

2 Функциональная структура памяти данных
2.1 Структура данных
2.1.1 Классификация данных
Данными называют информацию, которая обрабатывается при выполнении программ, при этом может быть изменено значение или место хранения данных. Данные, обрабатываемые в процессе выполнения одной команды, называются операндами. Структурными единицами информации являются бит, поле, слово, массив, сегмент, страница. Поле – последовательность бит, имеющая определенный смысл. Поле из восьми бит – байт. Слово – последовательность бит, полей или байтов, имеющая смысл. Каждое слово в памяти имеет свой адрес. Массив – последовательность слов, имеющих одинаковый смысл. Сегмент – последовательность структурных единиц информации, сгруппированных с целью названия (различные заголовки). Страница – область памяти, в которую входит несколько массивов и которая обрабатывается одной программой.
Данные подразделяются на типы: данные, определяемые программистом, и данные, определяемые системой. Типы данных зависят от назначения программы. Например, для коммутационных программ данные по составу оборудования определяются программистом, а данные о состоянии оборудования – системой.
Данные в памяти представлены в виде последовательности битов, разделенных на адресуемые слова. Структурой данных называют логическую организацию элементов данных. Например: массив двумерный. Представление в памяти – линейная последовательность ячеек памяти, содержащих целые числа. Логическая организация (структура) – прямоугольная сетка целых чисел, лежащая на плоскости.
Каждая структура данных имеет в ПО свой описатель (дескриптор), в котором содержится индикатор типа данных и дополнительная информация, необходимая для декодирования цепочки битов, в виде которых данные представлены.
Элементы данных подразделяются на простые и составные. Простыми называются элементы данных, операции доступа и изменения для которых выполняются над всем элементом (например, целые числа, логические и символьные данные). Основной структурой составных элементов данных является массив. Массивом называют структуру данных для представления упорядоченного множества элементов одного типа.
Массивы по структуре подразделяются на однородные и неоднородные. Однородные массивы имеют один описатель (дескриптор), неоднородные – разные описатели для разных элементов, представленных в массиве.
По размеру массивы подразделяются на массивы фиксированной и переменной длины. В последних размер динамически изменяется путем включения или исключения элементов (стеки, очереди, списки, деревья, графы).
Входящие в состав ПО ЦСК данные независимо от типа и структурной организации предназначены для отображения состояния объекта управления в памяти управляющей системы.
Данные по времени жизни подразделяются на:
постоянные данные, которые не изменяются в нормальном режиме работы ПО (таблицы констант, значения табличных функций, таблицы расписаний запуска программ и др.). Несанкционированный доступ к этому виду данных предотвращают специальные средства защиты памяти;
полупостоянные данные, которые могут быть изменены по командам оператора (абонентские, станционные и внестанционные характеристики);
оперативные данные, изменяются программами прикладного ПО и исполнительной операционной системы (данные о состояниях физических объектов и процессов).
Формирование первоначальных значений постоянных и полупостоянных данных осуществляется с помощью программ инициализации (первоначального запуска) и восстановления.
Данные, входящие в состав программного обеспечения, образуют базу данных. К базе данных предъявляются следующие требования:
быстрый доступ к необходимой информации, чтобы обеспечить требуемую скорость обработки вызовов;
целостность и непротиворечивость данных;
оптимальное использование ресурсов памяти путем дублирования данных только там, где это технически целесообразно;
возможность расширения структуры данных с незначительными затратами при согласовании базы данных при расширении станции.
Базы данных могут быть централизованными и децентрализованными. Децентрализация базы данных имеет следующие недостатки:
- увеличение общих потребностей в памяти;
- усложнение операций по изменению данных в распределенной памяти;
- необходимость наличия дополнительных средств для обеспечения непротиворечивости (согласованности) данных;
- увеличение времени на загрузку базы данных.
Объем, содержимое и организация базы данных зависит от системной организации коммутационной станции и от объема требуемых услуг связи. Надежность базы данных обеспечивается дублированием информации на магнитных и оптических носителях.
