

МІНІСТЕРСТВО ОСВІТИ І НАУКИ УКРАЇНИ
ОДЕСЬКИЙ НАЦІОНАЛЬНИЙ ПОЛІТЕХНІЧНИЙ УНІВЕРСИТЕТ
Конспект лекцій
по дисципліні
“ЕКОНОМЕТРІЯ”
для студентів економічних спеціальностей
Затверджено
на засіданні кафедри
прикладної математики та
інформаційних технологій у бізнесі
Протокол № 4 від 11.11.03
Одеса ОНПУ 2004
Конспект лекцій по дисципліні “Економетрія” для студентів економічних спеціальностей / Укл. Б.І. Юхименко. — Одеса: ОНПУ, 2004. — 20 с.
Укладачі: Б.І. Юхименко, професор
Лекция 1. Введение в эконометрию
Определение эконометрии. Перечень разделов математики для эконометрических исследований. Структура эконометрических исследований.
В области теории экономики эконометрия выделяется как особый раздел, в котором методами математической статистики на базе экономических данных строятся математические модели, осуществляется прогнозирование экономических показателей, определяется их числовые значения. В целом эконометрия определяет три области знаний: математики, теории экономики и статистики. Само слово ЭКОНОМЕТРИЯ как понятие предопределяется словами экономия (управление, хозяйствование) и метром (измерение). Другими словами: эконометрия это «измерение» эффективности деятельности предприятия при помощи математических методов. Согласно с Леонтьевым В., эконометрия это применение количественного экономического анализа в самых различных областях хозяйственной деятельности.
При проведении эконометрических исследований применяются такие разделы математики как корреляционно-регрессионный анализ, системы массового обслуживания, имитационное моделирование, матрично-балансовые модели. При организации производства в системе, основанной на свободной конкуренции, эконометрические исследования проводятся с использованием производственных функций. Производственные функции – это математическая модель, построена на основе статистических данных методами корреляционно-регрессионного анализа. Коммерческие функции, в основном функции спроса, также результат обработки статистической информации корреляционными методами, являются средством для исследования рынка. Система массового обслуживания, как математический аппарат, используется для исследования причин возникновения очередей. Очереди возникают как в сфере обслуживания, так и в производственной сфере, скажем, при выполнении различных технологических процессов. В тех случаях, когда производство разделено на несколько секторов, эффективность их кооперирования может исследоваться, используя матрично-балансовую модель Леонтьева. Имитационное моделирование, как средство получения информации о функционировании самых различных систем, используется, к примеру, в исследовании деятельности фондовой биржи. Структурная схема эконометрии как дисциплина приведена на рис.1.
Э К О Н О М
Е Т Р И Я




М А Т Е М А Т И Ч Е С К И Й А П П А Р А Т
Корреляционно
-регрессионный анализ Системы массового
обслуживания Имитационное
моделирование Балансовые матричные
модели








Ф У Н К Ц И О Н А Л Ь Н О Е Н А З Н А Ч Е Н И Е
Моделирование
систем обслуживания Производственные
функции Коммерческие
функции Моделирование
производственных систем Моделирование
производственных систем Моделирование фондовой
биржи Открытая модель
Леонтьева Закрытая модель
Леонтьева








Ц Е Л Е В А Я У С Т А Н О В К А
Анализ деятельности
предприятия Анализ спроса
на товар Определение Структуры
технического процесса Оптимизация системы
обслуживания Определение структуры
гипотетической системы Проверка гипотез об
оптимальных стратегиях Регулирование зарплат Регулирование цен
Рис.1. Структурная схема дисциплины.
Перечисленные области применяемости эконометрических исследований составляют лишь не большую часть всех возможных исследований данного типа. Все эти исследования проводятся на основе статистических данных. Поэтому, ожидать абсолютно точных результатов нет возможности. Получаемые результаты являются информацией для принятия решений. Последовательность действий в эконометрических исследованиях приведена на рис.2.
