

Министерство образования и науки Российской Федерации
Федеральное агенство по образованию
Российский государственный профессионально-педагогический университет
Кафедра общей физики
4082
Математическая обработка результатов
физического эксперимента
Екатеринбург
2005
УДК 531
Учебно-методическая разработка
"Математическая обработка результатов физического эксперимента. Российский государственный проф.-пед. университет. Екатеринбург, 2005. 17с.
Составитель: доцент Литовский Владимир Васильевич,
Рецензент: д.ф.м.н., проф. П.С.Попель
В разработке приведены основные сведения по теории погрешностей для физического практикума. Особое внимание уделено оценкам случайных и систематических погрешностей. Отмечены отличительные особенности нахождения погрешностей электроизмерительных приборов. Приведены примеры округления численных значений физических величин.
Рассмотрено на заседании кафедры физики Протокол № 2 от 30.09.04
Заведующий кафедрой ОФ А.С.Борухович
Рекомендовано к печати методической комиссией ЭЭФ ИПИ Протокол №
от 21.03.2005 г.
Председатель методической комиссии В.Ф.Журавлев
Российский государственный
профессионально-педагогический
университет, 2005
Измерения. Классификация погрешностей измерений
Одним из способов нахождения значения физической величины является ее измерение, т.е. опытное определение с помощью специальных технических средств - приборов и установок. Не все физические величины можно определить непосредственно прямыми измерениями, чаще всего искомое значение интересующей величины находят вычислением на основании известных зависимостей между ней и другими физическими величинами, определяемыми непосредственно из эксперимента. Соответственно, такие измерения называют прямыми и косвенными.
Следует учитывать, что никакое измерение не может быть выполнено абсолютно точно. Его результат содержит некоторую погрешность.
Погрешностью (абсолютной погрешностью) измерения называется разность
x-x0 между результатом измерения x и истинным значением измеряемой величины x0.
Относительная погрешность у – это отношение абсолютной погрешности
x-x0 к истинному значению x0 измеряемой величины: γ=(x-x0)/x0
Истинное значение измеряемой величины обычно неизвестно, потому в задачу измерении входит не только нахождение самой величины, но и оценка допущенной при измерении погрешности. .Для решения этой проблемы необходимо знать основные свойства погрешностей и методы их вычислений. Погрешность измерений можно разделить на три группы: промахи, случайные и систематические.
Промахи (грубые ошибки) возникают вследствие нарушения основных условий измерений. Например, при плохом освещении, регистрируя показания прибора вместо цифры 3 записали 8. Внешним признаком промаха является его резкое отличие по величине от остальных измерений. Такой результат необходимо отбросить, а измерение повторить.
Вычисление случайных и систематических погрешностей требует использование математических методов. Остановимся на них подробнее.
Случайные погрешности.
Случайными погрешностями называются погрешности, обусловленные неодинаковым действием совокупности физических факторов на измеряемую величину при повторении опытов.
Таким образом, наиболее существенным отличительным свойством случайной погрешности является непредсказуемость ее поведения при каждом повторном измерении. Так, при многократном определении линейного размера тела с помощью штангенциркуля из-за не идеальности его формы, поверхности, неодинаковой степени сжатия, неточности фиксации положения тела и т.д. результаты измерений будут отличаться друг от друга случайным образом. Следует отметить, что случайные величины возникают вследствие самых различных причин, результаты, действия которых столь малы, что их нельзя учесть по отдельности. Поэтому их рассматривают как суммарный эффект множества физических факторов и учитывают с помощью методов теории вероятностей.
Ясно, что при многократном повторении опыта экспериментатора интересует наиболее вероятное значение определяемой величины. Если каждое из полученных значений случайной величины xi повторяется один раз, то относительная частота Рi (вероятность) его появления определяется как (1/N) и за наиболее вероятное значение
![]() (1)
(1)
вполне можно принять среднеарифметическое значение
![]() (2)
(2)
вытекающее из выражения (1). При различной частоте выпадения случайной величины xi Pi=(mi/N) необходимо пользоватьсяобщей формулой (1) (mi - число повторений cлучайной величины xi ).
