


59
Клиент: Не могу получить интерфейс IZ Клиент: Освободить интерфейс IUnknown
CA: Release = 0
CA: Ликвидировать себя
Это та же программа, что и в примере гл. 3, но к ней добавлен подсчет ссылок. К компоненту добавлены реализации AddRef и Release. Единственное отличие в клиенте — добавлены вызовы Release, чтобы обозначить окончание работы с различными интерфейсами. Обратите также внимание, что клиент больше не использует оператор delete. В данном примере клиенту нет надобности в AddRef, так как эту функцию для соответствующих указателей вызывают CreateInstance и QueryInterface.
Когда подсчитывать ссылки
Теперь пора разобраться с тем, когда нужно вести подсчет ссылок. Мы увидим, что иногда можно безопасно опустить пары вызовов AddRef/Release, тем самым оптимизируя код. Сочетая изложенные ранее принципы с новыми навыками оптимизации, мы определим некоторые общие правила подсчета ссылок.
Оптимизация подсчета ссылок
Не так давно мы задавали себе вопрос, нужно ли при копировании указателя интерфейса всякий раз увеличивать счетчик ссылок. Этот вопрос появился при рассмотрении кода, похожего на приведенный ниже:
HRESULT hr;
IUnknown* pIUnknown = CreateInstance();
IX* pIX = NULL;
hr = pIUnknown->QueryInterface(IID_IX, (void**)&pIX);
pIUnknown->Release(); |
|
if (SUCCEEDED(hr)) |
|
{ |
// Скопировать pIX |
IX* pIX2 = pIX; |
|
// Время жизни pIX2 «вложено» во время существования pIX |
|
pIX2->AddRef(); |
// Увеличить счетчик ссылок |
pIX->Fx(); |
// Использовать интерфейс IX |
pIX2->Fx(); |
// Сделать что-нибудь при помощи pIX2 |
pIX2->Release(); |
// Конец работы с pIX2 |
pIX->Release(); |
// Конец работы с IX |
// А также конец работы с компонентом
}
Представленный фрагмент не выгружает компонент до тех пор, пока клиент не освободит pIX. Клиент не освобождает pIX до тех пор, пока не закончит работу как с pIX, так и с pIX2. Поскольку компонент не выгружается, пока не освобожден pIX, постольку он гарантированно остается в памяти на протяжении всей жизни pIX2. Таким образом, нам на самом деле нет необходимости вызывать AddRef и Release для pIX2, поэтому две строки кода, выделенные полужирным шрифтом, можно сократить.
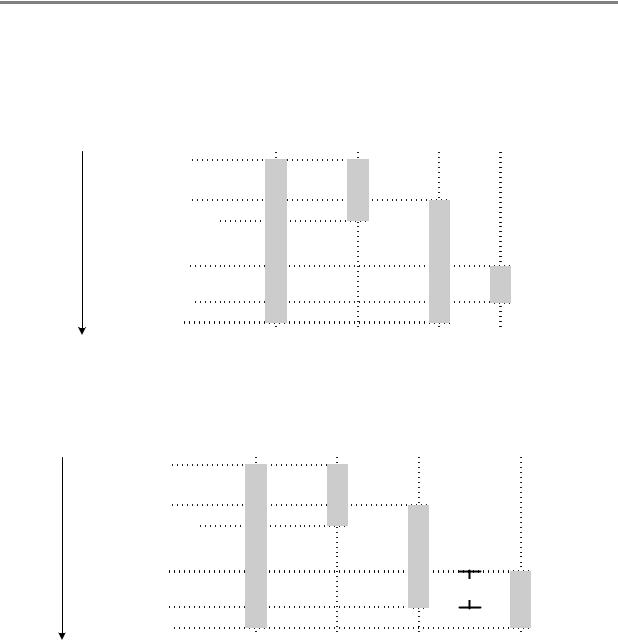
Подсчет ссылок для pIX — это все, что необходимо для удерживания компонента в памяти. Принципиально то, что время жизни pIX2 содержится внутри времени существования pIX. Чтобы подчеркнуть это, я увеличил отступы для строк, где используется pIX2. На рис. 4-2 вложение времени существования pIX и pIX2 показано в виде графика. Здесь столбиками обозначены времена жизни различных интерфейсов и время жизни самого компонента. Ось времени направлена сверху вниз. Операции, оказывающие воздействие на продолжительность жизни, перечислены в левой части рисунка. Горизонтальные линии показывают, как эти операции начинают или завершают период существования интерфейсов.
Из рис. 4-2 легко видеть, что жизни pIX2 начинается после начала жизни pIX и заканчивается до окончания жизни pIX. Таким образом, счетчик ссылок pIX будет сохранять компонент в памяти все время жизни pIX2. Если бы жизнь pIX2 не содержалась внутри жизни pIX, но перекрывалась с нею, то для pIX2 потребовалось бы подсчитывать ссылки. Например, в следующем фрагменте кода жизни pIX2 и pIX перекрываются:
HRESULT hr;
IUnknown* pIUnknown = CreateInstance();
IX* pIX = NULL;
hr = pIUnknown->QueryInterface(IID_IX, (void**)&pIX); pIUnknown->Release();
if (SUCCEEDED(hr))
{
IX* pIX2 = pIX; |
// |
Скопировать pIX |
pIX2->AddRef(); |
// |
Начало жизни pIX2 |
60
pIX->Fx(); |
// Конец жизни |
|
pIX->Release(); |
IX |
|
pIX2->Fx(); |
// Конец жизни |
|
pIX2->Release(); |
pIX2 |
// А также конец работы с компонентом
}
Время
Операция |
Компонент |
IUnknown |
pIX |
pIX2 |
CreateInstance
QueryInterface
pIUnknown->Release()
pIX2 = pIX pIX2->AddRef()
pIX2->Release()
pIX->Release()
Столбиками показаны времена жизни различных элементов
Рис. 4-2 Вложенность времен жизни указателей на интерфейсы. Ссылки для указателя со вложенным временем жизни подсчитывать не требуется.
