

Контрольные вопросы и задания
Опишите особенности способа удаленного доступа на основе использования инфраструктуры аналоговых телефонных сетей.
Какие функции выполняют модемы при передаче данных по аналоговым телефонным сетям?
В чем заключаются основные недостатки организации удаленного доступа по обычным телефонным сетям?
Охарактеризуйте цифровые сети, функционирующие на основе технологии ISDN.
Представьте базовые типы внутрисетевых цифровых канал, используемых при реализации технологии ISDN.
Какие цели преследует разработка технологии DSL?
Дайте описание основных подвидов семейства технологий DSL.
Какими параметрами передачи данных характеризуется наиболее популярная технология ADSL?
Дайте описание сетей X.25, их основных компонентов и особенностей информационного обмена в этих сетях.
Перечислите достоинства и недостатки технологии X.25.
Опишите особенности реализации и практического применения технологии Frame Relay.
Охарактеризуйте современную степень распространения технологии Frame Relay, ее достоинства и недостатки.
Дайте описание технологии синхронной цифровой иерархии SDH.
Представьте характерные черты технологии ATM и основные компоненты сети на ее базе.
Какие функции выполняют коммутаторы ATM?
Что представляют собой так называемые «ячейки» в технологии ATM?
Каковы скорости передачи данных по каналам ATM?
13. Организация и характеристики многопроцессорных вычислительных комплексов
13.1. Классификация и архитектура многопроцессорных вычислительных комплексов
Как было отмечено в разделе 1, к многопроцессорным вычислительным комплексам (МВК) будем относить многопроцессорные вычислительные машины (МВМ), часто именуемые «мультипроцессорами», и многомашинные вычислительные системы (ММВС) сосредоточенного типа, а также гибридные схемы МВМ и ММВС.
МВМ с общей памятью, разделяемой всеми процессорами (относительно независимыми друг от друга), строятся по двум основным архитектурным схемам, реализующим соответствующий характер доступа процессоров к общей памяти. Первая из рассматриваемых архитектур МВМ носит название SMP-архитектуры (Symmetric MultiProcessing – симметричная мультипроцессорная). Такие МВМ также относят к классу UMA-мультипроцессоров (Uniform Memory Access – однородный доступ к памяти). Существенным является то, что в UMA-мультипроцессорах каждое слово может быть считано из памяти теоретически с одинаковой скоростью. Вторую из рассматриваемых архитектур МВМ называют ASMP-архитектурой (ASymmetric MultiProcessing – асимметричная мультипроцессорная), но чаще для обозначения таких МВМ применяется термин NUMA-мультипроцессоры (NonUniform Memory Access – неоднородный доступ к памяти).
В основе простейшего схемного решения SMP-архитектуры лежит идея общей шины (рис. 13.1). В такой схеме несколько центральных процессоров (ЦП) и общая память (которая может быть представлена как совокупность нескольких модулей памяти – МП) одновременно используют одну и ту же шину для общения друг с другом. Когда какому-либо процессору необходимо прочитать слово в памяти, он сначала проверяет, свободна ли шина. Если шина свободна, процессор выставляет на нее адрес нужного ему слова, подает управляющие сигналы и ожидает, пока память не выставит нужное слово на шину. Если шина занята, то процессор просто ждет ее освобождения. При небольшом числе процессоров (например, двух или трех) состязание за шину управляемо. При количестве процессоров, исчисляемом несколькими десятками, шина будет перегружена и для каждого отдельного процессора почти все время занята. Именно пропускная способность шины является главной проблемой такой схемы.
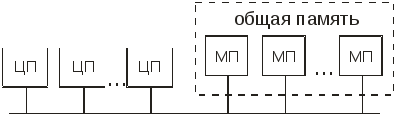
Рис. 13.1. Структурная схема многопроцессорной вычислительной
машины с SMP-архитектурой на базе общей шины
Другое более эффективное схемное решение SMP-архитектуры заключается в использовании так называемых перекрестно-координатных коммутаторов (или коммутаторов типа crossbar – «перекрестные полосы») для соединения процессоров и модулей памяти (рис. 13.2). Перекрестно-координатный коммутатор может быть замкнут или разомкнут в зависимости от того, какой из ЦП должен быть соединен с тем или другим МП. Схема с перекрестно-координатными коммутаторами представляет собой неблокирующую сеть, то есть ни один из ЦП не получает отказа в соединении по причине занятости какого-либо коммутатора (при условии, что сам требующийся МП свободен). Основным недостатком такой схемы является то, что число коммутаторов растет пропорционально квадрату числа ЦП, и при значительном числе ЦП схемное решение становится технически трудно реализуемым.
Эффективное схемное решение UMA-мультипроцессоров при большом числе ЦП реализуется на базе так называемых многоступенчатых коммутаторных сетей. В простейшей из таких сетей – баньян-сети (от названия индийского дерева «баньян») – используются так называемые «баньяновые» коммутаторы с двумя входами и двумя выходами (рис. 13.3.). Сообщения, поступающие по любой из входных линий, могут переключаться на любую выходную линию. Таким образом, любой из ЦП получает доступ к любому из требуемых МП.
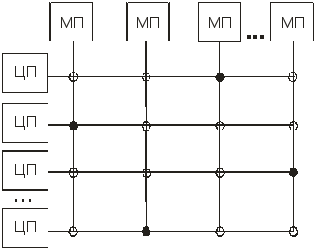
Р
 ис.13.2.
Структурная схема многопроцессорной
вычислительной машины с SMP-архитектурой
на базе координатных переключателей
(коммутаторов):
– разомкнутые переключатели (
)
ис.13.2.
Структурная схема многопроцессорной
вычислительной машины с SMP-архитектурой
на базе координатных переключателей
(коммутаторов):
– разомкнутые переключатели (
)