Сбор статистических
данных Обработка
статистических данных Построение
математической модели Прогнози-рование Обработка
результатов Внедрение





Рис.2. Последовательность действий.
Возможно, что полученные прогнозные значения не устраивают пользователя результатами эконометрических исследований. В таком случае необходимо либо корректировка математической модели, либо статистические данные не достаточно корректные и не показывает истинного положения дел, необходим их просмотр.
Вопросы для самоподготовки.
-
Дайте свое определение эконометрии.
-
С какой целью используется математический аппарат в эконометрических исследованиях?
-
Для чего необходимы статистические данные и для чего они используются?
-
Когда возникает необходимость корректировки математической модели?
Лекция 2. Задачи корреляционно-регрессионного анализа
Назначение корреляционно-регрессионного анализа. Линия регрессии. Определение линии регрессии. Коэффициенты корреляции. Коэффициент Фишера. Коэффициент Стьюдента.
Построение корреляционных моделей позволяет дать количественную характеристику связи, зависимости и взаимной обусловленности экономических показателей. Хоть модель является упрощенным отражением действительности, она обеспечивает строго математический подход к исследованию экономических зависимостей. Корреляционно-регрессионный анализ (К-Ра) как математический аппарат это метод обработки статистических данных.
Экономическая величина складывается обычно под влиянием множества факторов. Закономерности не проявляются в сфере экономики с большей точностью и неизменностью. Поэтому в изучении взаимосвязей в экономике удобно пользоваться методами (К-Ра).
В простейшем случае корреляционного анализа исследуется связь между двумя показателями, из которых один рассматривается как зависимый (у), а второй независимый (х). Сама зависимость устанавливается в результате качественного анализа статистических данных, получаемых в результате наблюдений показателей х и у. До математического определения зависимости предполагается, что связь существует и формально записывается в виде терма y=f(x).
Первой задачей корреляционного анализа является установка аналитического вида этой зависимости, которая наилучшим образом определяет действительную зависимость. В практическом применении чаще всего исследуется зависимость, имеющая либо линейный
![]()
либо степенной
![]()
вид зависимости. Стандартный математический аппарат определения аналитического вида функции разработан для линейного вида зависимости. Однако это не умоляет общности, поскольку путем алгебраических преобразований любой другой вид зависимости можно привести к линейному.
Практически исследуемый показатель у складывается обычно под влиянием многих различных факторов, каждый из которых в отдельности может не оказывать решающего воздействия, но совместное влияние нескольких факторов является уже достаточно сильным и по их изменениям можно судить об изменении зависимого показателя. Для измерения такого совместного влияния ряда факторов на анализируемый показатель строится модель множественной корреляции, у рассматривается как функция от n переменных
![]() .
.
В множественной корреляции важным вопросом является выбор вида зависимости. Качественный анализ влияния независимых показателей на зависимый приобретает еще большую важность.
Опять таки, чаще всего рассматривается либо линейный
![]() ,
,
либо степенной
![]() ,
,
вид зависимости.
Чтобы
установить аналитический вид зависимости
для каждого конкретного случая, необходимо
собрать статистические данные.
Неизвестными в формальных записях
зависимостей являются коэффициенты
![]() Исходными данными для их определения
является совокупность значений ук
и соответствующие значения
Исходными данными для их определения
является совокупность значений ук
и соответствующие значения
![]() .
Совокупность
.
Совокупность
![]() составляет выборку. Объем выборки m
зависит от количества независимых
факторов и тем самым от количества
искомых величин aj.
Существует математический аппарат, при
помощи которого можно определить этот
объем, но практически считается
достаточным такой объем выборки m,
который 3-4 раза превращает число
независимых факторов.
составляет выборку. Объем выборки m
зависит от количества независимых
факторов и тем самым от количества
искомых величин aj.