В этом примере мы обязаны вызывать AddRef для pIX2, так как pIX2 освобождается после освобождения pIX. Графически это представлено на рис. 4-3.
Время
Операция |
Компонент |
IUnknown |
pIX |
pIX2 |
CreateInstance
QueryInterface
pIUnknown->Release()
pIX2 = pIX pIX2->AddRef()
Перекрывание времен жизни
pIX->Release()
pIX2->Release()
Столбиками показаны времена жизни различных элементов
Рис. 4-3 Перекрывание времен жизни указателей на интерфейсы. Здесь надо подсчитывать ссылки на оба интерфейса.
В таких простых примерах легко определить, нужно ли подсчитывать ссылки. Однако достаточно лишь немного приблизиться к реальности, как идентифицировать вложенность времен жизни будет затруднительно. Тем не менее, иногда соотношение времен жизни по-прежнему очевидно. Один такой случай — функции. Для нижеследующего кода очевидно, что время работы foo содержится внутри времени жизни pIX. Таким образом, нет необходимости вызывать AddRef и Release для передаваемых в функцию указателей на интерфейсы.
void foo(IX* pIX2)
{
pIX2->Fx(); // Использование интерфейса IX
}
void main()
{
HRESULT hr;
IUnknown* pIUnknown = CreateInstance(); IX* pIX = NULL;
hr = pIUnknown->QueryInterface(IID_IX, (void**)&pIX); pIUnknown->Release();
if (SUCCEEDED(hr))
61
{
foo(pIX); // Передать pIX процедуре pIX->Release(); // Завершить работу с IX
// А также и с компонентом
}
}
Внутри функции незачем подсчитывать ссылки для указателей на интерфейсы, хранящиеся в локальных переменных. Время жизни локальной переменной совпадает со временем работы функции, т.е. содержится внутри времени жизни вызывающей программы. Однако подсчет ссылок необходим при всяком копировании указателя в глобальную переменную или из нее — глобальная переменная может освободиться в любой момент и в любой функции.
Оптимизация подсчета ссылок основана на определении указателей на интерфейс, чьи времена жизни вложены во времена жизни других ссылок на тот же интерфейс. Искать такие вложения в непростом коде бывает сложно. Однако правила, представленные в следующем разделе, учитывают некоторые типичные случаи, когда пары AddRef / Release можно опустить без большой опасности внести в программу ошибку.
Правила подсчета ссылок
Эти правила объединяют идеи оптимизации из предыдущего раздела с правилами подсчета ссылок, приведенными в начале главы. Читая их, помните, что клиент должен работать с каждым интерфейсом так, как если бы у того был отдельный счетчик ссылок. Следовательно, клиент должен выполнять подсчет ссылок для разных указателей на интерфейсы, хотя бы их времена жизни и были вложенными.
Правило для выходных параметров
Выходной параметр (out parameter) — это параметр функции, в котором вызывающей программе возвращается некоторое значение. Функция устанавливает это значение; первоначальное, заданное вызывающей программой значение не используется. Выходные параметры служат той же цели, что и возвращаемые значения функции. Пример выходного значения параметра — второй параметр функции QueryInterface.
HRESULT QueryInterface(const IID&, void**);
Любая функция, возвращающая указатель на интерфейс через выходной параметр или как свое собственное возвращаемое значение, должна вызывать AddRef для этого указателя. Это то же самое правило, что и «Вызывайте AddRef перед возвратом» из начала главы, но сформулировано оно по-другому. QueryInterface следует этому правилу, вызывая AddRef для возвращаемого ею указателя на интерфейс. Наша функция создания компонентов CreateInstance также следует ему.
Правило для входных параметров
Входной параметр (in parameter) — это параметр, через который функции передается некоторое значение. Функция использует это значение, но не изменяет его и ничего не возвращает в нем вызывающей программе. В С++ такие параметры представляются константами или передаваемыми по значению аргументами функции. Ниже указатель на интерфейс передается как входной параметр:
void foo(IX* pIX)
{
pIX->Fx();
}
Указатель на интерфейс, переданный в функцию, не требует обращений к AddRef и Release, так как время жизни функции всегда вложено во время жизни вызывающей программы. Это правило легко запомнить, если попробовать мысленно подставить код функции в точку ее вызова. Возьмем в качестве примера следующий фрагмент:
IX* pIX = CreateInstance(); |
// Автоматический вызов AddRef |
foo(IX); |
|
pIX->Release(); |
|
В варианте с «развернутым» кодом foo этот фрагмент имел бы вид:
IX* pIX = CreateInstance(); |
// Автоматический вызов AddRef |
// foo(pIX); |
// Подстановка функции foo |
pIX->Fx(); |
|
pIX->Release(); |
|
После установки foo становится очевидно, что время ее жизни вложено во время жизни вызывающей программы.