

Метод Квайна
Для этого метода
исходная булева функция должна быть
представлена в СДНФ. Если эта функция
представлена в произвольной ДНФ, то ее
с помощью операции развертывания,
заключающейся в умножении некоторых
членов на выражение вида
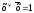 ,
приводят к СДНФ.
,
приводят к СДНФ.
Метод Квайна основан на последовательном применении к парам дизъюнктивных членов операций склеивания и элементарного поглощения.
Операция склеивания
основана на справедливости тождества
 .
Операция элементарного поглощения —
на справедливости тождествх1х1х2
= х1
и х1(х1х2)
= х1.
.
Операция элементарного поглощения —
на справедливости тождествх1х1х2
= х1
и х1(х1х2)
= х1.
Вначале в СДНФ исходной булевой функции проводят все возможные операции склеивания дизъюнктивных членов — конъюнкций ранга n, где n — число аргументов функции. В результате склеивания получим конъюнкции n – 1 ранга. После выполнения операции поглощения с конъюнкциями n – 1 ранга осуществляют все возможные операции склеивания конъюнкций n – 1 ранга. Затем проводят операции поглощения с конъюнкциями n – 2 ранга и вновь выполняют операции склеивания и т.д.
Пример 4. Найти сокращенную ДНФ булевой функции
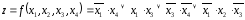
1) Используя операцию
развертывания, представим исходную
функцию в СДНФ. Для этого первуй член
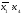 умножим на
умножим на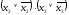 ,
второй член
,
второй член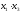 умножим на
умножим на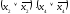 ,
третий член
,
третий член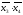 умножим на
умножим на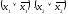 ,
а четвертый член
,
а четвертый член умножим на
умножим на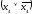 .
В результате получим СДНФ:
.
В результате получим СДНФ:
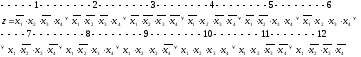
2) Пронумеруем все дизъюнктивные члены.
3) Выполним все возможные операции склеивания дизъюнктивных членов в такой последовательности:
первый член со всеми остальными,
второй член с остальными, кроме первого,
третий член с остальными, кроме первого и второго, и т.д.
В результате проведенных операций склеивания и поглощения получим ДНФ заданной функции в форме