 –замкнутые
переключатели ( )
–замкнутые
переключатели ( )


Рис.13.3. Структурная схема многопроцессорной вычислительной
машины с SMP-архитектурой на базе коммутируемой сети
В NUMA-мультипроцессорах каждый из ЦП имеет «свою», непосредственно связанную с ним память (локальную память), обращения к которой происходят наиболее часто и с самой высокой скоростью обмена информацией. Кроме того, каждый из ЦП имеет доступ и к любой локальной памяти других процессоров, однако к этим модулям памяти у данного ЦП нет непосредственной связи, а доступ осуществляется через соответствующий процессор (см. рис. 13.4). Поэтому скорость обмена информацией с удаленной («чужой») локальной памятью у каждого из ЦП гораздо ниже, чем со «своей» (этим и объясняется наименовании таких МВМ как мультипроцессоров с неоднородным доступом к памяти). В дополнение к локальным модулям памяти в NUMA-мультипроцессорах может иметься и общая память, к которой все ЦП имеют равноправный однородный доступ.

Рис.13.4. Структурная схема многопроцессорной вычислительной
машины с неоднородным доступом к памяти и шинной архитектурой
ЛП – локальная память, ОП – общая память
Для разгрузки шинного интерфейса и возможности вследствие этого существенного увеличения числа ЦП применяются комбинированные схемы NUMA-мультипроцессоров с иерархическим расположением шин. Например, в представленной на рис. 13.5 двухуровневой схеме, NUMA-мультипроцессор состоит из нескольких МВМ, имеющих SMP-архитектуру, локальные шины которых связаны общей шиной. Возможны более сложные схемные комбинации построения NUMA-мультипроцессоров с разными вариантами SMP-архитектур и с большим числом уровней шин.
В NUMA-мультипроцессорах также находят применение схемы с непосредственной связью процессоров (при небольшом их числе) и схемы с кольцевой последовательной связью процессоров (рис. 13.6, 13.7).

Рис.13.5. Структурная схема многопроцессорной вычислительной
машины с неоднородным доступом к памяти и двумя уровнями шин