Если построить зависимость числа попаданий ΔN случайной величины xi в определенный интервал dx отрезка [а, б] при достаточно большом числе измерений N, то отношение ΔN/N будет определять относительную частоту (вероятность) dP(x) попаданий указанной величины х в интервал dx :
![]()
Для
оценки случайной погрешности важно
знать значение
вероятностей
dP(x)
в пределах всего отрезка [а,б],
т.е. функцию
распределения
вероятностей ∫(x),
определяемую соотношением
![]() или
или
![]() и
называемую иначе плотностью вероятности
(по аналогии с понятием плотности
известным из механики).
и
называемую иначе плотностью вероятности
(по аналогии с понятием плотности
известным из механики).
Эта функция в общем случае имеет сложный вид и удовлетворяет двум очевидным требованиям:
1)![]()
2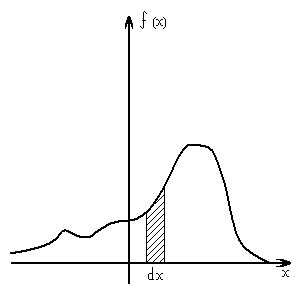 )
)![]()
П
Рис.1![]() определяет вероятность
появления случайной величины
в интервале dx.
определяет вероятность
появления случайной величины
в интервале dx.
Функция распределения вероятности позволяет определить две
основные характеристики распределения случайной величины – ее среднее значение (математическое ожидание) и среднеквадратичное отклонение (или стандарт).
Среднее значение (математическое ожидание) случайной величины определяется естественным образом выражением
![]() (3)
(3)
которое предполагает "взвешивание" каждой из величин х бесконечного интервала соответствующей вероятностью dР(х), так, что суммирование "взвешенных" значений х по всему интервалу обеспечивает средневзвешенное значение ∫(x) . При переходе к дискретному (от латинского discretus - разделенный, прерывистый) числу измерений (x1, x2, …, xN) функцию распределения и соответственно dP(х) нужно считать отличными от нуля только в этих точках (∫(xi) P(xi)), и интеграл заменить суммой т.е.
![]()
Так, что получаем уже известное выражение x0.
В частности, если ∫(х) отлична от нуля в точках x1=1, x2=2, x3=3, x4=4, x5=5, а соответствующие им вероятности P1=0,025; P2=0,05; P3=0,085; P4=0,1; P5=0,125, то средневзвешенным окажется x0=3=x3
![]()
Для
характеристики распределения
![]() случайных
величин
необходимо также определить величину,
являющуюся мерой их разбросанности
возле среднего значения. Если за такую
меру принять сумму разностей между
каждой из случайных величин xi
и их средним
значением, умноженных на соответствующие
вероятности, то при
значительном расширении интервала xi
будет стремиться
к нулю и, следовательно, не
даст
желаемого результата.
случайных
величин
необходимо также определить величину,
являющуюся мерой их разбросанности
возле среднего значения. Если за такую
меру принять сумму разностей между
каждой из случайных величин xi
и их средним
значением, умноженных на соответствующие
вероятности, то при
значительном расширении интервала xi
будет стремиться
к нулю и, следовательно, не
даст
желаемого результата.
Например, для указанных выше хi и Рi имеем:
![]()
Наиболее разумной оценкой такого разброса может служить сумма квадратов разностей (xi-x0)2 с учетом вероятности реализации каждой из них. При непрерывном распределении случайных величин вдоль бесконечного интервала эту меру определяют следующим образом
![]() (4)
(4)
D(x) - называют дисперсией случайной величины х. Сопоставляя выражение (4) с формулой (3), легко понять, что дисперсия определяет средневзвешенное значение (x-x0)2 - их возможных разностей (x-x0)2, умноженных на соответственные вероятности.
