

6.3. Интеллектуальный анализ данных. Управление знаниями
Информационная составляющая играет важнейшую роль в эффективном управлении бизнесом, поэтому способность предприятий обеспечивать своих сотрудников всем необходимым для принятия взвешенных решений имеет огромное значение. С середины 90-х гг. XX в. стремительно растет интерес компаний к программным продуктам, которые позволяют аналитикам работать с большими объемами данных, накопленными в ERP-, CRM-системах и хранилищах данных, и извлекать из них полезную информацию. Следствием этого стало рождение новых информационных технологий и инструментов, обеспечивающих безопасный доступ к источникам корпоративных данных и обладающих развитыми возможностями консолидации, анализа, представления данных и распространения готовых аналитических документов внутри организации и за ее пределами: витрин данных, обработки произвольных запросов (Ad-hoc query), выпуска отчетов (Reporting), инструментов OLAP (On-Line Analytical Processing), интеллектуального анализа данных (DM — Data Mining), поиска знаний в БД (KDD — Knowledge Discovery in Databases) и т.д.
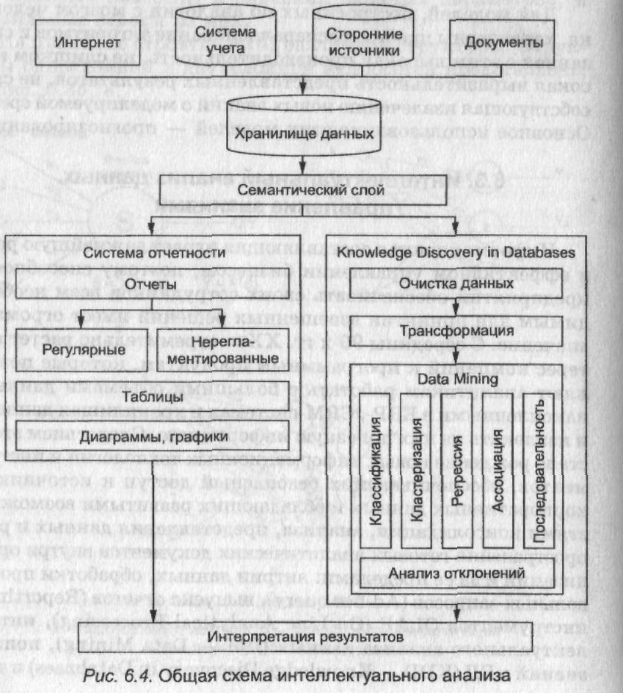
Под «анализом данных» понимают действия, направленные на извлечение из них информации об исследуемом объекте и на получение по имеющимся данным новых данных. Интеллектуальный анализ данных (ИАД) — общий термин для обозначения анализа данных с активным использованием математических методов и алгоритмов (методы оптимизации, генетические алгоритмы, распознавание образов, статистические методы, Data Mining и т.д.), использующих визуальное представление данных. Общая схема интеллектуального анализа приведена на рис. 6.4.
 1)
выявление закономерностей (свободный
поиск);
1)
выявление закономерностей (свободный
поиск);
2) использование выявленных закономерностей для предсказания неизвестных значений (прогнозирование);
3) анализ исключений для выявления и толкования аномалий в найденных закономерностях.
Иногда выделяют промежуточную стадию проверки достоверности найденных закономерностей (стадия валидации) между их нахождением и использованием.
Все методы ИАД по принципу работы с исходными данными подразделяются на две группы:
1. Методы рассуждений на основе анализа прецедентов — исходные данные могут храниться в явном детализированном виде и непосредственно использоваться для прогнозирования и/или анализа. Недостатком этой группы методов является сложность их использования на больших объемах данных.
2. Методы выявления и использования формализованных закономерностей, требующие извлечения информации из первичных данных и преобразования ее в некоторые формальные конструкции, вид которых зависит от конкретного метода. На рис. 6.6 представлены методы, входящие в эти группы.
В табл. 6.1 приведены примеры использования методов интеллектуального анализа данных в финансовых приложениях и маркетинговом анализе.
