

1.2. Типовые архитектуры систем поддержки
Принятия решений
На сегодняшний день можно выделить четыре наиболее популярных типа архитектур систем поддержки принятия решений:
функциональная СППР;
независимые витрины данных;
двухуровневое хранилище данных;
трехуровневое хранилище данных.
Функциональная СППР (рис. 1.1) является наиболее простой с архитектурной точки зрения [6]. Такие системы часто встречаются на практике, в особенности на предприятиях с невысоким уровнем аналитической культуры и недостаточно развитой информационной инфраструктурой [80; 82].
Такая СППР имеет следующие преимущества:
быстрое внедрение за счет отсутствия этапа перегрузки данных в специализированную систему;
минимальные затраты за счет использования одной платформы.
Однако для функциональной СППР характерны следующие недостатки:
ограниченный круг вопросов, на которые может ответить система;
очень низкое качество данных с точки зрения их роли в поддержке принятия стратегических решений в силу отсутствия этапа очистки данных;
большая нагрузка на оперативную систему, что весьма нежелательно.


Рис. 1.1. Функциональная СППР
Отличительной чертой функциональной СППР является то, что анализ осуществляется с использованием данных из оперативных систем.
Независимые витрины данных (рис. 1.2) часто используются на крупныхпредприятиях с большим количеством независимых подразделений, зачастую имеющих свои собственные отделы информационных технологий [9; 82].
К преимуществам подобных СППР можно отнести следующие:
витрины данных внедряются достаточно быстро;
витрины проектируются для ответов на конкретный ряд вопросов;
данные в витрине оптимизированы для использования определенными группами пользователей, что облегчает процедуры их наполнения, а также способствует повышению производительности.
Среди недостатков выделим следующие:
одни и те же данные хранятся в различных витринах данных. Это приводит к дублированию данных и, как следствие, к увеличению расходов на хранение и потенциальным проблемам, связанным с поддержанием непротиворечивости данных;
процесс наполнения витрин данных при большом количестве источников данных может быть потенциально очень сложным;
данные не консолидируются на уровне предприятия, таким образом единая картина бизнеса отсутствует.


Рис. 1.2. Независимые витрины данных
Двухуровневое хранилище данных(рис. 1.3) строится централизованно для предоставления информации в рамках компании. Для поддержки такой архитектуры необходима выделенная команда профессионалов в области хранилищ данных [82].
Системы, основанные на двухуровневом хранилище данных, обладают рядом существенных преимуществ:
данные хранятся в единственном экземпляре;
затраты на хранение данных минимальны;
отсутствуют проблемы, связанные с синхронизацией нескольких копий данных;
данные консолидируются на уровне предприятия, что позволяет иметь единую картину бизнеса.
Недостатки этих систем состоят в том, что данные для поддержки потребностей отдельных пользователей или групп пользователей не структурируются; возможны проблемы с производительностью системы, а также трудности с разграничением прав пользователей на доступ к данным.

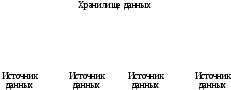
Рис. 1.3. Двухуровневое хранилище данных
Трехуровневое хранилище данных(рис. 1.4) является единым централизованным источником корпоративной информации. Витрины данныхпредставляют подмножества данных из хранилища, организованные для решениязадач отдельных подразделений компании. Конечные пользователи имеют возможность доступа к данным хранилища в случае если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса [82].
Преимущества систем на основе трехуровневого хранилища данных таковы:
создание и наполнение витрин данных упрощено, поскольку наполнение происходит из единого стандартизованного надежного источника очищенных нормализованных данных;
витрины данных синхронизированы и совместимы с корпоративным представлением, благодаря чему существует возможность сравнительно легкого расширения хранилища и добавления новых витрин данных;
гарантированная операбельность.
К числу недостатков можно отнести:
избыточность данных, ведущую к росту требований на хранение данных;
необходимость согласованности с принятой архитектурой многих областей с потенциально различными требованиями (например, скорость внедрения иногда конкурирует с требованиями следовать архитектурному подходу и т. д.).


Рис. 1.4. Трехуровневое хранилище данных
Таким образом, мы представили основные варианты архитектур систем поддержки принятия решений. Перейдем к рассмотрению существующих корпоративных систем с поддержкой технологии принятия решений.