Обращаясь к приведенному выше примеру, имеем:
![]()
т.е. D(x)≠0 и, следовательно, может быть принята за меру определения погрешностей случайных величин.
В действительности, удобнее всего пользоваться среднеквадрати-ческим отклонением случайной величины х, определяемым как корень квадратный от дисперсии этой величины,
![]() (5)
(5)
Из
выражения (5) видно, что
![]() в
точности совпадает по размерности
с исследуемой случайной величиной х
и, следовательно, вполне
может быть принята за меру погрешности
ее определения.
в
точности совпадает по размерности
с исследуемой случайной величиной х
и, следовательно, вполне
может быть принята за меру погрешности
ее определения.
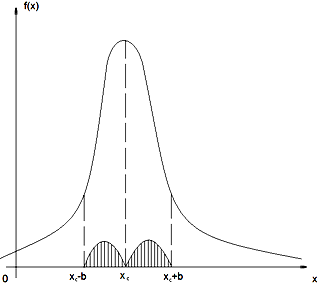
Анализ поведения распределения многих физических величин приводит к так называемому нормальному распределению (распределению Гаусса) случайной величины х, для которого плотность вероятности имеет вид:
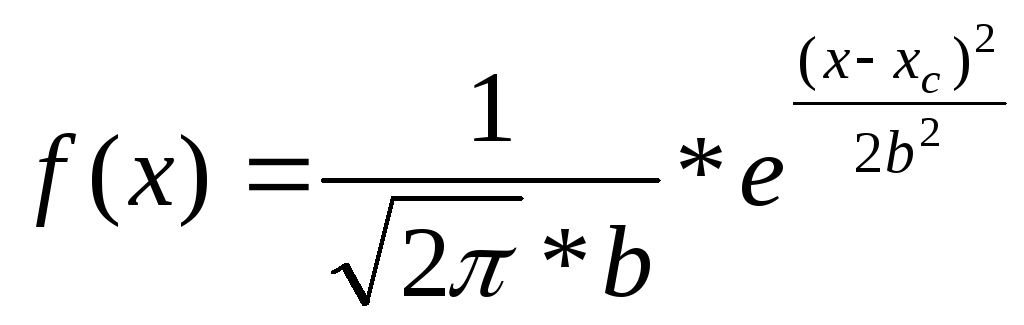 (6)
(6)
Э
Рис. 2
Можно убедиться, что входящие в формулу (6) параметры "хс" и "b" есть ничто иное, как среднее значение x0 и среднеквадратичное отклонение δ(x).
Зная x0 и δ(x) для нормального распределения случайной величины х можно составить себе приближенное представление о диапазоне ее возможных значений. А именно, значения случайной величины х лишь изредка выходят за пределы интервала x0 ± 3δ(х) и с вероятностью > 99% можно считать, что они укладываются в этот интервал. В интервал x0 ± 2δ(х) попадает 95 % случайных величин.
Вероятность попадания результатов в заданный интервал х называется доверительной вероятностью и обозначается буквой α , а сам интервал называется доверительным.
На практике для определения той или иной физической величины проводят конечное число её измерений. Поэтому при определении x0 и δ(x)приходиться пользоваться их приближенными выражениями (оценками) из имеющегося конечного числа значений xi.
Разумным
приближением x0
может служить среднеарифметическое
значение
![]()
![]() ,
которое, как было показано выше при
условии равно вероятности каждого из
xi
закономерно следует из
(I).
,
которое, как было показано выше при
условии равно вероятности каждого из
xi
закономерно следует из
(I).
Для дисперсии D(x)=δ2 на первый взгляд наиболее естественной представляется оценка в виде:
![]()
где xi - независимые случайные величины.
