таким образом,
параллельную обработку подцелей в
правой части прологовcкого
правила-оператора можно назвать
И-параллелизм. Можно одновременно
реализовать И- и ИЛИ- параллелизм.5.3.3. Языки программирования функционального типа
Под влиянием теоремы Гёделя о неполноте, опубликованной в 1981 г., было осуществлено уточнение важного понятия, связанного с алгоритмами – был определен класс целочисленных функций, носящих название рекурсивных функций (функций, определяемых через самих себя [18]).
А. Чёрч при помощи
 -формализма
и
-формализма
и -преобразований
создал
-преобразований
создал -исчисления
и установил, что так называемые
-исчисления
и установил, что так называемые -определимые
функции эквивалентны рекурсивным
функциям. А. Тьюринг и другие исследователи
разными способами давали определения
вычислимым функциям, однако оказалось,
что все они так же эквивалентны
рекурсивным функциям.
-определимые
функции эквивалентны рекурсивным
функциям. А. Тьюринг и другие исследователи
разными способами давали определения
вычислимым функциям, однако оказалось,
что все они так же эквивалентны
рекурсивным функциям.На основании результатов исследований вычислимых функций А. Чёрч в 1936 г. выдвинул тезис о том, что все функции, которые можно интуитивно рассматривать как вычислимые, являются рекурсивными. Для любой рекурсивной функции существует алгоритм её вычисления, с другой стороны, числовая функция, имеющая общий алгоритм её вычисления, является рекурсивной функцией.
Языки программирования, основанные на идеях
 -исчислений
и теории рекурсивных уравнений, относятся
к классу языков функционального типа.
Одним из таких языков является язык
Лисп. Существует несколько языков
функционального программирования,
отличающихся по конструкции, идеологии
и т.д. Из них трудно выделить какой-нибудь
один (кроме Лисп Мак Карти можно назвать
ЛиспKRC
Тэрнера, FP
Бэкус и др.) [18].
-исчислений
и теории рекурсивных уравнений, относятся
к классу языков функционального типа.
Одним из таких языков является язык
Лисп. Существует несколько языков
функционального программирования,
отличающихся по конструкции, идеологии
и т.д. Из них трудно выделить какой-нибудь
один (кроме Лисп Мак Карти можно назвать
ЛиспKRC
Тэрнера, FP
Бэкус и др.) [18].Программа, написанная на функциональном языке, представляет собой неупорядоченный набор уравнений, определяющих функции и значения. Функции определяются рекурсивно через другие функции и значения. Значения задаются как функции от других значений. В конечном счете полный набор уравнений достаточен для определения всех функций и значений через элементарные функции и значения, имеющиеся в языке. Среди задаваемых уравнениями значений содержатся и требуемые результаты – эти значения вычисляются в ходе выполнения программы.
Языки программирования функционального типа подвели практическую основу для применения
 -исчислений
и рекурсивных функций.
-исчислений
и рекурсивных функций.5.3.4. Логические и функциональные машины
В рамках работ по созданию интеллектуальных ЭВМ проводились работы по созданию архитектур нового типа, в основу которых положены языки программирования логического и функционального типов. Для обычных (традиционных) машин – это языки высокого и сверх высокого уровней, а в машинах нового типа эти языки являются и машинными языками.
На современном уровне развития техники и эти машины являются последовательными, однако при этом будет доказана их осуществимость. Примеры реализации Лисп- и Пролог- машин приведены в 9-ом томе 11-и томной серии по микроэлектронике, написанной японскими специалистами. Рассмотренная в [18] объектно-ориентированная Смолток-машина («Катана») является машиной такого типа.
Без сомнения языками логического и функционального типа будут руководствоваться и при создании архитектур машин параллельного типа, превосходящих по своим возможностям последовательные машины.