Рассмотренные методы позволяют коммерческим банкам решать следующие задачи:
• получение отчетности банка и проверка ее полноты и корректности;
• проведение группировки статей баланса и расчет экономических нормативов и аналитических коэффициентов (например, по методу CAMEL);
• оценка состояния банка по системе аналитических коэффициентов;
• определение рейтинга банка;
• анализ динамики основных показателей, выявление тенденций и прогнозирование состояния банка;
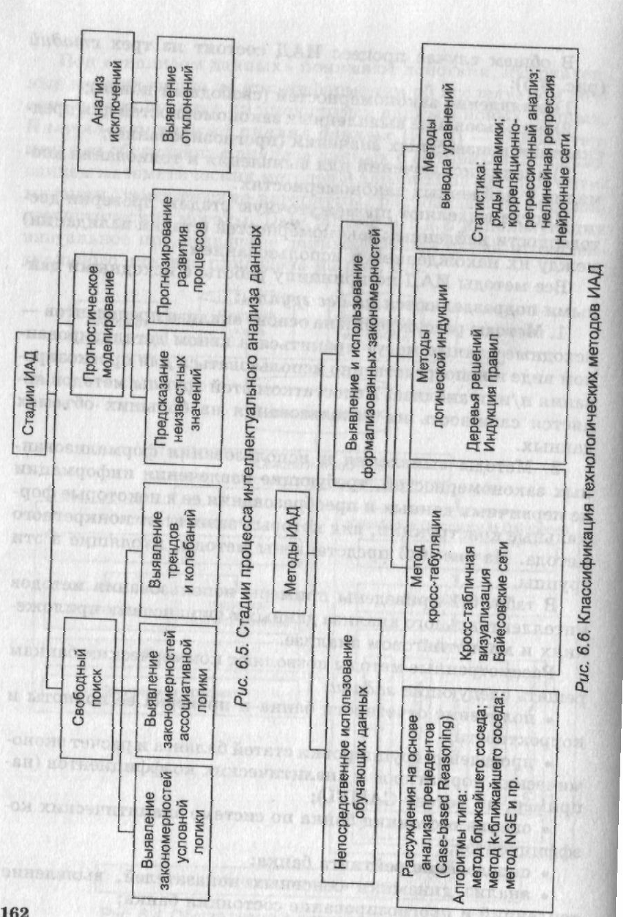
Рис. 6.6. Классификация технологических методов ИАД
• анализ степени влияния тех или иных факторов на состояние банка;
• выработка рекомендаций по оптимизации банковского баланса и т.д.
В основу технологии ИАД положен не один, а несколько принципиальных подходов (табл. 6.1), причем использование некоторых из них невозможно без специальной подготовки.
Таблица 6.1 Подходы к технологии ИАД
|
Технология |
Достоинства |
Недостатки |
|
1 |
2 |
3 |
|
Правила вывода |
Удобны в случаях, когда данные связаны отношениями, представимыми в виде правил «если — то» |
При большом количестве правил теряется наглядность; не всегда удается выделить отношения «если — то» |
|
Нейронные сети |
Удобны при работе с нелинейными зависимостями, зашумленными и неполными данными |
«Черный ящик»: модель не может объяснить выявленные знания; данные обязательно должны быть преобразованы к числовому виду |
|
Нечеткая логика |
Ранжируют данные по степени близости к желаемым результатам; нечеткий поиск в базах данных |
Технология новая, поэтому разработано ограниченное число приложений |
|
Визуализация |
Многомерное графическое представление данных, по которому пользователь сам выявляет закономерности |
Модели не исполняются, и их интерпретация полностью зависит от аналитика |
|
Статистика |
Существует множество алгоритмов и опыт их применения в научных и инженерных приложениях |
Ориентированы в основном на проверку гипотез, а не на выявление новых закономерностей в данных |
Окончание табл. 6.1
|
1 |
2 |
3 |
|
К-ближайший сосед |
Выявление кластеров, обработка целостных источников данных |
Большие затраты памяти, проблемы с чувствительностью |
|
Интегрированные технологии |
Возможность выбора подходов, адекватных задачам, или сравнения результатов применения разных подходов |
Сложность средств поддержки; высокая стоимость; для каждой отдельно взятой технологии не всегда реализуется наилучшее решение |
Существующие системы ИАД подразделяют на исследовательские, ориентированные на специалистов и предназначенные для работы с новыми типами проблем; прикладные, рассчитанные на аналитиков, менеджеров, технологов и решающие типовые задачи. Если в исследовательских системах ИАД важно разнообразие доступных методов обработки данных и гибкость используемых средств, то в прикладных системах целесообразно реализовывать не методы, а типовые виды рассуждений (анализа), характерные для проблемной области.