Более
точный математический анализ показывает
, что истинное
значение дисперсии D(х)
связано
![]() выражением:
выражением:
![]() (7)
(7)
Соответственно точное значение среднеквадратичного отклонения равно:
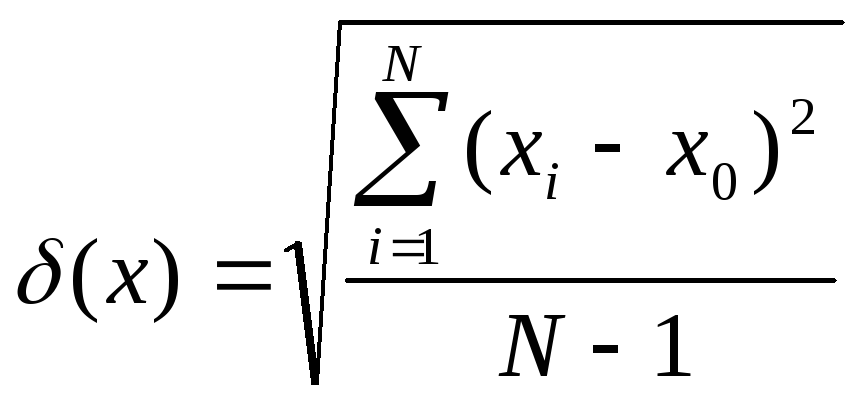 (8)
(8)
Можно заметить, что введение поправочного множителя играет заметную роль лишь при малых N и теряет смысл при больших его значениях.
Таким
образом, в реальных расчетах вполне
уместно пользоваться
приближенными значениями x0
и D(x),
при этом делая
соответствующую поправку для![]() .
.
Отметим,
что оценка
![]() будучи
функцией случайных величин сама
является случайной величиной, поэтому
пользуясь ею мы всегда
совершаем какую-то ошибку. Для того,
чтобы ее оценить рассмотрим
дисперсию
будучи
функцией случайных величин сама
является случайной величиной, поэтому
пользуясь ею мы всегда
совершаем какую-то ошибку. Для того,
чтобы ее оценить рассмотрим
дисперсию
![]() (не
путать
(не
путать
![]() ). Для этого
). Для этого
![]() будем рассматривать
как функцию независимых случайных
величин,
будем рассматривать
как функцию независимых случайных
величин,
![]() считая при этом что каждая из величин
xi
распределена
по одинаковому закону распределения,
т.е.
считая при этом что каждая из величин
xi
распределена
по одинаковому закону распределения,
т.е.
![]() .
Действительно, поскольку точки xi
-
случайны,
т.е. появление xi
не обязательно
влечет появление хi,
то их можно считать независимыми,
и полагать, что при большом числе
испытаний каждая из хi
и хi
дает набор значений, подчиняющийся
закону нормального распределения,
справедливого для любой из рассматриваемых
случайных
величин х1,х2,…,хN.
.
Действительно, поскольку точки xi
-
случайны,
т.е. появление xi
не обязательно
влечет появление хi,
то их можно считать независимыми,
и полагать, что при большом числе
испытаний каждая из хi
и хi
дает набор значений, подчиняющийся
закону нормального распределения,
справедливого для любой из рассматриваемых
случайных
величин х1,х2,…,хN.
Вспоминая, что
![]() ,
,
имеем
![]()
или с учетом того,
что
![]() и
и
![]() ,
,
т.е.