Раздел 6. Параллельные компьютеры для интеллектуальных систем
Тема 6.1. Особенности интеллектуальных систем обработки знаний. Классификация параллельных архитектур
В последнее время в различных областях получили широкое применение разнообразные интеллектуальные системы: поддержки принятия решений, экспертные, обучающие, тренажерные и др., являющиеся в своей основе системами обработки знаний. Системы обработки знаний имеют свою специфику, обусловленную, во-первых, большими объемами перерабатываемой информации, во-вторых, высоким уровнем сложности структур перерабатываемых данных, в-третьих, трудно формализуемым характером перерабатываемых знаний. Практическая ценность интеллектуальных систем (особенно это касается систем поддержки принятия решений в чрезвычайных ситуациях и в управлении реальными объектами) определяется в значительной мере реальным масштабом времени ее реакции на поступающие запросы. Общеизвестно, что решение проблемы функционирования вычислительных систем обработки знаний в реальном масштабе времени трудно достижимо без использования принципов параллельной обработки и ассоциативного доступа к структурам данных. Разработка подобных систем чрезвычайно трудоемка, поэтому для обеспечения ее экономической целесообразности жизненный цикл функционирования подобных систем должен быть достаточно продолжительным (от десятка лет и более). Сменяемость аппаратных и программных средств вычислительной техники в настоящее время достигает от нескольких лет до нескольких месяцев. Это обусловливает необходимость наличия у интеллектуальных систем таких качеств, как открытость (в плане модифицируемости и добавления новых методов представления и переработки знаний) и интегрируемость (в смысле возможности функционирования в составе комплексов различных вычислительных и исполнительных средств). Анализ современных систем обработки знаний показывает, что ни одна из архитектур, на базе которых реализованы системы обработки знаний, не обладает в совокупности всеми указанными выше свойствами. Тем не менее рассмотрим особенности современных параллельных архитектур.
В процессе развития вычислительной техники роль параллельной обработки информации менялась. Если ранее применение параллельных ЭВМ диктовалось необходимостью увеличения надежности оборудования управляющих систем, то современные параллельные ЭВМ используются для ускорения счета в различных областях. Особое значение приобретает параллельная обработка для ЭВМ, предназначенных для выполнения алгоритмов искусственного интеллекта. Такие алгоритмы часто носят комбинаторный характер и требуют большой вычислительной мощности.
Параллелизм – это возможность одновременного выполнения нескольких арифметико-логических или служебных операций. На стадии постановки задачи параллелизм не определен, он появляется только после выбора метода вычислений. В зависимости от характера этого метода параллелизм алгоритма может меняться в довольно больших пределах. Параллелизм используемой ЭВМ также меняется в широких пределах и зависит в первую очередь от числа процессоров, способов размещения данных, методов коммутации и способов синхронизации процессов. Язык программирования является средством переноса параллелизма алгоритма на параллелизм ЭВМ и тип языка может в сильной степени влиять на результат переноса.
Для сравнения параллельных алгоритмов необходимо уметь оценивать степень параллелизма. Одновременное выполнение операций возможно, если они не зависят друг от друга по данным или управлению.
Можно выделить следующие основные формы параллелизма: естественный, или векторный параллелизм; параллелизм независимых ветвей; параллелизм смежных операций, или скалярный параллелизм.
Отметим, что для скалярного параллелизма часто используют термин мелкозернистый параллелизм (МЗП). К крупнозернистому параллелизму (КЗП) относят векторный параллелизм и параллелизм независимых ветвей. КЗП оперирует с крупными информационными объектами: ветвями программ и векторами.
В зависимости от стадии разработки полезными оказываются различные характеристики эффективности ЭВМ. Рассмотрим ускорение r параллельной системы, которое используется на начальных этапах проектирования или в научных исследованиях для оценки предельных возможностей параллельной архитектуры. Ускорение определяется выражением:
r =T1 /Tn
где T1 – время решения задачи на однопроцессорной системе,
Tn – время решения той же задачи на n-процессорной системе.
Пусть W = Wск + Wпр, где W – общее число операций в задаче, Wпр – число операций, которые можно выполнять параллельно, а

 – число скалярных (не распараллеливаемых)
операций.
– число скалярных (не распараллеливаемых)
операций.Обозначим также через t время выполнения одной операции. Тогда получаем закон Амдала:
 ,
,
Здесь a =

 / W – удельный
вес скалярных операций.
