

Правительство Российской Федерации
Федеральное государственное автономное образовательное учреждение
высшего профессионального образования
«Национальный исследовательский университет
«Высшая школа экономики»
Факультет экономики
Кафедра экономики и финансов фирмы
Магистерская программа "Стратегическое управление финансами фирмы"
Анализ технологии применения matching models на примерах академических статей.
Интеграция matching models в метод событий с длинным периодом наблюдений.
Выполнили студенты факультета экономики
Группы СУФФ1,2:
Борисенко А.
Гаврилкин А.
Елисеева Н.
Нурдинова Я.
Плотникова М.
Федорова А.
Москва, 2011
Целью данного исследования явилось проанализировать применение matching models на примерах академических статей. В ходе исследования были выполнены следующие задачи:
Рассмотреть процесс интеграции matching models в метод событий с длинным периодом наблюдений;
Рассмотреть метод отбора подобного по вероятности;
Проанализировать загадку новых выпусков;
Проанализировать аномальные доходности для SEO с помощью данных методов.
Propensity Score Matching and New Issues Puzzle (Cheng Y., 2003)1
Метод отбора подобного по вероятности и загадка новых выпусков
Данная работа является одной из первых, в которых метод отбора подобного по вероятности, применяется к вопросам корпоративных финансов. В ней исследуется загадка наличия отрицательных аномальных доходностей после выпуска акций. Ранее эта проблема анализировалась с помощью применения либо факторного анализа, либо метода событий с соответствием по характеристикам (characteristic matching event study). При этом исследователи получали противоречивые результаты: работы, в которых использовался метод событий с соответствием по характеристикам (Loughran and Ritter (1995), Spiess and Affleck-Graves (1995), Jung, Kim and Stulz (1996), Loughran and Ritter (2000) and Jegadeesh (2000)), а также ряд работ, в которых применялся факторный анализ, также подтверждают наличие отрицательных доходностей после SEO (Loughran and Ritter (1995, 2000)). Однако Eckbo, Masulis, and Norli (2000) и Brav, Geczy and Gompers (2000), применяя факторный анализ, не нашли подтверждения наличию аномальных доходностей после SEO.
Тем не менее, несмотря на согласованность результатов, полученных в работах, где применялся метод событий с соответствием по характеристикам, сам этот метод не свободен от недостатков. Автор указывает на наличие «проклятия многомерности», которое заключается в том, что отбор фирм-аналогов (компаний, которые максимально похожи на исследуемые, но в течение рассматриваемого периода в отличие от последних, не осуществляли SEO) в рамках данного метода основывается максимум на 2-3 факторах. Данный недостаток может привести к тому, что фирмы-аналоги будут выбраны неправильно и полученные результаты будут неадекватными.
В своей работе Ченг обращается к теории причинности (causal inference theory). SEO можно рассматривать как своего рода эксперимент, который ставится над фирмой (treatment), тогда можно сказать, что оценка AR эмитентов после события является эффектом эксперимента (treatment effect). Ожидаемый эффект от эксперимента можно рассчитать следующим образом:
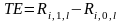
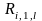 -
доходность фирмы i
в течение периода l,
если фирма выпускает акции
-
доходность фирмы i
в течение периода l,
если фирма выпускает акции
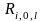 -
доходность фирмы i
в
течение периода l,
если фирма не выпускает акции
-
доходность фирмы i
в
течение периода l,
если фирма не выпускает акции
Введем переменную Si:
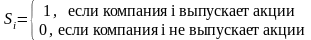
Тогда ожидаемый эффект от эксперимента для SEO фирм:
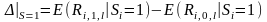 (1)
(1)
Здесь
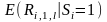 -
средняя доходность акций фирм,
осуществивших SEO,
в течение периода l,
начинающегося с исследуемого события.
-
средняя доходность акций фирм,
осуществивших SEO,
в течение периода l,
начинающегося с исследуемого события.
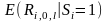 -
то, какой была бы средняя доходность
акций фирм, осуществивших SEO,
в течение периода l,
начинающегося с исследуемого события.
-
то, какой была бы средняя доходность
акций фирм, осуществивших SEO,
в течение периода l,
начинающегося с исследуемого события.
Но,
поскольку значение
ненаблюдаемо,
то данное слагаемое мы заменяем на
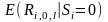 -
среднюю доходность акций non-SEO
фирм в течение периода l.
Тогда формула для вычисления ожидаемого
эффекта от эксперимента для SEO
фирм будет выглядеть следующим образом:
-
среднюю доходность акций non-SEO
фирм в течение периода l.