Рис. 13.6. Структурная схема многопроцессорной вычислительной машиныс неоднородным доступом к памяти и непосредственной
связью процессоров
Многомашинные вычислительные системы сосредоточенного типа (см. подраздел 1.2) относят к классу MPP-архитектуры (Massive Parallel Processing – «массово-параллельные системы» или «массивно-параллельные системы»). Переход от архитектуры SMP к MPP позволил практически бесконечно масштабировать систему машин. Такой путь оказался технически и экономически более эффективным, чем увеличение числа процессоров в архитектурах SMP и ASMP. Изначально ММВС с MPP-архитектурой строились как уникальные узко специализированные системы, в которых независимые специализированные вычислительные модули объединялись специализированными каналами связи, причем те и другие создавались под конкретную реализацию системы и ни в каких других целях фактически не могли быть использованы. Такое положение дел привело к появлению идеи так называемой кластеризации ММВС.
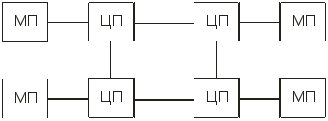
Рис. 13.7 Структурная схема многопроцессорной вычислительной
машины с неоднородным доступом к памяти и кольцевой последовательной связью процессоров
Кластерная ММВС или просто кластер (от claster – гроздь, пучок) представляет собой многопроцессорный вычислительный комплекс, который построен на базе стандартных вычислительных модулей, соединенных высокоскоростной коммуникационно-коммутационной средой (ККС). Основная идея создания кластерных систем заключается в использовании достаточно развитых и эффективных методов и технологий локальных вычислительных сетей (распределенных систем!) применительно к MPP-системам. Кластеризация получила свое практическое воплощение в середине 1990-х годов, когда благодаря оснащению компьютеров высокоскоростной шиной PCI и появлению относительно дешевой, но быстродействующей сетевой технологии Fast Ethernet, стало реальным построение кластеров, не уступающих по своим коммуникационным характеристикам специализированным MPP-системам того времени. Это означало, что высокопроизводительную MPP-систему можно было создать из стандартных серийно выпускаемых компьютеров и серийных коммуникационных программно-аппаратных средств, причем такая система может обходиться дешевле специализированных MPP-систем в сотни раз. Родственность локальных сетей и кластерных систем иногда прослеживается и в терминологии: встречается наименование кластерных систем (систем сосредоточенного типа) как COWS (Clusters of WorkStations – «гроздья рабочих станций»), а вычислительных сетей (систем распределенного типа) – как NOWS (Network of WorkStations– «сети рабочих станций»).
Современная кластерная система состоит из вычислительных модулей (ВМод) на базе стандартных аппаратных компонентов (процессоров, модулей памяти), соединенных высокоскоростной ККС, а также, как правило, вспомогательной и управляющей сетями (рис. 13.8).

Рис.13.8. Структурная схема кластерной конфигурации многомашинных вычислительных систем
В качестве элементарных вычислительных модулей кластера могут использоваться как однопроцессорные ВМ, так и архитектуры типа SMP (чаще – двухпроцессорные), ASMP или МРР. Желательным является то, чтобы каждый модуль мог в состоянии функционировать самостоятельно и отдельно от кластера. Состав и производительность вычислительных модулей могут быть разными в рамках одного кластера, однако чаще строятся однородные кластеры. С помощью вспомогательной сети обычно решается задача эффективного доступа модулей к данным (например, к массиву внешних дисковых ЗУ). Управляющая сеть отвечает за распределение задач между модулями кластера и управление параллельно протекающими процессами. Она также используется для сетевой загрузки операционных систем модулей и управления модулями на уровне операционной системы, в том числе мониторинга температурного режима и других параметров работы модулей.
Показательными характеристиками кластерных систем являются наращиваемая масштабируемость (кластер строится так, что его можно наращивать постепенно путем добавления новых модулей), абсолютная масштабируемость (возможность создания структур, практически неограниченных по числу модулей), высокий коэффициент готовности (отказ одного или нескольких модулей кластера не приводит к потере его работоспособности, поскольку каждый из модулей является самостоятельной машиной или системой), экономное соотношение цена/производительность (кластер компонуется из стандартных серийно выпускаемых, а поэтому относительно дешевых компонентов).
Модули ММВС могут составлять различные по топологии схемы взаимного соединения. Простейшими вариантами таких схем являются классические звездообразные и кольцевые топологии. Небольшие системы часто строятся по звездообразной схеме с использованием центрального коммутатора. Альтернативная схема представляет собой кольцо, в котором каждый узел соединяется с двумя соседними узлами без помощи коммутаторов. Более сложным вариантом является двумерная топология, представляющая собой решетку или сеть. Такая схема обладает высокой степенью регулярности и легко масштабируется до достаточно больших размеров. Самый длинный путь между двумя узлами называют диаметром решетки. Диаметр решетки увеличивается пропорционально квадратному корню от общего числа узлов решетки. Один из вариантов топологии решетки, у которой крайние узлы соединены друг с другом, называется «двойным тором». Такая схема обладает большей устойчивостью к повреждениям и сбоям, чем простая решетка, к тому же дополнительные линии связи снижают ее диаметр. Регулярную трехмерную топологию представляет собой топология «куб». Из двух трехмерных кубов с помощью соединений соответствующих узлов может быть построен четырехмерный куб. Дальнейшее развитие этой идеи позволяет создавать пятимерные кубы, шестимерные кубы и т. д. Созданный таким образом N-мерный куб называется «гиперкубом». Подобная топология используется во многих многомашинных системах, реализующих параллельные вычисления. Это связано с тем, что диаметр в таких системах растет линейно в зависимости от размерности, в результате чего схема обладает низкими временными задержками. Платой за небольшой диаметр гиперкуба является большое число ответвлений на каждом узле, пропорциональное размерности гиперкуба, и, таким образом, значительное количество связей между узлами и, соответственно, их повышенная суммарная стоимость.