Существует математический аппарат, при
помощи которого можно определить этот
объем, но практически считается
достаточным такой объем выборки m,
который 3-4 раза превращает число
независимых факторов.
Пример.
П усть
ставится вопрос об определении
аналитического вида зависимости
зависимого фактора у
от трех независимых факторов х1,х2,х3.
Для определения выборки необходимо
собрать статистические данные т.е.
значения ук
и х1к,х2к,х3к
если к=1,10.
усть
ставится вопрос об определении
аналитического вида зависимости
зависимого фактора у
от трех независимых факторов х1,х2,х3.
Для определения выборки необходимо
собрать статистические данные т.е.
значения ук
и х1к,х2к,х3к
если к=1,10.
Выборка будет представляться так
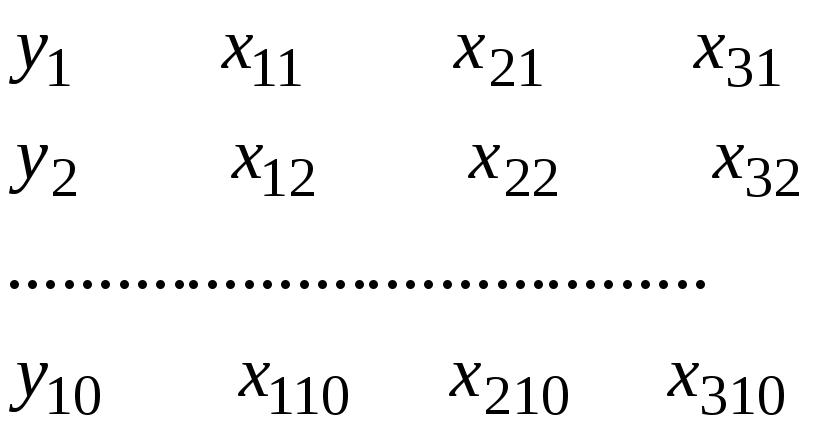
Для
определения тесноты связи между факторами
используется коэффициент корреляции.
Он представляет собой эмпирическую
меру линейной зависимости между
факторами. Коэффициенты корреляции
бывают: парной
корреляции
(ryx),
показывающей тесноту связи между двумя
факторами у
и х;
множественной
корреляции
![]() показывает
тесноту связи группы факторов; частной
корреляции
показывает
тесноту связи группы факторов; частной
корреляции
![]() ,
показывающей как изменится теснота
связи, если из группы факторов исключить
один.
,
показывающей как изменится теснота
связи, если из группы факторов исключить
один.
Коэффициент корреляции – величина r, где r[-1,1]. Причем чем ближе значение r к единице, тем связь теснее. Для парной корреляции, если r близко к (-1), то связь обратная (с увеличением одного фактора, второй уменьшается), а если r близок к (+1) – связь прямая. Если r близок к нулю, то связи не существует, и никакая линейная зависимость, полученная линией регрессии, не показывает истинной картины.
Следующим вопросом является изучение точности оценки полученного зависимого фактора при помощи найденной линии регрессии. В рассмотрение берутся квадраты отклонений фактических значений от расчетных. Полученная сумма квадратов связываются с определенным числом, усредняющим эту сумму. В литературе это число называют степенями свободы. Это разность между объемом выборки и числом независимых факторов.
Для оценки точности линии регрессии используется коэффициент Фишера F, который понимается в двух аспектах: табличный или теоретический и расчетный, вычисленный на основе полученной линии регрессии. Количественное значение коэффициента F зависит от уровня степеней свободы и уровня достоверности. Полученное расчетное значение критерия Фишера сравнивается с табличным значением при соответствующих условиях. Если расчетное значение F больше или хотя бы не меньше табличного, то зависимость – линия регрессии, достоверная. Практически берется 95% уровень достоверности. Независимые показатели имеют неодинаковую значимость при определении зависимого показателя. Для оценки значимости каждого независимого показателя используют критерий Стьюдента S или t отношения. Этот критерий рассматривается так же в двух аспектах при тех же условиях, но вычисляется для каждого независимого показателя в отдельности. Если для какого-то показателя расчетное значение S меньше табличного, то данный показатель является не значимым. Выдвигается гипотеза о его исключении. Гипотеза проверяется при помощи коэффициента частной корреляции.