Пронумеровав все члены выражения, полученного на предыдущем этапе, выполним все возможные операции склеивания конъюнкций третьего ранга в той же последовательности, что и ранее. В результате проведенных операций склеивания и поглощения исходная функция примет вид
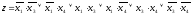 .
.
1.3. Метод импликантных таблиц
Метод импликантных таблиц является одним из методов нахождения тупиковых и минимальных ДНФ по сокращенным ДНФ. Импликантная таблица представляет собой прямоугольную таблицу, столбцы которой соответствуют конституентам единицы исходной булевой функции, а строки — простым импликантам. В случае если простую импликанту можно получить из конституенты единицы вычеркиванием некоторых букв, то говорят, что импликанта накрывает (покрывает) конституенту. В этом случае клетка импликантной таблицы, соответствующая импликанте и конституенте, отмечается специальным знаком (например, звездочкой).
Реляційні бази даних
Реляционные системы
Реляционная БД – основной тип современных баз данных. Состоит из таблиц, между которыми могут существовать связи по ключевым значениям.
Таблица базы данных – регулярная структура, которая состоит из однотипных строк (записей), разбитых на столбцы (поля).
Реляционные системы далеко не сразу получили широкое распространение. В то время как основные теоретические результаты в этой области были получены еще в 70-х годах ХХ века и тогда же появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако постепенное накопление методов и алгоритмов организации реляционных БД и управления ими привели к тому, что уже в середине 80-х годов ХХ века реляционные системы практически вытеснили с мирового рынка ранние СУБД.
Реляционная модель данных основывается на математических принципах, вытекающих непосредственно из теории множеств и логики предикатов. Эти принципы впервые были применены в области моделирования данных в конце 60-х гг. американским специалистом доктором Е.Ф.Коддом ( в то время работавшим в компании IBM), а впервые опубликованы в 1970 г. в статье «Реляционная модель данных для больших разделяемых банков данных».
Доктор Кодд определил правила реляционной модели (которые называют 12 правилами Кодда).
Реляционная СУБД должна быть способна полностью управлять базой данных через ее реляционные возможности:
Информационное правило – вся информация в реляционной БД (включая имена таблиц и столбцов) должна определяться строго как значения в таблицах.
Гарантированный доступ – любое значение в реляционной БД должно быть гарантированно доступно для использования через комбинацию имени таблицы, значения первичного ключа и имени столбца
Поддержка пустых значений – СУБД должна уметь работать с пустыми значениями (неизвестными или неиспользованными значениями), в отличие от значений по умолчанию и независимо для любых доменов.
Онлайновый реляционный каталог – описание БД и ее содержания должны быть представлены на логическом уровне как таблицы, к которым можно применять запросы, используя язык базы данных.
Исчерпывающий язык управления данными – по крайней мере, один из поддерживаемых языков должен иметь четко определенный синтаксис и быть всеобъемлющим. Он должен поддерживать описание структуры данных и манипулирование ими, правила целостности, авторизацию и транзакции.
Правило обновления представлений – все представления, теоретически обновляемые, могут быть обновлены через систему.
Вставка, обновление и удаление - СУБД поддерживает не только запрос на отбор данных, но и вставку, обновление и удаление.
Физическая независимость данных – на программы-приложения и специальные программы логически не влияют изменения физических методов доступа к данным и структур хранилищ данных.
Логическая независимость данных – на программы-приложения и специальные программы логически не влияют, в пределах разумного, изменения структур таблиц.
Независимость целостности – язык БД должен быть способен определять правила целостности. Они должны сохраняться в онлайновом справочнике, и не должно существовать способа их обойти.
Независимость распределения – на программы-приложения и специальные программы логически не влияет, первый раз используются данные или повторно.
Неподрывность – невозможность обойти правила целостности, определенные через язык базы данных, использованием языков низкого уровня
Кодд предложил применение реляционной алгебры в СУБД, для расчленения данных в связанные наборы. Он организовал свою систему БД вокруг концепции, основанной на наборах данных: в реляционной модели данные разбиваются на наборы, которые составляют табличную структуру. Эта структура таблиц состоит из индивидуальных элементов данных, называемых полями. Одиночный набор или группа полей определяется как запись.
Модель данных (концептуальное описание предметной области) - самый абстрактный уровень проектирования баз данных.
С точки зрения теории реляционных БД, основные принципы реляционной модели на концептуальном уровне можно сформулировать следующим образом:
все данные представляются в виде упорядоченной структуры, определенной в виде строк и столбцов и называемой отношением;
все значения являются скалярами. Это означает, что для любой строки и столбца любого отношения существует одно и только одно значение;
все операции выполняются над целым отношением, и результатом их выполнения также является целое отношение. Этот принцип называется замыканием.
Представлення цілих чисел зі знаком. Двійкові коди чисел
Целые числа со знаком обычно занимают в памяти компьютера один, два или четыре байта, при этом самый левый (старший) разряд содержит информацию о знаке числа. Знак «плюс (+)» кодируется нулем, а «минус (-)» — единицей.
Рассмотрим особенности записи целых чисел со знаком на примере однобайтового формата, при котором для знака отводится один разряд, а для цифр абсолютной величины – семь разрядов.
В ЭВМ применяются три формы записи (кодирования) целых чисел со знаком: прямой код, обратный код, дополнительный код. Последние две формы применяются особенно широко, так как позволяют упростить конструкцию арифметико-логического устройства компьютера путем замены разнообразных арифметических операций операцией сложения.
Положительные числа в прямом, обратном и дополнительном кодах изображаются одинаково — двоичными кодами с цифрой 0 в знаковом разряде. Например:

Отрицательные числа в прямом, обратном и дополнительном кодах имеют разное изображение.
1. Прямой код отрицательного числа: в знаковый разряд помещается цифра 1, а в разряды цифровой части числа — двоичный код его абсолютной величины. Например:
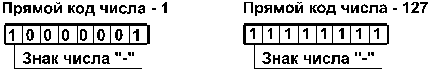
2. Обратный код отрицательного числа: получается инвертированием всех цифр двоичного кода абсолютной величины числа, включая разряд знака: нули заменяются единицами, а единицы — нулями. Например:

3. Дополнительный код отрицательного числа: получается образованием обратного кода с последующим прибавлением единицы к его младшему разряду. Например:
![]()
Обычно отрицательные десятичные числа при вводе в машину автоматически преобразуются в обратный или дополнительный двоичный код и в таком виде хранятся, перемещаются и участвуют в операциях. При выводе таких чисел из машины происходит обратное преобразование в отрицательные десятичные числа.
В большинстве компьютеров операция вычитания не используется. Вместо нее производится сложение уменьшаемого с обратным или дополнительным кодом вычитаемого. Это позволяет существенно упростить конструкцию АЛУ.