2.1.2 Массивы фиксированной длины
Векторы – однородные линейные массивы фиксированного размера. Логически вектор организован как последовательность элементов данных – последовательное представление в памяти. К каждому элементу данных возможен индивидуальный доступ с помощью целого индекса, указывающего позицию элемента в последовательности. Индивидуальные элементы данных, входящие в последовательность, могут заменяться новыми, но число элементов меняться не может (рисунок 2.1).
Дескриптор |
Вектор |
Тип данных |
|
LB |
Нижняя граница индекса |
||
UB |
Верхняя граница индекса |
||
Целый |
Тип элементов вектора |
||
E |
Длина элемента |
||
|
|
|
|
|
|
|
|
|
|
|
|
НА (начальный адрес, используемый для указания местонахождения вектора, отмечает начало массива) |
|
Битовая цепочка элемента А [LB] |
|
|
|||
|
Битовая цепочка элемента А [LB+1] |
||
|
|||
|
|
||
|
Битовая цепочка элемента А [UB] |
||
|
|||
Рисунок 2.1
Вектор – одномерный массив. Доступ к элементам вектора управляется индекс, значение которого может вычисляться во время выполнения программы. Формула доступа:
Адр Аi =НА+(i – LB) х Е,
где i – индекс элемента, к которому обеспечивается доступ;
LB – указатель нижней границы диапазона изменения индекса;
Е – длина элемента данных, указывает количество слов памяти (ячеек запоминающего устройства), отводимое для хранения элемента.
Пример: Массив состояний приборов, отображающий все возможные состояния данного типа приборов (свободен и исправен, занят в обслуживании вызова, заблокирован из-за неисправности, занят в профилактических проверках и т.д.). Каждому прибору в массиве соответствует один элемент, длина которого равна одному слову памяти. Если общее число приборов данного типа N, то в массиве должно храниться N слов и объем памяти составит N ячеек (рисунок 2.2).
НА+0 НА+1 НА+2 НА+3
НА+(N – 2) НА+(N – 1) |
Слово 0 |
Состояние прибора 0 Состояние прибора 1 |
Слово 1 |
||
Слово 2 |
Состояние прибора 2 Состояние прибора 3 |
|
Слово 3 |
||
|
|
|
Слово (N – 2) |
Состояние прибора (N – 2) Состояние прибора (N – 1) |
|
Слово ((N – 1) |
Рисунок 2.2
Для данного массива указатель нижней границы индекса LB=0, длина элемента Е=1.
Адрес, по которому хранится слово состояния прибора с номером i, будет равен:
Адр i=НА+(i – LB)хE= НА+(i –0) х1= НА+i
Матрицы – многомерные массивы, обычно представляются в виде прямоугольной сетки элементов на плоскости (двумерные матрицы). Трехмерный массив можно представить в виде трехмерного параллелепипеда и т.д. На рисунке 2.3 показана обычная матрица 3х4, состоящая из 12 элементов.
А11 |
А12 |
А13 |
А14 |
А21 |
А22 |
А23 |
А24 |
А31 |
А32 |
А33 |
А34 |
Рисунок 2.3 – Матрица 3х4
Местонахождение каждого элемента определяется двумя индексами. Двумерный массив можно рассматривать как вектор, элементы которого, в свою очередь, являются векторами; трехмерный массив – как вектор, элементы которого являются векторами векторов и т.д. Таким образом, линейный массив можно расширить на более высокие размерности, допуская, что элемент вектора также может быть вектором. Матрица, показанная на рисунке 2.3, может быть представлена как вектор, состоящий из трех векторов. В состав каждого вектора входят элементы одной строки. Такой подход к организации массива позволяет достаточно просто разместить его в памяти и организовать доступ к элементам. Наиболее распространена структура «столбец строк», хотя неважно как матрица рассматривается (может быть «столбец столбцов»). «Столбец строк» - представление, известное как упорядочение по строкам: массив представляется в виде вектора, состоящего из подвекторов, образуемых элементами массива с фиксированными значениями первого индекса (рисунок 2.4).
