

Уточнение структурной электрической схемы многопроцессорной системы
По результатам расчетов определено, что для успешной работы системы в ее составе необходимо иметь:
-
1453 процессорных блоков с производительностью 0.2 Тфлоп/с ;
-
16 накопителей на МЛ или 73 накопителей на МД;
-
общий объем обрабатываемых файлов составляет 18 Тбайт;
-
общий объем ОЗУ системы составляет 3,12 Тбайт
Для балансировки нагрузки в функциональных узлах системы целесообразно организовать из однотипных накопителей две подсистемы ВЗУ: подсистему ВЗУ на НМЛ и подсистему ВЗУ на НМД.
Структурные схемы подсистем ВЗУ на НМЛ и ВЗУ на НМД приведены на рисунке 3 и 4 соответственно.
При конструировании ВЗУ на НМЛ использовано 7 контроллеров ПДП, 14 накопителей на МЛ, емкость подсистемы составляет 16 (15,3)Тбайт.
ВЗУ на НМД содержит 5 контроллеров ПДП и 10 накопителей на МД, емкость подсистемы составляет 4 (2,34) Тбайта.
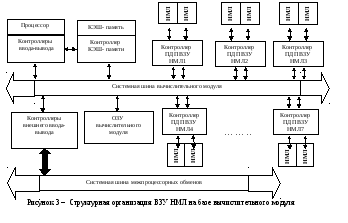
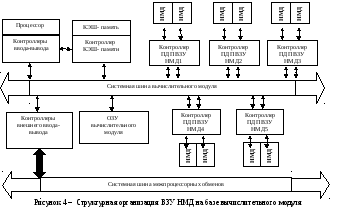
В итоге емкость подсистем внешней памяти составляет 18 Тбайт. Подсистемы спроектированы на базе заданных типов вычислительных модулей, на которые возлагаются функции процессоров баз данных.
При организации вычислений в системе принимается стратегия синхронных вычислений в исполнительных вычислительных модулях. В связи с тем, что используются выделенные вычислительные блоки с функциями баз данных, во-первых, нет необходимости вводить в состав исполнительных модулей подсистемы ВЗУ.
Во-вторых, исполнительные вычислители являются однотипными модулями со следующей структурной организацией.
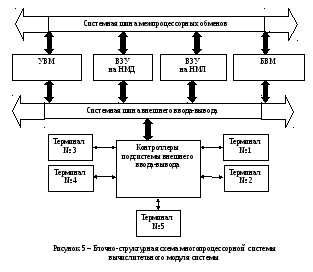
Исходя из принятой концепции построения системы, блочно-структурная организация системы приведена на рисунке 5, где
ПВЗУ НМЛ – подсистема внешней памяти на магнитных лентах;
ПВЗУ НМД – подсистема внешней памяти на магнитных дисках;
УВМ – выделенный управляющий вычислительный модуль;
БВМ – блок исполнительных вычислительных модулей, работающих в синхронном режиме вычислений; количество исполнительных вычислительных модулей – 1453;
ПВВВ – подсистема внешнего ввода-вывода, обеспечивающая взаимодействие системы с терминалами пользователей системы;
СШВВВ – системная шина внешнего ввода-вывода данных;
СШМО – системная шина межпроцессорных обменов между вычислительными модулями системы.
Разработка модели Маркова вычислительного процесса
Концептуально принимается следующая организация вычислительного процесса в многопроцессорной системе с разработанной структурой.
-
Запросы на обслуживания формируются с терминалов пользователей с интенсивностью, заданной по варианту задания.
-
Каждый запрос включает этапы процессорного счета, обращения к файлам данных и программ, вывод результатов счета на терминалы пользователей.
-
Запросы пользователей рассматриваются интегрировано – характеризуются параметрами средней задачи.
-
Каждый запрос на обслуживание первоначально вводится в УВМ, который и определяет порядок использования ресурсов системы для результативного исполнения запроса.
-
Первично файлы данных и программ, необходимых для исполнения запроса, размещены в накопителях подсистем ВЗУ.
-
При поступлении в УВМ запроса на обслуживание, УВМ инициирует загрузку в оперативную память данных исполнительных вычислительных модулей (БВМ) данных и программ из подсистем внешней памяти вычислительных модулей, на базе которых спроектированы ВЗУ НМЛ и ВЗУ НМД. Так как емкость оперативной памяти модулей БВМ не позволяет загрузить весь необходимый объем данных, то следует реализовать механизм свопинга.
-
Результаты расчетов из исполнительных модулей БВМ выводятся на пользовательские терминалы непосредственно из модулей БВМ.