Для проведения
автоматического анализа данных,
накопленных предприятием в течение
жизненного цикла, используются
технологии под общим названием Data
Mining.
На рис. 6.7 приведена классификация
уровней и инструментарий извлечения
знаний из данных.

Data Mining (DM) — это технология обнаружения в «сырых» данных ранее неизвестных нетривиальных, практически полезных и доступных интерпретаций знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Алгоритмы, используемые в Data Mining, требуют большого количества вычислений, что ранее являлось сдерживающим фактором широкого практического их применения, однако рост производительности современных процессоров снял остроту этой проблемы. Задачи, решаемые методами DM:
• классификация — отнесение объектов (наблюдений, событий) к одному из заранее известных классов;
• прогнозирование;
• кластеризация — группировка объектов на основе данных, описывающих сущность этих объектов. Объекты внутри кластера должны обладать общими чертами и отличаться от объектов, вошедших в другие кластеры. Чем больше похожи объекты внутри кластера и чем больше отличий между кластерами, тем точнее кластеризация;
• ассоциация — выявление закономерностей между связанными событиями;
• последовательные шаблоны — установление закономерностей между связанными во времени событиями;
• анализ отклонений — выявление наиболее нехарактерных шаблонов.
Решение большинства задач бизнес-анализа сводится к той или иной задаче Data Mining. Например, оценка рисков — решение задачи классификации; сегментация рынка — кластеризации; стимулирование спроса — ассоциации.
Технология Data Mining развивалась и развивается на стыке статистики, теории информации, машинного обучения, теории баз данных. Наибольшее распространение получили следующие методы Data Mining: нейронные сети, деревья решений, алгоритмы кластеризации, алгоритмы обнаружения ассоциативных связей между событиями и т.д.
Деревья решений представляют собой иерархическую древовидную структуру классифицирующих правил типа «если — то». Для отнесения некоторого объекта или ситуации к какому-либо классу следует ответить на вопросы, имеющие форму «значение параметра А больше X» и расположенные в узлах дерева. При положительном ответе осуществляется переход к правому узлу следующего уровня дерева, отрицательном — к левому узлу (рис. 6.8).
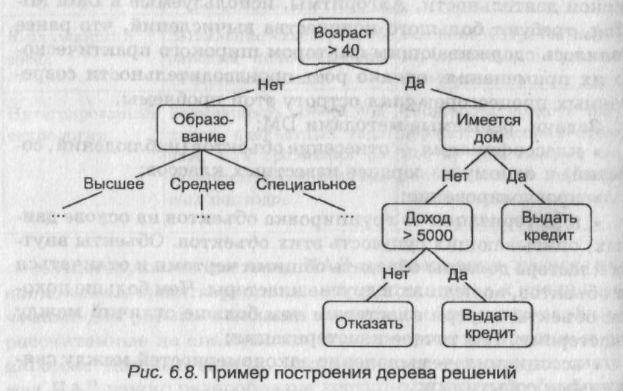
Рис. 6.8. Пример построения дерева решений
Если построенное дерево состоит из неоправданно большого числа ветвей, то оно не будет обеспечивать получение статистически обоснованного ответа. Деревья решений выдают полезные результаты только в случае независимости признаков.
В настоящее время деревья решений применяются при решении таких задач, как описание данных (они позволяют хранить информацию о данных в компактной форме); классификация (отнесение объектов к одному из заранее известных классов); регрессия (определение зависимости целевой переменной, принимающей непрерывные значения, от независимых — входных — переменных).
Несмотря на обилие методов Data Mining, приоритет постепенно все более смещается в сторону логических алгоритмов поиска в данных «если — то» правил. С их помощью решаются задачи прогнозирования, классификации, распознавания образов, сегментации БД, извлечения из данных скрытых знаний, интерпретации данных, установления ассоциаций в БД и др. Результаты таких алгоритмов эффективны и легко интерпретируются.