-
Дескриптор
Матрица
Тип данных
LB1
Нижняя граница
1-ый индекс
UB1
Верхняя граница
LB2
Нижняя граница
2-ой индекс
UB2
Верхняя граница
Целый
Тип элементов
E
Длина элемента
НА
Значение элем. А11
А11
Первая строка
Значение элем. А12
А12
Значение элем. А13
А13
Значение элем. А14
А14
Значение элем. А21
А21
Вторая строка
Значение элем. А22
А22
Значение элем. А23
А23
Значение элем. А24
А24
Значение элем. А31
А31
Третья строка
Значение элем. А32
А32
Значение элем. А33
А33
Значение элем. А34
А34
Рисунок 2.4 – Представление матрицы 3х4 в виде «столбца строк»
В случае матрицы, упорядоченной по строкам, в памяти первыми располагаются элементы первой строки, затем – второй и т.д. Этот метод размещения легко распространить на массивы более высокой размерности.
Если матрица упорядочена по строкам, то формула доступа к элементу Аij имеет вид:
Адр Аij =НА+(i – LB1) х S+(j – LB2) х Е,
где S – длина строки.
S=(UB2 – LB2+1) х Е
Пример: Массив индексов (номеров линий и приборов) для коммутационного поля ГИ DX200 (файл 0А). В файле хранится 256 записей (по числу цифровых линий, подключаемых к блоку ГИ). Длина каждой записи 5 байт (рисунок 2.5).
Запись 00 |
FF (индекс обслуживающей ЭВМ) |
FF (индекс управляющего процесса) |
13 |
00 (номер приемника) |
00 |
Подключение блока кодовых приемников |
|
|
|
|
|
|
|
Запись FE |
FF (индекс обслуживающей ЭВМ) |
FF (индекс управляющего процесса) |
12 |
01 (номер КПП) |
00 |
Подключение блока КПП |
Запись FF |
FF (индекс обслуживающей ЭВМ) |
00 (индекс управляющего процесса) |
00 |
00 |
00 |
Линия не используется |
|
0-ой байт |
1-ый байт |
2-ой байт |
3-ий байт |
4-ый байт |
|
Рисунок 2.5
В записях байты 0-ой и 1-ый имеют одинаковое назначение, в них фиксируются индексы обслуживающей ЭВМ и управляющего процесса. Содержимое байтов 2, 3 и 4 зависит от назначения подключаемой цифровой линии.
Для данного файла значения границ диапазонов изменения индексов LB1=0, UB1= FF; LB2=0, UB2=4. Длина элемента Е=1, т.к. длина слов памяти равна байту (используются восьмиразрядные ячейки памяти).
На рисунке 2.6 показано представление файла в виде «столбца строк».
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
НА 0 1 Одна строка 2 3 4 |
FF |
Запись 00 |
|||||||
FF |
|||||||||
13 |
|||||||||
00 |
|||||||||
00 |
|||||||||
|
|
|
|||||||
0 1 2 3 4 |
FF |
Запись FF |
|||||||
00 |
|||||||||
00 |
|||||||||
00 |
|||||||||
00 |
|||||||||
Рисунок 2.6
Неоднородные массивы фиксированной длины
Требования однородности массива не позволяют сосредоточить в одной области памяти разнообразные данные (например, полную абонентскую характеристику или характеристику направления связи и др.). Для хранения данных такого рода используются неоднородные массивы, которые могут быть многомерными.
Пример: Массив первой ступени абонентских характеристик (АХ) АТСЭ КВАНТ.
|
F |
E |
D |
C |
B |
A |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
НА 44000 |
0 |
Номер класса СКО |
Номер элемента в табл. НС |
Цифры ДЕ списочного номера абонента |
||||||||||||
|
1 |
Номер начального слова блока ППЗУ второй ступени АХ |
||||||||||||||
|
Максимально 2048 записей (каждому АК ставится в соответствие строка массива длиной два байта) |
|||||||||||||||
453FF |
1 |
Номер начального слова блока ППЗУ второй ступени АХ |
||||||||||||||
СКО – сокращенный класс обслуживания (тип сервиса с ограниченным набором ДВО)
Табл. НС – таблица нормализованных сотен, структура данных для определения значений пяти цифр абонентского номера: сотен (С), тысяч (Т), третьего индекса станции (И3), второго индекса станции (И2), первого индекса станции (И1)
ДЕ – цифры десятков и единиц списочного номера абонента
ППЗУ – полупостоянное запоминающее устройство, область памяти для хранения таблиц второй ступени АХ
Рисунок 2.7 – Структура первой ступени абонентских характеристик
Массивы переменного размера
Для хранения данных, которые поступают с устройств ввода в неизвестном заранее количестве или генерируются при работе программ непредсказуемым образом, используются массивы переменной длины. Они могут динамически расти и сокращаться во время выполнения программы. Представление в памяти тесно связано с тем, каким образом массив может расти и сокращаться. В качестве основных операций для массивов переменного размера рассматриваются операции включения новых элементов и исключения существующих. Доступ к элементам массивов переменного размера чаще всего относительный: найти элемент следующий (или предыдущий) по отношению к данному, найти последний элемент и т.д. Позиции элементов могут меняться при изменении размера массива.