/ W – удельный
вес скалярных операций. Закон Амдала определяет принципиально важные для параллельных вычислений положения:
1. Ускорение вычислений зависит как от потенциального параллелизма задачи (величина 1-а), так и от параметров аппаратуры (числа процессоров n).
2. Предельное ускорение вычислений определяется свойствами задачи.
Пусть, например, а = 0,2 (что является реальным значением), тогда ускорение не может превосходить 5 при любом числе процессоров, т.е. максимальное ускорение определяется потенциальным параллелизмом задачи. Очевидной является чрезвычайно высокая чувствительность ускорения к изменению величины а.
Рассмотрим некоторые классификации параллельных вычислительных архитектур.
Классификация М. Флинна
Критерии классификации параллельных ЭВМ с крупноформатным параллелизмом могут быть разными: вид соединения процессоров, способ функционирования процессорного поля, область применения.
Одна из наиболее известных классификаций параллельных ЭВМ предложена Флинном и отражает форму реализуемого ЭВМ параллелизма. Основными понятиями классификации являются “поток команд” и “поток данных”. Под потоком команд упрощенно понимают последовательность команд одной программы. Поток данных – это последовательность данных, обрабатываемых одной программой.
Согласно классификации Флинна имеется четыре больших класса ЭВМ:
1) ОКОД (одиночный поток команд – одиночный поток данных) или SISD (Single Instruction – Single Data). Это последовательные ЭВМ, в которых выполняется единственная программа, т.е. имеется только один счетчик команд и одно арифметико-логическое устройство (АЛУ).
2) ОКМД (одиночный поток команд – множественный поток данных) или SIMD (Single Instruction – Multiple Data). В таких ЭВМ выполняется единственная программа, но каждая ее команда обрабатывает много чисел. Это соответствует векторной форме параллелизма.
3) МКОД (множественный поток команд – одиночный поток данных) или MISD (Multiple Instruction – Single Data). Подразумевается, что в данном классе несколько команд одновременно работают с одним элементом данных, однако эта позиция классификации Флинна на практике не нашла применения.
4) МКМД (множественный поток команд – множественный поток данных) или MIMD (Multiple Instruction – Multiple Data). В таких ЭВМ одновременно и независимо друг от друга выполняется несколько программных ветвей, в определенные промежутки времени обменивающихся данными. Такие системы обычно называют многопроцессорными.
В класс МКМД входят машины двух типов: с управлением от потока команд (IF – Instruction Flow) и управлением от потока данных (DF – Data Flow).
Если в ЭВМ первого типа используется традиционное выполнение команд по ходу их расположения в программе, то применение ЭВМ второго типа предполагает активацию операторов по мере их текущей готовности.
Наиболее известными их представителями являются векторно-конвейерная ЭВМ CRAY и ЭВМ типа процессорной матрицы ILLIAC-4. Ограниченный вариант векторной архитектуры используется при разработке параллельных микропроцессоров. Впервые его применила корпорация Intel в микропроцессоре Pentium под названием MMX (MultiMedia eXtension) для вычислений с фиксированной точкой. Данный тип процессора, по классификации Флинна, относится к классу ОКМД (SIMD). Метод ОКМД позволяет по одной команде обрабатывать несколько пар операндов (векторная обработка). Сейчас многие производители микропроцессоров выпускают приборы с векторной архитектурой, причем в двух вариантах: как в виде сопроцессора на одном кристалле с универсальным процессором (например Intel в микропроцессоре Pentium), так и в виде специализированного микропроцессора для цифровой обработки сигналов.
Более полной является классификация Головкина [3]
В качестве основных признаков классификации, характеризующих организацию структуры и функционирования вычислительных систем с точки зрения, главным образом, параллельности работы, в этой классификации выбраны следующие:
1) тип потока команд в центральной части вычислительной системы;
2) тип потока данных в центральной части вычислительной системы;
3) способ обработки данных в центральных устройствах обработки;
4) степень связанности компонент вычислительной системы;
5) степень однородности основных компонент вычислительной системы;
6) тип внутренних связей в вычислительной системе.
Эти шесть признаков определяют базовую схему классификации, содержащую семь уровней иерархии, в которой переход от i-го уровня к i+1-му уровню определяется соответствующим i–м признаком (рисунок 5.1.).