Тогда формула для вычисления ожидаемого
эффекта от эксперимента для SEO
фирм будет выглядеть следующим образом:

Однако
стоит учесть, что, поскольку решение о
том, какая фирма выпускает акции, а какая
– нет, принимается не случайным образом,
не
будет равно
,
а
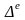 будет смещенной оценкой ∆. В то же время
Rubin
(1977) показывает, что если фирмы из обеих
групп, экспериментальной (SEO)
и контрольной (non-SEO)
обладают сходными характеристиками,
то можно рассматривать эти фирмы как
участвующие в эксперименте, в котором
решение о том, какая фирма является SEO,
а какая non-SEO,
принимается случайно. Эффект от
эксперимента может тогда быть вычислен
по следующей формуле.
будет смещенной оценкой ∆. В то же время
Rubin
(1977) показывает, что если фирмы из обеих
групп, экспериментальной (SEO)
и контрольной (non-SEO)
обладают сходными характеристиками,
то можно рассматривать эти фирмы как
участвующие в эксперименте, в котором
решение о том, какая фирма является SEO,
а какая non-SEO,
принимается случайно. Эффект от
эксперимента может тогда быть вычислен
по следующей формуле.
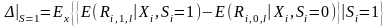 (2)
(2)
Где Xi – вектор характеристик фирмы i. Один из способов оценить выражение (2), подобрать non-SEO фирмы, соответствующие SEO фирмам. Такова суть методов соответствия (matching approach) в целом.
Из-за наличия проклятия многомерности традиционные методы соответствия могут учесть только 2-3 характеристики в векторе X.
С точки зрения эконометрической теории, в основе метода поиска подобного по вероятности лежит Propensity Score Theorem (Rosenbaum, Ruben, 1983). Пусть P(X) – вероятность участвовать в эксперименте (так называемая оценка склонности (propensity score), Х – вектор независимых переменных. Тогда соответствие может быть найдено путем сравнения P(X), а не X непосредственно.
Тогда выражение (3) можно переписать следующим образом:
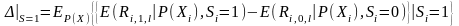
Таким образом метод отбора подобного по вероятности позволяет избавиться от проклятия многомерности и заменить сопоставление по факторам непосредственно на сопоставление по вероятностям.
Метод отбора подробного по вероятности, предлагаемый автором, позволяет учесть большее количество факторов, а, значит, более аккуратно подойти к выбору фирмы-аналога. Особенность данного подхода заключается в том, что аналог для компании выбирается не на основании значений конкретного набора характеристик, а на основании одинаковой условной вероятности выхода на SPO. На первом этапе исследования оценивается логит-модель, иллюстрирующая зависимость вероятности выхода компанией на SPO от ряда характеристик компании. Затем, на основании полученных оценок коэффициентов, оценивается условная вероятность (propensity score) выхода компании на SPO.
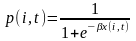
где p(i,t) – вероятность того, что фирма i осуществит выпуск акций в году t;
x(i,t) – вектор характеристик фирмы;
β – вектор оцениваемых параметров.
Вектор характеристик исследуемых фирм формируется из тех факторов, которые могут повлиять на решение фирмы о выпуске акции (те, что были использованы при оценке логит-модели). Автор предлагает учитывать следующие факторы:
Фиктивная переменная, соответствующая году выпуска акций; фиктивная переменная, соответствующая конкретной отрасли (используется классификация Фамы-Френча); моментум (buy-and-hold доходность акций компании в предшествующие 11 месяцев). Данные переменные используются в соответствии с market timing hypothesis, которая говорит о том, что фирмы выбирают для выпуска акций момент, когда рынок находится на подъеме, либо когда акции фирмы переоценены.
Q-Тобина, отношение расходов на R&D к балансовой стоимости активов используется в соответствии с growth-potential-signaling hypotheses, которая говорит о том, что в условиях асимметрии информации выпуск акции может служить сигналом о наличии потенциала роста.
Расходы будущих периодов, переменная, использующаяся в соответствии с future-earnings hypothesis (фирмы выпускают акции, когда рынок переоценивает их возможность генерировать прибыль в будущем).
Кроме того, в качестве регрессоров используется рычаг, размер фирмы, ROA, отношение выручки к активам (мера операционной эффективности), балансовая стоимость собственного капитала, деленная на рыночную, а также торговая система.