Исходя из рассмотренной концепции для создания Марковской модели вычислительного процесса, можно выделить следующие состояния процесса:
S0: Начальное состояние и конечное – формирование потоков запросов на обслуживание пользователями, прием результатов вычислений;
S1: Прием ПВВВ запросов пользователей на обслуживание и передача этих запросов на СШВВВ; Прием ПВВВ запросов на обслуживание операции ввода-вывода данных из СШВВВ;
S2: Передача запросов СШВВВ адресатам – УВМ, БВМ, ПВВВ, ПВЗУ НМЛ и НМД;
S3: Прием запроса на обслуживание УВМ и выдача запроса на обслуживание адресату;
S4: Прием и передача данных между взаимодействующими вычислительными модулями;
S5: Чтение запрашиваемых данных с НМЛ;
S6: Чтение запрашиваемых данных с НМД;
S7: Прием данных в оперативную память модулей БВМ, выполнение вычислительных операций, формирование запросов на обслуживание адресатам и передача данных из БВМ на СШВВВ.
Граф Маркова, представляющий организацию вычислительного процесса в многопроцессорной системе, показан на рисунке 6.
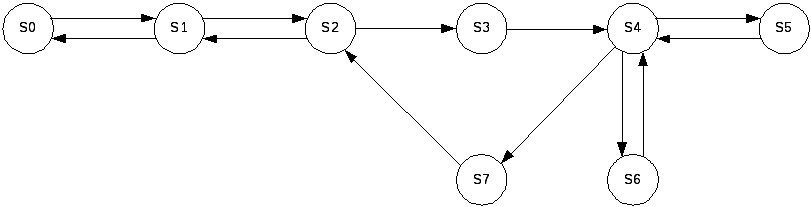
Рисунок 6 – Граф Маркова вычислительного процесса
Тогда количества переходов процессов в системе за один процесс для данного графа будут иметь значения, представленные в таблице.
-
S0
S1
S2
S3
S4
S5
S6
S7
S0
0
1
0
0
0
0
0
0
S1
1
0
1
0
0
0
0
0
S2
0
1
0
1
0
0
0
0
S3
0
0
0
0
1
0
0
0
S4
0
0
0
0
0
Nнмл
Nнмд
Nф
S5
0
0
0
0
Nнмл
0
0
0
S6
0
0
0
0
Nнмд
0
0
0
S7
0
0
Nшвв
0
Nф
0
0
0
Примем, данные, к которым обращается процесс, равномерно распределены по всему объему пространства ВЗУ, занятому файлами.
Nнмл=Nф*Vнмл/Vф – количество обращений к файлам, расположенным на ВЗУ НМЛ в рамках одного процесса,
где Nф – количество обращений к файлам для одного процесса,
Vф – суммарный объем файлов, размещенных на всех ВЗУ.
Nнмд=Nф*Vнмд/Vф – количество обращений к файлам, расположенным на ВЗУ НМД в рамках одного процесса,
Nшвв – количество обращений к тем файлам, которые необходимо выводить в качестве результата пользователям.
Таким образом, матрица вероятностей для одного процесса будет иметь вид, представленный в таблице.
|
|
S0 |
S1 |
S2 |
S3 |
S4 |
S5 |
S6 |
S7 |
|
S0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
S1 |
1/2 |
0 |
1/2 |
0 |
0 |
0 |
0 |
0 |
|
S2 |
0 |
1/2 |
0 |
1/2 |
0 |
0 |
0 |
0 |
|
S3 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
S4 |
0 |
0 |
0 |
0 |
0 |
|
|
|
|
S5 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
S6 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
S7 |
0 |
0 |
|
0 |
|
0 |
0 |
0 |
где N = Nшвв+Nф
Nмо=Nнмл+Nнмд+Nф
Матрица примет следующий вид:

Расчет характеристик функциональных подсистем многопроцессорной системы
Расчет блока ввода-вывода
Для определения задержки на БВВ необходимо рассчитать средний объем заявки передаваемой с терминала при поступлении, а также средний объем результатов, выводимых из системы. Средний объем данных, передаваемый при каждом обращении для каждого потока, вычисляется по формуле:
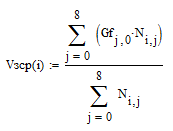
Тогда усреднённое значение объёма передаваемых данных можно вычислить как:
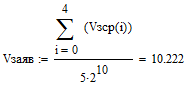 =10,651
=10,651
Как видно из формулы, результат в КБ.
Пусть средний объем выводимых данных определяется количеством обращений к файлам данных, а также средним объемом записей, считываемых из файлов:
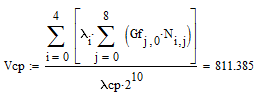 =572
=572
где Gf – средний объем записи j-го файла,
N – среднее число обращений к j-му файлу i-го процесса.
Пусть подсистема внешнего ввода-вывода представляет собой Ethernet адаптер со скоростью обмена 1 Гбит/с . Средняя задержка на БВВ составит:
![]() =7,77*10-3
=7,77*10-3
Пусть внутренние шины вычислительной системы выполнены по стандарту InfiniBand QDR с эквивалентной полосой пропускания в 10 ГГц и эквивалентной разрядностью 32 бита, которая определяет максимальное время задержки распространения сигнала, которое составляет ШВВВ=10-10с для системной шины внешнего ввода вывода, и аналогично СШМО=10-10с для системной шины межмодульного обмена.