Пример.
Исследование связи между двумя показателями. Пусть организуется строительство цеха некоторого предприятия. На его строительство и оборудование вкладываются определенные средства. Величина капиталовложений зависит от мощности цеха. Посчитана величина капиталовложений при соответствующей мощности. Статистические данные приведены в таблице №1.
Таблица 1.
Выборка
|
№ п/п |
Мощность цеха т.грн./смену |
Капиталовложения млн.грн. |
|
1 |
10 |
1,75 |
|
2 |
20 |
2,59 |
|
3 |
30 |
3,67 |
|
4 |
40 |
4,35 |
Предположим, что зависимость капиталовложений от мощности цеха имеет линейный вид. Обозначим через х мощность цеха, а через у капиталовложения. Формально зависимость запишется:
![]()
Аналитический вид зависимости будет установлена, если определены коэффициенты а1 и а0. Нормальные уравнения для показателей имеет вид:
 .
.
Объем выборки m=4. Вычислим значения, составляющих систему.
![]() .
.
Тогда имеем систему уравнений:
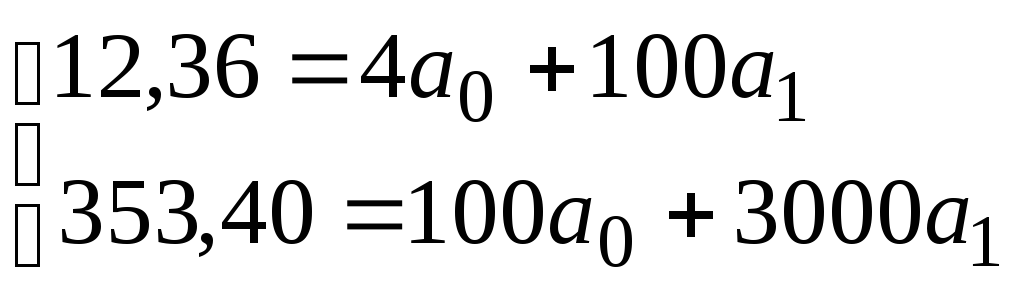 .
.
Решение данной системы следующее:
![]() .
.
Таким образом, аналитическое выражение зависимости капиталовложений от мощности цеха имеет вид:
![]() .
.
Посчитан коэффициент Фишера F=113,9. Табличное значение F=98,5 соответствующие условиям: независимых факторов 1, степеней свободы 4-1-1=2, уровень достоверности 95%. Полученная величина превосходит табличное значение при 99%-ом уровне достоверности.
Поскольку полученная зависимость верна, ее можно использовать для прогнозирования величины капиталовложений, если мощность цеха изменится. Пусть мощность составляет 50т.грн. в смену. Тогда капиталовложения определим согласно полученной модели
![]()
они составят 5,29млн.грн.
Вопросы для самопроверки.
-
Основная цель использования (К-Ра).
-
Что значит построить линию регрессии?
-
Как проверить существует или нет функциональная зависимость вида y=f(x) между факторами у и х?
-
Почему необходима проверка на достоверность полученной линии регрессии?
-
Пусть получен аналитический вид зависимости типа
 .
Как проверить какие из 4 независимых
факторов мало влияет на зависимый
фактор?
.
Как проверить какие из 4 независимых
факторов мало влияет на зависимый
фактор?
Лекция 3-4. Алгоритм построения математической модели зависимости экономических показателей.
Определение представительной выборки. Определение зависимого показателя. Построение математической модели. Выбор значимых независимых показателей.