Далее автор выбирает из приведенного списка регрессоров те, которые позволяют максимизировать долю правильно классифицированных фирм. Для этого рассматриваются различные наборы регрессоров, и для каждого из них оценивается модель зависимости того, вышла ли компания на SEO от различных комбинаций факторов. Далее для каждой фирмы рассчитывается условная вероятность выпуска акций на основании полученных на первом шаге оценок коэффициентов. Если полученное значение превышает уровень отсечения (рассчитывается как отношение количества наблюдений по фирмам, осуществившим SEO к общему количеству наблюдений), то делается вывод о том, что данная фирма будет отнесена к классу «SEO». Если же полученное значение ниже уровня отсечения, то данная фирма будет отнесена к классу «non-SEO». Общий процент верно типизированных фирм (фирма верно типизирована, если модель относит ее к классу SEO и фирма действительно выпустила акции либо если модель относит ее к классу non-SEO и фирма не выпускала акции) и будет долей правильно классифицированных фирм. Максимизирующая долю правильно классифицированных фирм комбинация регрессоров для исследуемой автором выборки является следующей: фиктивная переменная, соответствующая году выпуска; фиктивная переменная, соответствующая конкретной отрасли; моментум; ROA; рычаг, размер, отношение расходов на R&D к активам, отношение балансовой стоимости собственного капитала к рыночной стоимости собственного капитала; отношение выручки к активам, торговая система. При этом доля верно классифицированных фирм составила 70%.
Далее для каждой фирмы из класса SEO выбирается фирма-аналог из класса non-SEO таким образом, чтобы вероятность выпуска акций для фирмы-аналога из класса non-SEO была максимально близка к вероятности выпуска акций для фирмы из класса SEO.
Избыточная доходность оценивается как разница в buy-and-hold доходности компании “SEO”и компании-аналога.
Временной горизонт: 3 года и 5 лет
Выборка включает данные по SEO с 1970 по 1997 год, при этом эмитент должен котироваться на CRSP как минимум год до года выпуска и иметь при этом код акций 10 или 11 (только обычные акции), торговаться на NYSE, NASDAQ, AMEX. Если фирмы осуществила несколько выпусков в течение одного календарного года, то учитывается только первый из них. Фирмы non-SEO отбираются на основе сходных критериев, отличным является только условие, что в конкретном рассматриваемом календарном году фирма не выпускает акции.
Результаты, полученные по методу propensity score matching, сравниваются с теми, что были получены по альтернативным методам выбора компании-аналога. К их числу относится выбор на основании следующих комбинаций измерений: отрасль и размер; размер и отношение балансовой стоимости собственного капитала к рыночной; размер и отношение балансовой стоимости собственного капитала к рыночной, отрасль.
При выборе компаний-аналогов альтернативными способами автор получила тот же результат, что и исследователи ранее: фирмы, предпринявшие SEO, имеют негативные аномальные доходности. Но при этом стоит отметить, что фирмы-аналоги, подобранные по критериям, описанным выше (стандартные процедуры соответствия), имели значительные различия по ROA, соотношению выручки и активов. Таким образом, компании-аналоги были подобраны не наилучшим образом.
При использовании метода отбора подобного по вероятности автор приходит к выводу, что негативные аномальные доходности для фирм SEO отсутствуют. Таким образом, доходность SEO компании незначимо отличается от доходности аналога. Это объясняется тем, что подбор фирмы-аналога по этому методу более точен. Следовательно, можно сделать вывод о том, что выявление негативных аномальных доходностей при применении стандартной процедуры подбора может объясняться неточностью подбора компании-аналога.
Propensity Score-Matching Methods For Nonexperimental Causal Studies (Dehejia, Wahba s., 2002)2
Данная работа рассматривает метод событий на основе теории причинности «causal inference». Производится специальный отбор в выборку, о котором говорилось ранее – подбирается компания-аналог для исследуемой компании на основании многих значимых характеристик. Также рассматривается применимость метода в случае, если компании имеют значимые различия. Метод соответствия проверялся на данных из the National Supported Work (NSW) Demonstration.
Выбор компании аналога в ряде работ осуществляется на основании небольшого количества параметров (двух-трех), однако по причине такого отбора возникает проблема несоответствия других параметров в рассматриваемых компаниях. Если же пытаться отбирать компании-аналоги на основе большего числа характеристик, то поиск аналогичных компаний станет затруднительнее. Также появится проблема взвешивания показателей в итоговом сравнительном анализе.
Важными пунктами в проведении метода соответствия являются:
отбор в соответствии с критерием рандомизации;
одинаковые ковариации для фирм;
нивелирование «проклятия многомерности».
Метод соответствия на основе «propensity score» представляет собой процедуру взвешивания, которая присваивает определенные веса сравниваемым параметрам:

где N – количество фирм в рассматриваемой группе, Ji – параметры, по которым происходит сравнение.
В связи с применением моделей соответствия возникает три проблемы: есть ли необходимость осуществлять соответствие с заменой; сколько сравниваемых параметров достаточно для формирования выборки; и последняя – какую из моделей соответствия выбрать.