Главной проблемой логических методов обнаружения закономерностей является проблема перебора вариантов за приемлемое время. Известные методы либо искусственно ограничивают такой перебор (алгоритмы КОРА, WizWhy), либо строят деревья решений (алгоритмы CART, CHAID, ID3, See5, Sipina и др.). имеющие принципиальные ограничения.
Программное обеспечение для реализации технологий Data Mining: Poly Analyst, Scenario, 4Thought, MineSet.
Поиск данных в базах данных (Knowledge Discovery in Databases) определяет последовательность действий, необходимую для получения знаний, а не набор методов обработки или алгоритмов анализа, и включает следующие этапы:
1. Подготовка исходного набора данных — создание набора данных из различных источников, для чего должен обеспечиваться доступ к источникам данных.
2. Предобработка данных — удаление пропусков, искажений, аномальных значений, дополнение данных некоторой априорной информацией. Данные должны быть качественны и корректны с точки зрения используемого метода DM.
3. Трансформация, нормализация данных — приведение информации к пригодному для последующего анализа виду.
4. Data Mining — применение различных алгоритмов нахождения знаний.
5. Постобработка данных — интерпретация результатов и применение полученных знаний в бизнес-приложениях.
Динамические системы поддержки принятия решений (СППР) ориентированы на обработку нерегламентированных (ad hoc) запросов аналитиков к данным. Работа аналитиков с этими системами заключается в интерактивном формировании запросов и изучении их результатов. Поддержка принятия управленческих решений на основе накопленных данных может выполняться в следующих областях: поиск данных; формирование комплексного взгляда на собранную в хранилище данных информацию, ее обобщение и агрегация, гиперкубическое представление и многомерный анализ; интеллектуальная обработка методами ИАД, главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие процессов.
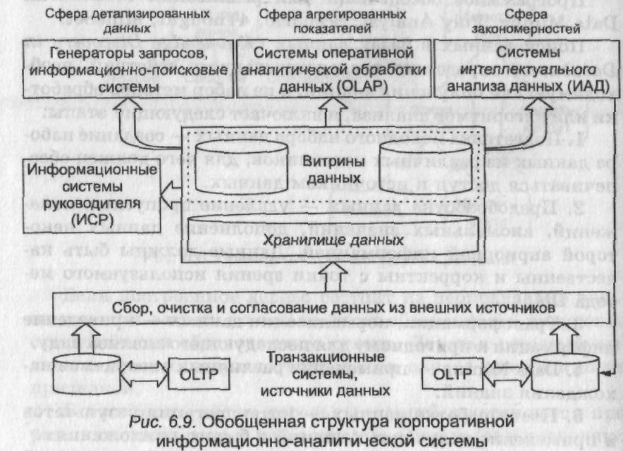
Обобщенная структура информационно-аналитической системы, построенной на основе хранилища данных, показана на рис. 6.9. В конкретных реализациях отдельные компоненты этой схемы часто отсутствуют.
В основе концепции OLAP лежит принцип многомерного представления данных. Э. Кодд определил 12 правил, которым должен удовлетворять программный продукт класса OLAP (табл. 6.2).