Для массивов переменного размера, кроме последовательного представления в памяти, используется метод связанного представления: текущий элемент содержит указатель на позицию следующего и/или предыдущего элемента.
Стеки являются простейшей разновидностью линейных массивов переменного размера. Включение и исключение элементов ограничено только одним концом стека, называемым вершиною стека. Доступ разрешается только к элементу, расположенному на вершине стека, поэтому порядок доступа определяется правилом FILO (First In Last Out) – первым вошел, последним вышел. Для стеков применяется как последовательное, так и связанное представление в памяти.
Очереди отличаются от стеков тем, что доступ разрешен к обоим концам массива: включение новых элементов производится с нижнего конца, а исключение элементов – с вершины. Таким образом, очередь увеличивается с конца, сокращается с начала, действует правило FIFO (Fist In First Out) – первым вошел, первым вышел. Для очередей применяется как последовательное, так и связанное представление в памяти.
Списки являются линейными массивами, в которых включение и исключение элементов может выполняться в произвольных точках. Доступ возможен к любому, но только путем «прокручивания» списка, начиная с первого элемента, т.е. списки относятся к структуре данных с последовательным доступом. Каждый элемент содержит указатель на следующий. Если указатель задает только один следующий элемент, список называется однонаправленным. Если также есть указатель предыдущего элемента, список – двунаправленный. Списки имеют только связанное представление в памяти.
Контрольные вопросы:
1) Что такое данные? Как называются данные, которые обрабатываются в процессе выполнения одной команды?
2 )Пояснить структурные единицы информации (бит, поле, слово, массив, сегмент, страница).
3) Как данные представлены в памяти? Что называют структурой данных?
4) Назначение дескриптора.
5) На какие виды подразделяются данные в зависимости от срока жизни?
6) Что отображают полупостоянные данные и какие средства обеспечивают их изменение?
7) Что отображают оперативные данные и какие средства обеспечивают их изменение?
8) Какие виды баз данных применяются в коммутационных станциях, их достоинства и недостатки.
9) Что такое вектор? Как определяется адрес доступа к данным в векторе?
10) Определить адрес хранения состояния прибора с номером 12710, если начальный адрес массива состояний приборов АВС016 (рисунок 2.2).
11) Что такое матрица? Как определяется адрес доступа к данным в матрице?
12) Определить место хранения записи FE в массиве индексов (номеров линий и приборов) для коммутационного поля ГИ DX200 (рисунки 2.5, 2.6), если начальный адрес массива D00016.
13) Когда используются массивы данных переменной длины?
14) Какие правила определяют порядок доступа к данным в стеке, очереди?
15) Что такое однонаправленный и двунаправленный список?
2.2 Структуры полупостоянных данных
2.2.1 Виды таблиц
Полупостоянные данные относятся к категории справочной информации. Одной из основных структур таких данных являются таблицы, при помощи которых обеспечивается доступ к искомой информации (объектным параметрам) по известным исходным параметрам. Различают индексные и поисковые таблицы.
В индексных таблицах каждому исходному параметру ставится в соответствие набор объектных параметров. Объектные параметры расположены в таблице последовательно друг за другом в порядке нумерации исходных параметров.
Пример: таблица абонентских характеристик (рисунки 2.7, 2.8).