Выборка
Для формирования выборки авторами данной статьи была использована база The NSW. Она является федеральной американской частной программой, которая обеспечивает работой людей, столкнувшихся с экономическими и социальными проблемами. Кандидаты отбирались на основе критерия профпригодности, а далее случайным образом распределялись в рамках тренинговой программы или вовсе исключались из нее.
В результате исследования авторы статьи приходят к выводу, что модель соответствия является применимой даже в случае, если сравниваемые объекты имеют значимые отличия. Данные, проверяемые в статье, были схожи с данными, исследуемыми LaLonde (1986), на которых автор продемонстрировал невозможность применения стандартных неэкспериментальных методов для изменения «the treatment effect». Методы, обсуждаемые в этой статье, стоит рассматривать в качестве дополнения к стандартным регрессионным технологиям исследования. Применения данных методов поможет исследователю выбрать наиболее адекватные регрессионные модели, соответствующие реальности.
Using Propensity Score Matching and Estimating Treatment Effects: An Application to the Post-Issue Operating Performance of French ipOs (Slim Chaouani, 2010)3
В своей статье Slim Chaouani рассматривает влияние IPO на деятельность компании. Для этого он использовал метод подбора подобного по вероятностям и average treatment effect для компаний, которые провели IPО и для компаний, которое не проводили.
Для исследования автор использовал выборку из 3951 компании Франции за период с 1996 по 2006 года. Из 3951 компаний 157 компаний – это те, которые провели IPO. Компании были выбраны из Euronext Paris из Nouveau Marché и Second Marché.
В качестве treatment group автор принял фирмы, которые приняли решение о проведении IPO.
Автор следовал следующим этапам для того, чтобы использовать метод подбора подобного по вероятностям:
Оценка logit-модели для эндогенной переменной выбора (проводить ли IPO), основанной на наблюдаемых характеристиках компании и отрасли.
Каждое наблюдение из группы, участвующей в событии, (проводившие IPO) сопоставляется с наблюдением из группы контроля (не проводившие) на основе их propensity score.
Т-тест для определения наличия большого различия среднего каждой выбранной характеристики между двумя группами.
Оценить влияние IPO на результаты операционной деятельности.
Автор пришел к выводу, что фирмы, проводящие IPO меньше по размерам, моложе, более инновационные, имеют меньший рычаг и показатель рентабельности выше, чем у компаний, которые не проводили IPO.
Т-статистика показала, что модель хорошо сбалансировала выборку (matched). Сопоставление (matching) сильно повлияло на следующие показатели: рост, рычаг, возраст, показатель предыдущей деятельности. Баланс между участниками в событии и контрольной группами улучшился более, чем на 50% по сравнению с несопоставленными данными для 12 из 18 переменных. Среднее значения уменьшения смещенности составило 43.84%.
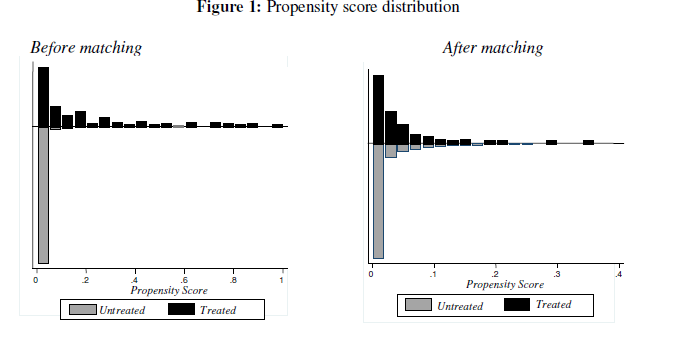
Рис. 1. Распределение оценки склонности
Автор предоставил графические иллюстрации распределения propensity score до и после сопоставления.
F-тест также показал, что объясняющие переменные хорошо сбалансированы. Также pseudo R2 стал меньше, что говорит о том, что переменные более сбалансированы.
Чтобы оценить результаты деятельности компаний после IPO, автор рассмотрел деятельность предприятия за 2 года до IPO и 5 лет после события и сравнил полученные данные с медианой аналогичных значений компаний, которые не проводили IPO. Для определения результатов деятельности автор выбрал следующие прокси-переменные: показатели ROA и ROS в качестве меры рентабельности, в качестве меры эффективности было принят показатель оборотности активов, темп прироста выручки в качестве показателя выпуска, и debt-to-assets в качестве показателя рычага.
Проанализировав полученные данные, автор делает вывод, что результаты деятельности компании, которые провели IPO ниже, чем у тех, которые не проводили.
Автор также посмотрел средний эффект от участия в событии. Он оказался отрицательным. А стандартное отклонение было приблизительно равно по группам прокси-переменных.