Таблица 6.2 Оценка программных продуктов класса OLAP
|
Критерий оценки |
Пояснение |
|
1 |
2 |
|
Многомерное концептуальное представление данных |
Концептуальное представление модели данных в продукте OLAP должно быть многомерным по своей природе |
Продолжение табл. 6.2
|
1 |
2 |
|
|
Прозрачность |
Пользователь не должен знать о том, какие конкретные средства используются для хранения и обработки данных, как данные организованы и откуда берутся |
|
|
Доступность |
Инструментарий OLAP должен накладывать свою логическую схему на физические массивы данных, выполняя все преобразования, требующиеся для обеспечения единого, согласованного и целостного взгляда пользователя на информацию |
|
|
Устойчивая производительность |
Увеличение числа измерений и размеров базы данных не должно уменьшать производительность |
|
|
Клиент-серверная архитектура |
Способность продуктов OLAP работать в среде клиент-сервер, серверный компонент должен быть интеллектуальным и обладать способностью строить концептуальную схему на основе обобщения и консолидации различных логических и физических схем корпоративных баз данных для обеспечения эффекта прозрачности |
|
|
Равноправие измерений |
Все измерения данных должны быть равноправны |
|
|
Динамическая обработка разреженных матриц |
Обеспечение оптимальной обработки разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную разреженность |
|
|
Поддержка многопользовательского режима |
OLAP-система должна предоставлять доступ, обеспечивать целостность и защиту данных |
|
|
Неограниченная поддержка кроссмерных операций |
Вычисления и манипуляция данными по любому числу измерений не должны запрещать или ограничивать любые отношения между ячейками данных; преобразования, требующие произвольного определения, должны задаваться на функционально полном формульном языке |
|
|
Интуитивное манипулирование данными |
Консолидация, детализация данных, агрегация и другие манипуляции должны выполняться в максимально удобном, естественном и комфортном пользовательском интерфейсе |
|
|
Гибкий механизм генерации отчетов |
Должны поддерживаться различные способы визуализации данных |
|
|
Неограниченное количество измерений и уровней агрегации |
Должно допускаться практически неограниченное количество определенных пользователем уровней агрегации по любому направлению консолидации |
|
Все продукты OLAP делятся на классы (табл. 6.3).
Таблица 6.3 Классы программных продуктов OLAP
|
Класс |
Характеристика |
ПО |
|||
|
1 |
2 |
3 |
|||
|
MOLAP — системы оперативной аналитической обработки многомерных данных |
Работают только с собственными многомерными базами данных, основываются на патентованных технологиях для многомерных СУБД и являются наиболее дорогими, обеспечивают полный цикл OLAP-обработки, включают в себя, помимо серверного компонента, собственный интегрированный клиентский интерфейс либо используют для связи с пользователем внешние программы работы с электронными таблицами |
Essbase (Arbor Software), Oracle Express Server (Oracle) |
|||
|
ROLAP — системы оперативной аналитической обработки реляционных данных |
Позволяют представлять данные, хранимые в реляционной базе, в многомерной форме, обеспечивая преобразование информации в многомерную модель через промежуточный |
DSS Suite (Micro-Strategy), MetaCube (Informix), Decision-Suite (Information Advantage), Инфо-Визор (РФ) |
|||
|
|
слой метаданных, хорошо приспособлены для работы с крупными хранилищами, предусматривают многопользовательский режим работы |
|
|
||
|
Hybrid OLAP, HOLAP - гибридные системы |
Объединяют аналитическую гибкость и скорость ответа МОLАР с постоянным доступом к реальным данным, свойственным ROLAP |
Media/MR (Speed-ware) |
|
||
|
Инструменты генерации запросов и отчетов для настольных ПК |
Осуществляют выборку данных из исходных источников, преобразуют их и помещают в динамическую многомерную БД, функционирующую на клиентской станции конечного пользователя |
BusinessObjects (BusinessObjects), BrioQuery (Brio Technology), PowerPlay (Cognos) |
|
||
Достоинства использования многомерных БД в системах оперативной аналитической обработки:
• поиск и выборка данных осуществляются значительно быстрее, так как многомерная БД денормализована, содержит заранее агрегированные показатели и обеспечивает оптимизированный доступ к запрашиваемым ячейкам;
• простота включения в информационную модель разнообразных встроенных функций.
Ограничения использования многомерных СУБД в системах OLAP:
• не позволяют работать с большими БД;
• денормализация и предварительно выполненная агрегация данных в многомерной базе приводят к уменьшению объема исходных детализированных данных;
• неэффективно используют внешнюю память. Использование многомерных СУБД оправдано при следующих условиях:
• объем исходных данных для анализа не слишком велик, т.е. уровень агрегации данных достаточно высок;
• набор информационных измерений стабилен;
• время ответа системы на нерегламентированные запросы является наиболее критичным параметром;
• требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба.
В большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД, инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP.
ROLAP системы с динамическим представлением размерности являются оптимальным решением в случае, когда изменения в структуру измерений приходится вносить достаточно часто, так как в этих системах модификация не требует физической реорганизации БД.
Реляционные СУБД обеспечивают высокий уровень защиты данных и возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД — меньшая производительность.