Номера разрядов ячеек памяти
Адреса |
F |
E |
D |
C |
B |
A |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
НА+СтН |
Абонентская характеристика (АХ) 0 |
|||||||||||||||
НА+СтН |
Абонентская характеристика (АХ) 1 |
|||||||||||||||
|
|
|||||||||||||||
НА+СтН |
Абонентская характеристика (АХ) (N –1) |
|||||||||||||||
НА – начальный адрес массива
СтН – станционный номер абонента (номер абонентского комплекта)
Рисунок 2.8 – Структура таблицы АХ
Исходным
параметром для поиска нужной абонентской
характеристики (АХ) является станционный
номер абонента, представленный в двоичной
системе. Поиск местонахождения АХ
производится смещением относительно
начального адреса (НА) массива АХ.![]()
В поисковых таблицах (ассоциативных) выбор объектных параметров производится не по внешнему признаку, а по ключу, с которым сравнивается каждое слово таблицы.
Поисковые и индексные таблицы, как правило, являются многоступенчатыми (рисунок 2.9). Результирующая структура такой таблицы является древовидной. Верхний узел называется корнем, нижние – терминальными элементами (объектные параметры).
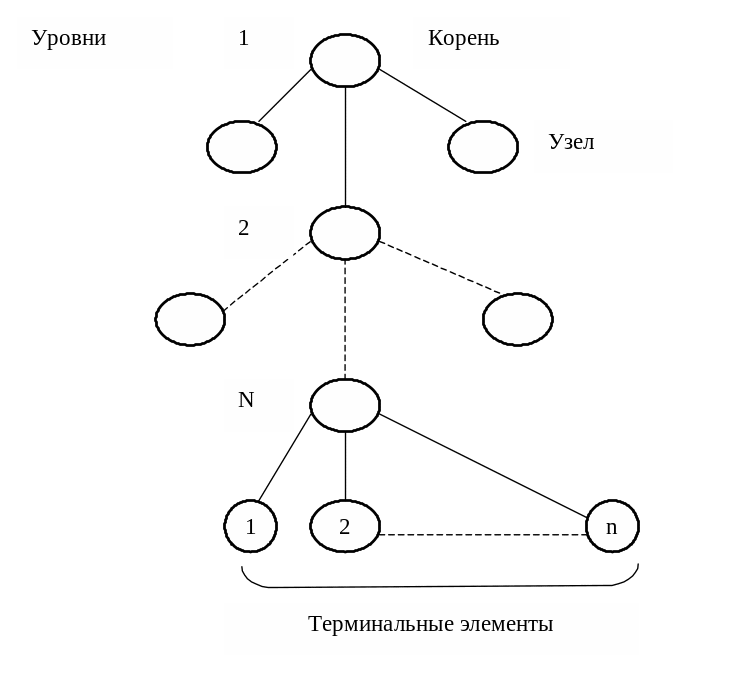
Рисунок 2.9 – Структура многоступенчатой таблицы
Если каждому узлу, за исключением терминальных, поставить в соответствие некоторую таблицу, то получим реализацию древовидной структуры на основе многоступенчатой таблицы (например, рисунок 2.10).
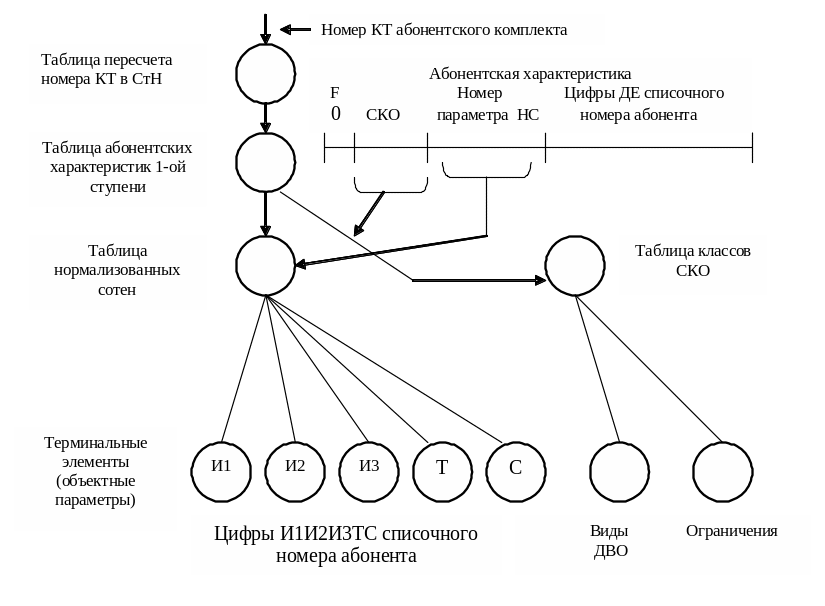
Рисунок 2.10
Пересчет списочных номеров (СНА) в станционные (СтН)
Примером индексных таблиц являются таблицы пересчета одного числа или набора чисел в другие. Эта процедура является достаточно распространенной операцией в коммутационной технике. Приборы АТС имеют несколько типов номеров, которые по ходу выполнения программ необходимо пересчитывать из одного вида в другой (например, для АК, рисунок 2.11).