![]() ,
,
имеем
для дисперсии
![]()
Подставляя связь
истинного значения дисперсии для
произвольной
случайной величины хi
с ее оценкой
![]() ,
окончательно
получаем:
,
окончательно
получаем:
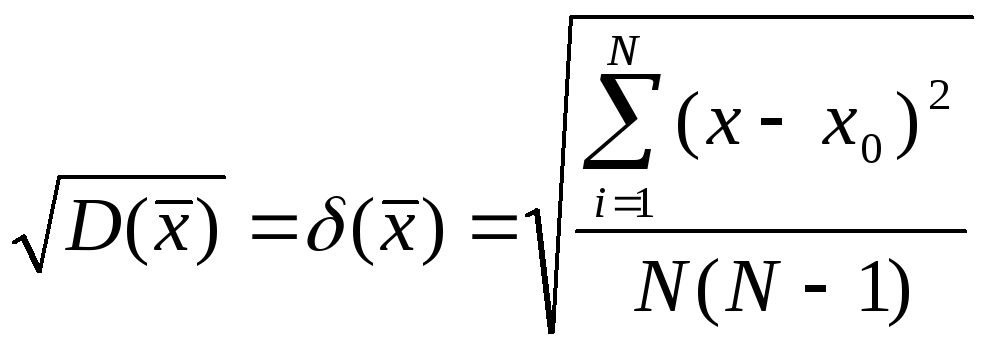 (9)
(9)
или
![]() (10)
(10)
Выше было показано, какими оценками, исходя из реальных возможностей экспериментатора, необходимо пользоваться для случайных величин, подчиняющихся закону нормального распределения. Было отмечено, что данный закон справедлив для большого числа измерений N и выявлено, что истинное значение случайной величины х с вероятностью Р=0,95 попадает в интервал ±2δ(х) от среднеарифметического значения х.
Однако при малых значениях числа измерений N функция нормального
распределения
![]() для оценки вероятности
для оценки вероятности
![]() попадания
случайной величины х
в определенный интервал
dх
не
является точной и, следовательно,
пользуясь ею мы
совершаем некоторую погрешность в
определении указанного интервала.
попадания
случайной величины х
в определенный интервал
dх
не
является точной и, следовательно,
пользуясь ею мы
совершаем некоторую погрешность в
определении указанного интервала.
Этого можно избежать, если воспользоваться распределением Стьюдента*1.
Данное
распределение обладает тем свойством,
что позволяет
точно находить вероятность попадания
случайной величины х
при наличии ограниченного
числа ее значений
![]() и
экспериментальной дисперсии* , а
при больших N
переходит в нормальное (см. рис.3).
и
экспериментальной дисперсии* , а
при больших N
переходит в нормальное (см. рис.3).
*
Распределение Гаусса
Распределение Стъюдента
Рис.6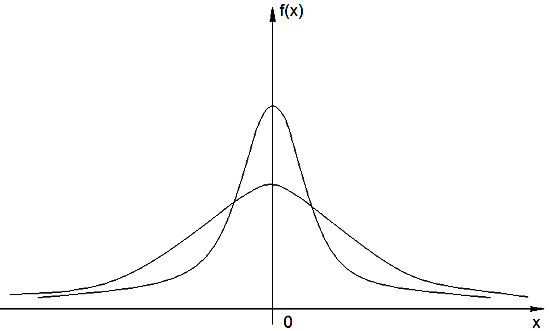

При
малых N
пользуясь этим распределением можно
вычислить доверительный
интервал, при заданной вероятности Р,
попадания
в него среднеарифметического значения
![]()
Сопоставляя этот интервал с интервалом, рассчитанным в тех же предположениях при нормальном распределении случайной величины х для каждого из значений N можно найти уточняющий множитель tP,N для интервала, соответствующего нормальному распределению. Этот множитель называют коэффициентом Стъюдента1 и представляют в табличном виде. Например, для Р=0,95 значения t0,95;N равны:
|
N |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
…. 20 |
|
t0,95;N |
4.30 |
3.18 |
2.77 |
2.57 |
2.45 |
2.36 |
2.31 |
2.26 |
2.09 |
Видно,
что по мере увеличения числа измерений
tP,N→2
и
соответственно
доверительный интервал укладывается
в пределы
![]() .
Таким
образом, для ограниченного числа
измерений
среднеарифметическое
.
Таким
образом, для ограниченного числа
измерений
среднеарифметическое
![]() значение определяется
со случайной погрешностью или для
границы
интервала :
значение определяется
со случайной погрешностью или для
границы
интервала :
![]() имеем:
имеем:
![]() (11)
(11)
____________________________