Оперативная аналитическая обработка и интеллектуальный анализ данных — две составные части процесса поддержки принятия решений (рис. 6.10). Эти два вида анализа должны быть объединены.
В настоящее время немногие производители предоставляют мощные средства интеллектуального анализа многомерных данных в рамках систем OLAP. Проблема заключается в том, что некоторые методы ИАД неприменимы для задач многомерного интеллектуального анализа, так как не способны работать с агрегированными данными.
Под «управлением знаниями» (Knowledge Management) обычно понимают систематическое приобретение, синтез, обмен и использование опыта для достижения успеха в бизнесе или в управлении компанией.
Обычно выделяют два типа знаний: явные и неявные.
Явные знания — знания, представленные в компании в виде должностных инструкций, регламентов и положений о деятельности подразделений, корпоративные учебные пособия и другое. Управление такими знаниями осуществляется с использованием следующих технологий:
• корпоративные архивы и таксономия (от греч. taxis — строй, порядок, расположение по порядку и nomos — закон, теория классификации и систематизации сложноорганизованных областей действительности, имеющих обычно иерархическое строение);
• создание систем обеспечения разграниченного доступа персонала компании к необходимым знаниям;
• навигация в системе формальных знаний;
• поиск необходимых формальных знаний.
Неявные знания — знания, носителем которых является человек (продукт личного опыта), их нельзя увидеть, сложно задокументировать, передать их можно только посредством личного и непосредственного общения (совместной работы). Они могут содержаться в корпоративном хранилище данных (понимание конкретного корпоративного процесса, полученное в ходе ИАД), для извлечения которых используются технологии искусственного интеллекта и статистики.
Для извлечения неявных знаний можно использовать различные методы извлечения знаний:
• экспертное интервью, проводимое инженером по знаниям с целью формализации знаний, интервью при увольнении сотрудника с целью сохранения знаний, обучающее интервью;
• заполнение анкет и форм учета знаний (CRM, описание лучших практик);
• время ответа системы на нерегламентированные запросы является наиболее критичным параметром;
• требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба.
В большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД, инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP.
ROLAP системы с динамическим представлением размерности являются оптимальным решением в случае, когда изменения в структуру измерений приходится вносить достаточно часто, так как в этих системах модификация не требует физической реорганизации БД.
Реляционные СУБД обеспечивают высокий уровень защиты данных и возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД — меньшая производительность.
Оперативная
аналитическая обработка и интеллектуальный
анализ данных — две составные части
процесса поддержки принятия решений
(рис. 6.10). Эти два вида анализа должны
быть объединены.
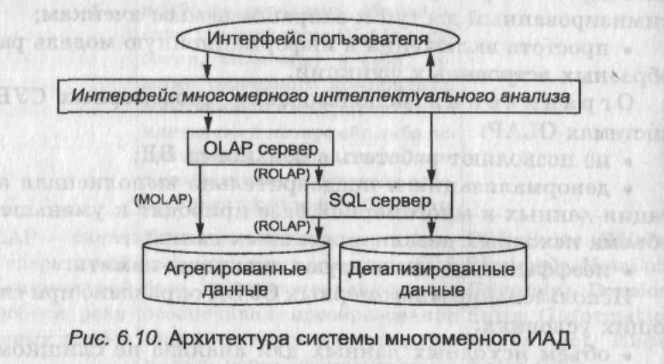
В настоящее время немногие производители предоставляют мощные средства интеллектуального анализа многомерных данных в рамках систем OLAP. Проблема заключается в том, что некоторые методы ИАД неприменимы для задач многомерного интеллектуального анализа, так как не способны работать с агрегированными данными.
Под «управлением знаниями» (Knowledge Management) обычно понимают систематическое приобретение, синтез, обмен и использование опыта для достижения успеха в бизнесе или в управлении компанией.
Обычно выделяют два типа знаний: явные и неявные.
Явные знания — знания, представленные в компании в виде должностных инструкций, регламентов и положений о деятельности подразделений, корпоративные учебные пособия и другое. Управление такими знаниями осуществляется с использованием следующих технологий:
• корпоративные архивы и таксономия (от греч. taxis — строй, порядок, расположение по порядку и nomos — закон, теория классификации и систематизации сложноорганизованных областей действительности, имеющих обычно иерархическое строение);
• создание систем обеспечения разграниченного доступа персонала компании к необходимым знаниям;
• навигация в системе формальных знаний;
• поиск необходимых формальных знаний.