Совокупность всех возможных значений рассматриваемых факторов составляет генеральную совокупность. Часть генеральной совокупности называется выборкой. Практически всегда обрабатывается выборка. Поскольку выборка представляет генеральную совокупность, то она должна отражать тенденцию изменения значений всех рассматриваемых факторов. Говорят, выборка должна быть представительной. Представительность выборки характеризуется двумя моментами: объемом выборки и характером изменений значений каждого из рассматриваемых факторов. С математических позиций выборка может рассматриваться как временной или пространственный ряд статистических данных. Если статистические данные, т.е. значения рассматриваемых факторов, собраны на одном объекте в определенные моменты времени, то выборку можно принять за временной ряд. Если статистические данные собраны на различных объектах, то выборка будет пространственным рядом статистических данных.
Объем выборки зависит от количества независимых факторов. Может случиться так, что количество значений рассматриваемых факторов меньше необходимого объема выборки, т.е. выборка не представлена из-за нехватки статистических данных. Если дополнить выборку не возможно, ставить вопрос об исключении из рассмотрения одного или более независимых факторов. Исключение факторов необходимо подтвердить. Для этого используются коэффициенты корреляции. Определяется значения коэффициентов парной корреляции между зависимым и каждым независимым факторов. Какое значение коэффициента минимальное, выдвигается гипотеза о возможности исключить из рассмотрения соответствующий независимый фактор как мало влияющий на значение зависимого фактора. Гипотеза проверяется при помощи коэффициента частной корреляции.
Пример.
Пусть
рассматривается зависимость
![]() .
Объем выборки значений
.
Объем выборки значений
![]() равно 9. Выборка не представительна
из-за малого объема. Значение коэффициентов
парной корреляции следующее
равно 9. Выборка не представительна
из-за малого объема. Значение коэффициентов
парной корреляции следующее

Фактор
х3
мало влияет на значение у.
Полагается, что можно его исключить из
рассмотрения. Проверка данной гипотезы
осуществляется путем сравнения значений
коэффициентов множественной корреляции
![]() и
и
![]() .
Пусть значения такие
.
Пусть значения такие
![]() ,
,
![]() .
Они мало отличаются друг от друга. Новая
совокупность имеет такую же тесноту
связи, как и исходная. Фактор х3
можно исключить. Следует рассматривать
зависимость
.
Они мало отличаются друг от друга. Новая
совокупность имеет такую же тесноту
связи, как и исходная. Фактор х3
можно исключить. Следует рассматривать
зависимость
![]() .
Для трех независимых факторов выборка
достаточна по объему.
.
Для трех независимых факторов выборка
достаточна по объему.
Выборка может оказаться не представительной из-за характера значений каждого отдельно взятого фактора. Среди значений какого-то фактора находится патологическое значение, сильно отличающееся от остальных. В таком случае либо исключается вся соответствующая строка выборки, либо нужно выяснить причины, которые предопределили появление такого значения. Если выборка пространственный ряд и объем достаточный, то из рассмотрения можно исключить объем и естественно все значения факторов, характеризующий этот объем. Если выборка временной ряд, то такое исключение не желательно, поскольку временные интервалы получаются разные и точность прогнозирования будет не велика.
Пример.
Пусть
рассматривается зависимость
![]() .
Гипотетическая выборка значений факторов
у, х1,
х2
следующая:
.
Гипотетическая выборка значений факторов
у, х1,
х2
следующая:
|
№ п/п |
у |
х1 |
х2 |
|
1 |
95 |
17 |
61 |
|
2 |
103 |
20 |
69 |
|
3 |
98 |
19 |
71 |
|
4 |
101 |
9
98 |
64 |
|
5 |
99 |
23 |
65 |
|
6 |
106 |
18 |
70 |
|
7 |
103 |
15 |
72 |
Четвертое
значение фактора х1
патологическое. Выборка не представительная.
Если это пространственный ряд, то строка
4 исключается из рассмотрения, объем
выборки позволяет это сделать. Если это
временной ряд, необходимо выяснить
причины появления значения
![]() .