В этой схеме используются следующие условные обозначения:
а) ВС – вычислительные системы;
б) ОК, МК – одиночный и множественный потоки команд соответственно;
в) ОД, МД – одиночный и множественный потоки данных соответственно;
г) С, Р – пословная и поразрядная обработка данных в центральных обрабатывающих устройствах соответственно;
д) Нс, Вс – низкая и высокая степень связанности вычислительной системы соответственно;
е) Ор, Нр – однородная и неоднородная вычислительная система соответственно;
ж) Кн, Пм, Пр – системы со связями “канал – канал”, через общую внешнюю память и непосредственно между процессорами соответственно;
з) Ош, Мш, Пк – системы со связями через одну общую шину с разделением ее времени, со связями через множество шин при использовании многовходовых модулей оперативной памяти и с перекрестными связями при помощи матричного коммутатора соответственно.
Обозначения классов систем составляются из условных обозначений каждого узла схемы, начиная с узлов второго уровня, через которые нужно пройти по стрелкам от узла ВС до узла данного класса систем включительно, отделяя, для удобства записи, условные обозначения узлов первых трех уровней от условных обозначений узлов последних трех уровней наклонной чертой. Так, например, класс вычислительных систем, помеченный на рисунке 5.1. звездочкой (*), имеет обозначение МКМДС/ВсОрПк. Оно расшифровывается следующим образом: вычислительная система с множественным потоком команд и множественным потоком данных в центральной части, с пословной обработкой данных в центральных обрабатывающих устройствах, с высокой степенью связанности и однородной структурой, с перекрестными связями между процессорами и модулями памяти.
Схема классификации и структура межпроцессорных связей приведена на рисунке 5.2.

2-й уровень
3-й уровень
4-й уровень
5-й уровень
6-й уровень
7-й уровень
1-й уровень
Однородные многомашинные системы
Неоднородные многомашинные системы
Однородные многопроцессорные системы
Неоднородные многопроцессорные системы
Рисунок 5.1. Классификация вычислительных систем

Рисунок 5.2. Схема классификации и структура межпроцессорных связей
Существуют и другие классификации вычислительных систем. Отметим, что любая схема классификации должна обладать такими качествами, как:
возможность классификации как всех существующих, так и предвидимых вычислительных структур;
дифференциация существенно-различимых вычислительных структур;
однозначность классификации любой ЭВМ или ВС.
В некоторых системах классификации ВС эти правила нарушаются.
Эрлангенская схема классификации (ЭСК) в значительной степени свободна от этих недостатков. Она, в основном, базируется на двух принципах:
для характеристики основных ВС в ней используются три простых и понятных, и в то же время строгих признака;
в ней применяются операции +, * и ˅, которые позволяют образовывать композиции структур и делают схему достаточно гибкой.
Здесь под гибкостью или многофункциональностью понимают число различных режимов функционирования аппаратуры.
Безотносительно от трех типов конвейерной обработки эрлангенский триплет определяется как t = (k, d, w), где
k – количество устройств управления (УУ), интерпретирующих программу;
d – число АЛУ, управляемых одним из k устройств управления;
w – длина машинного слова или число разрядов, обрабатываемых каждым из d АЛУ.
Из определения следует, что все k УУ и d АЛУ должны быть одинаковы, так же, как и все разряды слова w в каждом из d АЛУ.
Простые ЭВМ типа фон-Неймана можно охарактеризовать триплетом t = (l, l, w).

Возможны композиции и более сложные триплеты.
Например: t B6700-ILLIAC = (1, 1, 48) + (1, 1, 64)
t PDP10-ILLIAC = (2, 1, 36) + [(1, 64, 64) ˅ (1, 128, 32)]
Можно отметить ещё и классификацию Энслоу, в соответствии с которой многопроцессорные системы (МВС) по структуре аппаратных средств делятся на:
МВС с общей или разделенной во времени шиной;
МВС с перекрестной коммутацией;
многоуровневые МВС;
матричные и векторные системы;
ассоциативные МВС;
конвейерные ЭВМ.