Неявные знания — знания, носителем которых является человек (продукт личного опыта), их нельзя увидеть, сложно задокументировать, передать их можно только посредством личного и непосредственного общения (совместной работы). Они могут содержаться в корпоративном хранилище данных (понимание конкретного корпоративного процесса, полученное в ходе ИАД), для извлечения которых используются технологии искусственного интеллекта и статистики.
Для извлечения неявных знаний можно использовать различные методы извлечения знаний:
• экспертное интервью, проводимое инженером по знаниям с целью формализации знаний, интервью при увольнении сотрудника с целью сохранения знаний, обучающее интервью;
• заполнение анкет и форм учета знаний (CRM, описание лучших практик);
• формализация экспертных дискуссий (инженер по знаниям может преобразовать дискуссию, прошедшую на форуме или совещании, в обучающую аннотацию или справку);
• наблюдение.
Результат, полученный в ходе применения интеллектуальных методов и методов статистики, принимается как конкретное знание только при соблюдении следующих условий:
• четкая формулировка вопроса;
• структура собранных данных позволяет обработать БД согласно сформулированному запросу.
Система хранения знаний должна регламентировать доступ персонала к знаниям, обладать понятной для использования навигацией, обеспечивать эффективный поиск необходимых знаний.
Обмен является одним из ключевых способов распространения неявных знаний в компании. Для его организации компания должна понимать, кто в ее среде является носителем ключевых знаний, и способствовать обмену знаниями в среде корпоративных специалистов; создать благоприятную среду обмена знаниями.
Управлять знаниями так, как управляют, например, финансовыми ресурсами, нельзя, но можно управлять взаимодействиями явных и неявных знаний, способствовать их обмену на уровне групп, индивидуальном и корпоративном уровнях, управлять переходом знаний из одной формы в другую. Процедуры взаимодействия могут быть реализованы в портале управления знаниями.
Портал управления знаниями — это корпоративный информационный портал для управления взаимодействием на уровне знаний сотрудников организации, рабочих групп и собственно организации. Он обеспечивает поиск, извлечение и представление знаний и предназначен для выявления, сохранения и эффективного использования знаний и информации в организации и ее окружении.
В зависимости от функциональной направленности или ориентации на определенную категорию пользователей существуют различные варианты порталов управления знаниями: кадровый, проектного офиса, управления взаимодействием с клиентами. Принципы, на которых строится портал, сочетают в себе специфику пользователей и перечень функций, с которыми данная категория пользователей будет работать.
Как правило, подобные порталы не реализуются на базе единого программного продукта, а формируются из отдельных функциональных модулей, реализующих конкретные решения.
Система управления содержимым /контентом (Content management system, CMS) — программный комплекс, который позволяет управлять электронным контентом (массивы текстовых и мультимедиадокументов, форумы, каталоги и др.).
Функции систем управления контентом:
• предоставление авторам удобных и привычных средств создания контента;
• храпение контента в едином репозитории, что позволяет отслеживать версии документов, контролировать их изменения и авторство, обеспечивать интеграцию с существующими информационными источниками и ИТ-системами, осуществлять управление потоком документов;
• автоматическое размещение контента на терминале пользователя, управление внешним видом страниц;
• дополнительные функции для улучшения формы представления данных.
Инструментарий управления контентом предлагается компаниями Glyphica (система Portalware), Autonomy (Portal-in-a-Box, Content Server и др.), Plumtree Software (Plumtree Server), Hyperknowledge (Hyperknowledge Builder), Intraspect Software (Intraspect Knowledge Server 2.0), Documentum (Documentum Enterprise Document Management System), Open Text (Livelink) и др.