Вместо этого значения можно поставить
среднее значение всех значений фактора
х1.
В данном случае
.
Вместо этого значения можно поставить
среднее значение всех значений фактора
х1.
В данном случае
![]() и вместо 98 подставить 19.
и вместо 98 подставить 19.
В реальных условиях появляется проблема выбора зависимого фактора из множества полагаемых зависимых факторов, когда задана совокупность независимых факторов. Выбор можно осуществить интуитивно, но можно это сделать обосновано. Процедура выбора следующая. Вычисляются коэффициенты парной корреляции между любой парой полагаемых зависимых факторов. Если все коэффициенты парной корреляции близки к единице, факторы считаются колиниарными. Можно выбрать любой из них в качестве зависимого. Если колиниарность не наблюдается, то необходимо искать другие пути выбора зависимого фактора. При колиниарности факторов необходимо проверить их поведение по отношению к совокупности независимых факторов. Вычисляются коэффициенты парной корреляции каждого зависимого фактора с каждым независимым. Если соответствующие коэффициенты близки по величине и обязательно имеют одинаковый знак, то полагаемые зависимые показатели одинаково ведут себя по отношению к независимым. Окончательное решение о выборе независимого принимаются на основе значений коэффициентов множественной корреляции. Для какой совокупности (один зависимый и все независимые) коэффициент множественной корреляции наибольший, то совокупность следует рассматривать.
Пример.
Пусть
рассматриваются факторы у1
и у2
как полагаемые зависимые и х1,
х2,
х3,
как независимые. На основе выборки
вычислены коэффициенты парной корреляции.
Значения такие
![]() .
Фактора у1
и у2
колинеарны.
.
Фактора у1
и у2
колинеарны.

Соответствующие
значения коэффициентов парной корреляции
близки по значениям и имеют одинаковые
знаки. Можно рассматривать любой из
факторов. Коэффициенты множественной
корреляции совокупности факторов такие.
![]() ;
;
![]() .
В качестве зависимого выбирается у1
и рассматривается зависимость
.
В качестве зависимого выбирается у1
и рассматривается зависимость
![]() .
Аналитический вид зависимости определяется
используя метод наименьших квадратов
[1], используя любой пакет прикладных
программ либо в ручную. Изначально
полагается вид зависимости, далее
определяются составляющие эту зависимость.
К примеру, необходимо определить
аналитический вид зависимости
.
Аналитический вид зависимости определяется
используя метод наименьших квадратов
[1], используя любой пакет прикладных
программ либо в ручную. Изначально
полагается вид зависимости, далее
определяются составляющие эту зависимость.
К примеру, необходимо определить
аналитический вид зависимости
![]() .
Полагаем, что зависимость существует.
Это можно проверить при помощи коэффициента
множественной корреляции. Имеется
представительная выборка значений у,
х1
и х2.
Если предположит, что зависимость имеет
линейный вид, то общий вид линейной
зависимости будет такой
.
Полагаем, что зависимость существует.
Это можно проверить при помощи коэффициента
множественной корреляции. Имеется
представительная выборка значений у,
х1
и х2.
Если предположит, что зависимость имеет
линейный вид, то общий вид линейной
зависимости будет такой
![]() .
В аналитическом виде зависимости вместо
а0,
а1,
и а2
должна стоять
конкретные числовые значения. Их можно
определить на основе выборки, используя
метод наименьших квадратов, реализованный
в любом пакете прикладных программ по
математической статистике. Если
предположить, что зависимость имеет
степенной вид т.е.
.
В аналитическом виде зависимости вместо
а0,
а1,
и а2
должна стоять
конкретные числовые значения. Их можно
определить на основе выборки, используя
метод наименьших квадратов, реализованный
в любом пакете прикладных программ по
математической статистике. Если
предположить, что зависимость имеет
степенной вид т.е.
![]() и
таким же образом необходимо определить
значения а0,
1
и 2.
