

3.2.5. Модели ранжирования
Модели ранжирования предназначены для того, чтобы упорядочить полученные ссылки с множества сайтов как внутри одного языкового множества, так и для многомерного языкового множества.
Рассмотрим модель поиска информации сразу по нескольким языкам.
Эта модель применяется при опросе Интернета в разных языковых сегментах одновременно. В результате получается множество ссылок на разноязычные документы djy, после чего проводится отсев дублирующихся ссылок и вычисляется вес ссылки на документ.
Таким образом, результат каждого запроса может быть представлен в виде r-мерного ранжированного вектора:
![]() (3.5)
(3.5)
 (3.6)
(3.6)
где i– номер опрашиваемого сайта (i = 1, ...,n);n –количество опрашиваемых сайтов;j– номер ссылки из множества ссылок, выданных всеми опрошенными поисковыми сайтами, без дублей (j = 1, ..., m);m – количество ссылок без повторений; y – номер языкового множества (y = 1, ..., r); r –количество опрашиваемых языковых множеств;RangDocjy– получаемый рангj-й страницыk-го языкового множества;RangSiteiy– рангi-го сайта в текущей предметной областиk-го языкового множества на данный момент;RangSiteDociy– ранг ссылки на страницу внутриi-го поискового сайтаk-го языкового множества.
 (3.7)
(3.7)
здесь Dociy= 1, еслиi-й сайт дал ссылку на данную страницу, и 0, если ссылка наi-м сайте отсутствует.
Ранг сайта по каждой предметной области определятся по следующему алгоритму:
при первом проходе RangSiteiy= 0;
в процессе опроса каждого сайта ранг изменяет свое значениепо формуле
RangSiteiy = RangSiteiy + (DocRelTotaliy –
– DocNotRelTotaliy) /DocTotaliy, (3.8)
где DocRelTotaliy – количество релевантных документов, выданных i-м поисковым сайтом; DocNotRelTotaliy – количество нерелевантных документов, выданных i-м поисковым сайтом; DocTotaliy – общее количество документов:
DocTotaliy = DocRelTotaliy + DocNotRelTotaliy. (3.9)
Ранг ссылки на страницу внутри множества ссылок, выданных каждым конкретным сайтом, определяется по формуле
RangSiteDociy = NumDociy – DocTotaliy. (3.10)
Если поиск проводится только в пределах одного языкового множества, то в предложенной модели ранжирования необходимо принять y= 1.
Если ввести один индекс w, отвечающий за предметную область, то полученная модель будет производить поиск и ранжирование сразу для нескольких предметных областей. При этом сумма всех неповторяющихся ссылок всех опрашиваемых предметных областей должна быть меньше или равна общей сумме ссылок без повторений, что связано с пересечением предметных областей или наличием смежных предметных областей.
Необходимо отметить, что в предлагаемой модели ранжирования все ранги должны быть не меньше единицы [6; 7; 16].
3.2.6. Модель определения релевантности
В рамках этой модели каждому терму (словоформе) ti в документеdj(и запросеq) сопоставляется некоторый неотрицательный весwij (wi для запроса на один поисковый сайт). Таким образом, каждый документ и запрос может быть представлен в видеk-мерного вектора:
![]() (3.11)
(3.11)
где k– общее количество различных термов во всех документах.
Согласно векторной модели [16], близость документа djк запросуqоценивается как корреляция между векторами их описаний. Эта корреляция может быть вычислена, например, как скалярное произведение соответствующих векторов описаний.
Веса термов можно вычислять различными способами [20; 27; 90].
Один из возможных вариантов – это применение в качестве веса терма wij в документе dj нормализованной частоты его использования freqijв рамках данного документа:
 (3.12)
(3.12)
При поиске с использованием мультилингвистических частотных словарей для вычислений целесообразнее применять частотную характеристику терма из словаря freqDicj.
wij = freqDicij. (3.13)
Здесь freqDic1j, …, freqDicnj равны, и это связано с тем, что веса терминов берутся из словаря и для всех терминов в документе они равны весу из словаря.