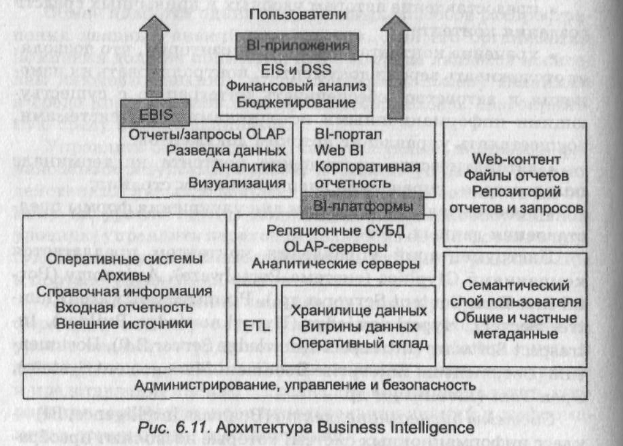
Системы бизнес-интеллекта (Business Intelligence, BI) — класс информационных систем, которые позволяют преобразовать разрозненные и необработанные данные операционной деятельности предприятия в структурированную информацию и знания, используемые для принятия управленческих решений. В отличие от стандартных систем отчетности, BI-системы основаны на технологиях моделирования ситуации, поведения объектов и визуализации их деятельности и играют ключевую роль в процессе стратегического планирования деятельности корпорации. Как правило, В1-решения являются надстройкой к ERP-системе.
Архитектура BI-системы представлена на рис. 6.11. BI-инструменты включают корпоративные ВТ-наборы (Enterprise BI Suites, EBIS), предназначенные для генерации запросов и отчетов, и BI-платформы, представляющие собой набор инструментов для создания, внедрения, поддержки и сопровождения BI-приложений. ВI-приложения содержат встроенные BI-инструменты (OLAP, генераторы запросов и отчетов, средства моделирования, статистического анализа, визуализации и Data Mining).
 По
оценкам агентства IDC
рынок Business
Intelligence
состоит из 5 секторов:
По
оценкам агентства IDC
рынок Business
Intelligence
состоит из 5 секторов:
1. OLAP-продукты.
2. Инструменты добычи данных.
3. Средства построения Хранилищ и Витрин данных (Data Warehousing).
4. Управленческие информационные системы и приложения.
5. Инструменты конечного пользователя для выполнения запросов и построения отчетов.
Классификация BI-систем базируется на методе функциональных задач, где программные продукты каждого класса выполняют определенный набор функций с использованием специальных технологий (прил. А). Как правило, функции BI включают поддержку принятия решений, запросы и отчетность, аналитическую обработку online, статистический анализ, прогнозирование и количественный анализ.
Интеграция BI-систем и ERP-систем обеспечивает использование качественных и количественных данных при выборе варианта решения, комбинацию внешних данных и совместных сценариев, что представляет собой новое поколение средств управления предприятием и бизнес-средой.
Для отслеживания финансовых и операционных показателей необходимо, чтобы BI-системы могли одновременно обращаться к данным из различных источников (БД автоматизированных систем, CRM-приложений и т.д.). Обработка таких данных невозможна без применения технологий интеграции на основе сервисно-ориентированной архитектуры.
Сектор BI-систем на белорусском рынке представлен слабо. Компания ЕРАМ представляет Hyperion® System™ 9, которая объединяет BI-платформу с финансовыми приложениями, легко адаптируемую под конкретные требования бизнеса (комплекс внедряется на Белорусском моторном заводе и в концерне «Белнефтехим»). Фирма ТопСофт представляет модуль Галактика Business Intelligence — комплекс приложений для поддержки принятия решений в сбытовой деятельности. На данный момент Галактика BI-Сбыт внедрена в Республике Беларусь в компаниях «British-American Tobacco» и «МАВ» (производство красок). Потенциальными потребителями BI-систем являются телекоммуникационные компании, которые испытывают потребность в глубоком анализе базы клиентов; банки, нуждающиеся в средствах аналитики услуг по кредитованию предприятий и частных лиц; промышленные предприятия и сфера торговли; государственные управленческие структуры; крупные компании и холдинги, требующие полнофункциональных BI-решений, интегрированных с системами планирования и бюджетирования; отрасли энергетики, нефтехимии — требуются BI-системы для повышения эффективности системы управления.
Потребность в системах искусственного интеллекта возникает по мере достижения предприятием достаточно высокой культуры управления.
Лидерами в области разработки корпоративных ВI-плат-форм являются MicroStrategy, Business Objects, Cognos, Hyperion Solutions, Microsoft, Oracle, SAP, SAS Institute и другие (в прил. Б).