Списочный номер абонента зафиксирован в справочниках, известен абоненту, представлен в десятичной системе.
Номер абонентского комплекта (порядковый номер АК) называется станционным номером абонента, в памяти управляющих устройств представлен в двоичной системе, для обслуживающего персонала выводится в восьмеричной или шестнадцатеричной системе.
Позиционный номер определяет координаты включения АК в коммутационное поле.
Номер контрольной точки АК используется программами сканирования для обращения к матрице сканирования в периферийном оборудовании и определения местонахождения разряда памяти, отображающего ее состояние в массиве состояний КТ.
В процессе установления соединения номера АК пересчитываются из одного типа в другой при помощи соответствующих таблиц. При разработке программного обеспечения АТС всегда стремятся упорядочить связь между номерами АК. Например, абонентскую линию со списочным номером 0000 включают в АК с порядковым номером 0. Наличие такой закономерности облегчает пересчет, экономит память, но в процессе эксплуатации такие закономерности могут нарушаться.
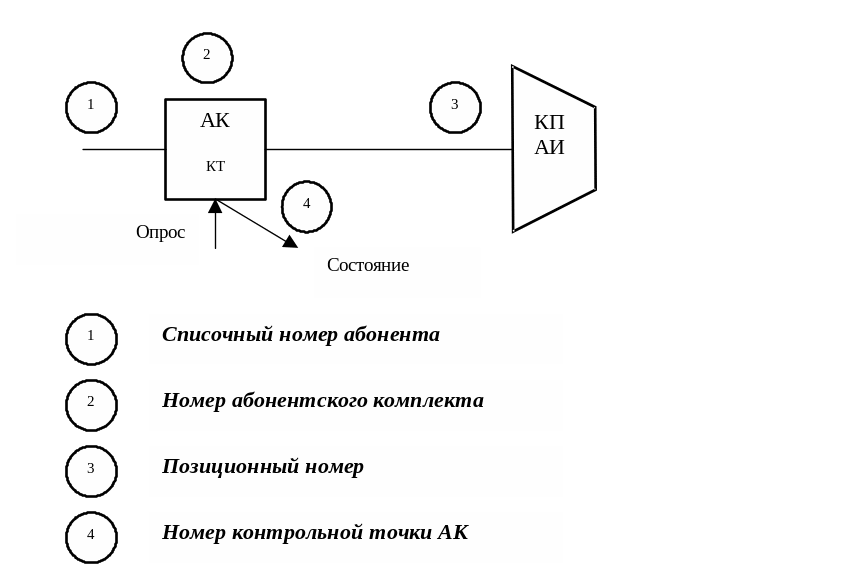
АК – абонентский комплект
КТ – контрольная точка
КП АИ – коммутационное поле ступени абонентского искания
Рисунок 2.11
Для пересчета могут применяться одноступенчатая и двухступенчатая дешифрация.
Например, нумерация абонентских линий 510000…512999.
Одноступенчатая дешифрация (рисунок 2.12).
СНА |
510000 |
510001 |
510002 |
|
510028 |
Адреса памяти |
НА |
НА+1 |
НА+2 |
|
НА+28 |
Таблица |
0 (N АКСтН) |
1 (N АКСтН) |
2 |
|
28 (N АКСтН) |
 (N
АКСтН)
(N
АКСтН)
СтН – станционный номер абонента
Рисунок 2.12 – Одноступенчатая дешифрация