Полученный аналитический вид зависимости
подвергается проверке на достоверность.
Это необходимо сделать по двум причинам.
Во-первых, выборка, на основе которой
получена зависимость, является только
выборкой, а не генеральной совокупностью
статистических данных. Во-вторых, вид
зависимости полагается изначально.
Можно ошибиться. Проверка на достоверность
осуществляется при помощи коэффициента
Фишера. В случае, если расчетное значение
коэффициента Фишера меньше табличного,
линию регрессии нельзя использовать в
качестве математической модели
зависимости рассматриваемой совокупности
факторов. Следует искать причины
недостоверности, их исключить и повторить
процедуру определения аналитического
вида зависимости.
и
таким же образом необходимо определить
значения а0,
1
и 2.
Полученный аналитический вид зависимости
подвергается проверке на достоверность.
Это необходимо сделать по двум причинам.
Во-первых, выборка, на основе которой
получена зависимость, является только
выборкой, а не генеральной совокупностью
статистических данных. Во-вторых, вид
зависимости полагается изначально.
Можно ошибиться. Проверка на достоверность
осуществляется при помощи коэффициента
Фишера. В случае, если расчетное значение
коэффициента Фишера меньше табличного,
линию регрессии нельзя использовать в
качестве математической модели
зависимости рассматриваемой совокупности
факторов. Следует искать причины
недостоверности, их исключить и повторить
процедуру определения аналитического
вида зависимости.
В случае достоверности линии регрессии, можно ставить вопрос об упрощении самой модели зависимости. Корреляционно-регрессионный анализ такую возможность представляет. Вычисляются значения коэффициентов Стьюдента на основе полученной линии регрессии. Если для какого-то фактора коэффициент Стьюдента меньше табличного, выдвигается и проверяется гипотеза о его исключении. Если гипотеза подтвердилась, коэффициент частной корреляции показал маленькое значение остаточного значения коэффициента множественной корреляции, то фактор исключается из рассмотрения, из выборки выбрасывается соответствующий столбец значений и заново начинается процедура определения аналитического вида зависимости зависимого показателя от меньшего количества независимых факторов.
Пример.
Определен аналитический вид зависимости и проверена на достоверность линия регрессии, описывающая зависимость фактора от трех независимых факторов
![]()
Посчитаны
коэффициенты Стьюдента : S1=4,25;
S2=6,14;
S3=0,91.
Табличные значения при соответствующих
условиях Sтабл.=3,67.
Согласно такой информации, фактор х3
является малозначимым для определения
значения зависимого фактора у.
Полагаем, его можно исключить. Коэффициенты
множественной корреляции
![]() и
и
![]() подтверждают гипотезу об исключении
х3
из рассмотрения. Можно довольствоваться
зависимостью
подтверждают гипотезу об исключении
х3
из рассмотрения. Можно довольствоваться
зависимостью
![]() .
Опять полагаем вид зависимости, (он
может быть и другим, чем изначально),
определяем составляющие этот вид и
проверяем на достоверность новую
зависимость.
.
Опять полагаем вид зависимости, (он
может быть и другим, чем изначально),
определяем составляющие этот вид и
проверяем на достоверность новую
зависимость.
Вопросы для самопроверки.
-
Что такое выборка и почему она должна быть представительной?
-
Каким образом определяется представительность выборки?
-
Какие средства корреляционного анализа позволяет выдвинуть гипотезу о исключении фактора из рассмотрения и какие проверить эту гипотезу?
-
Каким образом и на основе чего определяется линия регрессии?
-
Когда линию регрессии можно считать математической моделью, представляющей функциональную зависимость одного фактора от других?
-
Объясните, почему нельзя просто вычеркнуть из полученной линии регрессии фактор с его коэффициентом, если было принято решение о его исключении из рассмотрения?
-
Как, по Вашему мнению, можно использовать линию регрессии как средство прогнозирования значений факторов?