Однако такой подход не учитывает, насколько часто данный терм используется в других документах коллекции, т. е. дискриминационнуюсилу терма. Поэтому в случае доступности статистики использований термов по коллекции лучше работает другая схема вычисления весов:
![]() (3.14)
(3.14)
где ni – число документов, в которых используется терм tj; N – общее число документов в коллекции. С учетом частотности словоформ выражение (3.14) может быть представлено в виде
![]() (3.15)
(3.15)
Предложенный алгоритм хорошо показал себя на этапе формирования мультилингвистического частотного словаря, однако после того, как этот словарь уже составлен и возникает необходимость в его актуализации или обновлении, в качестве весового коэффициента лучше использоватьвесовой коэффициент каждого терма из частотного мультилингвистического словаря. Для этого при анализе текстов необходимо сравнивать полученный вес терма с относительной частотой данного терма в частотном словаре. Таким образом, будет получено два вектора, состоящих из весов, только в одном векторе будут веса термов из текста, а в другом – веса термов из словаря:
![]() (3.16)
(3.16)
![]() (3.17)
(3.17)
где
wdocij = wij·gij; (3.18)
wdicl= frecDicl ·gl; (3.19)

 (3.20)
(3.20)
здесь i– номер терма вj-м документе (i=1, …,k);l – номер терма в частотном словаре (l = 1, …, kd);wdocij – весi-го терма вj-м документе;wdicl – весl-го терма в частотном словаре;gij и gl– признаки включения терма в вектор для определения релевантности документа: если терм нерелевантен предметной области, то признак равен нулю, в противном случае он равен единице.
Векторы wdocij и wdicl имеют разные размерности, что связано с ограничением словаря, в котором содержатся только релевантные термины. Следовательно,glравен нулю только в случае устаревания какого-то термина настолько, что он полностью вышел из употребления.
В процессе составления векторов wdocij и wdiclнеобходимо привести их к одной размерности и упорядочить веса по принадлежности к одному терму, после чего необходимо составить векторc:
![]() (3.21)
(3.21)
где e – размерность векторов весов;
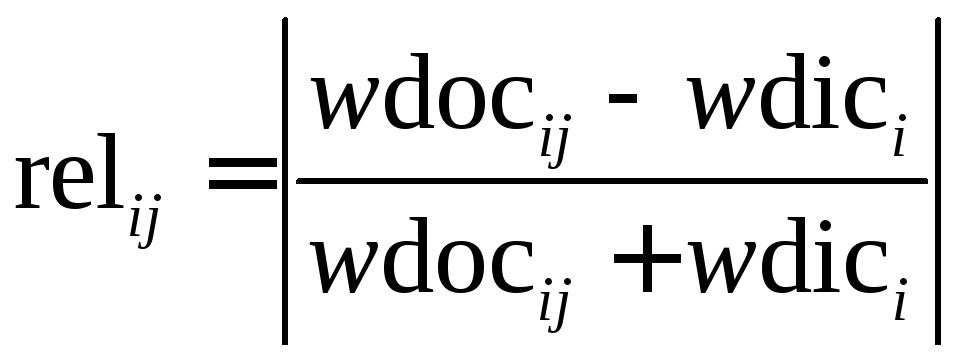 (3.22)
(3.22)
при i = 1, ..., e. В идеалеrelij должен быть равен единице.
В случае если
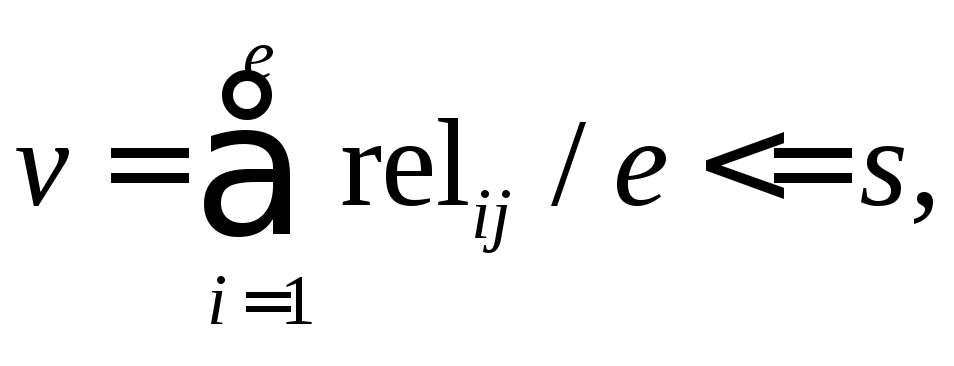 (3.23)
(3.23)
где s– пороговая величина, принимается решение о релевантности документаdj предметной области. В идеалеvстремится к нулю [5; 37; 101].
В заключение следует отметить, что предложенный алгоритм определения релевантности эффективно работает как на этапе формирования мультилингвистического частотного словаря, так и после его составлеия, когда возникает необходимость в его актуализации или обновлении.